PHẦN II: Dữ Liệu Phân Tán
Đối với một công nghệ thành công, thực tế phải được đặt lên trên quan hệ công chúng, vì tự nhiên không thể bị đánh lừa.
— Richard Feynman, Rogers Commission Report (1986)
Trong Phần I của cuốn sách này, chúng ta đã thảo luận về các khía cạnh của hệ thống dữ liệu khi dữ liệu được lưu trữ trên một máy đơn. Bây giờ, trong Phần II, chúng ta nâng lên một mức và đặt câu hỏi: điều gì xảy ra khi có nhiều máy tham gia vào việc lưu trữ và truy xuất dữ liệu?
Có nhiều lý do khiến bạn muốn phân tán một cơ sở dữ liệu trên nhiều máy:
Khả năng mở rộng (Scalability)
Nếu khối lượng dữ liệu, tải đọc hay tải ghi tăng đến mức một máy đơn không thể xử lý được, bạn có thể phân tải ra nhiều máy.
Khả năng chịu lỗi và tính sẵn sàng cao (Fault tolerance / High availability)
Nếu ứng dụng cần tiếp tục hoạt động ngay cả khi một máy (hoặc nhiều máy, hoặc mạng, hoặc toàn bộ một trung tâm dữ liệu) gặp sự cố, bạn có thể sử dụng nhiều máy để tạo dự phòng (redundancy). Khi một máy hỏng, máy khác có thể tiếp quản.
Độ trễ thấp (Low latency)
Nếu bạn có người dùng trên khắp thế giới, bạn có thể muốn đặt máy chủ ở nhiều vị trí địa lý khác nhau để mỗi người dùng được phục vụ từ trung tâm dữ liệu gần họ nhất. Điều đó giúp người dùng tránh phải chờ các gói tin đi nửa vòng Trái Đất.
Mở Rộng Lên Tải Cao Hơn
Nếu tất cả những gì bạn cần là mở rộng để chịu tải cao hơn, cách đơn giản nhất là mua một máy mạnh hơn (đôi khi gọi là vertical scaling hay scaling up). Nhiều CPU, nhiều chip RAM và nhiều đĩa có thể được kết hợp lại dưới một hệ điều hành duy nhất, và một kết nối nội bộ tốc độ cao cho phép mọi CPU truy cập vào bất kỳ phần nào của bộ nhớ hoặc đĩa. Trong kiến trúc bộ nhớ chia sẻ (shared-memory architecture) như vậy, tất cả các thành phần có thể được xem như một máy duy nhất 1.
Note
Trong một máy lớn, dù mọi CPU đều có thể truy cập vào toàn bộ bộ nhớ, nhưng một số bank bộ nhớ gần với một CPU hơn các CPU khác (gọi là truy cập bộ nhớ không đồng đều, hay NUMA 1). Để khai thác hiệu quả kiến trúc này, quá trình xử lý cần được chia nhỏ sao cho mỗi CPU chủ yếu truy cập bộ nhớ ở gần nó - nghĩa là phân vùng (partitioning) vẫn cần thiết ngay cả khi chỉ chạy trên một máy.
Vấn đề với cách tiếp cận bộ nhớ chia sẻ là chi phí tăng nhanh hơn tuyến tính: một máy có gấp đôi số CPU, gấp đôi RAM và gấp đôi dung lượng đĩa thường tốn hơn gấp đôi tiền. Và do các nút thắt cổ chai, một máy to gấp đôi chưa chắc đã xử lý được tải gấp đôi.
Kiến trúc bộ nhớ chia sẻ có thể cung cấp khả năng chịu lỗi ở mức độ hạn chế - các máy cao cấp có thành phần hot-swap (bạn có thể thay thế đĩa, module RAM và thậm chí CPU mà không cần tắt máy) - nhưng nó bị giới hạn ở một vị trí địa lý duy nhất.
Một hướng khác là kiến trúc lưu trữ chia sẻ (shared-disk architecture), sử dụng nhiều máy với CPU và RAM độc lập, nhưng dữ liệu được lưu trên một mảng đĩa dùng chung giữa các máy, kết nối qua mạng tốc độ cao. Kiến trúc này được dùng trong một số workload kho dữ liệu (data warehousing), nhưng tranh chấp và chi phí khóa (locking overhead) thường hạn chế khả năng mở rộng của shared-disk 2.
Note
Network Attached Storage (NAS) hay Storage Area Network (SAN).
Kiến Trúc Không Chia Sẻ (Shared-Nothing)
Ngược lại, kiến trúc không chia sẻ (shared-nothing architectures) 3 (đôi khi gọi là horizontal scaling hay scaling out) đã trở nên rất phổ biến. Trong kiến trúc này, mỗi máy hoặc máy ảo chạy phần mềm cơ sở dữ liệu được gọi là một nút (node). Mỗi nút sử dụng CPU, RAM và đĩa của riêng mình. Sự phối hợp giữa các nút được thực hiện ở tầng phần mềm, sử dụng mạng thông thường.
Hệ thống shared-nothing không đòi hỏi phần cứng đặc biệt, nên bạn có thể dùng bất kỳ máy nào có tỉ lệ giá/hiệu năng tốt nhất. Bạn có thể phân tán dữ liệu ra nhiều khu vực địa lý khác nhau, từ đó giảm độ trễ cho người dùng và có khả năng chịu lỗi ngay cả khi toàn bộ một trung tâm dữ liệu gặp sự cố. Với triển khai đám mây sử dụng máy ảo, bạn không cần phải là Google mới làm được: ngay cả doanh nghiệp nhỏ cũng có thể xây dựng kiến trúc phân tán đa vùng ngày nay.
Trong phần này của cuốn sách, chúng ta tập trung vào kiến trúc shared-nothing - không phải vì nó luôn là lựa chọn tốt nhất cho mọi trường hợp, mà vì nó đòi hỏi sự thận trọng nhất từ phía bạn, người phát triển ứng dụng. Khi dữ liệu được phân tán trên nhiều nút, bạn cần nhận thức được các ràng buộc và đánh đổi trong hệ thống phân tán - cơ sở dữ liệu không thể che giấu những điều đó khỏi bạn một cách kỳ diệu.
Dù kiến trúc phân tán shared-nothing có nhiều ưu điểm, nó thường cũng kéo theo độ phức tạp bổ sung cho ứng dụng và đôi khi giới hạn tính biểu đạt của các mô hình dữ liệu bạn có thể sử dụng. Trong một số trường hợp, một chương trình đơn luồng đơn giản có thể hoạt động tốt hơn đáng kể so với một cụm hơn 100 lõi CPU 4. Mặt khác, hệ thống shared-nothing có thể rất mạnh mẽ. Vài chương tiếp theo sẽ đi vào chi tiết các vấn đề phát sinh khi dữ liệu được phân tán.
Replication và Partitioning
Có hai cách phổ biến để phân tán dữ liệu trên nhiều nút:
Replication (Sao chép)
Lưu một bản sao của cùng một dữ liệu trên nhiều nút khác nhau, có thể ở các vị trí địa lý khác nhau. Replication cung cấp tính dự phòng: nếu một số nút không khả dụng, dữ liệu vẫn có thể được phục vụ từ các nút còn lại. Replication cũng có thể giúp cải thiện hiệu suất. Chúng ta sẽ thảo luận về replication trong Chương 6.
Partitioning (Phân vùng)
Chia một cơ sở dữ liệu lớn thành các tập con nhỏ hơn gọi là partition (phân vùng) để các phân vùng khác nhau có thể được gán cho các nút khác nhau (còn gọi là sharding). Chúng ta sẽ thảo luận về partitioning trong Chương 7.
Đây là hai cơ chế riêng biệt, nhưng thường được dùng kết hợp với nhau, như minh họa trong Hình II-1.
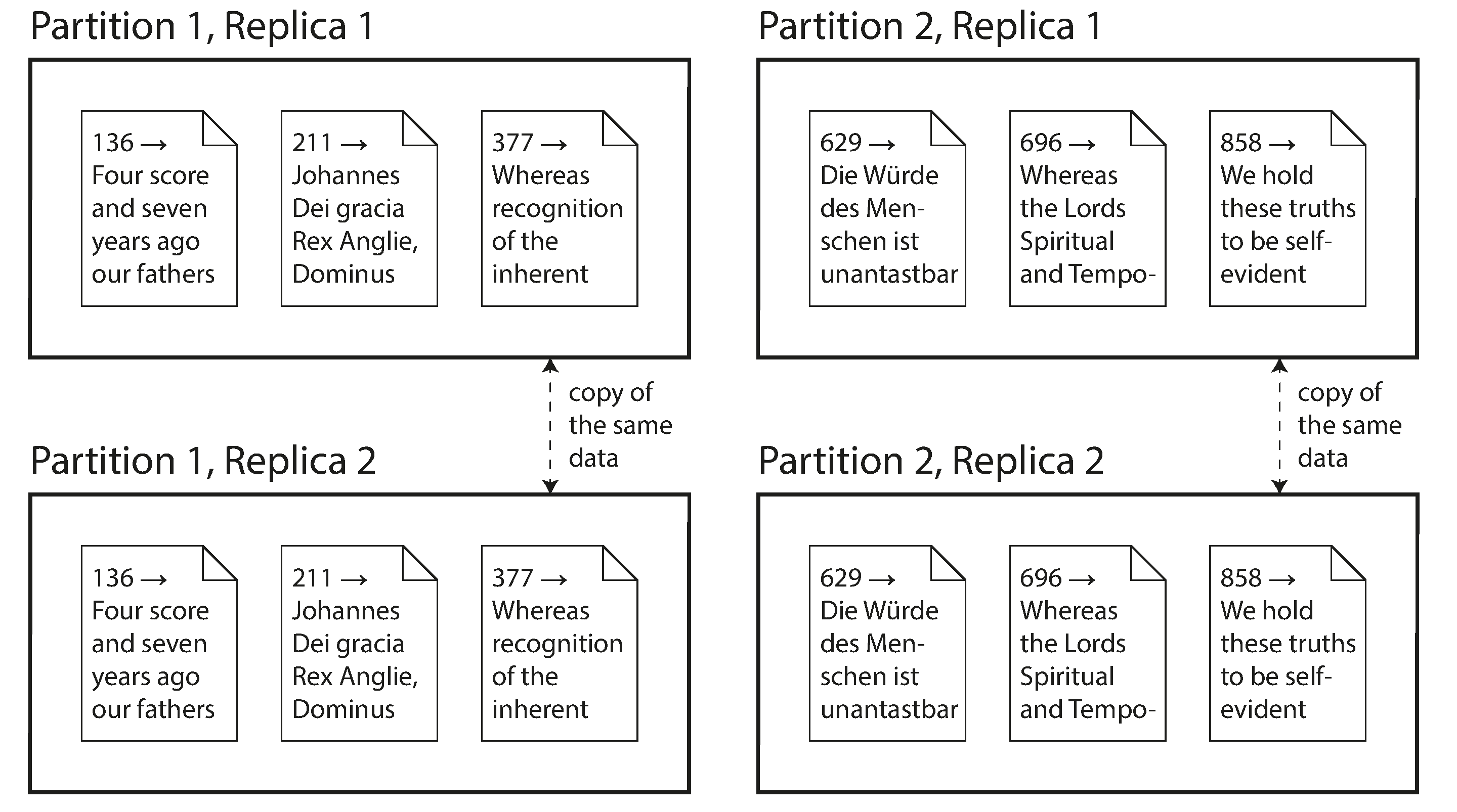
Khi đã hiểu các khái niệm đó, chúng ta có thể thảo luận về những đánh đổi khó khăn mà bạn cần thực hiện trong một hệ thống phân tán. Chúng ta sẽ thảo luận về transaction (giao dịch) trong Chương 8, vì điều đó sẽ giúp bạn hiểu tất cả những thứ có thể xảy ra sai trong một hệ thống dữ liệu và bạn có thể làm gì về chúng. Chúng ta sẽ kết thúc phần này bằng cách thảo luận về các giới hạn cơ bản của hệ thống phân tán trong Chương 9 và Chương 10.
Sau đó, trong Phần III của cuốn sách này, chúng ta sẽ thảo luận về cách bạn có thể kết hợp nhiều kho dữ liệu (có thể phân tán) thành một hệ thống lớn hơn, đáp ứng nhu cầu của một ứng dụng phức tạp. Nhưng trước tiên, hãy nói về dữ liệu phân tán.
6. Replication - Sao Chép Dữ Liệu
- Single-Leader Replication
- Vấn Đề Với Replication Lag
- Multi-Leader Replication
- Leaderless Replication
- Tóm Tắt
7. Sharding - Phân Mảnh Dữ Liệu
- Ưu và Nhược Điểm của Sharding
- Sharding Dữ Liệu Key-Value
- Định Tuyến Yêu Cầu (Request Routing)
- Sharding và Chỉ Mục Thứ Cấp
- Tóm Tắt
8. Transaction - Giao Dịch
9. Rắc Rối Với Hệ Thống Phân Tán
- Lỗi và Sự Cố Mạng
- Mạng Không Đáng Tin Cậy
- Đồng Hồ Không Đáng Tin Cậy
- Kiến Thức, Sự Thật và Dối Trá
- Tóm Tắt
10. Tính Nhất Quán và Đồng Thuận (Consensus)
Tài Liệu Tham Khảo
Ulrich Drepper: “What Every Programmer Should Know About Memory,” akka‐dia.org, November 21, 2007. ↩︎ ↩︎
Ben Stopford: “Shared Nothing vs. Shared Disk Architectures: An Independent View,” benstopford.com, November 24, 2009. ↩︎
Michael Stonebraker: “The Case for Shared Nothing,” IEEE Database EngineeringBulletin, volume 9, number 1, pages 4–9, March 1986. ↩︎
Frank McSherry, Michael Isard, and Derek G. Murray: “Scalability! But at What COST?,” at 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015. ↩︎