6. Replication
Sự khác biệt lớn nhất giữa một thứ có thể xảy ra sự cố và một thứ không thể nào xảy ra sự cố là khi thứ không thể nào xảy ra sự cố ấy lại xảy ra, thì thường hóa ra là không thể nào tiếp cận hay sửa chữa được nó.
Douglas Adams, Mostly Harmless (1992)
Replication (sao chép dữ liệu) có nghĩa là lưu giữ bản sao của cùng một dữ liệu trên nhiều máy được kết nối qua mạng. Như đã thảo luận trong “Distributed versus Single-Node Systems”, có một số lý do để bạn muốn sao chép dữ liệu:
- Để giữ dữ liệu gần về mặt địa lý với người dùng (và từ đó giảm độ trễ truy cập)
- Để hệ thống tiếp tục hoạt động ngay cả khi một số thành phần gặp sự cố (và từ đó tăng tính sẵn sàng)
- Để mở rộng số lượng máy có thể phục vụ các truy vấn đọc (và từ đó tăng thông lượng đọc)
Trong chương này chúng ta sẽ giả định rằng tập dữ liệu đủ nhỏ để mỗi máy có thể giữ một bản sao toàn bộ tập dữ liệu. Trong Chương 7 chúng ta sẽ nới lỏng giả định đó và thảo luận về sharding (partitioning, phân mảnh) đối với các tập dữ liệu quá lớn cho một máy đơn. Trong các chương sau chúng ta sẽ thảo luận về các loại lỗi có thể xảy ra trong hệ thống dữ liệu được sao chép, và cách xử lý chúng.
Nếu dữ liệu bạn đang sao chép không thay đổi theo thời gian, thì replication rất đơn giản: bạn chỉ cần sao chép dữ liệu sang từng node một lần là xong. Toàn bộ sự khó khăn của replication nằm ở việc xử lý các thay đổi đối với dữ liệu đã được sao chép, và đó chính là chủ đề của chương này. Chúng ta sẽ thảo luận ba nhóm thuật toán để sao chép các thay đổi giữa các node: single-leader (một leader), multi-leader (nhiều leader), và leaderless (không có leader). Hầu hết mọi cơ sở dữ liệu phân tán đều sử dụng một trong ba phương pháp này. Mỗi phương pháp đều có ưu và nhược điểm riêng, mà chúng ta sẽ xem xét chi tiết.
Có nhiều đánh đổi cần cân nhắc khi sao chép dữ liệu: chẳng hạn, dùng replication đồng bộ hay bất đồng bộ, và cách xử lý các replica bị lỗi. Đây thường là các tùy chọn cấu hình trong cơ sở dữ liệu, và mặc dù chi tiết có thể khác nhau tùy từng cơ sở dữ liệu, các nguyên tắc chung là tương đồng trên nhiều cách triển khai khác nhau. Chúng ta sẽ thảo luận hệ quả của những lựa chọn như vậy trong chương này.
Replication của cơ sở dữ liệu là một chủ đề cũ, các nguyên tắc cơ bản hầu như không thay đổi từ khi được nghiên cứu vào những năm 1970 1, bởi vì các ràng buộc cơ bản của mạng vẫn không thay đổi. Mặc dù rất cũ, các khái niệm như eventual consistency (nhất quán cuối cùng) vẫn gây nhầm lẫn. Trong “Problems with Replication Lag” chúng ta sẽ làm rõ hơn về eventual consistency và thảo luận các đảm bảo như read-your-writes (đọc những gì bạn đã ghi) và monotonic reads (đọc đơn điệu).
BACKUPS AND REPLICATION
Bạn có thể tự hỏi liệu có cần backup nếu đã có replication hay không. Câu trả lời là có, bởi vì chúng phục vụ các mục đích khác nhau: các replica phản ánh nhanh các lần ghi từ node này sang node khác, nhưng backup lưu trữ các snapshot cũ của dữ liệu để bạn có thể quay ngược về quá khứ. Nếu bạn vô tình xóa dữ liệu, replication không giúp ích gì vì việc xóa đó cũng đã được truyền sang các replica, nên bạn cần backup để khôi phục dữ liệu đã xóa.
Thực ra, replication và backup thường bổ sung cho nhau. Backup đôi khi là một phần của quá trình thiết lập replication, như chúng ta sẽ thấy trong “Setting Up New Followers”. Ngược lại, lưu trữ lâu dài các replication log có thể là một phần của quy trình backup.
Một số cơ sở dữ liệu nội bộ duy trì các snapshot bất biến của các trạng thái trong quá khứ, đóng vai trò như một dạng backup nội bộ. Tuy nhiên, điều này có nghĩa là phải giữ các phiên bản dữ liệu cũ trên cùng phương tiện lưu trữ với trạng thái hiện tại. Nếu bạn có lượng dữ liệu lớn, có thể rẻ hơn khi lưu trữ backup dữ liệu cũ trên một object store được tối ưu cho dữ liệu ít được truy cập, và chỉ lưu trạng thái hiện tại của cơ sở dữ liệu trên bộ nhớ chính.
Single-Leader Replication
Mỗi node lưu trữ bản sao của cơ sở dữ liệu được gọi là một replica. Khi có nhiều replica, một câu hỏi không thể tránh khỏi xuất hiện: làm thế nào để đảm bảo rằng tất cả dữ liệu đều có mặt trên tất cả các replica?
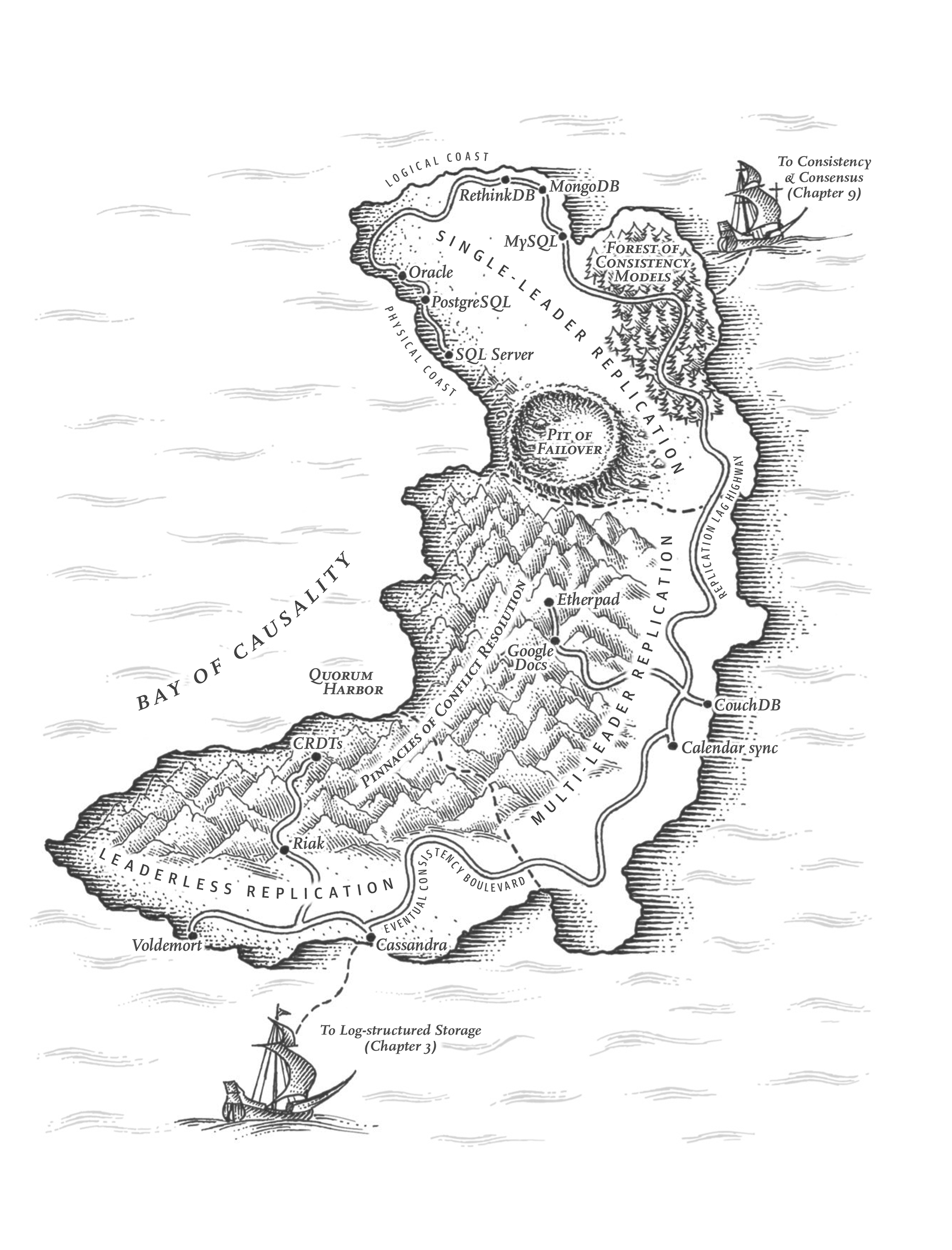
Mỗi lần ghi vào cơ sở dữ liệu cần được xử lý bởi mọi replica; nếu không, các replica sẽ không còn chứa cùng dữ liệu nữa. Giải pháp phổ biến nhất được gọi là leader-based replication (sao chép dựa trên leader), primary-backup (chính-dự phòng), hay active/passive (chủ động/thụ động). Cơ chế hoạt động như sau (xem Hình 6-1):
- Một trong các replica được chỉ định làm leader (còn gọi là primary hay source 2). Khi các client muốn ghi vào cơ sở dữ liệu, họ phải gửi yêu cầu đến leader, leader ghi dữ liệu mới vào bộ nhớ cục bộ của nó trước.
- Các replica còn lại được gọi là followers (read replicas, secondaries, hay hot standbys). Mỗi khi leader ghi dữ liệu mới vào bộ nhớ cục bộ, nó cũng gửi thay đổi dữ liệu đó đến tất cả các follower dưới dạng một replication log hay change stream. Mỗi follower lấy log từ leader và cập nhật bản sao cục bộ của cơ sở dữ liệu tương ứng, bằng cách áp dụng tất cả các lần ghi theo đúng thứ tự chúng được xử lý trên leader.
- Khi một client muốn đọc từ cơ sở dữ liệu, nó có thể truy vấn hoặc leader hoặc bất kỳ follower nào. Tuy nhiên, các lần ghi chỉ được chấp nhận trên leader (các follower là chỉ đọc từ góc nhìn của client).
Nếu cơ sở dữ liệu được sharded (xem Chương 7), mỗi shard có một leader. Các shard khác nhau có thể có leader trên các node khác nhau, nhưng mỗi shard vẫn phải có một node leader. Trong “Multi-Leader Replication” chúng ta sẽ thảo luận về một mô hình thay thế trong đó hệ thống có thể có nhiều leader cho cùng một shard cùng một lúc.
Single-leader replication được sử dụng rất rộng rãi. Đây là tính năng tích hợp sẵn của nhiều cơ sở dữ liệu quan hệ, chẳng hạn như PostgreSQL, MySQL, Oracle Data Guard 3, và SQL Server’s Always On Availability Groups 4. Nó cũng được dùng trong một số cơ sở dữ liệu tài liệu như MongoDB và DynamoDB 5, các message broker như Kafka, các block device được sao chép như DRBD, và một số network filesystem. Nhiều thuật toán đồng thuận như Raft, được dùng cho replication trong CockroachDB 6, TiDB 7, etcd, và RabbitMQ quorum queues (cùng nhiều hệ thống khác), cũng dựa trên một leader duy nhất, và tự động bầu chọn một leader mới nếu leader cũ bị lỗi (chúng ta sẽ thảo luận về đồng thuận chi tiết hơn trong Chương 10).
Note
Trong các tài liệu cũ bạn có thể thấy thuật ngữ master–slave replication. Nó có nghĩa tương tự leader-based replication, nhưng thuật ngữ này nên tránh dùng vì được coi là xúc phạm rộng rãi 8.
Synchronous Versus Asynchronous Replication
Một chi tiết quan trọng của hệ thống sao chép dữ liệu là liệu replication xảy ra đồng bộ (synchronously) hay bất đồng bộ (asynchronously). (Trong các cơ sở dữ liệu quan hệ, đây thường là tùy chọn có thể cấu hình; các hệ thống khác thường được mã hóa cứng theo một trong hai cách.)
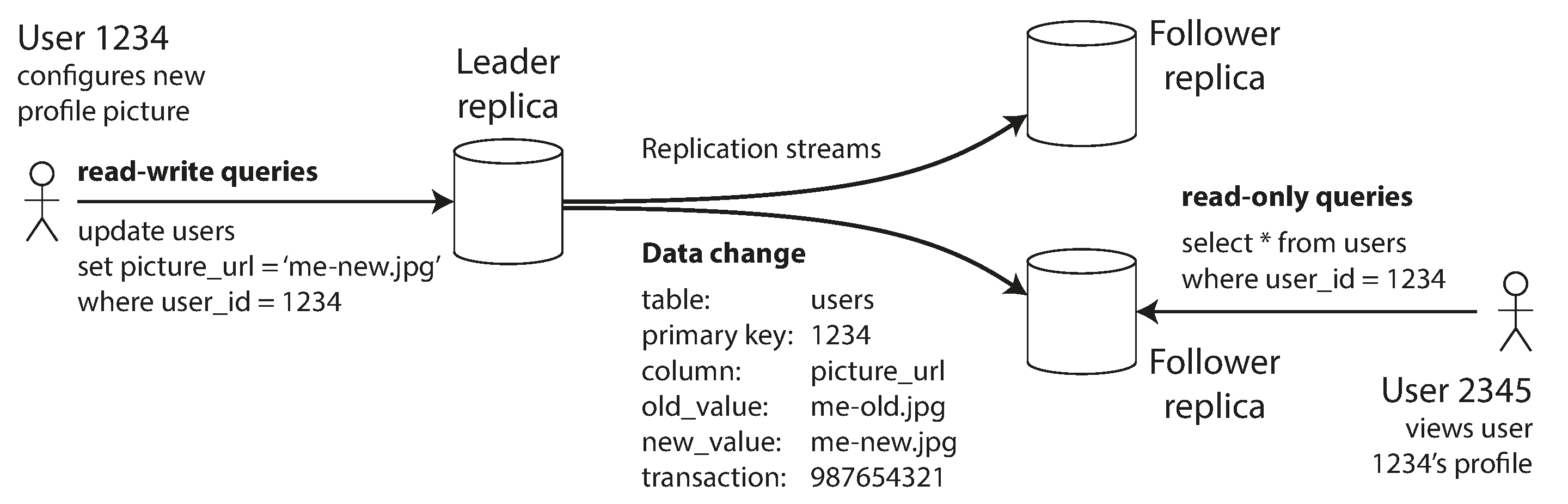
Hãy nghĩ về điều gì xảy ra trong Hình 6-1, khi người dùng của một trang web cập nhật ảnh đại diện của họ. Tại một thời điểm nào đó, client gửi yêu cầu cập nhật đến leader; sau đó ít lâu, leader nhận được yêu cầu. Tại một thời điểm nào đó, leader chuyển tiếp thay đổi dữ liệu đến các follower. Cuối cùng, leader thông báo cho client rằng cập nhật đã thành công. Hình 6-2 cho thấy một cách mà thời gian thực hiện có thể diễn ra.
Trong ví dụ của Hình 6-2, việc sao chép đến follower 1 là đồng bộ: leader chờ cho đến khi follower 1 xác nhận đã nhận được lần ghi trước khi báo cáo thành công cho người dùng, và trước khi làm cho lần ghi đó hiển thị với các client khác. Việc sao chép đến follower 2 là bất đồng bộ: leader gửi tin nhắn nhưng không chờ phản hồi từ follower.
Biểu đồ cho thấy có một độ trễ đáng kể trước khi follower 2 xử lý tin nhắn. Thông thường, replication khá nhanh: hầu hết các hệ thống cơ sở dữ liệu áp dụng thay đổi cho các follower trong chưa đầy một giây. Tuy nhiên, không có đảm bảo nào về thời gian thực hiện. Có những trường hợp các follower có thể trễ sau leader vài phút hoặc hơn; chẳng hạn, nếu follower đang phục hồi từ một lỗi, nếu hệ thống đang hoạt động gần mức tối đa, hoặc nếu có sự cố mạng giữa các node.
Ưu điểm của replication đồng bộ là follower được đảm bảo có bản sao dữ liệu cập nhật nhất quán với leader. Nếu leader đột ngột bị lỗi, chúng ta có thể chắc chắn rằng dữ liệu vẫn còn trên follower. Nhược điểm là nếu follower đồng bộ không phản hồi (vì nó đã crash, có lỗi mạng, hoặc bất kỳ lý do nào khác), lần ghi không thể được xử lý. Leader phải chặn tất cả các lần ghi và chờ cho đến khi replica đồng bộ sẵn sàng trở lại.
Vì lý do đó, không khả thi để tất cả các follower đều đồng bộ: bất kỳ một node nào ngừng hoạt động sẽ khiến toàn bộ hệ thống dừng lại. Trong thực tế, nếu cơ sở dữ liệu cung cấp replication đồng bộ, thường có nghĩa là một trong các follower là đồng bộ, còn những follower khác là bất đồng bộ. Nếu follower đồng bộ trở nên không khả dụng hoặc chậm, một trong các follower bất đồng bộ sẽ được chuyển thành đồng bộ. Điều này đảm bảo rằng bạn có bản sao dữ liệu cập nhật trên ít nhất hai node: leader và một follower đồng bộ. Cấu hình này đôi khi còn được gọi là semi-synchronous (bán đồng bộ).
Trong một số hệ thống, đa số (ví dụ: 3 trong 5 replica, bao gồm cả leader) của các replica được cập nhật đồng bộ, và phần thiểu số còn lại là bất đồng bộ. Đây là một ví dụ về quorum (túc số), mà chúng ta sẽ thảo luận thêm trong “Quorums for reading and writing”. Quorum đa số thường được dùng trong các hệ thống sử dụng giao thức đồng thuận cho việc bầu leader tự động, mà chúng ta sẽ quay lại trong Chương 10.
Đôi khi, leader-based replication được cấu hình hoàn toàn bất đồng bộ. Trong trường hợp này, nếu leader bị lỗi và không thể phục hồi, bất kỳ lần ghi nào chưa được sao chép đến các follower sẽ bị mất. Điều này có nghĩa là một lần ghi không được đảm bảo là bền vững, ngay cả khi nó đã được xác nhận với client. Tuy nhiên, cấu hình bất đồng bộ hoàn toàn có ưu điểm là leader có thể tiếp tục xử lý các lần ghi, ngay cả khi tất cả các follower đã tụt hậu.
Việc giảm bớt độ bền có vẻ là một đánh đổi tệ, nhưng replication bất đồng bộ vẫn được sử dụng rộng rãi, đặc biệt khi có nhiều follower hoặc khi chúng được phân bổ về mặt địa lý 9. Chúng ta sẽ quay lại vấn đề này trong “Problems with Replication Lag”.
Setting Up New Followers
Theo thời gian, bạn cần thiết lập các follower mới, có thể để tăng số lượng replica, hoặc để thay thế các node bị lỗi. Làm thế nào để đảm bảo rằng follower mới có bản sao chính xác của dữ liệu leader?
Chỉ đơn giản là sao chép các file dữ liệu từ node này sang node khác thường là không đủ: các client liên tục ghi vào cơ sở dữ liệu, và dữ liệu luôn thay đổi, vì vậy một thao tác sao chép file thông thường sẽ thấy các phần khác nhau của cơ sở dữ liệu tại các thời điểm khác nhau. Kết quả có thể không nhất quán.
Bạn có thể làm cho các file trên đĩa nhất quán bằng cách khóa cơ sở dữ liệu (làm cho nó không thể ghi được), nhưng điều đó đi ngược lại mục tiêu về tính sẵn sàng cao. May mắn thay, thiết lập một follower thường có thể được thực hiện mà không cần downtime. Về mặt khái niệm, quy trình trông như sau:
- Lấy một snapshot nhất quán của cơ sở dữ liệu leader tại một thời điểm nào đó, nếu có thể, mà không cần khóa toàn bộ cơ sở dữ liệu. Hầu hết cơ sở dữ liệu đều có tính năng này, vì nó cũng cần thiết cho backup. Trong một số trường hợp cần các công cụ bên thứ ba, chẳng hạn như Percona XtraBackup cho MySQL.
- Sao chép snapshot đến node follower mới.
- Follower kết nối với leader và yêu cầu tất cả các thay đổi dữ liệu đã xảy ra kể từ khi snapshot được lấy. Điều này yêu cầu snapshot phải được liên kết với một vị trí chính xác trong replication log của leader. Vị trí đó có nhiều tên khác nhau: chẳng hạn, PostgreSQL gọi nó là log sequence number; MySQL có hai cơ chế, binlog coordinates và global transaction identifiers (GTIDs).
- Khi follower đã xử lý xong toàn bộ tồn đọng các thay đổi dữ liệu kể từ snapshot, chúng ta nói nó đã bắt kịp (caught up). Lúc này nó có thể tiếp tục xử lý các thay đổi dữ liệu từ leader khi chúng xảy ra.
Các bước thực tế để thiết lập một follower có thể khác nhau đáng kể tùy từng cơ sở dữ liệu. Trong một số hệ thống, quy trình được tự động hóa hoàn toàn, trong khi ở những hệ thống khác nó có thể là một quy trình nhiều bước khó hiểu cần được quản trị viên thực hiện thủ công.
Bạn cũng có thể lưu trữ lâu dài replication log vào một object store; cùng với các snapshot định kỳ của toàn bộ cơ sở dữ liệu trong object store, đây là cách tốt để triển khai backup cơ sở dữ liệu và khôi phục sau thảm họa. Bạn cũng có thể thực hiện bước 1 và 2 của việc thiết lập follower mới bằng cách tải xuống các file từ object store. Chẳng hạn, WAL-G làm điều này cho PostgreSQL, MySQL, và SQL Server, còn Litestream làm tương tự cho SQLite.
DATABASES BACKED BY OBJECT STORAGE
Object storage có thể được dùng cho nhiều hơn là lưu trữ lâu dài dữ liệu. Nhiều cơ sở dữ liệu đang bắt đầu sử dụng các object store như Amazon Web Services S3, Google Cloud Storage, và Azure Blob Storage để phục vụ dữ liệu cho các truy vấn trực tiếp. Lưu trữ dữ liệu cơ sở dữ liệu trong object storage có nhiều lợi ích:
- Object storage rẻ hơn so với các tùy chọn lưu trữ đám mây khác, cho phép các cơ sở dữ liệu đám mây lưu dữ liệu ít được truy vấn hơn trên bộ nhớ rẻ hơn, độ trễ cao hơn, trong khi phục vụ working set từ bộ nhớ, SSD, và NVMe.
- Object store cũng cung cấp replication multi-zone, dual-region, hoặc multi-region với các đảm bảo độ bền rất cao. Điều này cũng cho phép cơ sở dữ liệu bỏ qua các chi phí mạng liên vùng.
- Cơ sở dữ liệu có thể dùng tính năng conditional write (ghi có điều kiện) của object store, về bản chất là thao tác compare-and-set (CAS), để triển khai transaction và bầu chọn leader 10 11
- Lưu trữ dữ liệu từ nhiều cơ sở dữ liệu trong cùng một object store có thể đơn giản hóa việc tích hợp dữ liệu, đặc biệt khi sử dụng các định dạng mở như Apache Parquet và Apache Iceberg.
Những lợi ích này giúp đơn giản hóa đáng kể kiến trúc cơ sở dữ liệu bằng cách chuyển trách nhiệm xử lý transaction, bầu chọn leader, và replication sang object storage.
Các hệ thống áp dụng object storage cho replication phải đối mặt với một số đánh đổi. Đáng chú ý, object store có độ trễ đọc và ghi cao hơn nhiều so với đĩa cục bộ hay các block device ảo như EBS. Nhiều nhà cung cấp đám mây cũng tính phí theo số lần gọi API, buộc các hệ thống phải đóng gói (batch) các thao tác đọc và ghi để giảm chi phí. Việc đóng gói như vậy làm tăng thêm độ trễ. Hơn nữa, nhiều object store không cung cấp giao diện filesystem tiêu chuẩn. Điều này ngăn các hệ thống thiếu tích hợp object storage tận dụng được object storage. Các giao diện như filesystem in userspace (FUSE) cho phép người vận hành mount các bucket của object store dưới dạng filesystem mà ứng dụng có thể dùng mà không biết dữ liệu của chúng được lưu trên object storage. Tuy nhiên, nhiều giao diện FUSE với object store thiếu các tính năng POSIX như ghi không tuần tự hay symlink, mà các hệ thống có thể phụ thuộc vào.
Các hệ thống khác nhau xử lý những đánh đổi này theo nhiều cách. Một số áp dụng kiến trúc tiered storage (lưu trữ phân tầng) đặt dữ liệu ít được truy cập hơn trên object storage trong khi dữ liệu mới hoặc thường xuyên được truy cập được giữ trên các thiết bị lưu trữ nhanh hơn như SSD, NVMe, hoặc thậm chí trong bộ nhớ. Các hệ thống khác dùng object storage làm tầng lưu trữ chính, nhưng sử dụng một hệ thống lưu trữ độ trễ thấp riêng biệt như Amazon EBS hay Neon’s Safekeepers 12) để lưu WAL. Gần đây, một số hệ thống đã tiến xa hơn bằng cách áp dụng kiến trúc zero-disk architecture (ZDA). Các hệ thống dựa trên ZDA lưu trữ tất cả dữ liệu vào object storage và chỉ dùng đĩa và bộ nhớ cho mục đích caching. Điều này cho phép các node không có trạng thái lưu trữ bền vững, giúp đơn giản hóa đáng kể vận hành. WarpStream, Confluent Freight, Buf’s Bufstream, và Redpanda Serverless đều là các hệ thống tương thích Kafka được xây dựng theo kiến trúc zero-disk. Hầu hết mọi data warehouse đám mây hiện đại cũng áp dụng kiến trúc như vậy, cũng như Turbopuffer (một search engine vector), và SlateDB (một storage engine LSM cloud-native).
Handling Node Outages
Bất kỳ node nào trong hệ thống đều có thể ngừng hoạt động, đôi khi là bất ngờ do lỗi, nhưng cũng có thể là do bảo trì theo kế hoạch (ví dụ: khởi động lại máy để cài đặt bản vá bảo mật kernel). Khả năng khởi động lại từng node riêng lẻ mà không cần downtime là một lợi thế lớn cho vận hành và bảo trì. Vì vậy, mục tiêu của chúng ta là giữ cho toàn hệ thống tiếp tục hoạt động dù có lỗi node riêng lẻ, và giảm thiểu tác động của việc một node ngừng hoạt động.
Làm thế nào để đạt được tính sẵn sàng cao với leader-based replication?
Follower failure: Catch-up recovery
Trên đĩa cục bộ của nó, mỗi follower lưu một log về các thay đổi dữ liệu nó đã nhận từ leader. Nếu một follower bị crash và được khởi động lại, hoặc nếu mạng giữa leader và follower bị gián đoạn tạm thời, follower có thể phục hồi khá dễ dàng: từ log của nó, nó biết giao dịch cuối cùng được xử lý trước khi xảy ra lỗi. Vì vậy, follower có thể kết nối với leader và yêu cầu tất cả các thay đổi dữ liệu xảy ra trong thời gian follower bị ngắt kết nối. Khi nó đã áp dụng những thay đổi này, nó đã bắt kịp leader và có thể tiếp tục nhận luồng thay đổi dữ liệu như trước.
Mặc dù việc phục hồi follower về mặt khái niệm là đơn giản, nhưng có thể gặp thách thức về hiệu năng: nếu cơ sở dữ liệu có throughput ghi cao hoặc nếu follower đã offline trong thời gian dài, có thể có nhiều lần ghi cần bắt kịp. Sẽ có tải cao trên cả follower đang phục hồi và leader (cần phải gửi tồn đọng các lần ghi cho follower) trong khi quá trình bắt kịp đang diễn ra.
Leader có thể xóa log các lần ghi của nó khi tất cả các follower đã xác nhận đã xử lý chúng, nhưng nếu một follower không khả dụng trong thời gian dài, leader phải đưa ra lựa chọn: hoặc giữ lại log cho đến khi follower phục hồi và bắt kịp (với nguy cơ hết dung lượng đĩa trên leader), hoặc xóa log mà follower không khả dụng chưa xác nhận (trong trường hợp đó follower sẽ không thể phục hồi từ log và sẽ phải được khôi phục từ backup khi quay trở lại).
Leader failure: Failover
Xử lý lỗi của leader phức tạp hơn: một trong các follower cần được thăng cấp thành leader mới, các client cần được cấu hình lại để gửi các lần ghi đến leader mới, và các follower còn lại cần bắt đầu tiêu thụ các thay đổi dữ liệu từ leader mới. Quá trình này được gọi là failover (chuyển đổi dự phòng).
Failover có thể xảy ra thủ công (một quản trị viên được thông báo rằng leader đã bị lỗi và thực hiện các bước cần thiết để tạo leader mới) hoặc tự động. Một quy trình failover tự động thường bao gồm các bước sau:
- Xác định rằng leader đã bị lỗi. Có nhiều thứ có thể xảy ra sự cố: crash, mất điện, sự cố mạng, và nhiều hơn nữa. Không có cách nào chắc chắn để phát hiện điều gì đã xảy ra sai, vì vậy hầu hết các hệ thống chỉ đơn giản là dùng timeout: các node thường xuyên trao đổi tin nhắn với nhau, và nếu một node không phản hồi trong một khoảng thời gian nhất định, chẳng hạn 30 giây, nó được coi là đã chết. (Nếu leader được cố tình đưa xuống để bảo trì theo kế hoạch, điều này không áp dụng.)
- Chọn một leader mới. Điều này có thể được thực hiện qua quy trình bầu chọn (leader được chọn bởi đa số các replica còn lại), hoặc một leader mới có thể được bổ nhiệm bởi một controller node (node điều phối) đã được thiết lập trước 13. Ứng cử viên tốt nhất cho vị trí leader thường là replica có các thay đổi dữ liệu cập nhật nhất từ leader cũ (để giảm thiểu mất mát dữ liệu). Việc làm cho tất cả các node đồng ý về leader mới là một bài toán đồng thuận, được thảo luận chi tiết trong Chương 10.
- Cấu hình lại hệ thống để sử dụng leader mới. Các client bây giờ cần gửi các yêu cầu ghi của họ đến leader mới (chúng ta thảo luận về điều này trong “Request Routing”). Nếu leader cũ quay trở lại, nó có thể vẫn tin rằng mình là leader, không nhận ra rằng các replica khác đã buộc nó phải từ chức. Hệ thống cần đảm bảo rằng leader cũ trở thành follower và nhận ra leader mới.
Failover có nhiều điều có thể xảy ra sai:
- Nếu replication bất đồng bộ được sử dụng, leader mới có thể chưa nhận được tất cả các lần ghi từ leader cũ trước khi leader cũ bị lỗi. Nếu leader cũ tái gia nhập cluster sau khi leader mới đã được chọn, điều gì sẽ xảy ra với những lần ghi đó? Leader mới có thể đã nhận được các lần ghi xung đột trong thời gian chờ. Giải pháp phổ biến nhất là các lần ghi chưa được sao chép của leader cũ đơn giản là bị loại bỏ, điều đó có nghĩa là các lần ghi mà bạn tin là đã được commit thực ra không bền vững.
- Việc loại bỏ các lần ghi đặc biệt nguy hiểm nếu các hệ thống lưu trữ khác ngoài cơ sở dữ liệu cần được điều phối với nội dung cơ sở dữ liệu. Chẳng hạn, trong một sự cố tại GitHub 14, một follower MySQL lỗi thời đã được thăng cấp thành leader. Cơ sở dữ liệu dùng bộ đếm tự tăng để gán khóa chính cho các hàng mới, nhưng vì bộ đếm của leader mới tụt hậu so với leader cũ, nó đã dùng lại một số khóa chính đã được gán trước đó bởi leader cũ. Các khóa chính này cũng được dùng trong một Redis store, vì vậy việc dùng lại khóa chính dẫn đến sự không nhất quán giữa MySQL và Redis, gây ra việc một số dữ liệu riêng tư bị tiết lộ cho người dùng sai.
- Trong một số kịch bản lỗi nhất định (xem Chương 9), có thể xảy ra tình huống hai node đều tin rằng mình là leader. Tình trạng này được gọi là split brain (não phân đôi), và nó rất nguy hiểm: nếu cả hai leader đều chấp nhận lần ghi, và không có quy trình để giải quyết xung đột (xem “Multi-Leader Replication”), dữ liệu có thể bị mất hoặc bị hỏng. Như một biện pháp an toàn, một số hệ thống có cơ chế tắt một node nếu phát hiện hai leader. Tuy nhiên, nếu cơ chế này không được thiết kế cẩn thận, bạn có thể kết thúc với cả hai node đều bị tắt 15. Hơn nữa, có nguy cơ là đến khi split brain được phát hiện và node cũ bị tắt, đã quá muộn và dữ liệu đã bị hỏng.
- Timeout phù hợp trước khi leader được tuyên bố là chết là bao lâu? Timeout dài hơn có nghĩa là thời gian phục hồi lâu hơn trong trường hợp leader bị lỗi. Tuy nhiên, nếu timeout quá ngắn, có thể xảy ra failover không cần thiết. Chẳng hạn, một đợt tải đột biến tạm thời có thể khiến thời gian phản hồi của node vượt quá timeout, hoặc một sự cố mạng có thể gây ra các gói tin bị trễ. Nếu hệ thống đang gặp khó khăn với tải cao hoặc sự cố mạng, một failover không cần thiết có khả năng làm tình hình tệ hơn, không phải tốt hơn.
Note
Bảo vệ chống split brain bằng cách giới hạn hoặc tắt các leader cũ được gọi là fencing (rào chắn) hay, nhấn mạnh hơn, Shoot The Other Node In The Head (STONITH, bắn node kia vào đầu). Chúng ta sẽ thảo luận fencing chi tiết hơn trong “Distributed Locks and Leases”.
Không có giải pháp dễ dàng nào cho những vấn đề này. Vì lý do này, một số nhóm vận hành thích thực hiện failover thủ công, ngay cả khi phần mềm hỗ trợ failover tự động.
Điều quan trọng nhất với failover là chọn một follower cập nhật làm leader mới, nếu replication đồng bộ hoặc bán đồng bộ được sử dụng, đây sẽ là follower mà leader cũ đã chờ trước khi xác nhận các lần ghi. Với replication bất đồng bộ, bạn có thể chọn follower có log sequence number lớn nhất. Điều này giảm thiểu lượng dữ liệu bị mất trong quá trình failover: mất một phần nhỏ của giây ghi có thể chấp nhận được, nhưng chọn một follower tụt hậu vài ngày có thể là thảm họa.
Những vấn đề này, lỗi node, mạng không đáng tin cậy, và các đánh đổi về tính nhất quán replica, độ bền, tính sẵn sàng, và độ trễ, thực ra là những vấn đề cơ bản trong các hệ thống phân tán. Trong Chương 9 và Chương 10 chúng ta sẽ thảo luận chúng sâu hơn.
Implementation of Replication Logs
Leader-based replication hoạt động như thế nào bên dưới? Nhiều phương pháp replication khác nhau được dùng trong thực tế, vì vậy hãy xem xét sơ qua từng phương pháp.
Statement-based replication
Trong trường hợp đơn giản nhất, leader ghi lại mỗi yêu cầu ghi (statement, câu lệnh) mà nó thực thi và gửi log câu lệnh đó đến các follower. Đối với cơ sở dữ liệu quan hệ, điều này có nghĩa là mỗi câu lệnh INSERT, UPDATE, hay DELETE được chuyển tiếp đến các follower, và mỗi follower phân tích và thực thi câu lệnh SQL đó như thể nó được nhận từ một client.
Mặc dù điều này nghe có vẻ hợp lý, nhưng có nhiều cách mà phương pháp replication này có thể thất bại:
- Bất kỳ câu lệnh nào gọi một hàm không xác định (nondeterministic), chẳng hạn như
NOW()để lấy ngày giờ hiện tại hayRAND()để lấy số ngẫu nhiên, có khả năng tạo ra giá trị khác nhau trên mỗi replica. - Nếu các câu lệnh dùng cột tự tăng, hoặc nếu chúng phụ thuộc vào dữ liệu hiện có trong cơ sở dữ liệu (ví dụ:
UPDATE … WHERE <một điều kiện>), chúng phải được thực thi theo đúng thứ tự trên mỗi replica, nếu không chúng có thể có tác động khác nhau. Điều này có thể bị giới hạn khi có nhiều transaction được thực thi đồng thời. - Các câu lệnh có tác dụng phụ (ví dụ: trigger, stored procedure, hàm do người dùng định nghĩa) có thể dẫn đến các tác dụng phụ khác nhau xảy ra trên mỗi replica, trừ khi tác dụng phụ hoàn toàn xác định.
Có thể giải quyết những vấn đề đó, chẳng hạn, leader có thể thay thế bất kỳ lời gọi hàm không xác định nào bằng một giá trị trả về cố định khi câu lệnh được ghi vào log để tất cả các follower đều nhận được cùng giá trị. Ý tưởng thực thi các câu lệnh xác định theo thứ tự cố định tương tự với mô hình event sourcing mà chúng ta đã thảo luận trước đây trong “Event Sourcing and CQRS”. Phương pháp này còn được gọi là state machine replication (sao chép máy trạng thái), và chúng ta sẽ thảo luận lý thuyết đằng sau nó trong “Using shared logs”.
Statement-based replication được dùng trong MySQL trước phiên bản 5.1. Nó vẫn đôi khi được dùng ngày nay vì khá gọn nhẹ, nhưng theo mặc định MySQL hiện nay chuyển sang row-based replication (sẽ được thảo luận ngay sau) nếu có bất kỳ tính không xác định nào trong một câu lệnh. VoltDB dùng statement-based replication, và làm cho nó an toàn bằng cách yêu cầu các transaction phải xác định 16. Tuy nhiên, tính xác định có thể khó đảm bảo trong thực tế, vì vậy nhiều cơ sở dữ liệu thích các phương pháp replication khác.
Write-ahead log (WAL) shipping
Trong Chương 4 chúng ta đã thấy rằng write-ahead log cần thiết để làm cho các storage engine B-tree trở nên đáng tin cậy: mỗi sửa đổi đầu tiên được ghi vào WAL để cây có thể được khôi phục về trạng thái nhất quán sau khi crash. Vì WAL chứa tất cả thông tin cần thiết để khôi phục các index và heap về trạng thái nhất quán, chúng ta có thể dùng cùng log đó để xây dựng một replica trên node khác: bên cạnh việc ghi log vào đĩa, leader cũng gửi nó qua mạng đến các follower. Khi follower xử lý log này, nó xây dựng một bản sao của các file giống hệt như trên leader.
Phương pháp replication này được dùng trong PostgreSQL và Oracle, cùng nhiều hệ thống khác 17 18. Nhược điểm chính là log mô tả dữ liệu ở mức rất thấp: một WAL chứa chi tiết về những byte nào đã thay đổi trong những block đĩa nào. Điều này làm cho replication gắn chặt với storage engine. Nếu cơ sở dữ liệu thay đổi định dạng lưu trữ từ phiên bản này sang phiên bản khác, thông thường không thể chạy các phiên bản phần mềm cơ sở dữ liệu khác nhau trên leader và các follower.
Điều đó có vẻ là một chi tiết triển khai nhỏ, nhưng có thể có tác động vận hành lớn. Nếu giao thức replication cho phép follower dùng phiên bản phần mềm mới hơn leader, bạn có thể thực hiện nâng cấp phần mềm cơ sở dữ liệu không có downtime bằng cách trước tiên nâng cấp các follower và sau đó thực hiện failover để làm một trong các node đã nâng cấp thành leader mới. Nếu giao thức replication không cho phép sự không khớp phiên bản này, như thường thấy với WAL shipping, các nâng cấp như vậy yêu cầu downtime.
Logical (row-based) log replication
Một giải pháp thay thế là dùng các định dạng log khác nhau cho replication và cho storage engine, điều đó cho phép replication log được tách rời khỏi nội bộ storage engine. Loại replication log này được gọi là logical log (log logic), để phân biệt với biểu diễn dữ liệu (vật lý) của storage engine.
Một logical log cho cơ sở dữ liệu quan hệ thường là một chuỗi các bản ghi mô tả các lần ghi vào bảng cơ sở dữ liệu ở mức độ chi tiết của một hàng:
- Đối với hàng được chèn, log chứa các giá trị mới của tất cả các cột.
- Đối với hàng bị xóa, log chứa đủ thông tin để xác định duy nhất hàng đã bị xóa. Thông thường đây sẽ là khóa chính, nhưng nếu bảng không có khóa chính, các giá trị cũ của tất cả các cột cần được ghi lại.
- Đối với hàng được cập nhật, log chứa đủ thông tin để xác định duy nhất hàng được cập nhật, và các giá trị mới của tất cả các cột (hoặc ít nhất là các giá trị mới của tất cả các cột đã thay đổi).
Một transaction sửa đổi nhiều hàng tạo ra nhiều bản ghi log như vậy, theo sau là một bản ghi cho biết transaction đã được commit. MySQL duy trì một replication log logic riêng biệt, được gọi là binlog, ngoài WAL (khi được cấu hình để dùng row-based replication). PostgreSQL triển khai logical replication bằng cách giải mã WAL vật lý thành các sự kiện chèn/cập nhật/xóa hàng 19.
Vì logical log được tách rời khỏi nội bộ storage engine, nó có thể dễ dàng được giữ tương thích ngược hơn, cho phép leader và follower chạy các phiên bản phần mềm cơ sở dữ liệu khác nhau. Điều này đến lượt nó cho phép nâng cấp lên phiên bản mới với thời gian downtime tối thiểu 20.
Định dạng logical log cũng dễ phân tích hơn cho các ứng dụng bên ngoài. Khía cạnh này hữu ích nếu bạn muốn gửi nội dung của cơ sở dữ liệu đến một hệ thống bên ngoài, chẳng hạn như một data warehouse để phân tích offline, hoặc để xây dựng các index và cache tùy chỉnh 21. Kỹ thuật này được gọi là change data capture (thu thập thay đổi dữ liệu), và chúng ta sẽ quay lại nó trong “Change Data Capture”.
Problems with Replication Lag
Khả năng chịu đựng lỗi node chỉ là một lý do để muốn replication. Như đã đề cập trong “Distributed versus Single-Node Systems”, các lý do khác là khả năng mở rộng (xử lý nhiều yêu cầu hơn so với một máy đơn có thể xử lý) và độ trễ (đặt các replica gần hơn về mặt địa lý với người dùng).
Leader-based replication yêu cầu tất cả các lần ghi đi qua một node duy nhất, nhưng các truy vấn chỉ đọc có thể đến bất kỳ replica nào. Đối với các workload chủ yếu là đọc và chỉ có một tỷ lệ nhỏ là ghi (thường thấy với các dịch vụ trực tuyến), có một lựa chọn hấp dẫn: tạo nhiều follower, và phân phối các yêu cầu đọc trên các follower đó. Điều này giảm tải cho leader và cho phép các yêu cầu đọc được phục vụ bởi các replica gần hơn.
Trong kiến trúc read-scaling này, bạn có thể tăng công suất phục vụ các yêu cầu chỉ đọc đơn giản bằng cách thêm nhiều follower hơn. Tuy nhiên, phương pháp này chỉ thực sự hoạt động với replication bất đồng bộ, nếu bạn cố gắng đồng bộ sao chép đến tất cả các follower, một lỗi node duy nhất hoặc gián đoạn mạng sẽ làm cho toàn bộ hệ thống không thể ghi được. Và càng có nhiều node, càng có khả năng một trong số chúng sẽ bị lỗi, vì vậy cấu hình đồng bộ hoàn toàn sẽ rất không đáng tin cậy.
Thật không may, nếu một ứng dụng đọc từ một follower bất đồng bộ, nó có thể thấy thông tin lỗi thời nếu follower đã tụt hậu. Điều này dẫn đến sự không nhất quán rõ ràng trong cơ sở dữ liệu: nếu bạn chạy cùng một truy vấn trên leader và một follower cùng lúc, bạn có thể nhận được kết quả khác nhau, vì không phải tất cả các lần ghi đã được phản ánh trong follower. Sự không nhất quán này chỉ là trạng thái tạm thời, nếu bạn ngừng ghi vào cơ sở dữ liệu và chờ một lúc, các follower cuối cùng sẽ bắt kịp và trở nên nhất quán với leader. Vì lý do đó, hiệu ứng này được gọi là eventual consistency (nhất quán cuối cùng) 22.
Note
Thuật ngữ eventual consistency được đặt ra bởi Douglas Terry và cộng sự 23, được phổ biến bởi Werner Vogels 24, và đã trở thành khẩu hiệu của nhiều dự án NoSQL. Tuy nhiên, không chỉ các cơ sở dữ liệu NoSQL mới có tính nhất quán cuối cùng: các follower trong cơ sở dữ liệu quan hệ được sao chép bất đồng bộ cũng có các đặc điểm tương tự.
Từ “eventually” (cuối cùng) cố tình mơ hồ: nói chung, không có giới hạn nào về mức độ một replica có thể tụt hậu. Trong điều kiện bình thường, độ trễ giữa một lần ghi xảy ra trên leader và được phản ánh trên follower, gọi là replication lag (độ trễ sao chép), có thể chỉ là một phần của giây, và không đáng chú ý trong thực tế. Tuy nhiên, nếu hệ thống đang hoạt động gần mức công suất hoặc nếu có sự cố mạng, lag có thể dễ dàng tăng lên đến vài giây hoặc thậm chí vài phút.
Khi lag lớn như vậy, những sự không nhất quán nó tạo ra không chỉ là vấn đề lý thuyết mà còn là vấn đề thực sự cho các ứng dụng. Trong phần này chúng ta sẽ nêu bật ba ví dụ về các vấn đề có khả năng xảy ra khi có replication lag. Chúng ta cũng sẽ phác thảo một số cách tiếp cận để giải quyết chúng.
Reading Your Own Writes
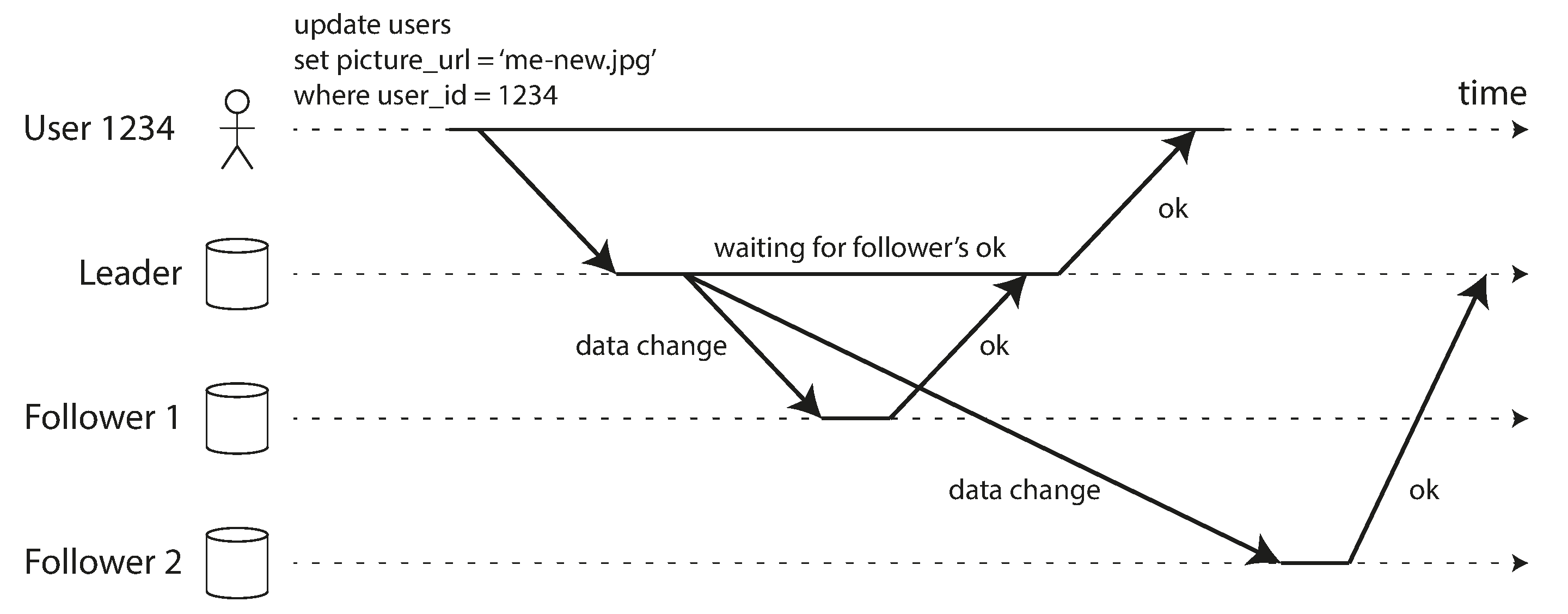
Nhiều ứng dụng cho phép người dùng gửi một số dữ liệu và sau đó xem những gì họ đã gửi. Đây có thể là một bản ghi trong cơ sở dữ liệu khách hàng, hoặc một bình luận trên một luồng thảo luận, hoặc thứ gì đó tương tự. Khi dữ liệu mới được gửi, nó phải được gửi đến leader, nhưng khi người dùng xem dữ liệu, nó có thể được đọc từ một follower. Điều này đặc biệt phù hợp nếu dữ liệu thường xuyên được xem nhưng chỉ đôi khi được ghi.
Với replication bất đồng bộ, có một vấn đề được minh họa trong Hình 6-3: nếu người dùng xem dữ liệu ngay sau khi thực hiện một lần ghi, dữ liệu mới có thể chưa đến được replica. Với người dùng, có vẻ như dữ liệu họ đã gửi đã bị mất, vì vậy họ sẽ không hài lòng một cách dễ hiểu.
Trong tình huống này, chúng ta cần read-after-write consistency (nhất quán đọc-sau-ghi), còn được gọi là read-your-writes consistency 23. Đây là đảm bảo rằng nếu người dùng tải lại trang, họ sẽ luôn thấy bất kỳ cập nhật nào họ đã tự gửi. Nó không đưa ra lời hứa nào về các người dùng khác: các cập nhật của người dùng khác có thể không hiển thị cho đến một thời điểm sau đó. Tuy nhiên, nó đảm bảo với người dùng rằng input của họ đã được lưu đúng cách.
Làm thế nào để triển khai read-after-write consistency trong hệ thống với leader-based replication? Có nhiều kỹ thuật có thể. Để đề cập một vài:
- Khi đọc thứ gì đó mà người dùng có thể đã sửa đổi, hãy đọc từ leader hoặc một follower được cập nhật đồng bộ; nếu không, đọc từ một follower được cập nhật bất đồng bộ. Điều này yêu cầu bạn có cách nào đó biết liệu thứ gì đó có thể đã được sửa đổi hay không, mà không thực sự truy vấn nó. Chẳng hạn, thông tin hồ sơ người dùng trên mạng xã hội thường chỉ có thể chỉnh sửa bởi chủ sở hữu hồ sơ, không phải bất kỳ ai khác. Vì vậy, một quy tắc đơn giản là: luôn đọc hồ sơ của người dùng từ leader, và hồ sơ của bất kỳ người dùng nào khác từ follower.
- Nếu hầu hết mọi thứ trong ứng dụng đều có khả năng được chỉnh sửa bởi người dùng, phương pháp đó sẽ không hiệu quả, vì hầu hết mọi thứ sẽ phải được đọc từ leader (phủ nhận lợi ích của read scaling). Trong trường hợp đó, các tiêu chí khác có thể được dùng để quyết định xem có đọc từ leader hay không. Chẳng hạn, bạn có thể theo dõi thời gian của lần cập nhật cuối cùng và, trong vòng một phút sau lần cập nhật cuối cùng, thực hiện tất cả các lần đọc từ leader 25. Bạn cũng có thể theo dõi replication lag trên các follower và ngăn các truy vấn trên bất kỳ follower nào tụt hậu hơn một phút so với leader.
- Client có thể nhớ timestamp của lần ghi gần nhất của nó, sau đó hệ thống có thể đảm bảo rằng replica phục vụ bất kỳ lần đọc nào cho người dùng đó phản ánh các cập nhật ít nhất cho đến timestamp đó. Nếu một replica không đủ cập nhật, hoặc lần đọc có thể được xử lý bởi một replica khác hoặc truy vấn có thể chờ cho đến khi replica đã bắt kịp 26. Timestamp có thể là một logical timestamp (cái gì đó chỉ ra thứ tự của các lần ghi, chẳng hạn như log sequence number) hoặc đồng hồ hệ thống thực tế (trong trường hợp đó đồng bộ hóa đồng hồ trở nên quan trọng; xem “Unreliable Clocks”).
- Nếu các replica của bạn được phân phối trên nhiều region (để gần hơn về mặt địa lý với người dùng hoặc để đạt tính sẵn sàng), có thêm độ phức tạp. Bất kỳ yêu cầu nào cần được phục vụ bởi leader phải được định tuyến đến region chứa leader.
Một vấn đề phức tạp khác xuất hiện khi cùng một người dùng truy cập dịch vụ của bạn từ nhiều thiết bị, chẳng hạn như trình duyệt web máy tính và ứng dụng di động. Trong trường hợp này bạn có thể muốn cung cấp cross-device read-after-write consistency: nếu người dùng nhập một số thông tin trên một thiết bị và sau đó xem nó trên thiết bị khác, họ sẽ thấy thông tin họ vừa nhập.
Trong trường hợp này, có một số vấn đề bổ sung cần xem xét:
- Các phương pháp yêu cầu nhớ timestamp của lần cập nhật cuối cùng của người dùng trở nên khó khăn hơn, vì mã chạy trên một thiết bị không biết các cập nhật nào đã xảy ra trên thiết bị kia. Metadata này sẽ cần phải được tập trung hóa.
- Nếu các replica của bạn được phân phối trên các region khác nhau, không có đảm bảo rằng các kết nối từ các thiết bị khác nhau sẽ được định tuyến đến cùng một region. (Chẳng hạn, nếu máy tính để bàn của người dùng sử dụng kết nối băng thông rộng tại nhà và thiết bị di động của họ sử dụng mạng dữ liệu di động, các tuyến mạng của các thiết bị có thể hoàn toàn khác nhau.) Nếu phương pháp của bạn yêu cầu đọc từ leader, trước tiên bạn có thể cần định tuyến các yêu cầu từ tất cả các thiết bị của người dùng đến cùng region.
![TIP] Regions and Availability Zones
Chúng ta dùng thuật ngữ region (khu vực) để chỉ một hoặc nhiều trung tâm dữ liệu trong một vị trí địa lý duy nhất. Các nhà cung cấp đám mây đặt nhiều trung tâm dữ liệu trong cùng một khu vực địa lý. Mỗi trung tâm dữ liệu được gọi là một availability zone hay đơn giản là zone. Vì vậy, một cloud region đơn bao gồm nhiều zone. Mỗi zone là một trung tâm dữ liệu riêng biệt nằm trong một cơ sở vật lý riêng biệt với nguồn điện, hệ thống làm mát riêng, v.v.
Các zone trong cùng một region được kết nối bằng các kết nối mạng tốc độ rất cao. Độ trễ đủ thấp để hầu hết các hệ thống phân tán có thể chạy với các node phân tán trên nhiều zone trong cùng region như thể chúng ở trong một zone duy nhất. Cấu hình multi-zone cho phép các hệ thống phân tán tồn tại qua các sự cố vùng khi một zone ngoại tuyến, nhưng chúng không bảo vệ chống lại các sự cố khu vực khi tất cả các zone trong một region không khả dụng. Để tồn tại qua sự cố khu vực, một hệ thống phân tán phải được triển khai trên nhiều region, điều này có thể dẫn đến độ trễ cao hơn, throughput thấp hơn, và hóa đơn mạng đám mây tăng lên. Chúng ta sẽ thảo luận những đánh đổi này hơn trong “Multi-leader replication topologies”. Hiện tại, chỉ cần biết rằng khi chúng ta nói region, chúng ta có nghĩa là một tập hợp các zone/trung tâm dữ liệu trong một vị trí địa lý duy nhất.
Monotonic Reads
Ví dụ thứ hai về bất thường có thể xảy ra khi đọc từ các follower bất đồng bộ là người dùng có thể thấy mọi thứ di chuyển ngược thời gian.
Điều này có thể xảy ra nếu một người dùng thực hiện nhiều lần đọc từ các replica khác nhau. Chẳng hạn, Hình 6-4 cho thấy người dùng 2345 thực hiện cùng truy vấn hai lần, đầu tiên đến một follower có ít lag, sau đó đến một follower có lag lớn hơn. (Tình huống này khá có thể xảy ra nếu người dùng làm mới một trang web và mỗi yêu cầu được định tuyến đến một server ngẫu nhiên.) Truy vấn đầu tiên trả về một bình luận được thêm gần đây bởi người dùng 1234, nhưng truy vấn thứ hai không trả về gì vì follower đang lag chưa nhận được lần ghi đó. Thực tế là, truy vấn thứ hai quan sát trạng thái hệ thống tại một thời điểm sớm hơn so với truy vấn đầu tiên. Điều này sẽ không tệ lắm nếu truy vấn đầu tiên không trả về gì, vì người dùng 2345 có lẽ sẽ không biết rằng người dùng 1234 đã thêm bình luận gần đây. Tuy nhiên, rất khó hiểu với người dùng 2345 nếu họ trước tiên thấy bình luận của người dùng 1234 xuất hiện, rồi sau đó thấy nó biến mất.
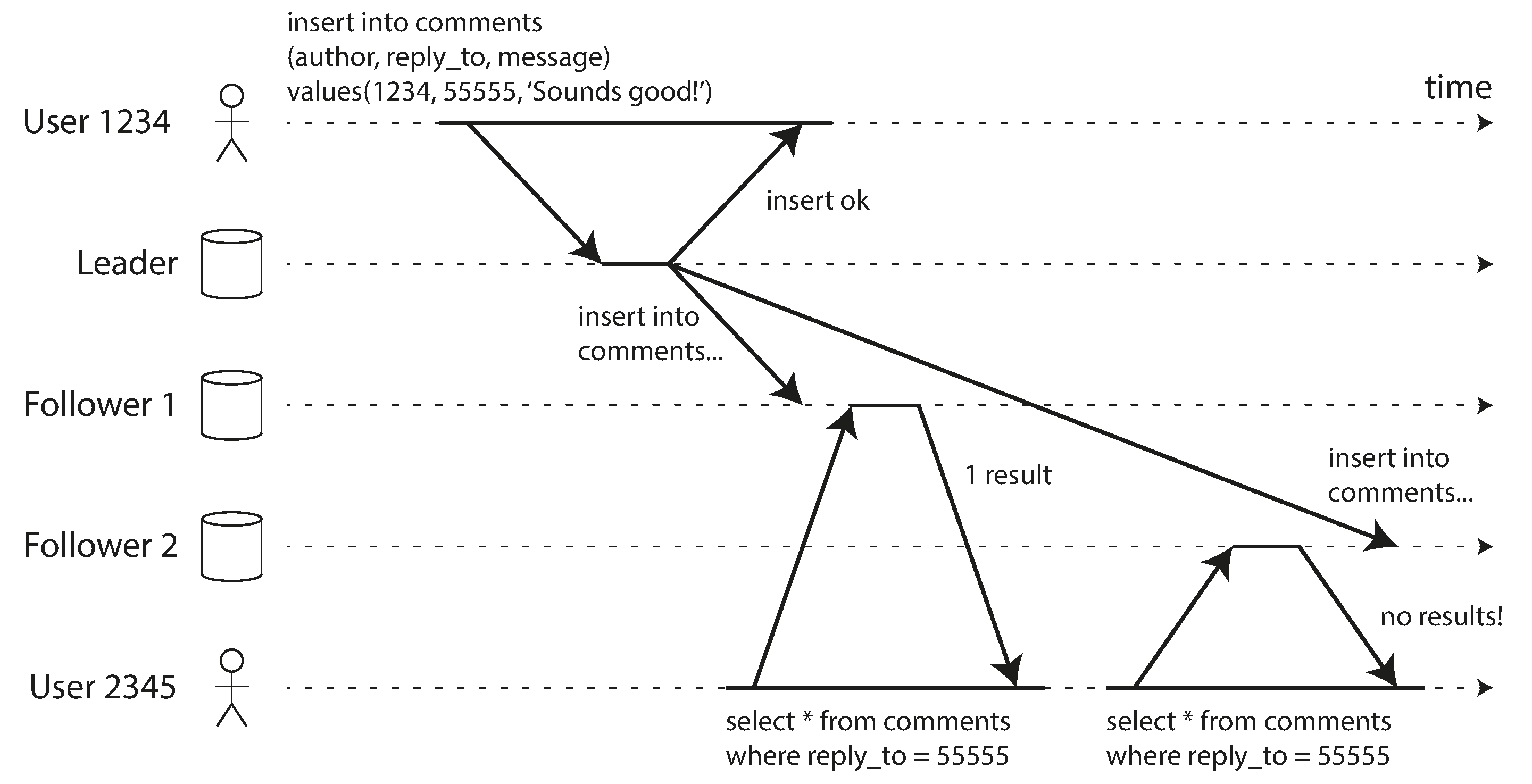
Monotonic reads 22 là đảm bảo rằng loại bất thường này không xảy ra. Đây là đảm bảo yếu hơn so với tính nhất quán mạnh, nhưng mạnh hơn so với eventual consistency. Khi bạn đọc dữ liệu, bạn có thể thấy một giá trị cũ; monotonic reads chỉ có nghĩa là nếu một người dùng thực hiện nhiều lần đọc liên tiếp, họ sẽ không thấy thời gian đi ngược lại, tức là họ sẽ không đọc dữ liệu cũ hơn sau khi đã đọc dữ liệu mới hơn.
Một cách để đạt được monotonic reads là đảm bảo rằng mỗi người dùng luôn thực hiện các lần đọc của họ từ cùng một replica (người dùng khác nhau có thể đọc từ các replica khác nhau). Chẳng hạn, replica có thể được chọn dựa trên hash của user ID, thay vì ngẫu nhiên. Tuy nhiên, nếu replica đó bị lỗi, các truy vấn của người dùng sẽ cần được định tuyến lại đến một replica khác.
Consistent Prefix Reads
Ví dụ thứ ba về các bất thường replication lag liên quan đến vi phạm nhân quả. Hãy tưởng tượng cuộc đối thoại ngắn sau giữa Mr. Poons và Mrs. Cake:
- Mr. Poons
- Bà có thể nhìn thấy bao xa vào tương lai, bà Cake?
- Mrs. Cake
- Thường khoảng mười giây, ông Poons.
Có một phụ thuộc nhân quả giữa hai câu đó: Mrs. Cake nghe câu hỏi của Mr. Poons và trả lời.
Bây giờ, hãy tưởng tượng một người thứ ba đang nghe cuộc trò chuyện này qua các follower. Những gì Mrs. Cake nói đi qua một follower có ít lag, nhưng những gì Mr. Poons nói có lag replication dài hơn (xem Hình 6-5). Người quan sát này sẽ nghe thấy điều sau:
- Mrs. Cake
- Thường khoảng mười giây, ông Poons.
- Mr. Poons
- Bà có thể nhìn thấy bao xa vào tương lai, bà Cake?
Với người quan sát, có vẻ như Mrs. Cake đang trả lời câu hỏi trước khi Mr. Poons thậm chí còn hỏi. Những năng lực thấu thị như vậy thật ấn tượng, nhưng rất khó hiểu 27.
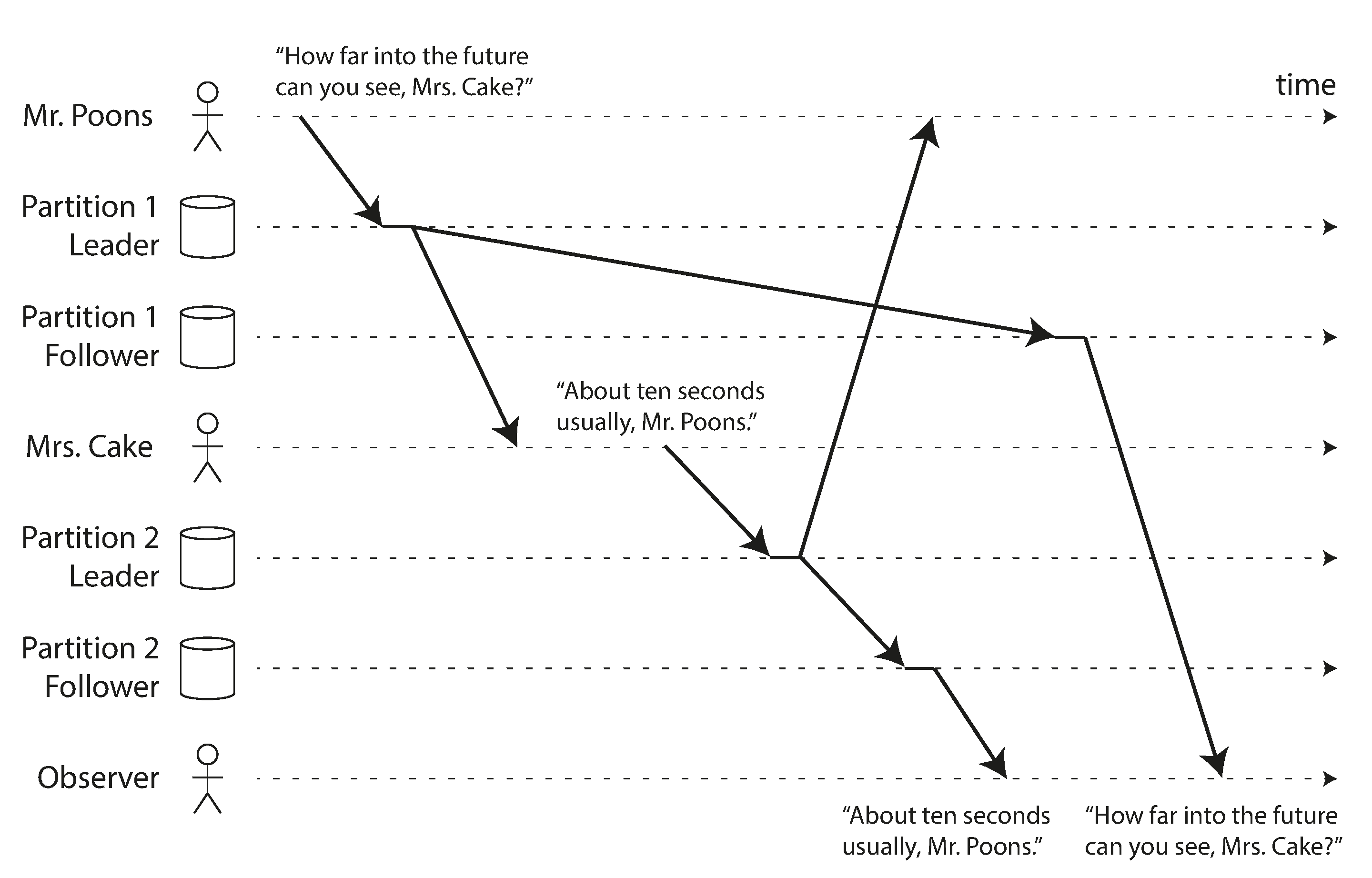
Ngăn chặn loại bất thường này yêu cầu một loại đảm bảo khác: consistent prefix reads 22. Đảm bảo này nói rằng nếu một chuỗi các lần ghi xảy ra theo một thứ tự nhất định, thì bất kỳ ai đọc những lần ghi đó sẽ thấy chúng xuất hiện theo cùng thứ tự.
Đây là vấn đề đặc biệt trong các cơ sở dữ liệu được sharded (phân mảnh), mà chúng ta sẽ thảo luận trong Chương 7. Nếu cơ sở dữ liệu luôn áp dụng các lần ghi theo cùng thứ tự, các lần đọc luôn thấy một prefix nhất quán, vì vậy bất thường này không thể xảy ra. Tuy nhiên, trong nhiều cơ sở dữ liệu phân tán, các shard khác nhau hoạt động độc lập, vì vậy không có thứ tự toàn cầu của các lần ghi: khi người dùng đọc từ cơ sở dữ liệu, họ có thể thấy một số phần của cơ sở dữ liệu ở trạng thái cũ hơn và một số phần ở trạng thái mới hơn.
Một giải pháp là đảm bảo rằng bất kỳ lần ghi nào có liên quan nhân quả với nhau đều được ghi vào cùng một shard, nhưng trong một số ứng dụng điều đó không thể thực hiện hiệu quả. Cũng có các thuật toán theo dõi rõ ràng các phụ thuộc nhân quả, một chủ đề mà chúng ta sẽ quay lại trong “The “happens-before” relation and concurrency”.
Solutions for Replication Lag
Khi làm việc với một hệ thống nhất quán cuối cùng, đáng để nghĩ về cách ứng dụng hoạt động nếu replication lag tăng lên đến vài phút hoặc thậm chí vài giờ. Nếu câu trả lời là “không có vấn đề gì,” thì tuyệt vời. Tuy nhiên, nếu kết quả là trải nghiệm tệ cho người dùng, điều quan trọng là thiết kế hệ thống để cung cấp đảm bảo mạnh hơn, chẳng hạn như read-after-write. Giả vờ rằng replication là đồng bộ khi thực ra nó là bất đồng bộ là công thức dẫn đến các vấn đề về sau.
Như đã thảo luận trước đây, có những cách mà ứng dụng có thể cung cấp đảm bảo mạnh hơn so với cơ sở dữ liệu bên dưới, chẳng hạn bằng cách thực hiện một số loại đọc nhất định trên leader hoặc một follower được cập nhật đồng bộ. Tuy nhiên, xử lý những vấn đề này trong mã ứng dụng rất phức tạp và dễ mắc lỗi.
Mô hình lập trình đơn giản nhất cho các nhà phát triển ứng dụng là chọn một cơ sở dữ liệu cung cấp đảm bảo tính nhất quán mạnh cho các replica như linearizability (xem Chương 10), và ACID transactions (xem Chương 8). Điều này cho phép bạn hầu như bỏ qua những thách thức xuất phát từ replication, và coi cơ sở dữ liệu như thể nó chỉ có một node duy nhất. Vào đầu những năm 2010, phong trào NoSQL thúc đẩy quan điểm rằng những tính năng này hạn chế khả năng mở rộng, và các hệ thống quy mô lớn sẽ phải chấp nhận eventual consistency.
Tuy nhiên, kể từ đó, một số cơ sở dữ liệu đã bắt đầu cung cấp tính nhất quán mạnh và transaction trong khi vẫn cung cấp ưu điểm chịu lỗi, tính sẵn sàng cao, và khả năng mở rộng của cơ sở dữ liệu phân tán. Như đã đề cập trong “Relational Model versus Document Model”, xu hướng này được gọi là NewSQL để đối lập với NoSQL (mặc dù ít liên quan đến SQL cụ thể hơn, và nhiều hơn về các phương pháp mới cho quản lý transaction có thể mở rộng).
Mặc dù các cơ sở dữ liệu phân tán có thể mở rộng và nhất quán mạnh hiện có sẵn, vẫn còn có lý do chính đáng tại sao một số ứng dụng chọn sử dụng các hình thức replication khác nhau cung cấp đảm bảo nhất quán yếu hơn: chúng có thể cung cấp khả năng phục hồi mạnh mẽ hơn khi gián đoạn mạng, và có chi phí thấp hơn so với các hệ thống transaction. Chúng ta sẽ khám phá các phương pháp như vậy trong phần còn lại của chương này.
Multi-Leader Replication
Cho đến nay trong chương này chúng ta chỉ xem xét các kiến trúc replication sử dụng một leader duy nhất. Mặc dù đó là cách tiếp cận phổ biến, có những phương án thay thế thú vị.
Single-leader replication có một nhược điểm lớn: tất cả các lần ghi phải đi qua một leader duy nhất. Nếu bạn không thể kết nối đến leader vì bất kỳ lý do nào, chẳng hạn do gián đoạn mạng giữa bạn và leader, bạn không thể ghi vào cơ sở dữ liệu.
Một phần mở rộng tự nhiên của mô hình single-leader replication là cho phép nhiều hơn một node chấp nhận các lần ghi. Replication vẫn xảy ra theo cùng cách: mỗi node xử lý một lần ghi phải chuyển tiếp thay đổi dữ liệu đó đến tất cả các node khác. Chúng ta gọi đây là cấu hình multi-leader (còn được gọi là active/active hay bidirectional replication). Trong thiết lập này, mỗi leader đồng thời đóng vai follower cho các leader khác.
Cũng như single-leader replication, có sự lựa chọn giữa đồng bộ hoặc bất đồng bộ. Giả sử bạn có hai leader, A và B, và bạn đang cố gắng ghi vào A. Nếu các lần ghi được sao chép đồng bộ từ A sang B, và mạng giữa hai node bị gián đoạn, bạn không thể ghi vào A cho đến khi mạng quay lại. Multi-leader replication đồng bộ do đó cho bạn một mô hình rất giống với single-leader replication, tức là nếu bạn đã làm B là leader và A chỉ đơn giản là chuyển tiếp bất kỳ yêu cầu ghi nào đến B để thực thi.
Vì lý do đó, chúng ta sẽ không đi sâu hơn vào multi-leader replication đồng bộ, và chỉ coi nó tương đương với single-leader replication. Phần còn lại của phần này tập trung vào multi-leader replication bất đồng bộ, trong đó bất kỳ leader nào cũng có thể xử lý các lần ghi ngay cả khi kết nối của nó đến các leader khác bị gián đoạn.
Geographically Distributed Operation
Hiếm khi có ý nghĩa khi dùng thiết lập multi-leader trong một region đơn, vì lợi ích hiếm khi vượt qua độ phức tạp tăng thêm. Tuy nhiên, có một số tình huống mà cấu hình này hợp lý.
Hãy tưởng tượng bạn có một cơ sở dữ liệu với các replica ở một số region khác nhau (có lẽ để bạn có thể chịu đựng sự cố của toàn bộ region, hoặc có lẽ để gần hơn với người dùng của bạn). Đây được gọi là thiết lập geographically distributed (phân tán địa lý), geo-distributed, hay geo-replicated. Với single-leader replication, leader phải ở trong một trong các region, và tất cả các lần ghi phải đi qua region đó.
Trong cấu hình multi-leader, bạn có thể có một leader ở mỗi region. Hình 6-6 cho thấy kiến trúc này có thể trông như thế nào. Trong mỗi region, replication leader-follower thông thường được sử dụng (với các follower có thể ở một availability zone khác với leader); giữa các region, leader của mỗi region sao chép các thay đổi của nó đến các leader ở các region khác.
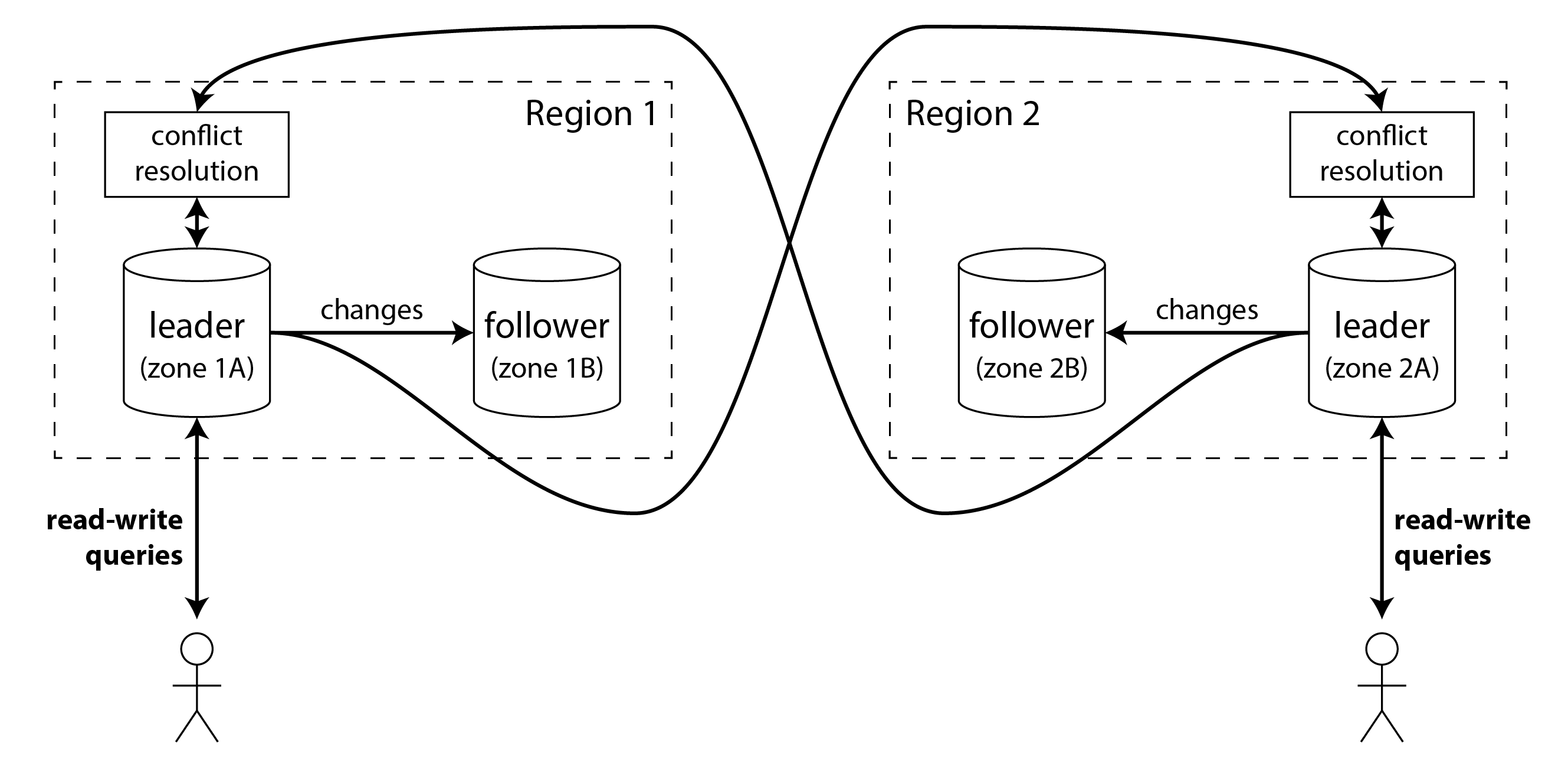
Hãy so sánh cách các cấu hình single-leader và multi-leader hoạt động trong một deployment nhiều region:
- Performance (Hiệu năng)
- Trong cấu hình single-leader, mỗi lần ghi phải đi qua internet đến region có leader. Điều này có thể thêm độ trễ đáng kể cho các lần ghi và có thể đi ngược lại mục đích của việc có nhiều region ngay từ đầu. Trong cấu hình multi-leader, mỗi lần ghi có thể được xử lý trong region cục bộ và được sao chép bất đồng bộ đến các region khác. Vì vậy, độ trễ mạng inter-region bị ẩn khỏi người dùng, điều đó có nghĩa là hiệu năng cảm nhận được có thể tốt hơn.
- Tolerance of regional outages (Chịu đựng sự cố khu vực)
- Trong cấu hình single-leader, nếu region có leader trở nên không khả dụng, failover có thể thăng cấp một follower ở region khác thành leader. Trong cấu hình multi-leader, mỗi region có thể tiếp tục hoạt động độc lập với các region khác, và replication bắt kịp khi region offline quay trở lại trực tuyến.
- Tolerance of network problems (Chịu đựng sự cố mạng)
- Ngay cả với các kết nối chuyên dụng, lưu lượng giữa các region
có thể kém đáng tin cậy hơn lưu lượng giữa các zone trong cùng region hoặc trong một zone đơn. Cấu hình single-leader rất nhạy cảm với các sự cố trong liên kết inter-region này, vì khi một client trong một region muốn ghi vào một leader ở region khác, nó phải gửi yêu cầu qua liên kết đó và chờ phản hồi trước khi hoàn thành.
Cấu hình multi-leader với replication bất đồng bộ có thể chịu đựng sự cố mạng tốt hơn: trong một gián đoạn mạng tạm thời, leader của mỗi region có thể tiếp tục xử lý các lần ghi một cách độc lập.
- Consistency (Tính nhất quán)
- Hệ thống single-leader có thể cung cấp các đảm bảo nhất quán mạnh, chẳng hạn như serializable transactions (giao dịch tuần tự hóa), mà chúng ta sẽ thảo luận trong Chương 8. Nhược điểm lớn nhất của các hệ thống multi-leader là tính nhất quán chúng có thể đạt được yếu hơn nhiều. Chẳng hạn, bạn không thể đảm bảo rằng số dư tài khoản ngân hàng sẽ không âm hoặc tên người dùng là duy nhất: luôn có thể để các leader khác nhau xử lý các lần ghi riêng lẻ ổn (rút một phần tiền trong tài khoản, đăng ký một tên người dùng cụ thể), nhưng vi phạm ràng buộc khi kết hợp với một lần ghi khác trên leader khác.
Đây đơn giản là một hạn chế cơ bản của các hệ thống phân tán 28. Nếu bạn cần thực thi các ràng buộc như vậy, tốt hơn là nên dùng hệ thống single-leader. Tuy nhiên, như chúng ta sẽ thấy trong “Dealing with Conflicting Writes”, các hệ thống multi-leader vẫn có thể đạt được các thuộc tính nhất quán hữu ích trong nhiều ứng dụng không cần các ràng buộc như vậy.
Multi-leader replication ít phổ biến hơn single-leader replication, nhưng vẫn được nhiều cơ sở dữ liệu hỗ trợ, bao gồm MySQL, Oracle, SQL Server, và YugabyteDB. Trong một số trường hợp đó là tính năng add-on bên ngoài, chẳng hạn như trong Redis Enterprise, EDB Postgres Distributed, và pglogical 29.
Vì multi-leader replication là một tính năng được thêm vào sau trong nhiều cơ sở dữ liệu, thường có những bẫy cấu hình tinh tế và các tương tác bất ngờ với các tính năng cơ sở dữ liệu khác. Chẳng hạn, các khóa tự tăng, trigger, và ràng buộc toàn vẹn có thể gây ra vấn đề. Vì lý do này, multi-leader replication thường được coi là lãnh thổ nguy hiểm cần tránh nếu có thể 30.
Multi-leader replication topologies
Một replication topology (tô-pô sao chép) mô tả các đường truyền thông qua đó các lần ghi được truyền từ node này sang node khác. Nếu bạn có hai leader, như trong Hình 6-9, chỉ có một tô-pô khả thi: leader 1 phải gửi tất cả các lần ghi của nó đến leader 2, và ngược lại. Với nhiều hơn hai leader, có thể có nhiều tô-pô khác nhau. Một số ví dụ được minh họa trong Hình 6-7.
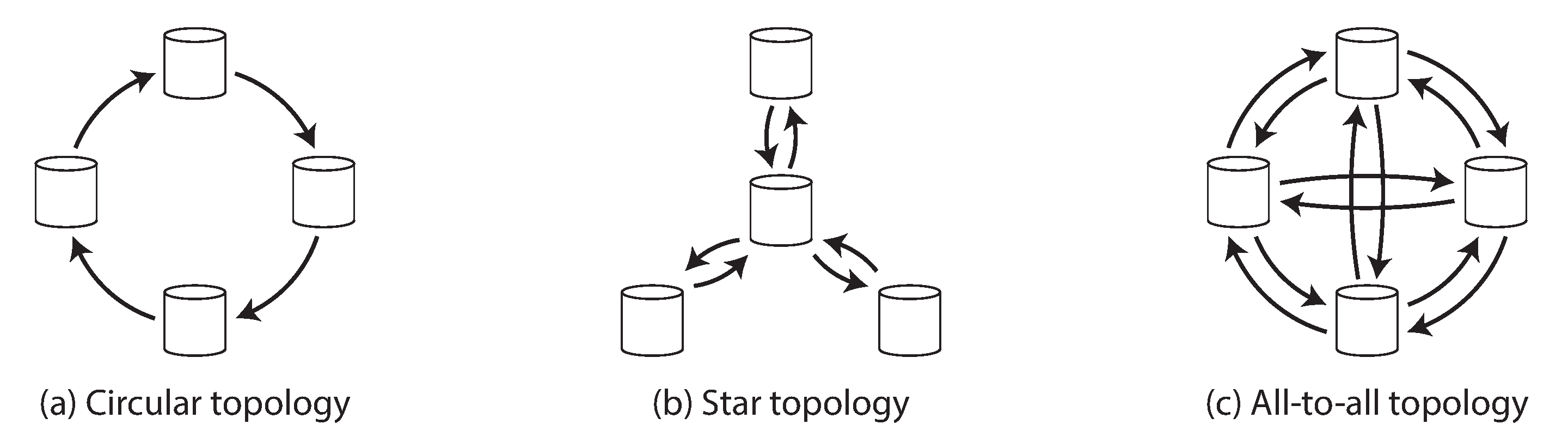
Tô-pô tổng quát nhất là all-to-all (tất cả với tất cả), được hiển thị trong Hình 6-7(c), trong đó mỗi leader gửi các lần ghi của nó đến mọi leader khác. Tuy nhiên, các tô-pô hạn chế hơn cũng được sử dụng: chẳng hạn circular topology (tô-pô vòng tròn) trong đó mỗi node nhận các lần ghi từ một node và chuyển tiếp những lần ghi đó (cộng với bất kỳ lần ghi nào của chính nó) đến một node khác. Một tô-pô phổ biến khác có hình dạng của một star (ngôi sao): một node gốc được chỉ định chuyển tiếp các lần ghi đến tất cả các node khác. Tô-pô ngôi sao có thể được tổng quát hóa thành một cây.
Note
Đừng nhầm lẫn tô-pô mạng hình ngôi sao với star schema (lược đồ ngôi sao) (xem “Stars and Snowflakes: Schemas for Analytics”), mô tả cấu trúc của một mô hình dữ liệu.
Trong các tô-pô vòng tròn và ngôi sao, một lần ghi có thể cần phải đi qua nhiều node trước khi đến tất cả các replica. Vì vậy, các node cần chuyển tiếp các thay đổi dữ liệu chúng nhận được từ các node khác. Để ngăn chặn các vòng lặp replication vô hạn, mỗi node được cấp một định danh duy nhất, và trong replication log, mỗi lần ghi được gắn thẻ với các định danh của tất cả các node mà nó đã đi qua 31. Khi một node nhận được một thay đổi dữ liệu được gắn thẻ với định danh của chính nó, thay đổi dữ liệu đó bị bỏ qua, vì node biết rằng nó đã được xử lý rồi.
Problems with different topologies
Một vấn đề với các tô-pô vòng tròn và ngôi sao là nếu chỉ một node bị lỗi, nó có thể làm gián đoạn luồng các tin nhắn replication giữa các node khác, khiến chúng không thể giao tiếp cho đến khi node được sửa. Tô-pô có thể được cấu hình lại để hoạt động xung quanh node bị lỗi, nhưng trong hầu hết các deployment, việc cấu hình lại như vậy phải được thực hiện thủ công. Khả năng chịu lỗi của tô-pô được kết nối dày đặc hơn (như all-to-all) tốt hơn vì nó cho phép các tin nhắn đi theo các đường khác nhau, tránh một điểm lỗi duy nhất.
Mặt khác, các tô-pô all-to-all cũng có thể có vấn đề. Đặc biệt, một số liên kết mạng có thể nhanh hơn so với các liên kết khác (ví dụ: do tắc nghẽn mạng), với kết quả là một số tin nhắn replication có thể “vượt mặt” những tin nhắn khác, như minh họa trong Hình 6-8.
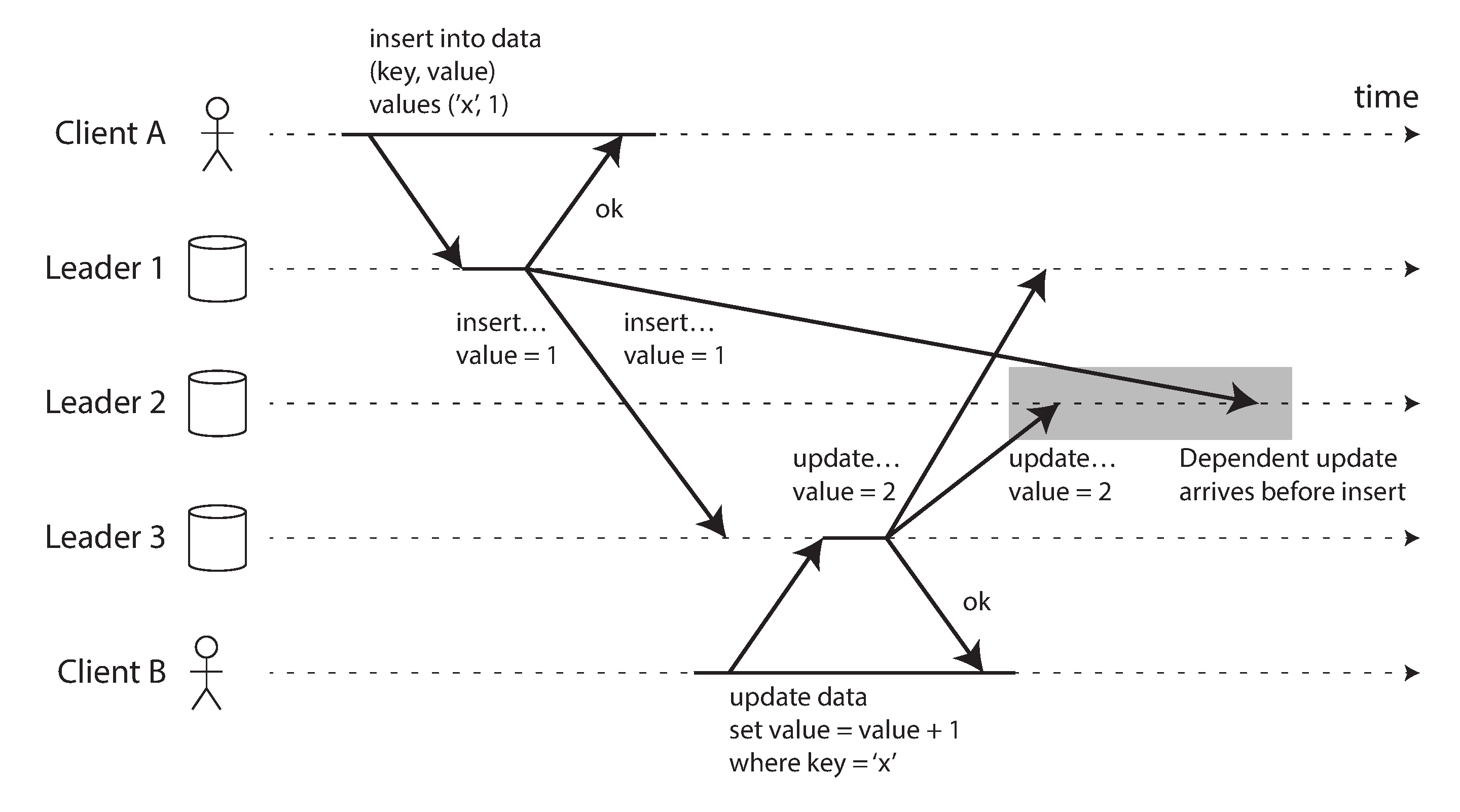
Trong Hình 6-8, client A chèn một hàng vào một bảng trên leader 1, và client B cập nhật hàng đó trên leader 3. Tuy nhiên, leader 2 có thể nhận được các lần ghi theo thứ tự khác: nó có thể đầu tiên nhận được cập nhật (mà từ góc nhìn của nó, là cập nhật một hàng không tồn tại trong cơ sở dữ liệu) và chỉ sau đó mới nhận được lệnh chèn tương ứng (lẽ ra phải đến trước cập nhật).
Đây là vấn đề nhân quả, tương tự như vấn đề chúng ta đã thấy trong “Consistent Prefix Reads”: cập nhật phụ thuộc vào lệnh chèn trước đó, vì vậy chúng ta cần đảm bảo rằng tất cả các node xử lý lệnh chèn trước, rồi mới đến cập nhật. Chỉ đơn giản gắn timestamp cho mỗi lần ghi là không đủ, vì đồng hồ không thể tin cậy để đồng bộ hóa đủ chính xác để sắp xếp đúng thứ tự các sự kiện này tại leader 2 (xem Chương 9).
Để sắp xếp đúng thứ tự các sự kiện này, có thể dùng kỹ thuật gọi là version vectors (vectơ phiên bản), mà chúng ta sẽ thảo luận sau trong chương này (xem “Detecting Concurrent Writes”). Tuy nhiên, nhiều hệ thống multi-leader replication không dùng các kỹ thuật tốt để sắp xếp thứ tự cập nhật, khiến chúng dễ bị tổn thương bởi các vấn đề như trong Hình 6-8. Nếu bạn đang dùng multi-leader replication, đáng để nhận thức về những vấn đề này, đọc kỹ tài liệu, và kiểm tra kỹ lưỡng cơ sở dữ liệu của bạn để đảm bảo rằng nó thực sự cung cấp các đảm bảo bạn tin là nó có.
Sync Engines and Local-First Software
Một tình huống khác mà multi-leader replication phù hợp là nếu bạn có một ứng dụng cần tiếp tục hoạt động khi bị ngắt kết nối internet.
Chẳng hạn, hãy xem xét các ứng dụng lịch trên điện thoại di động, máy tính xách tay, và các thiết bị khác của bạn. Bạn cần có khả năng xem các cuộc họp của mình (thực hiện các yêu cầu đọc) và nhập các cuộc họp mới (thực hiện các yêu cầu ghi) bất kỳ lúc nào, bất kể thiết bị của bạn hiện có kết nối internet hay không. Nếu bạn thực hiện bất kỳ thay đổi nào khi ngoại tuyến, chúng cần được đồng bộ với server và các thiết bị khác của bạn khi thiết bị tiếp theo có kết nối trực tuyến.
Trong trường hợp này, mỗi thiết bị có một replica cơ sở dữ liệu cục bộ đóng vai trò leader (nó chấp nhận các yêu cầu ghi), và có một quy trình multi-leader replication bất đồng bộ (đồng bộ) giữa các replica lịch của bạn trên tất cả các thiết bị. Replication lag có thể là hàng giờ hoặc thậm chí hàng ngày, tùy thuộc vào khi nào bạn có internet.
Từ góc nhìn kiến trúc, thiết lập này rất giống với multi-leader replication giữa các region, được đẩy đến mức cực đoan: mỗi thiết bị là một “region,” và kết nối mạng giữa chúng cực kỳ không đáng tin cậy.
Real-time collaboration, offline-first, and local-first apps
Hơn nữa, nhiều ứng dụng web hiện đại cung cấp các tính năng real-time collaboration (cộng tác thời gian thực), chẳng hạn như Google Docs và Sheets cho tài liệu văn bản và bảng tính, Figma cho đồ họa, và Linear cho quản lý dự án. Điều làm cho các ứng dụng này nhanh nhạy là input của người dùng được phản ánh ngay lập tức trong giao diện người dùng, không cần chờ một vòng khứ hồi mạng đến server, và các chỉnh sửa của một người dùng được hiển thị cho các cộng tác viên của họ với độ trễ thấp 32 33 34
Điều này lại dẫn đến kiến trúc multi-leader: mỗi tab trình duyệt web đã mở file chia sẻ là một replica, và bất kỳ cập nhật nào bạn thực hiện đối với file đó được sao chép bất đồng bộ đến thiết bị của những người dùng khác đã mở cùng tệp đó. Ngay cả khi ứng dụng không cho phép bạn tiếp tục chỉnh sửa tệp khi ngoại tuyến, thực tế là nhiều người dùng có thể thực hiện các chỉnh sửa mà không cần chờ phản hồi từ máy chủ đã làm cho nó trở thành multi-leader (đa leader).
Cả chỉnh sửa ngoại tuyến lẫn cộng tác thời gian thực đều đòi hỏi một cơ sở hạ tầng nhân bản tương tự: ứng dụng cần ghi lại mọi thay đổi mà người dùng thực hiện với tệp, rồi gửi ngay đến cộng tác viên (nếu đang trực tuyến), hoặc lưu cục bộ để gửi sau (nếu ngoại tuyến). Ngoài ra, ứng dụng cần nhận các thay đổi từ cộng tác viên, hợp nhất chúng vào bản sao cục bộ của người dùng, và cập nhật giao diện người dùng để phản ánh phiên bản mới nhất. Nếu nhiều người dùng đã thay đổi tệp đồng thời, có thể cần logic giải quyết xung đột để hợp nhất các thay đổi đó.
Một thư viện phần mềm hỗ trợ quá trình này được gọi là sync engine (công cụ đồng bộ). Mặc dù ý tưởng này đã tồn tại từ lâu, thuật ngữ này gần đây mới được chú ý 35 36 37. Một ứng dụng cho phép người dùng tiếp tục chỉnh sửa tệp khi ngoại tuyến (có thể được triển khai bằng sync engine) được gọi là offline-first 38. Thuật ngữ local-first software (phần mềm ưu tiên cục bộ) chỉ các ứng dụng cộng tác không chỉ là offline-first mà còn được thiết kế để tiếp tục hoạt động ngay cả khi nhà phát triển tạo ra phần mềm đó tắt toàn bộ dịch vụ trực tuyến của họ 39. Điều này có thể đạt được bằng cách sử dụng sync engine với một giao thức đồng bộ tiêu chuẩn mở, trong đó có nhiều nhà cung cấp dịch vụ khả dụng 40. Ví dụ, Git là một hệ thống cộng tác local-first (dù không hỗ trợ cộng tác thời gian thực) vì bạn có thể đồng bộ qua GitHub, GitLab hoặc bất kỳ dịch vụ lưu trữ kho lưu trữ nào khác.
Ưu và nhược điểm của sync engine
Cách phổ biến nhất để xây dựng ứng dụng web hiện nay là giữ rất ít trạng thái lâu dài trên client, và dựa vào việc gửi yêu cầu đến máy chủ bất cứ khi nào cần hiển thị một phần dữ liệu mới hoặc cần cập nhật một số dữ liệu. Ngược lại, khi sử dụng sync engine, bạn có trạng thái lâu dài trên client, và việc giao tiếp với máy chủ được chuyển vào một tiến trình nền. Cách tiếp cận sync engine có một số ưu điểm:
- Có dữ liệu cục bộ có nghĩa là giao diện người dùng có thể phản hồi nhanh hơn nhiều so với khi phải chờ một cuộc gọi dịch vụ để lấy dữ liệu. Một số ứng dụng nhắm đến việc phản hồi thao tác người dùng trong frame (khung hình) tiếp theo của hệ thống đồ họa, nghĩa là render trong vòng 16 ms trên màn hình có tần số làm tươi 60 Hz.
- Cho phép người dùng tiếp tục làm việc khi ngoại tuyến rất có giá trị, đặc biệt trên các thiết bị di động có kết nối không ổn định. Với sync engine, ứng dụng không cần chế độ ngoại tuyến riêng biệt: việc ngoại tuyến cũng giống như có độ trễ mạng rất lớn.
- Sync engine đơn giản hóa mô hình lập trình cho các ứng dụng frontend, so với việc thực hiện các cuộc gọi dịch vụ tường minh trong code ứng dụng. Mỗi cuộc gọi dịch vụ đòi hỏi xử lý lỗi, như đã thảo luận trong “The problems with remote procedure calls (RPCs)”: ví dụ, nếu yêu cầu cập nhật dữ liệu trên máy chủ thất bại, giao diện người dùng cần phản ánh lỗi đó theo một cách nào đó. Sync engine cho phép ứng dụng thực hiện đọc và ghi trên dữ liệu cục bộ, điều này hầu như không bao giờ thất bại, dẫn đến phong cách lập trình khai báo hơn 41.
- Để hiển thị các chỉnh sửa từ người dùng khác theo thời gian thực, bạn cần nhận thông báo về các chỉnh sửa đó và cập nhật giao diện người dùng một cách hiệu quả. Sync engine kết hợp với mô hình reactive programming (lập trình phản ứng) là một cách tốt để triển khai điều này 42.
Sync engine hoạt động tốt nhất khi tất cả dữ liệu mà người dùng có thể cần được tải xuống trước và lưu trữ lâu dài trên client. Điều này có nghĩa là dữ liệu sẵn sàng cho truy cập ngoại tuyến khi cần, nhưng cũng có nghĩa là sync engine không phù hợp nếu người dùng có quyền truy cập vào một lượng dữ liệu rất lớn. Ví dụ, việc tải xuống tất cả các tệp mà chính người dùng tạo ra có thể chấp nhận được (một người dùng nói chung không tạo ra quá nhiều dữ liệu), nhưng tải xuống toàn bộ danh mục của một trang thương mại điện tử có lẽ không hợp lý.
Sync engine được tiên phong bởi Lotus Notes vào những năm 1980 43 (mà không sử dụng thuật ngữ đó), và đồng bộ cho các ứng dụng cụ thể như lịch cũng đã tồn tại từ lâu. Ngày nay có một số sync engine đa năng, một số sử dụng dịch vụ backend độc quyền (ví dụ: Google Firestore, Realm hoặc Ditto), và một số có backend mã nguồn mở, phù hợp để tạo phần mềm local-first (ví dụ: PouchDB/CouchDB, Automerge hoặc Yjs).
Trò chơi điện tử nhiều người chơi có nhu cầu tương tự: phản hồi ngay lập tức với các hành động cục bộ của người dùng, và đối chiếu chúng với hành động của người chơi khác nhận được bất đồng bộ qua mạng. Trong thuật ngữ phát triển game, tương đương của sync engine được gọi là netcode. Các kỹ thuật sử dụng trong netcode khá đặc thù cho các yêu cầu của game 44, và không áp dụng trực tiếp cho các loại phần mềm khác, vì vậy chúng ta sẽ không xem xét thêm trong cuốn sách này.
Xử lý các Ghi Xung đột
Vấn đề lớn nhất của multi-leader replication, cả trong cơ sở dữ liệu phân tán địa lý phía máy chủ lẫn sync engine local-first trên thiết bị người dùng cuối, là các ghi đồng thời trên các leader khác nhau có thể dẫn đến các xung đột cần được giải quyết.
Ví dụ, hãy xem xét một trang wiki đang được chỉnh sửa đồng thời bởi hai người dùng, như được hiển thị trong Hình 6-9. Người dùng 1 thay đổi tiêu đề của trang từ A thành B, và người dùng 2 độc lập thay đổi tiêu đề từ A thành C. Thay đổi của mỗi người dùng được áp dụng thành công cho leader cục bộ của họ. Tuy nhiên, khi các thay đổi được nhân bản bất đồng bộ, một xung đột được phát hiện. Vấn đề này không xảy ra trong cơ sở dữ liệu single-leader.
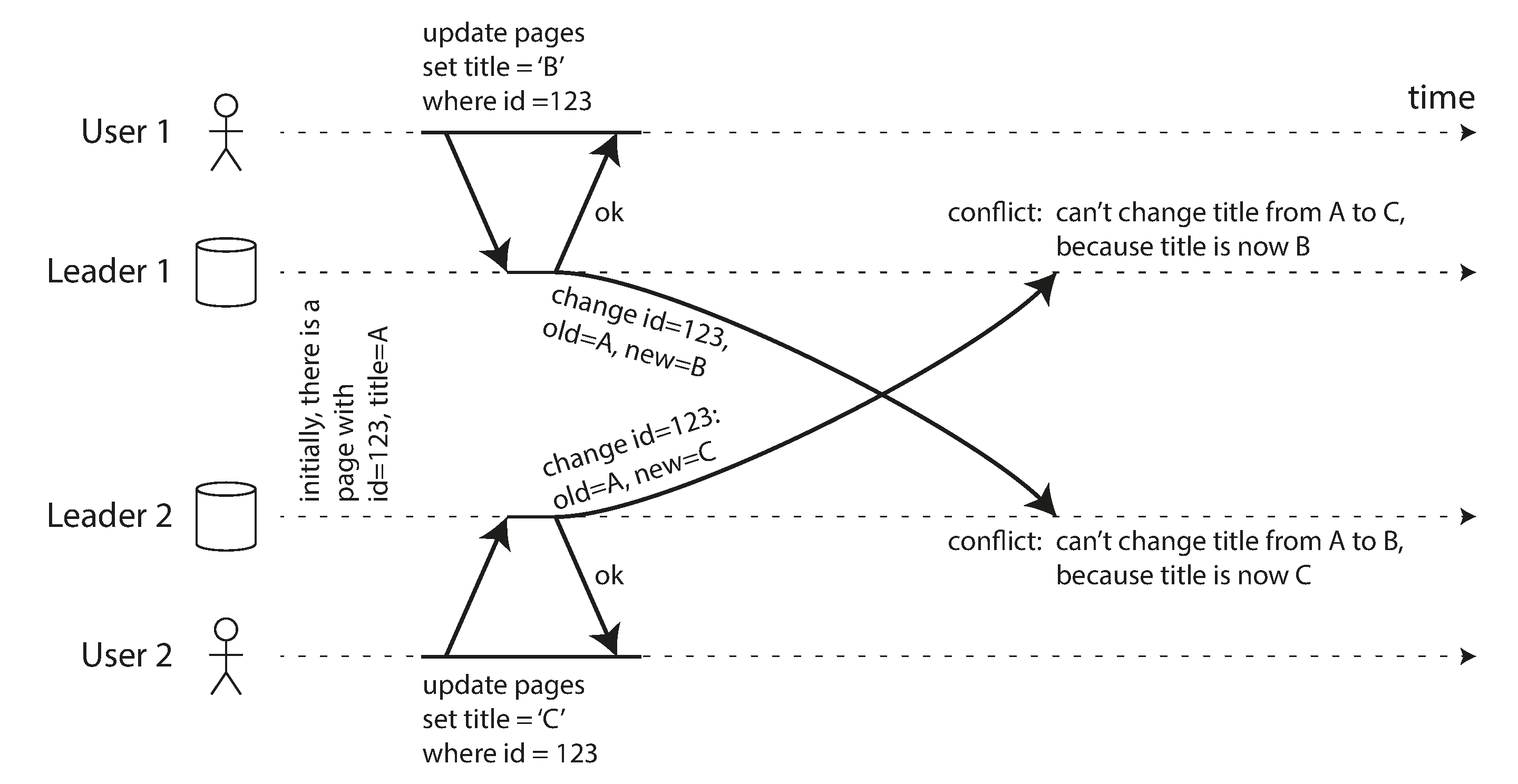
Note
Chúng ta nói rằng hai lần ghi trong Hình 6-9 là đồng thời vì không lần nào “biết” đến lần kia tại thời điểm lần ghi ban đầu được thực hiện. Không quan trọng là liệu các lần ghi có thực sự xảy ra cùng một lúc hay không; thực ra, nếu các lần ghi được thực hiện khi ngoại tuyến, chúng có thể đã xảy ra cách nhau một khoảng thời gian. Điều quan trọng là liệu một lần ghi có xảy ra trong trạng thái mà lần ghi kia đã có hiệu lực hay chưa.
Trong “Phát hiện các Ghi Đồng thời” chúng ta sẽ giải quyết câu hỏi về cách cơ sở dữ liệu có thể xác định xem hai lần ghi có đồng thời hay không. Hiện tại chúng ta sẽ giả định rằng chúng ta có thể phát hiện xung đột, và chúng ta muốn tìm ra cách tốt nhất để giải quyết chúng.
Tránh xung đột
Một chiến lược đối với xung đột là tránh để chúng xảy ra ngay từ đầu. Ví dụ, nếu ứng dụng có thể đảm bảo rằng tất cả các lần ghi cho một bản ghi cụ thể đều đi qua cùng một leader, thì xung đột không thể xảy ra, ngay cả khi cơ sở dữ liệu nói chung là multi-leader. Cách tiếp cận này không khả thi trong trường hợp client sync engine được cập nhật ngoại tuyến, nhưng đôi khi có thể thực hiện trong các hệ thống máy chủ nhân bản địa lý 30.
Ví dụ, trong một ứng dụng mà người dùng chỉ có thể chỉnh sửa dữ liệu của chính họ, bạn có thể đảm bảo rằng các yêu cầu từ một người dùng cụ thể luôn được định tuyến đến cùng một vùng và sử dụng leader trong vùng đó để đọc và ghi. Các người dùng khác nhau có thể có các vùng “home” (nhà) khác nhau (có thể được chọn dựa trên khoảng cách địa lý với người dùng), nhưng từ góc độ của bất kỳ người dùng nào, cấu hình về cơ bản là single-leader.
Tuy nhiên, đôi khi bạn có thể muốn thay đổi leader được chỉ định cho một bản ghi, chẳng hạn vì một vùng không khả dụng và bạn cần định tuyến lại lưu lượng đến vùng khác, hoặc vì một người dùng đã chuyển đến vị trí khác và hiện gần hơn với một vùng khác. Lúc này có rủi ro là người dùng thực hiện một lần ghi trong khi việc thay đổi leader được chỉ định đang tiến hành, dẫn đến một xung đột sẽ phải được giải quyết bằng một trong các phương pháp dưới đây. Do đó, tránh xung đột thất bại nếu bạn cho phép thay đổi leader.
Một ví dụ khác về tránh xung đột: hãy tưởng tượng bạn muốn chèn các bản ghi mới và tạo các ID duy nhất cho chúng dựa trên bộ đếm tự tăng. Nếu bạn có hai leader, bạn có thể thiết lập để một leader chỉ tạo số lẻ và leader kia chỉ tạo số chẵn. Như vậy bạn có thể chắc chắn rằng hai leader sẽ không đồng thời gán cùng một ID cho các bản ghi khác nhau. Chúng ta sẽ thảo luận về các phương thức gán ID khác trong “ID Generators and Logical Clocks”.
Last write wins (loại bỏ các ghi đồng thời)
Nếu xung đột không thể tránh khỏi, cách đơn giản nhất để giải quyết chúng là gắn một timestamp (nhãn thời gian) vào mỗi lần ghi, và luôn sử dụng giá trị có timestamp lớn nhất. Ví dụ, trong Hình 6-9, giả sử timestamp của lần ghi của người dùng 1 lớn hơn timestamp của lần ghi của người dùng 2. Trong trường hợp đó, cả hai leader sẽ xác định rằng tiêu đề mới của trang nên là B, và họ loại bỏ lần ghi đặt nó thành C. Nếu các lần ghi tình cờ có cùng timestamp, người thắng có thể được chọn bằng cách so sánh các giá trị (ví dụ, trong trường hợp chuỗi, lấy cái đứng trước hơn trong bảng chữ cái).
Cách tiếp cận này được gọi là last write wins (LWW, lần ghi cuối cùng thắng) vì lần ghi có timestamp lớn nhất có thể được coi là “cuối cùng”. Tuy nhiên, thuật ngữ này gây hiểu nhầm, vì khi hai lần ghi đồng thời như trong Hình 6-9, cái nào cũ hơn và cái nào sau hơn là không xác định, và do đó thứ tự timestamp của các lần ghi đồng thời về cơ bản là ngẫu nhiên.
Do đó, ý nghĩa thực sự của LWW là: khi cùng một bản ghi được ghi đồng thời trên các leader khác nhau, một trong những lần ghi đó được chọn ngẫu nhiên là người thắng, và các lần ghi khác bị loại bỏ im lặng, dù chúng đã được xử lý thành công tại các leader tương ứng. Điều này đạt được mục tiêu rằng cuối cùng tất cả các replica đều đạt đến trạng thái nhất quán, nhưng với cái giá là mất dữ liệu.
Nếu bạn có thể tránh xung đột, ví dụ bằng cách chỉ chèn các bản ghi với khóa duy nhất như UUID, và không bao giờ cập nhật chúng, thì LWW không thành vấn đề. Nhưng nếu bạn cập nhật các bản ghi hiện có, hoặc nếu các leader khác nhau có thể chèn các bản ghi với cùng khóa, thì bạn phải quyết định xem liệu các cập nhật bị mất có là vấn đề với ứng dụng của bạn hay không. Nếu cập nhật bị mất là không chấp nhận được, bạn cần sử dụng một trong các cách tiếp cận giải quyết xung đột được mô tả dưới đây.
Một vấn đề khác với LWW là nếu đồng hồ thực (ví dụ: Unix timestamp) được sử dụng làm timestamp cho các lần ghi, hệ thống trở nên rất nhạy cảm với đồng bộ hóa đồng hồ. Nếu một node có đồng hồ chạy trước các node khác, và bạn cố ghi đè một giá trị được ghi bởi node đó, lần ghi của bạn có thể bị bỏ qua vì nó có thể có timestamp thấp hơn, ngay cả khi nó rõ ràng xảy ra sau. Vấn đề này có thể được giải quyết bằng cách sử dụng logical clock (đồng hồ logic), mà chúng ta sẽ thảo luận trong “ID Generators and Logical Clocks”.
Giải quyết xung đột thủ công
Nếu việc loại bỏ ngẫu nhiên một số lần ghi của bạn là không mong muốn, lựa chọn tiếp theo là giải quyết xung đột thủ công. Bạn có thể quen thuộc với giải quyết xung đột thủ công từ Git và các hệ thống kiểm soát phiên bản khác: nếu các commit trên hai nhánh khác nhau chỉnh sửa cùng dòng của cùng tệp, và bạn cố gắng hợp nhất các nhánh đó, bạn sẽ gặp xung đột merge cần được giải quyết trước khi merge hoàn tất.
Trong cơ sở dữ liệu, việc để một xung đột dừng toàn bộ quá trình nhân bản cho đến khi con người giải quyết nó sẽ không thực tế. Thay vào đó, các cơ sở dữ liệu thường lưu trữ tất cả các giá trị được ghi đồng thời cho một bản ghi nhất định, ví dụ cả B và C trong Hình 6-9. Các giá trị này đôi khi được gọi là siblings (anh chị em). Lần tiếp theo bạn truy vấn bản ghi đó, cơ sở dữ liệu trả về tất cả các giá trị đó, thay vì chỉ giá trị mới nhất. Bạn có thể giải quyết các giá trị đó theo bất kỳ cách nào bạn muốn, tự động trong code ứng dụng (ví dụ, bạn có thể nối B và C thành “B/C”), hoặc bằng cách hỏi người dùng. Sau đó bạn ghi lại một giá trị mới vào cơ sở dữ liệu để giải quyết xung đột.
Cách tiếp cận giải quyết xung đột này được sử dụng trong một số hệ thống, chẳng hạn CouchDB. Tuy nhiên, nó cũng có một số vấn đề:
- API của cơ sở dữ liệu thay đổi: ví dụ, trước đây tiêu đề của trang wiki chỉ là một chuỗi, giờ nó trở thành một tập hợp các chuỗi thường chứa một phần tử, nhưng đôi khi có thể chứa nhiều phần tử nếu có xung đột. Điều này có thể làm cho dữ liệu khó làm việc hơn trong code ứng dụng.
- Yêu cầu người dùng tự hợp nhất các siblings là rất nhiều công việc, cả cho nhà phát triển ứng dụng (người cần xây dựng giao diện người dùng để giải quyết xung đột) lẫn cho người dùng (người có thể bị nhầm lẫn về những gì họ đang được yêu cầu làm và tại sao). Trong nhiều trường hợp, tốt hơn là hợp nhất tự động hơn là làm phiền người dùng.
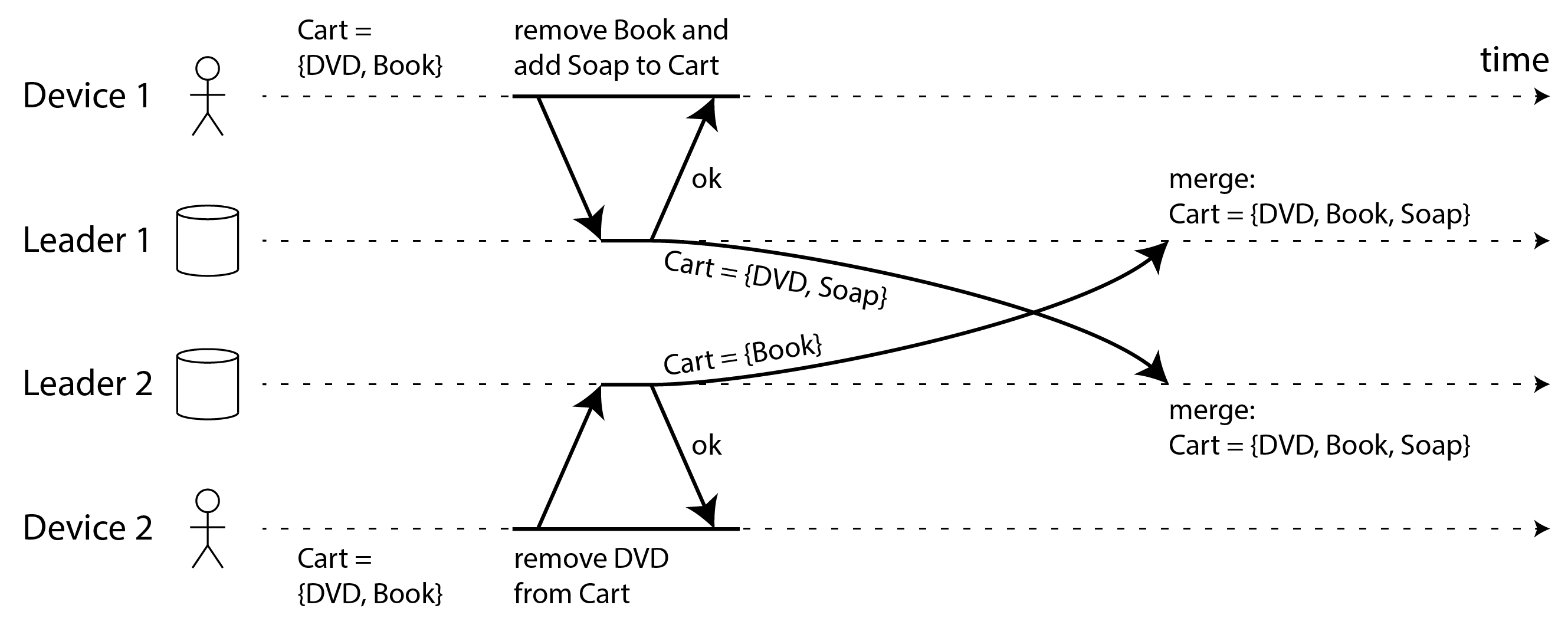
- Hợp nhất siblings tự động có thể dẫn đến hành vi bất ngờ nếu không được thực hiện cẩn thận. Ví dụ, giỏ hàng trên Amazon từng cho phép cập nhật đồng thời, sau đó được hợp nhất bằng cách giữ tất cả các mặt hàng giỏ hàng xuất hiện trong bất kỳ sibling nào (tức là lấy hợp tập của các giỏ hàng). Điều này có nghĩa là nếu khách hàng đã xóa một mặt hàng khỏi giỏ hàng trong một sibling, nhưng một sibling khác vẫn chứa mặt hàng cũ đó, mặt hàng đã xóa sẽ bất ngờ xuất hiện lại trong giỏ hàng của khách hàng 45. Hình 6-10 cho thấy một ví dụ mà Thiết bị 1 xóa Sách khỏi giỏ hàng và đồng thời Thiết bị 2 xóa DVD, nhưng sau khi hợp nhất xung đột cả hai mặt hàng đều xuất hiện lại.
- Nếu nhiều node quan sát xung đột và đồng thời giải quyết nó, quá trình giải quyết xung đột có thể tự giới thiệu một xung đột mới. Các giải pháp đó thậm chí có thể không nhất quán: ví dụ, một node có thể hợp nhất B và C thành “B/C” và một node khác có thể hợp nhất chúng thành “C/B” nếu bạn không cẩn thận để sắp xếp chúng một cách nhất quán. Khi xung đột giữa “B/C” và “C/B” được hợp nhất, nó có thể dẫn đến “B/C/C/B” hoặc điều gì đó tương tự bất ngờ.
Giải quyết xung đột tự động
Đối với nhiều ứng dụng, cách tốt nhất để xử lý xung đột là sử dụng một thuật toán tự động hợp nhất các ghi đồng thời vào một trạng thái nhất quán. Giải quyết xung đột tự động đảm bảo rằng tất cả các replica hội tụ về cùng một trạng thái, tức là tất cả các replica đã xử lý cùng tập hợp lần ghi đều có cùng trạng thái, bất kể thứ tự mà các lần ghi đến.
LWW là một ví dụ đơn giản về thuật toán giải quyết xung đột. Các thuật toán hợp nhất tinh vi hơn đã được phát triển cho các loại dữ liệu khác nhau, với mục tiêu bảo tồn hiệu ứng dự định của tất cả các cập nhật càng nhiều càng tốt, do đó tránh mất dữ liệu:
- Nếu dữ liệu là văn bản (ví dụ: tiêu đề hoặc nội dung của trang wiki), chúng ta có thể phát hiện những ký tự nào đã được chèn hoặc xóa từ phiên bản này sang phiên bản tiếp theo. Kết quả hợp nhất sau đó bảo tồn tất cả các chèn và xóa được thực hiện trong bất kỳ sibling nào. Nếu người dùng đồng thời chèn văn bản tại cùng vị trí, nó có thể được sắp xếp một cách xác định để tất cả các node nhận được cùng kết quả hợp nhất.
- Nếu dữ liệu là một tập hợp các mục (có thứ tự như danh sách to-do, hoặc không có thứ tự như giỏ hàng), chúng ta có thể hợp nhất nó tương tự như văn bản bằng cách theo dõi các chèn và xóa. Để tránh vấn đề giỏ hàng trong Hình 6-10, các thuật toán theo dõi thực tế rằng Sách và DVD đã bị xóa, vì vậy kết quả hợp nhất là Cart = {Soap}.
- Nếu dữ liệu là một số nguyên đại diện cho bộ đếm có thể được tăng hoặc giảm (ví dụ: số lượt thích trên một bài đăng mạng xã hội), thuật toán hợp nhất có thể cho biết bao nhiêu lần tăng và giảm đã xảy ra trên mỗi sibling, và cộng chúng lại đúng cách để kết quả không đếm hai lần và không bỏ mất các cập nhật.
- Nếu dữ liệu là một ánh xạ key-value (khóa-giá trị), chúng ta có thể hợp nhất các cập nhật cho cùng khóa bằng cách áp dụng một trong các thuật toán giải quyết xung đột khác cho các giá trị dưới khóa đó. Các cập nhật cho các khóa khác nhau có thể được xử lý độc lập với nhau.
Có những giới hạn về những gì có thể thực hiện với giải quyết xung đột. Ví dụ, nếu bạn muốn thực thi rằng một danh sách không chứa nhiều hơn năm mục, và nhiều người dùng đồng thời thêm mục vào danh sách đến mức có nhiều hơn năm mục tổng cộng, lựa chọn duy nhất của bạn là bỏ một số mục. Tuy nhiên, giải quyết xung đột tự động là đủ để xây dựng nhiều ứng dụng hữu ích. Và nếu bạn bắt đầu từ yêu cầu muốn xây dựng một ứng dụng cộng tác offline-first hoặc local-first, thì giải quyết xung đột là không thể tránh khỏi, và tự động hóa nó thường là cách tiếp cận tốt nhất.
CRDT và Operational Transformation
Hai họ thuật toán thường được sử dụng để triển khai giải quyết xung đột tự động: Conflict-free replicated datatypes (CRDT, kiểu dữ liệu nhân bản không xung đột) 46 và Operational Transformation (OT, biến đổi hoạt động) 47. Chúng có các triết lý thiết kế và đặc điểm hiệu suất khác nhau, nhưng cả hai đều có thể thực hiện hợp nhất tự động cho tất cả các loại dữ liệu được đề cập ở trên.
Hình 6-11 cho thấy một ví dụ về cách OT và CRDT hợp nhất các cập nhật đồng thời cho một văn bản. Giả sử bạn có hai replica đều bắt đầu với văn bản “ice”. Một replica thêm vào đầu chữ “n” để tạo thành “nice”, trong khi đồng thời replica kia thêm dấu chấm than vào cuối để tạo thành “ice!”.
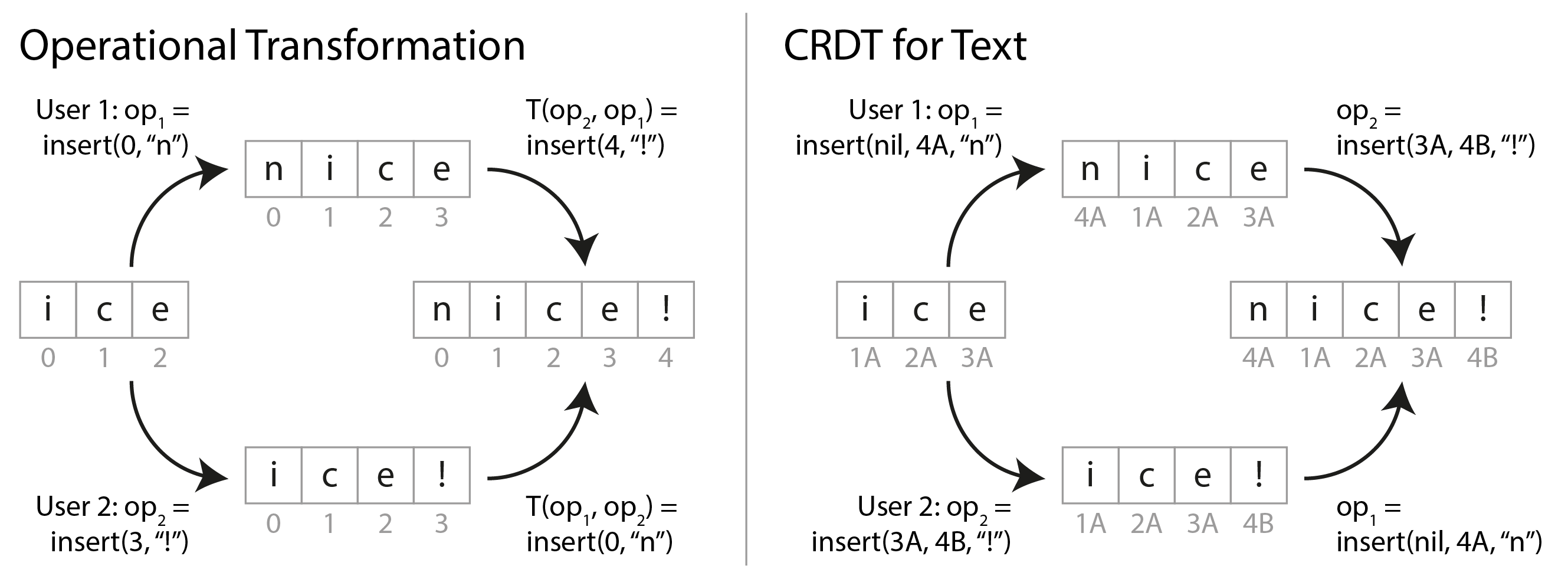
Kết quả hợp nhất “nice!” được đạt được theo cách khác nhau bởi cả hai loại thuật toán:
- OT
- Chúng ta ghi lại chỉ số mà các ký tự được chèn hoặc xóa: “n” được chèn tại chỉ số 0, và “!” tại chỉ số 3. Tiếp theo, các replica trao đổi các hoạt động của chúng. Việc chèn “n” tại 0 có thể được áp dụng như vậy, nhưng nếu việc chèn “!” tại 3 được áp dụng cho trạng thái “nice” chúng ta sẽ nhận được “nic!e”, điều này không đúng. Do đó chúng ta cần biến đổi chỉ số của mỗi hoạt động để tính đến các hoạt động đồng thời đã được áp dụng; trong trường hợp này, việc chèn “!” được biến đổi thành chỉ số 4 để tính đến việc chèn “n” tại chỉ số trước đó.
- CRDT
- Hầu hết các CRDT gán cho mỗi ký tự một ID duy nhất, bất biến và sử dụng chúng để xác định vị trí của các lần chèn/xóa, thay vì dùng chỉ số. Ví dụ, trong Hình 6-11 chúng ta gán ID 1A cho “i”, ID 2A cho “c”, v.v. Khi chèn dấu chấm than, chúng ta tạo một hoạt động chứa ID của ký tự mới (4B) và ID của ký tự hiện có sau đó chúng ta muốn chèn (3A). Để chèn vào đầu chuỗi, chúng ta cung cấp “nil” là ID ký tự đứng trước. Các lần chèn đồng thời tại cùng vị trí được sắp xếp theo ID của các ký tự. Điều này đảm bảo các replica hội tụ mà không cần thực hiện bất kỳ biến đổi nào.
Có nhiều thuật toán dựa trên các biến thể của những ý tưởng này. Danh sách/mảng có thể được hỗ trợ tương tự, sử dụng các phần tử danh sách thay vì các ký tự, và các kiểu dữ liệu khác như ánh xạ key-value có thể được thêm vào khá dễ dàng. Có một số đánh đổi về hiệu suất và chức năng giữa OT và CRDT, nhưng có thể kết hợp các ưu điểm của CRDT và OT trong một thuật toán 48.
OT thường được sử dụng nhất cho chỉnh sửa văn bản cộng tác thời gian thực, ví dụ: trong Google Docs 32, trong khi CRDT có thể được tìm thấy trong các cơ sở dữ liệu phân tán như Redis Enterprise, Riak và Azure Cosmos DB 49. Sync engine cho dữ liệu JSON có thể được triển khai với cả CRDT (ví dụ: Automerge hoặc Yjs) và với OT (ví dụ: ShareDB).
Xung đột là gì?
Một số loại xung đột rõ ràng. Trong ví dụ ở Hình 6-9, hai lần ghi đồng thời sửa đổi cùng một trường trong cùng một bản ghi, đặt nó thành hai giá trị khác nhau. Không còn nghi ngờ gì đây là một xung đột.
Các loại xung đột khác có thể khó phát hiện hơn. Ví dụ, hãy xem xét một hệ thống đặt phòng họp: nó theo dõi phòng nào được đặt bởi nhóm người nào vào thời điểm nào. Ứng dụng này cần đảm bảo rằng mỗi phòng chỉ được đặt bởi một nhóm người tại bất kỳ thời điểm nào (tức là không được có bất kỳ đặt phòng chồng chéo nào cho cùng một phòng). Trong trường hợp này, xung đột có thể phát sinh nếu hai đặt phòng khác nhau được tạo cho cùng một phòng vào cùng thời điểm. Ngay cả khi ứng dụng kiểm tra tính khả dụng trước khi cho phép người dùng đặt phòng, có thể có xung đột nếu hai đặt phòng được thực hiện trên hai leader khác nhau.
Không có câu trả lời nhanh chóng sẵn có, nhưng trong các chương tiếp theo chúng ta sẽ vạch ra con đường hướng tới một sự hiểu biết tốt về vấn đề này. Chúng ta sẽ thấy thêm một số ví dụ về xung đột trong Chương 8, và trong “Ordering events to capture causality” chúng ta sẽ thảo luận về các cách tiếp cận có thể mở rộng để phát hiện và giải quyết xung đột trong một hệ thống nhân bản.
Nhân bản Không Leader
Các cách tiếp cận nhân bản mà chúng ta đã thảo luận cho đến nay trong chương này, bao gồm nhân bản single-leader và multi-leader, đều dựa trên ý tưởng rằng client gửi yêu cầu ghi đến một node (leader), và hệ thống cơ sở dữ liệu đảm nhận việc sao chép lần ghi đó đến các replica khác. Một leader xác định thứ tự xử lý các lần ghi, và các follower áp dụng các lần ghi của leader ghi theo thứ tự giống nhau.
Một số hệ thống lưu trữ dữ liệu theo hướng tiếp cận khác, từ bỏ khái niệm leader và cho phép bất kỳ replica nào trực tiếp chấp nhận ghi từ client. Một số hệ thống dữ liệu nhân bản sớm nhất đã không có leader 1 50, nhưng ý tưởng này hầu như bị lãng quên trong thời kỳ thống trị của cơ sở dữ liệu quan hệ. Kiến trúc này lại trở nên phổ biến sau khi Amazon sử dụng nó cho hệ thống nội bộ Dynamo vào năm 2007 45. Riak, Cassandra và ScyllaDB là các kho dữ liệu mã nguồn mở với mô hình nhân bản không có leader, lấy cảm hứng từ Dynamo, vì vậy loại cơ sở dữ liệu này còn được gọi là Dynamo-style (kiểu Dynamo).
Note
Trong một số triển khai leaderless (không có leader), client trực tiếp gửi các lần ghi đến nhiều replica, trong khi ở các hệ thống khác, một node điều phối (coordinator node) thực hiện điều này thay mặt cho client. Tuy nhiên, khác với cơ sở dữ liệu có leader, coordinator đó không áp đặt một thứ tự cụ thể cho các lần ghi. Như chúng ta sẽ thấy, sự khác biệt trong thiết kế này có hệ quả sâu sắc đối với cách sử dụng cơ sở dữ liệu.
Ghi vào Cơ sở Dữ liệu Khi Một Node Ngừng Hoạt Động
Hãy tưởng tượng bạn có một cơ sở dữ liệu với ba replica, và một trong các replica đó hiện đang không khả dụng, có thể nó đang được khởi động lại để cài đặt bản cập nhật hệ thống. Trong cấu hình single-leader, nếu bạn muốn tiếp tục xử lý các lần ghi, bạn có thể cần thực hiện failover (xem “Xử lý sự cố Node”).
Mặt khác, trong cấu hình leaderless, failover không tồn tại. Hình 6-12 cho thấy điều gì xảy ra: client (user 1234) gửi lần ghi đến cả ba replica song song, và hai replica khả dụng chấp nhận lần ghi nhưng replica không khả dụng bỏ lỡ nó. Giả sử rằng hai trong số ba replica xác nhận lần ghi là đủ: sau khi user 1234 nhận được hai phản hồi ok, chúng ta coi lần ghi là thành công. Client đơn giản bỏ qua thực tế là một trong các replica đã bỏ lỡ lần ghi.
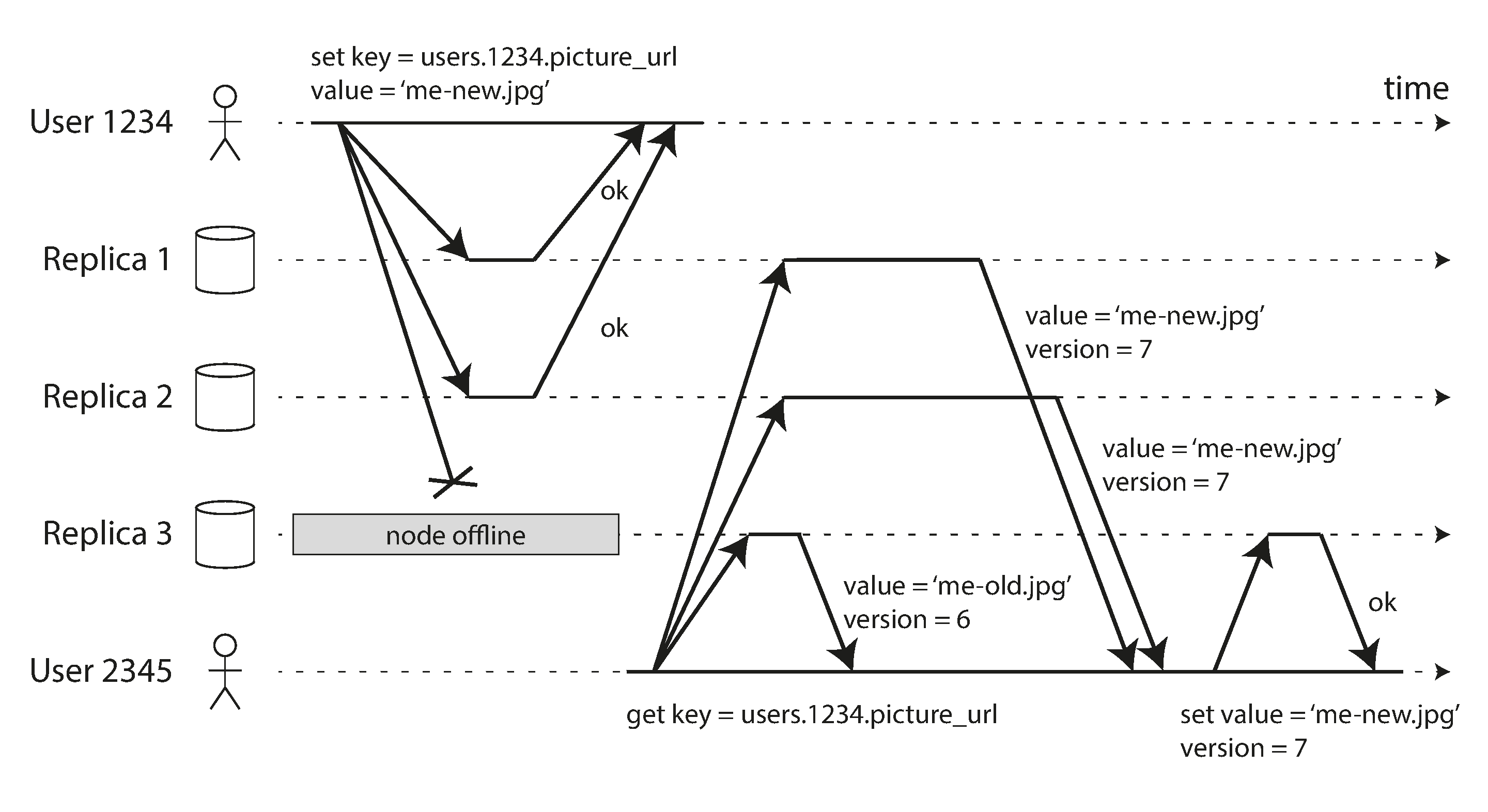
Bây giờ hãy tưởng tượng rằng node không khả dụng trở lại trực tuyến, và các client bắt đầu đọc từ nó. Bất kỳ lần ghi nào đã xảy ra trong khi node ngừng hoạt động đều bị thiếu trên node đó. Vì vậy, nếu bạn đọc từ node đó, bạn có thể nhận được các giá trị stale (lỗi thời) làm phản hồi.
Để giải quyết vấn đề đó, khi một client đọc từ cơ sở dữ liệu, nó không chỉ gửi yêu cầu đến một replica: các yêu cầu đọc cũng được gửi đến nhiều node song song. Client có thể nhận được các phản hồi khác nhau từ các node khác nhau; ví dụ, giá trị cập nhật từ một node và giá trị lỗi thời từ node khác.
Để phân biệt phản hồi nào là cập nhật và phản hồi nào đã lỗi thời, mỗi giá trị được ghi cần được gắn thẻ với số phiên bản hoặc dấu thời gian, tương tự như những gì chúng ta đã thấy trong “Lần ghi cuối thắng (loại bỏ các lần ghi đồng thời)”. Khi một client nhận được nhiều giá trị trong phản hồi cho một lần đọc, nó sử dụng giá trị có dấu thời gian lớn nhất (ngay cả khi giá trị đó chỉ được trả về bởi một replica, và nhiều replica khác trả về các giá trị cũ hơn). Xem “Phát hiện các lần ghi đồng thời” để biết thêm chi tiết.
Bắt kịp các lần ghi bị bỏ lỡ
Hệ thống nhân bản nên đảm bảo rằng cuối cùng tất cả dữ liệu được sao chép đến mọi replica. Sau khi một node không khả dụng trở lại trực tuyến, làm thế nào để nó bắt kịp các lần ghi mà nó đã bỏ lỡ? Một số cơ chế được sử dụng trong các kho dữ liệu kiểu Dynamo:
- Read repair (sửa chữa khi đọc)
- Khi một client thực hiện đọc từ nhiều node song song, nó có thể phát hiện bất kỳ phản hồi lỗi thời nào. Ví dụ, trong Hình 6-12, user 2345 nhận được giá trị phiên bản 6 từ replica 3 và giá trị phiên bản 7 từ replica 1 và 2. Client nhận thấy rằng replica 3 có giá trị lỗi thời và ghi giá trị mới hơn trở lại replica đó. Cách tiếp cận này hoạt động tốt cho các giá trị được đọc thường xuyên.
- Hinted handoff (bàn giao có gợi ý)
- Nếu một replica không khả dụng, một replica khác có thể lưu trữ các lần ghi thay mặt cho nó dưới dạng hints (gợi ý). Khi replica lẽ ra phải nhận những lần ghi đó trở lại, replica lưu trữ các gợi ý sẽ gửi chúng đến replica đã phục hồi, rồi xóa các gợi ý. Quá trình handoff (bàn giao) này giúp đưa các replica lên phiên bản cập nhật ngay cả đối với các giá trị không bao giờ được đọc, và do đó không được xử lý bởi read repair.
- Anti-entropy (chống entropy)
- Ngoài ra, có một tiến trình nền chạy định kỳ tìm kiếm sự khác biệt trong dữ liệu giữa các replica và sao chép bất kỳ dữ liệu nào bị thiếu từ một replica sang replica khác. Khác với replication log trong nhân bản dựa trên leader, tiến trình anti-entropy này không sao chép các lần ghi theo bất kỳ thứ tự cụ thể nào, và có thể có độ trễ đáng kể trước khi dữ liệu được sao chép.
Quorum cho đọc và ghi
Trong ví dụ về Hình 6-12, chúng ta coi lần ghi là thành công mặc dù nó chỉ được xử lý trên hai trong ba replica. Điều gì xảy ra nếu chỉ một trong ba replica chấp nhận lần ghi? Chúng ta có thể đẩy điều này đến đâu?
Nếu chúng ta biết rằng mỗi lần ghi thành công được đảm bảo có mặt trên ít nhất hai trong ba replica, điều đó có nghĩa là nhiều nhất một replica có thể lỗi thời. Vì vậy, nếu chúng ta đọc từ ít nhất hai replica, chúng ta có thể chắc chắn rằng ít nhất một trong hai replica là cập nhật. Nếu replica thứ ba ngừng hoạt động hoặc phản hồi chậm, các lần đọc vẫn có thể tiếp tục trả về giá trị cập nhật.
Tổng quát hơn, nếu có n replica, mỗi lần ghi phải được xác nhận bởi w node để được coi là thành công, và chúng ta phải truy vấn ít nhất r node cho mỗi lần đọc. (Trong ví dụ của chúng ta, n = 3, w = 2, r = 2.) Miễn là w + r > n, chúng ta kỳ vọng nhận được giá trị cập nhật khi đọc, bởi vì ít nhất một trong số r node mà chúng ta đọc từ đó phải là cập nhật. Các lần đọc và ghi tuân theo các giá trị r và w này được gọi là quorum reads và writes 50. Bạn có thể nghĩ về r và w như là số phiếu tối thiểu cần thiết để lần đọc hoặc ghi là hợp lệ.
Trong các cơ sở dữ liệu kiểu Dynamo, các tham số n, w và r thường có thể cấu hình được. Một lựa chọn phổ biến là đặt n là số lẻ (thường là 3 hoặc 5) và đặt w = r = (n + 1) / 2 (làm tròn lên). Tuy nhiên, bạn có thể thay đổi các con số theo ý muốn. Ví dụ, một tải công việc có ít lần ghi và nhiều lần đọc có thể được hưởng lợi từ việc đặt w = n và r = 1. Điều này làm cho các lần đọc nhanh hơn, nhưng có nhược điểm là chỉ một node bị lỗi sẽ khiến tất cả các lần ghi cơ sở dữ liệu thất bại.
Note
Có thể có nhiều hơn n node trong cluster, nhưng bất kỳ giá trị cụ thể nào cũng chỉ được lưu trữ trên n node. Điều này cho phép tập dữ liệu được phân mảnh (sharded), hỗ trợ các tập dữ liệu lớn hơn bạn có thể chứa trên một node. Chúng ta sẽ quay lại phân mảnh trong Chương 7.
Điều kiện quorum, w + r > n, cho phép hệ thống chịu đựng các node không khả dụng như sau:
- Nếu w < n, chúng ta vẫn có thể xử lý các lần ghi nếu một node không khả dụng.
- Nếu r < n, chúng ta vẫn có thể xử lý các lần đọc nếu một node không khả dụng.
- Với n = 3, w = 2, r = 2 chúng ta có thể chịu đựng một node không khả dụng, như trong Hình 6-12.
- Với n = 5, w = 3, r = 3 chúng ta có thể chịu đựng hai node không khả dụng. Trường hợp này được minh họa trong Hình 6-13.
Thông thường, các lần đọc và ghi luôn được gửi đến tất cả n replica song song. Các tham số w và r xác định có bao nhiêu node chúng ta chờ đợi, tức là, có bao nhiêu trong số n node cần báo cáo thành công trước khi chúng ta coi lần đọc hoặc ghi là thành công.
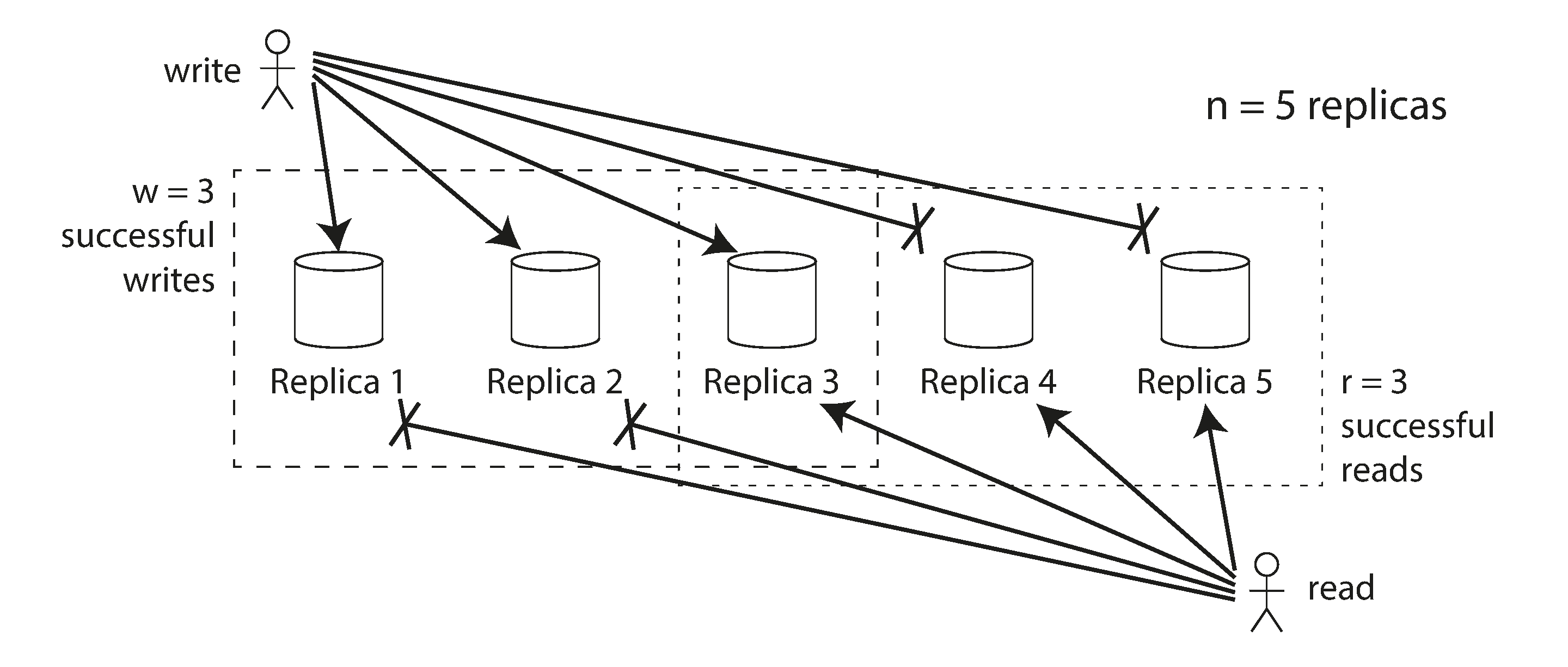
Nếu ít hơn số w hoặc r node cần thiết khả dụng, các lần ghi hoặc đọc sẽ trả về lỗi. Một node có thể không khả dụng vì nhiều lý do: vì node bị ngừng hoạt động (sập, tắt nguồn), do lỗi thực thi thao tác (không thể ghi vì đĩa đầy), do gián đoạn mạng giữa client và node, hoặc vì bất kỳ lý do nào khác. Chúng ta chỉ quan tâm liệu node đã trả về phản hồi thành công hay không và không cần phân biệt giữa các loại lỗi khác nhau.
Giới hạn của Tính nhất quán Quorum
Nếu bạn có n replica, và bạn chọn w và r sao cho w + r > n, bạn thường có thể kỳ vọng mỗi lần đọc trả về giá trị được ghi gần nhất cho một khóa. Điều này là vì tập hợp các node mà bạn đã ghi và tập hợp các node mà bạn đã đọc phải chồng lên nhau. Nghĩa là, trong số các node bạn đọc, phải có ít nhất một node có giá trị mới nhất (được minh họa trong Hình 6-13).
Thường thì r và w được chọn là đa số (nhiều hơn n/2) của các node, vì điều đó đảm bảo w + r > n trong khi vẫn chịu đựng tối đa n/2 (làm tròn xuống) node bị lỗi. Nhưng quorum không nhất thiết phải là đa số, điều quan trọng là các tập hợp node được sử dụng bởi các thao tác đọc và ghi phải chồng lên nhau trong ít nhất một node. Các phân công quorum khác cũng có thể thực hiện được, cho phép một số linh hoạt trong thiết kế thuật toán phân tán 51.
Bạn cũng có thể đặt w và r thành các số nhỏ hơn, sao cho w + r ≤ n (tức là, điều kiện quorum không được thỏa mãn). Trong trường hợp này, các lần đọc và ghi vẫn sẽ được gửi đến n node, nhưng cần số lượng phản hồi thành công nhỏ hơn để thao tác thành công.
Với w và r nhỏ hơn, bạn có nhiều khả năng đọc các giá trị lỗi thời hơn, bởi vì có nhiều khả năng hơn lần đọc của bạn không bao gồm node có giá trị mới nhất. Mặt tích cực, cấu hình này cho phép độ trễ thấp hơn và tính khả dụng cao hơn: nếu có gián đoạn mạng và nhiều replica trở nên không thể truy cập, có cơ hội cao hơn bạn có thể tiếp tục xử lý các lần đọc và ghi. Chỉ khi số lượng replica có thể truy cập giảm xuống dưới w hoặc r thì cơ sở dữ liệu mới trở nên không khả dụng để ghi hoặc đọc, tương ứng.
Tuy nhiên, ngay cả với w + r > n, có những trường hợp biên trong đó các thuộc tính nhất quán có thể gây nhầm lẫn. Một số tình huống bao gồm:
- Nếu một node mang giá trị mới bị lỗi, và dữ liệu của nó được khôi phục từ một replica mang giá trị cũ, số lượng replica lưu trữ giá trị mới có thể giảm xuống dưới w, phá vỡ điều kiện quorum.
- Trong khi một quá trình tái cân bằng đang diễn ra, trong đó một số dữ liệu được chuyển từ node này sang node khác (xem Chương 7), các node có thể có các quan điểm không nhất quán về những node nào nên lưu giữ n replica cho một giá trị cụ thể. Điều này có thể dẫn đến các quorum đọc và ghi không còn chồng lên nhau.
- Nếu một lần đọc đồng thời với một thao tác ghi, lần đọc có thể hoặc có thể không thấy giá trị được ghi đồng thời. Đặc biệt, có thể một lần đọc thấy giá trị mới, và một lần đọc tiếp theo thấy giá trị cũ, như chúng ta sẽ thấy trong “Tính tuyến tính hóa và quorum”.
- Nếu một lần ghi thành công trên một số replica nhưng thất bại trên các replica khác (ví dụ vì đĩa trên một số node đầy), và tổng thể thành công trên ít hơn w replica, nó không được khôi phục trên các replica nơi nó đã thành công. Điều này có nghĩa là nếu một lần ghi được báo cáo là thất bại, các lần đọc tiếp theo có thể hoặc có thể không trả về giá trị từ lần ghi đó 52.
- Nếu cơ sở dữ liệu sử dụng dấu thời gian từ đồng hồ thực tế để xác định lần ghi nào mới hơn (như Cassandra và ScyllaDB làm, ví dụ), các lần ghi có thể bị loại bỏ một cách lặng lẽ nếu một node khác có đồng hồ chạy nhanh hơn đã ghi vào cùng khóa đó, một vấn đề chúng ta đã thấy trước đây trong “Lần ghi cuối thắng (loại bỏ các lần ghi đồng thời)”. Chúng ta sẽ thảo luận điều này chi tiết hơn trong “Phụ thuộc vào các đồng hồ được đồng bộ hóa”.
- Nếu hai lần ghi xảy ra đồng thời, một trong số chúng có thể được xử lý trước trên một replica, và cái kia có thể được xử lý trước trên một replica khác. Điều này dẫn đến xung đột, tương tự như những gì chúng ta đã thấy với nhân bản multi-leader (xem “Xử lý các lần ghi xung đột”). Chúng ta sẽ quay lại chủ đề này trong “Phát hiện các lần ghi đồng thời”.
Như vậy, mặc dù quorum có vẻ như đảm bảo rằng một lần đọc trả về giá trị được ghi gần nhất, trong thực tế không đơn giản như vậy. Các cơ sở dữ liệu kiểu Dynamo thường được tối ưu hóa cho các trường hợp sử dụng có thể chịu đựng eventual consistency (nhất quán cuối cùng). Các tham số w và r cho phép bạn điều chỉnh xác suất các giá trị lỗi thời được đọc 53, nhưng khôn ngoan là không nên coi chúng là đảm bảo tuyệt đối.
Giám sát độ lỗi thời
Từ góc độ vận hành, điều quan trọng là phải giám sát xem cơ sở dữ liệu của bạn có trả về kết quả cập nhật hay không. Ngay cả khi ứng dụng của bạn có thể chịu đựng các lần đọc lỗi thời, bạn cần biết về sức khỏe của nhân bản. Nếu nó tụt hậu đáng kể, nó nên cảnh báo bạn để bạn có thể điều tra nguyên nhân (ví dụ, một vấn đề trong mạng hoặc một node bị quá tải).
Đối với nhân bản dựa trên leader, cơ sở dữ liệu thường cung cấp các chỉ số cho replication lag (độ trễ nhân bản), mà bạn có thể đưa vào một hệ thống giám sát. Điều này là có thể vì các lần ghi được áp dụng cho leader và cho các follower theo cùng một thứ tự, và mỗi node có một vị trí trong replication log (số lượng các lần ghi nó đã áp dụng cục bộ). Bằng cách trừ vị trí hiện tại của follower khỏi vị trí hiện tại của leader, bạn có thể đo lường lượng replication lag.
Tuy nhiên, trong các hệ thống với nhân bản leaderless, không có thứ tự cố định nào mà các lần ghi được áp dụng, điều này làm cho việc giám sát khó khăn hơn. Số lượng gợi ý mà một replica lưu trữ để handoff có thể là một thước đo sức khỏe hệ thống, nhưng khó để diễn giải một cách hữu ích 54. Eventual consistency là một đảm bảo cố tình mơ hồ, nhưng để vận hành tốt, điều quan trọng là có thể định lượng được “eventual” (cuối cùng).
Hiệu năng của Nhân bản Single-Leader so với Leaderless
Một hệ thống nhân bản dựa trên single-leader có thể cung cấp các đảm bảo nhất quán mạnh mẽ mà khó hoặc không thể đạt được trong một hệ thống leaderless. Tuy nhiên, như chúng ta đã thấy trong “Các vấn đề với Replication Lag”, các lần đọc trong một hệ thống nhân bản dựa trên leader cũng có thể trả về các giá trị lỗi thời nếu bạn thực hiện chúng trên một follower được cập nhật không đồng bộ.
Đọc từ leader đảm bảo phản hồi cập nhật, nhưng nó gặp phải các vấn đề về hiệu năng:
- Thông lượng đọc bị giới hạn bởi khả năng xử lý yêu cầu của leader (ngược lại với read scaling, phân phối các lần đọc qua các replica được cập nhật không đồng bộ có thể trả về giá trị lỗi thời).
- Nếu leader bị lỗi, bạn phải chờ lỗi được phát hiện, và failover hoàn tất trước khi bạn có thể tiếp tục xử lý các yêu cầu. Ngay cả khi quá trình failover rất nhanh, người dùng sẽ nhận thấy vì thời gian phản hồi tạm thời tăng lên; nếu failover mất nhiều thời gian, hệ thống không khả dụng trong suốt thời gian đó.
- Hệ thống rất nhạy cảm với các vấn đề hiệu năng trên leader: nếu leader phản hồi chậm, ví dụ do quá tải hoặc một số tranh chấp tài nguyên, thời gian phản hồi tăng lên ngay lập tức ảnh hưởng đến người dùng.
Một lợi thế lớn của kiến trúc leaderless là nó có khả năng phục hồi tốt hơn trước các vấn đề như vậy. Vì không có failover, và các yêu cầu đi đến nhiều replica song song anyway, một replica trở nên chậm hoặc không khả dụng có rất ít tác động đến thời gian phản hồi: client đơn giản sử dụng các phản hồi từ các replica khác phản hồi nhanh hơn. Sử dụng các phản hồi nhanh nhất được gọi là request hedging (phòng hộ yêu cầu), và nó có thể giảm đáng kể tail latency (độ trễ đuôi) 55).
Về cốt lõi, khả năng phục hồi của hệ thống leaderless đến từ thực tế là nó không phân biệt giữa trường hợp bình thường và trường hợp lỗi. Điều này đặc biệt hữu ích khi xử lý các gray failures (lỗi xám) được gọi là vậy, trong đó một node không hoàn toàn ngừng hoạt động, nhưng chạy ở trạng thái suy giảm nơi nó xử lý các yêu cầu chậm bất thường 56, hoặc khi một node đơn giản bị quá tải (ví dụ, nếu một node đã ngoại tuyến một thời gian, việc phục hồi qua hinted handoff có thể gây ra nhiều tải bổ sung). Một hệ thống dựa trên leader phải quyết định liệu tình huống có đủ tệ để thực hiện failover không (bản thân điều đó có thể gây ra thêm gián đoạn), trong khi ở hệ thống leaderless câu hỏi đó thậm chí không nảy sinh.
Tuy vậy, các hệ thống leaderless cũng có thể có vấn đề về hiệu năng:
- Mặc dù hệ thống không cần thực hiện failover, một replica vẫn cần phát hiện khi một replica khác không khả dụng để nó có thể lưu trữ các gợi ý về các lần ghi mà replica không khả dụng đã bỏ lỡ. Khi replica không khả dụng trở lại, quá trình handoff cần gửi những gợi ý đó cho nó. Điều này đặt thêm tải lên các replica vào thời điểm mà hệ thống đã đang bị áp lực 54.
- Càng nhiều replica bạn có, quorum của bạn càng lớn, và bạn càng phải chờ nhiều phản hồi hơn trước khi một yêu cầu có thể hoàn thành. Ngay cả khi bạn chỉ chờ r hoặc w replica nhanh nhất phản hồi, và ngay cả khi bạn thực hiện các yêu cầu song song, r hoặc w lớn hơn tăng khả năng bạn gặp phải một replica chậm, làm tăng thời gian phản hồi tổng thể (xem “Sử dụng các chỉ số thời gian phản hồi”).
- Một gián đoạn mạng quy mô lớn ngắt kết nối client khỏi một số lượng lớn replica có thể làm cho việc hình thành quorum trở nên bất khả thi. Một số cơ sở dữ liệu leaderless cung cấp tùy chọn cấu hình cho phép bất kỳ replica có thể truy cập nào chấp nhận các lần ghi, ngay cả khi nó không phải là một trong các replica thông thường cho khóa đó (Riak và Dynamo gọi đây là sloppy quorum 45; Cassandra và ScyllaDB gọi nó là consistency level ANY). Không có đảm bảo rằng các lần đọc tiếp theo sẽ thấy giá trị được ghi, nhưng tùy thuộc vào ứng dụng, điều đó vẫn có thể tốt hơn là để lần ghi thất bại.
Nhân bản multi-leader có thể cung cấp khả năng phục hồi thậm chí lớn hơn trước các gián đoạn mạng so với nhân bản leaderless, vì các lần đọc và ghi chỉ yêu cầu giao tiếp với một leader, có thể được đặt cùng vị trí với client. Tuy nhiên, vì một lần ghi trên một leader được truyền không đồng bộ đến các leader khác, các lần đọc có thể lỗi thời tùy ý. Các lần đọc và ghi quorum cung cấp một sự thỏa hiệp: khả năng chịu lỗi tốt trong khi vẫn có xác suất cao đọc được dữ liệu cập nhật.
Vận hành đa vùng
Chúng ta đã thảo luận trước đây về nhân bản xuyên vùng như một trường hợp sử dụng cho nhân bản multi-leader (xem “Nhân bản Multi-Leader”). Nhân bản leaderless cũng phù hợp cho vận hành đa vùng, vì nó được thiết kế để chịu đựng các lần ghi đồng thời xung đột, các gián đoạn mạng và các đỉnh độ trễ.
Cassandra và ScyllaDB triển khai hỗ trợ đa vùng của họ trong mô hình leaderless thông thường: client gửi các lần ghi trực tiếp đến các replica trong tất cả các vùng, và bạn có thể chọn từ nhiều mức nhất quán (consistency levels) xác định có bao nhiêu phản hồi cần thiết để một yêu cầu thành công. Ví dụ, bạn có thể yêu cầu quorum trên các replica trong tất cả các vùng, quorum riêng biệt trong mỗi vùng, hoặc quorum chỉ trong vùng cục bộ của client. Quorum cục bộ tránh phải chờ các yêu cầu chậm đến các vùng khác, nhưng nó cũng có nhiều khả năng trả về kết quả lỗi thời hơn.
Riak giữ tất cả giao tiếp giữa client và các node cơ sở dữ liệu cục bộ trong một vùng, vì vậy n mô tả số lượng replica trong một vùng. Nhân bản xuyên vùng giữa các cluster cơ sở dữ liệu xảy ra không đồng bộ trong nền, theo kiểu tương tự với nhân bản multi-leader.
Phát hiện các Lần Ghi Đồng Thời
Giống như với nhân bản multi-leader, các cơ sở dữ liệu leaderless cho phép các lần ghi đồng thời vào cùng một khóa, dẫn đến các xung đột cần được giải quyết. Các xung đột như vậy có thể xảy ra khi các lần ghi xảy ra, nhưng không phải lúc nào cũng vậy: chúng cũng có thể được phát hiện sau đó trong quá trình read repair, hinted handoff hoặc anti-entropy.
Vấn đề là các sự kiện có thể đến theo thứ tự khác nhau tại các node khác nhau, do độ trễ mạng và các lỗi cục bộ. Ví dụ, Hình 6-14 minh họa hai client, A và B, đồng thời ghi vào một khóa X trong một kho dữ liệu ba node:
- Node 1 nhận được lệnh ghi từ A, nhưng không bao giờ nhận được lệnh ghi từ B do một sự cố tạm thời.
- Node 2 nhận được lệnh ghi từ A trước, rồi mới nhận lệnh ghi từ B.
- Node 3 nhận được lệnh ghi từ B trước, rồi mới nhận lệnh ghi từ A.
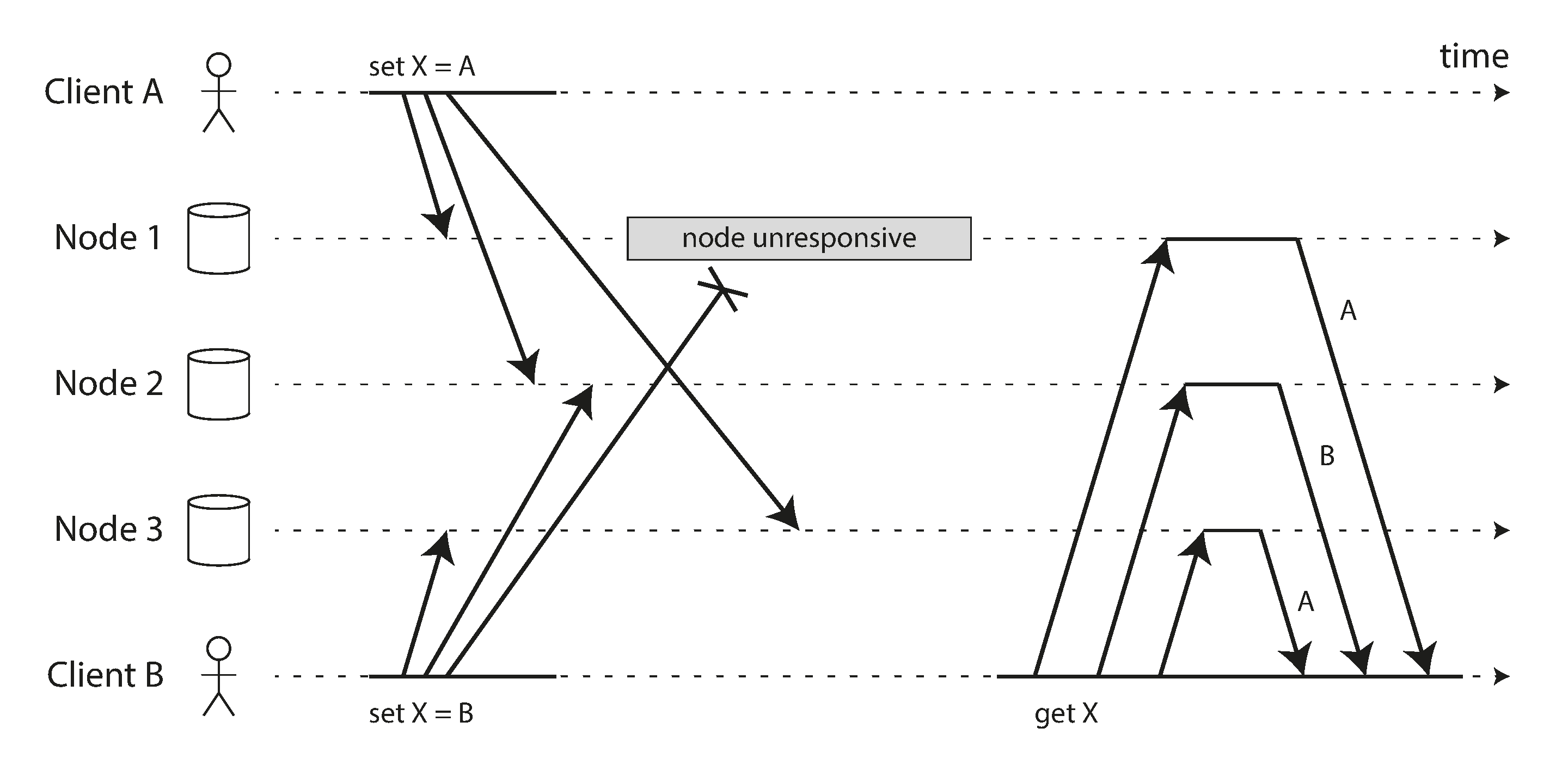
Nếu mỗi node đơn giản ghi đè giá trị của một khóa bất cứ khi nào nhận được yêu cầu ghi từ client, các node sẽ trở nên không nhất quán vĩnh viễn, như thể hiện qua yêu cầu get cuối cùng trong Hình 6-14: node 2 cho rằng giá trị cuối cùng của X là B, trong khi các node khác lại cho rằng giá trị đó là A.
Để đạt được tính nhất quán cuối cùng (eventually consistent), các bản sao cần hội tụ về cùng một giá trị. Để làm điều đó, chúng ta có thể dùng bất kỳ cơ chế giải quyết xung đột nào đã thảo luận trước đó trong “Xử lý các lệnh ghi xung đột”, chẳng hạn như last-write-wins (được Cassandra và ScyllaDB sử dụng), giải quyết thủ công, hoặc CRDT (được mô tả trong “CRDT và Operational Transformation”, và được Riak sử dụng).
Last-write-wins dễ triển khai: mỗi lệnh ghi được gắn thêm một timestamp, và giá trị có timestamp cao hơn luôn ghi đè lên giá trị có timestamp thấp hơn. Tuy nhiên, timestamp không cho biết liệu hai giá trị có thực sự xung đột (tức là được ghi đồng thời) hay không (chúng được ghi nối tiếp nhau). Nếu muốn giải quyết xung đột một cách tường minh, hệ thống cần cẩn thận hơn trong việc phát hiện các lệnh ghi đồng thời.
Quan hệ “xảy ra trước” và tính đồng thời
Làm thế nào để xác định hai thao tác có đồng thời hay không? Để hình thành trực giác, hãy xem xét một số ví dụ:
- Trong Hình 6-8, hai lệnh ghi không đồng thời: lệnh insert của A xảy ra trước lệnh increment của B, bởi vì giá trị mà B tăng chính là giá trị mà A đã chèn vào. Nói cách khác, thao tác của B dựa trên thao tác của A, do đó thao tác của B phải xảy ra sau. Chúng ta cũng nói rằng B phụ thuộc nhân quả (causally dependent) vào A.
- Ngược lại, hai lệnh ghi trong Hình 6-14 là đồng thời: khi mỗi client bắt đầu thao tác, nó không biết rằng một client khác cũng đang thực hiện thao tác trên cùng một khóa đó. Do vậy, không có sự phụ thuộc nhân quả nào giữa hai thao tác.
Một thao tác A xảy ra trước thao tác B khác nếu B biết về A, hoặc phụ thuộc vào A, hoặc xây dựng dựa trên A theo một cách nào đó. Việc xác định một thao tác có xảy ra trước thao tác khác hay không là chìa khóa để định nghĩa ý nghĩa của tính đồng thời. Thực ra, chúng ta có thể nói đơn giản rằng hai thao tác là đồng thời nếu không thao tác nào xảy ra trước thao tác kia (tức là không thao tác nào biết về thao tác kia) 57.
Do đó, bất cứ khi nào có hai thao tác A và B, có ba khả năng: hoặc A xảy ra trước B, hoặc B xảy ra trước A, hoặc A và B đồng thời. Điều chúng ta cần là một thuật toán để xác định liệu hai thao tác có đồng thời hay không. Nếu một thao tác xảy ra trước thao tác kia, thao tác sau nên ghi đè thao tác trước, nhưng nếu các thao tác là đồng thời, chúng ta có một xung đột cần được giải quyết.
![TIP] Concurrency, Time, and Relativity (Đồng thời, Thời gian và Tính tương đối)
Có vẻ như hai thao tác nên được gọi là đồng thời nếu chúng xảy ra “cùng một lúc”, nhưng thực ra, điều quan trọng không phải là chúng có thực sự chồng lấp về thời gian hay không. Do những vấn đề liên quan đến đồng hồ (clock) trong các hệ thống phân tán, rất khó để xác định liệu hai sự kiện có xảy ra vào đúng cùng một thời điểm không, đây là vấn đề sẽ được thảo luận chi tiết hơn trong Chương 9.
Để định nghĩa tính đồng thời, thời gian chính xác không quan trọng: chúng ta đơn giản gọi hai thao tác là đồng thời nếu cả hai đều không biết về nhau, bất kể thời điểm vật lý mà chúng xảy ra. Đôi khi người ta liên hệ nguyên tắc này với thuyết tương đối hẹp trong vật lý 57, lý thuyết này giới thiệu ý tưởng rằng thông tin không thể truyền đi nhanh hơn tốc độ ánh sáng. Kết quả là, hai sự kiện xảy ra ở những vị trí khác nhau không thể ảnh hưởng lẫn nhau nếu khoảng thời gian giữa chúng ngắn hơn thời gian ánh sáng cần để di chuyển qua khoảng cách đó.
Trong các hệ thống máy tính, hai thao tác có thể đồng thời dù về nguyên tắc tốc độ ánh sáng cho phép một thao tác ảnh hưởng đến thao tác kia. Ví dụ, nếu mạng bị chậm hoặc bị gián đoạn vào thời điểm đó, hai thao tác có thể xảy ra cách nhau một khoảng thời gian và vẫn được coi là đồng thời, bởi vì các vấn đề mạng đã ngăn không cho thao tác này biết về thao tác kia.
Nắm bắt quan hệ xảy ra trước
Hãy xem xét một thuật toán xác định liệu hai thao tác có đồng thời hay không, hoặc liệu thao tác nào xảy ra trước. Để đơn giản, hãy bắt đầu với một cơ sở dữ liệu chỉ có một bản sao. Sau khi hiểu cách thực hiện điều này trên một bản sao duy nhất, chúng ta có thể khái quát hóa cách tiếp cận này cho cơ sở dữ liệu không có leader với nhiều bản sao.
Hình 6-15 minh họa hai client đồng thời thêm các mặt hàng vào cùng một giỏ hàng. (Nếu ví dụ đó có vẻ quá tầm thường, hãy tưởng tượng thay vào đó là hai kiểm soát viên không lưu đồng thời thêm máy bay vào khu vực họ đang theo dõi.) Ban đầu, giỏ hàng trống. Hai client thực hiện tổng cộng năm lần ghi vào cơ sở dữ liệu:
- Client 1 thêm
milk(sữa) vào giỏ hàng. Đây là lần ghi đầu tiên cho khóa đó, vì vậy server lưu trữ thành công và gán cho nó phiên bản (version) 1. Server cũng trả về giá trị cho client, kèm theo số phiên bản. - Client 2 thêm
eggs(trứng) vào giỏ hàng, không biết rằng client 1 đồng thời đã thêmmilk(client 2 nghĩ rằngeggscủa mình là mặt hàng duy nhất trong giỏ). Server gán phiên bản 2 cho lần ghi này, và lưueggsvàmilknhư hai giá trị riêng biệt (sibling). Sau đó nó trả về cả hai giá trị cho client, kèm theo số phiên bản 2. - Client 1, không biết gì về lần ghi của client 2, muốn thêm
flour(bột mì) vào giỏ hàng, nên nó nghĩ rằng nội dung giỏ hàng hiện tại phải là[milk, flour]. Nó gửi giá trị này đến server, kèm theo số phiên bản 1 mà server đã cấp cho client 1 trước đó. Server có thể biết từ số phiên bản rằng lần ghi[milk, flour]thay thế giá trị trước đó[milk], nhưng nó đồng thời với[eggs]. Vì vậy, server gán phiên bản 3 cho[milk, flour], ghi đè giá trị phiên bản 1[milk], nhưng giữ lại giá trị phiên bản 2[eggs]và trả về cả hai giá trị còn lại cho client. - Trong khi đó, client 2 muốn thêm
ham(giăm bông) vào giỏ hàng, không biết rằng client 1 vừa thêmflour. Client 2 nhận được hai giá trị[milk]và[eggs]từ server trong lần phản hồi trước, vì vậy client bây giờ hợp nhất các giá trị đó và thêmhamđể tạo ra giá trị mới,[eggs, milk, ham]. Nó gửi giá trị đó đến server, kèm theo số phiên bản trước đó là 2. Server phát hiện rằng phiên bản 2 ghi đè[eggs]nhưng đồng thời với[milk, flour], vì vậy hai giá trị còn lại là[milk, flour]với phiên bản 3, và[eggs, milk, ham]với phiên bản 4. - Cuối cùng, client 1 muốn thêm
bacon(thịt xông khói). Trước đó nó đã nhận được[milk, flour]và[eggs]từ server ở phiên bản 3, vì vậy nó hợp nhất chúng, thêmbacon, và gửi giá trị cuối cùng[milk, flour, eggs, bacon]đến server, kèm theo số phiên bản 3. Thao tác này ghi đè[milk, flour](lưu ý rằng[eggs]đã bị ghi đè ở bước trước) nhưng đồng thời với[eggs, milk, ham], vì vậy server giữ lại hai giá trị đồng thời đó.
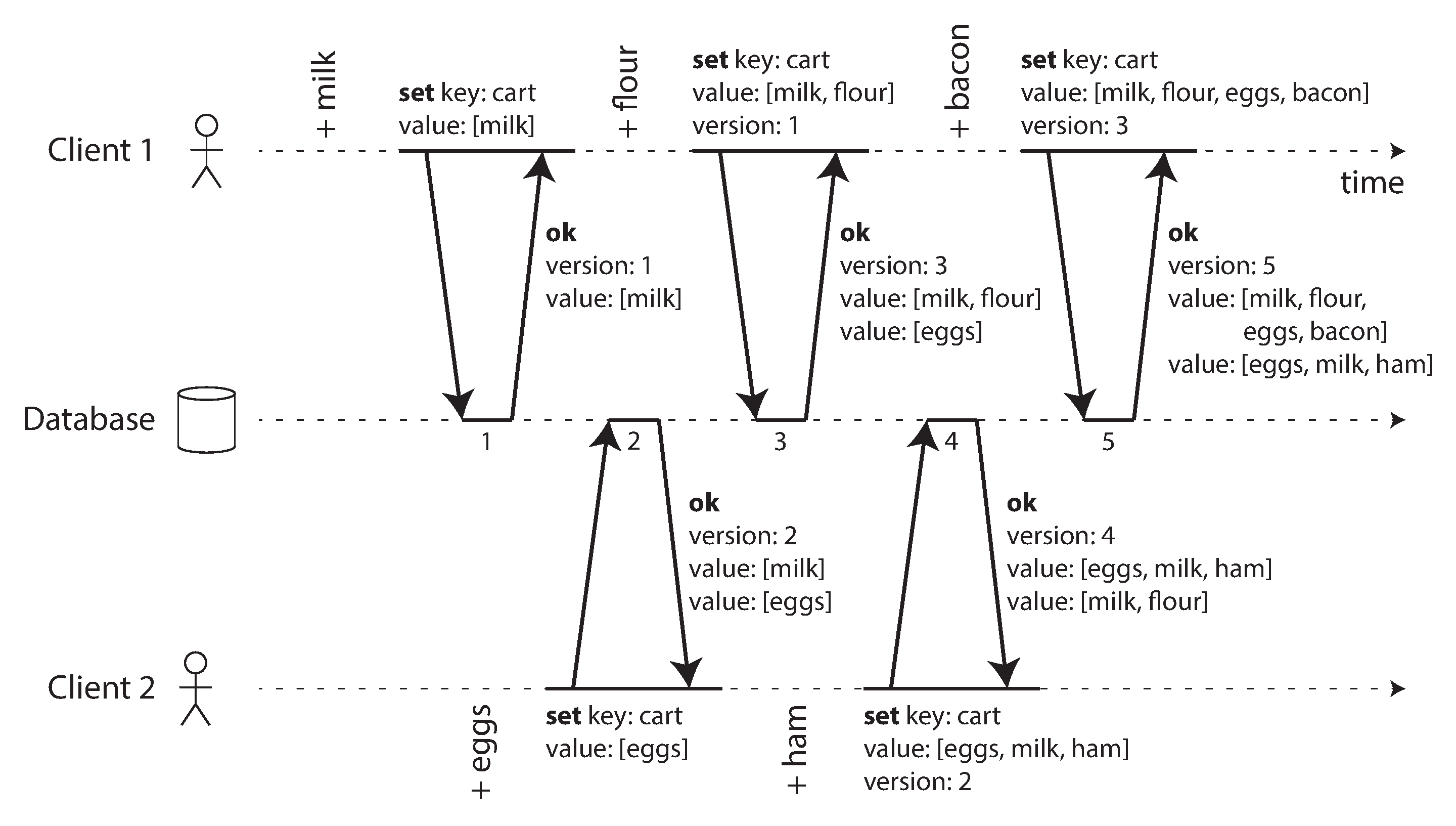
Luồng dữ liệu giữa các thao tác trong Hình 6-15 được minh họa trực quan trong Hình 6-16. Các mũi tên chỉ thao tác nào xảy ra trước thao tác nào khác, theo nghĩa thao tác sau biết về hoặc phụ thuộc vào thao tác trước. Trong ví dụ này, các client không bao giờ hoàn toàn cập nhật với dữ liệu trên server, vì luôn có một thao tác khác đang diễn ra đồng thời. Nhưng các phiên bản cũ của giá trị cuối cùng đều bị ghi đè, và không có lần ghi nào bị mất.
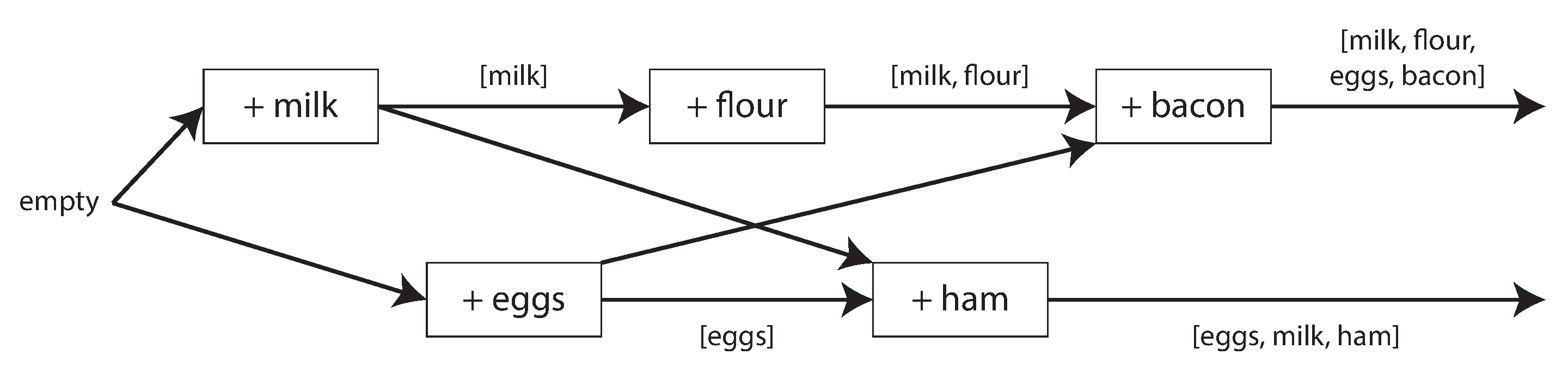
Lưu ý rằng server có thể xác định liệu hai thao tác có đồng thời hay không bằng cách xem xét các số phiên bản, mà không cần diễn giải bản thân giá trị (vì vậy giá trị có thể là bất kỳ cấu trúc dữ liệu nào). Thuật toán hoạt động như sau:
- Server duy trì một số phiên bản cho mỗi khóa, tăng số phiên bản mỗi khi khóa đó được ghi, và lưu số phiên bản mới cùng với giá trị được ghi.
- Khi một client đọc một khóa, server trả về tất cả các sibling, tức là tất cả các giá trị chưa bị ghi đè, cũng như số phiên bản mới nhất. Client phải đọc một khóa trước khi ghi.
- Khi một client ghi một khóa, nó phải bao gồm số phiên bản từ lần đọc trước đó, và phải hợp nhất tất cả các giá trị mà nó nhận được trong lần đọc trước, ví dụ: dùng CRDT hoặc bằng cách hỏi người dùng. Phản hồi từ yêu cầu ghi giống như một lần đọc, trả về tất cả các sibling, cho phép chúng ta nối tiếp nhiều lần ghi như trong ví dụ giỏ hàng.
- Khi server nhận được một lần ghi với số phiên bản cụ thể, nó có thể ghi đè tất cả các giá trị có số phiên bản đó hoặc thấp hơn (vì nó biết rằng chúng đã được hợp nhất vào giá trị mới), nhưng phải giữ lại tất cả các giá trị có số phiên bản cao hơn (vì những giá trị đó đồng thời với lần ghi đến).
Khi một lần ghi bao gồm số phiên bản từ lần đọc trước, điều đó cho biết trạng thái trước đó mà lần ghi dựa vào. Nếu bạn thực hiện ghi mà không bao gồm số phiên bản, nó sẽ đồng thời với tất cả các lần ghi khác, vì vậy nó sẽ không ghi đè bất cứ thứ gì mà chỉ được trả về như một trong các giá trị trong các lần đọc tiếp theo.
Version vector (Vectơ phiên bản)
Ví dụ trong Hình 6-15 chỉ sử dụng một bản sao duy nhất. Thuật toán thay đổi thế nào khi có nhiều bản sao nhưng không có leader?
Hình 6-15 sử dụng một số phiên bản duy nhất để nắm bắt các phụ thuộc giữa các thao tác, nhưng điều đó không đủ khi có nhiều bản sao đồng thời chấp nhận các lần ghi. Thay vào đó, chúng ta cần sử dụng một số phiên bản cho mỗi bản sao cũng như cho mỗi khóa. Mỗi bản sao tăng số phiên bản riêng của nó khi xử lý một lần ghi, và cũng theo dõi các số phiên bản mà nó đã thấy từ mỗi bản sao khác. Thông tin này chỉ ra giá trị nào cần ghi đè và giá trị nào cần giữ lại như sibling.
Tập hợp các số phiên bản từ tất cả các bản sao được gọi là version vector (vectơ phiên bản) 58. Có một số biến thể của ý tưởng này đang được sử dụng, nhưng thú vị nhất có lẽ là dotted version vector (vectơ phiên bản có dấu chấm) 59 60, được sử dụng trong Riak 2.0 61 62. Chúng ta sẽ không đi sâu vào chi tiết, nhưng cách thức hoạt động của nó khá giống với những gì chúng ta đã thấy trong ví dụ giỏ hàng.
Giống như các số phiên bản trong Hình 6-15, version vector được gửi từ các bản sao cơ sở dữ liệu đến client khi đọc giá trị, và cần được gửi lại cho cơ sở dữ liệu khi một giá trị được ghi sau đó. (Riak mã hóa version vector dưới dạng chuỗi mà nó gọi là causal context.) Version vector cho phép cơ sở dữ liệu phân biệt giữa ghi đè và các lần ghi đồng thời.
Version vector cũng đảm bảo rằng việc đọc từ một bản sao và sau đó ghi lại vào một bản sao khác là an toàn. Làm vậy có thể tạo ra các sibling, nhưng không có dữ liệu nào bị mất miễn là các sibling được hợp nhất đúng cách.
VERSION VECTORS AND VECTOR CLOCKS
Version vector đôi khi cũng được gọi là vector clock (đồng hồ vectơ), mặc dù chúng không hoàn toàn giống nhau. Sự khác biệt khá tinh tế, xin hãy xem các tài liệu tham khảo để biết chi tiết 60 63 64. Tóm lại, khi so sánh trạng thái của các bản sao, version vector là cấu trúc dữ liệu phù hợp để sử dụng.
Tóm tắt
Trong chương này, chúng ta đã xem xét vấn đề nhân bản (replication). Nhân bản có thể phục vụ nhiều mục đích:
- Tính sẵn sàng cao (High availability)
- Giữ cho hệ thống hoạt động, ngay cả khi một máy (hoặc nhiều máy, một zone, hoặc thậm chí cả một vùng) ngừng hoạt động
- Hoạt động ngắt kết nối (Disconnected operation)
- Cho phép ứng dụng tiếp tục hoạt động khi có sự gián đoạn mạng
- Độ trễ (Latency)
- Đặt dữ liệu gần người dùng về mặt địa lý, để người dùng có thể tương tác với nó nhanh hơn
- Khả năng mở rộng (Scalability)
- Có khả năng xử lý lượng đọc cao hơn so với một máy đơn lẻ có thể xử lý, bằng cách thực hiện đọc trên các bản sao
Mặc dù là một mục tiêu đơn giản, đó là giữ một bản sao của cùng dữ liệu trên nhiều máy, nhân bản lại hóa ra là một vấn đề khó khăn đáng kể. Nó đòi hỏi phải suy nghĩ cẩn thận về tính đồng thời và về tất cả những điều có thể xảy ra sai, và đối phó với hậu quả của những lỗi đó. Tối thiểu, chúng ta cần đối phó với các node không khả dụng và các gián đoạn mạng (và đó thậm chí còn chưa tính đến các loại lỗi nguy hiểm hơn, chẳng hạn như tình trạng hỏng dữ liệu âm thầm do lỗi phần mềm hoặc lỗi phần cứng).
Chúng ta đã thảo luận về ba cách tiếp cận chính để nhân bản:
- Nhân bản single-leader (một leader)
- Các client gửi tất cả các lệnh ghi đến một node duy nhất (leader), node đó gửi một luồng sự kiện thay đổi dữ liệu đến các bản sao khác (follower). Có thể thực hiện đọc trên bất kỳ bản sao nào, nhưng các lần đọc từ follower có thể đã cũ.
- Nhân bản multi-leader (nhiều leader)
- Các client gửi mỗi lệnh ghi đến một trong nhiều node leader, bất kỳ node nào trong số đó đều có thể chấp nhận các lần ghi. Các leader gửi luồng sự kiện thay đổi dữ liệu cho nhau và cho bất kỳ node follower nào.
- Nhân bản không có leader (Leaderless replication)
- Các client gửi mỗi lệnh ghi đến nhiều node, và đọc từ nhiều node song song để phát hiện và sửa chữa các node có dữ liệu cũ.
Mỗi cách tiếp cận đều có ưu và nhược điểm. Nhân bản single-leader phổ biến vì nó khá dễ hiểu và cung cấp tính nhất quán mạnh. Nhân bản multi-leader và leaderless có thể mạnh mẽ hơn khi có các node bị lỗi, gián đoạn mạng và độ trễ đột biến, nhưng với chi phí là phải giải quyết xung đột và cung cấp các đảm bảo nhất quán yếu hơn.
Nhân bản có thể là đồng bộ hoặc không đồng bộ, điều này có ảnh hưởng sâu sắc đến hành vi của hệ thống khi có lỗi. Mặc dù nhân bản không đồng bộ có thể nhanh khi hệ thống hoạt động trơn tru, điều quan trọng là phải tìm hiểu điều gì xảy ra khi độ trễ nhân bản tăng lên và các server gặp sự cố. Nếu một leader bị lỗi và bạn nâng một follower được cập nhật không đồng bộ lên làm leader mới, dữ liệu đã commit gần đây có thể bị mất.
Chúng ta đã xem xét một số hiệu ứng lạ có thể do độ trễ nhân bản gây ra, và đã thảo luận về một số mô hình nhất quán hữu ích để quyết định cách ứng dụng nên hành xử khi gặp độ trễ nhân bản:
- Nhất quán đọc sau ghi (Read-after-write consistency)
- Người dùng phải luôn thấy dữ liệu mà họ đã tự gửi.
- Đọc đơn điệu (Monotonic reads)
- Sau khi người dùng đã thấy dữ liệu tại một thời điểm, họ không được thấy dữ liệu từ một thời điểm trước đó sau này.
- Đọc tiền tố nhất quán (Consistent prefix reads)
- Người dùng nên thấy dữ liệu ở trạng thái có ý nghĩa nhân quả: ví dụ: thấy một câu hỏi và câu trả lời của nó theo đúng thứ tự.
Cuối cùng, chúng ta đã thảo luận về cách nhân bản multi-leader và leaderless đảm bảo rằng tất cả các bản sao cuối cùng hội tụ về trạng thái nhất quán: bằng cách sử dụng version vector hoặc thuật toán tương tự để phát hiện các lần ghi đồng thời, và bằng cách sử dụng thuật toán giải quyết xung đột như CRDT để hợp nhất các giá trị được ghi đồng thời. Last-write-wins và giải quyết xung đột thủ công cũng là các lựa chọn khả thi.
Chương này đã giả định rằng mỗi bản sao lưu trữ một bản sao đầy đủ của toàn bộ cơ sở dữ liệu, điều này không thực tế đối với các tập dữ liệu lớn. Trong chương tiếp theo, chúng ta sẽ xem xét sharding (phân mảnh), cho phép mỗi máy chỉ lưu trữ một tập con của dữ liệu.
References
B. G. Lindsay, P. G. Selinger, C. Galtieri, J. N. Gray, R. A. Lorie, T. G. Price, F. Putzolu, I. L. Traiger, and B. W. Wade. Notes on Distributed Databases. IBM Research, Research Report RJ2571(33471), July 1979. Archived at perma.cc/EPZ3-MHDD ↩︎ ↩︎
Kenny Gryp. MySQL Terminology Updates. dev.mysql.com, July 2020. Archived at perma.cc/S62G-6RJ2 ↩︎
Oracle Corporation. Oracle (Active) Data Guard 19c: Real-Time Data Protection and Availability. White Paper, oracle.com, March 2019. Archived at perma.cc/P5ST-RPKE ↩︎
Microsoft. What is an Always On availability group? learn.microsoft.com, September 2024. Archived at perma.cc/ABH6-3MXF ↩︎
Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, and Akshat Vig. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service. At USENIX Annual Technical Conference (ATC), July 2022. ↩︎ ↩︎
Rebecca Taft, Irfan Sharif, Andrei Matei, Nathan VanBenschoten, Jordan Lewis, Tobias Grieger, Kai Niemi, Andy Woods, Anne Birzin, Raphael Poss, Paul Bardea, Amruta Ranade, Ben Darnell, Bram Gruneir, Justin Jaffray, Lucy Zhang, and Peter Mattis. CockroachDB: The Resilient Geo-Distributed SQL Database. At ACM SIGMOD International Conference on Management of Data (SIGMOD), pages 1493–1509, June 2020. doi:10.1145/3318464.3386134 ↩︎
Dongxu Huang, Qi Liu, Qiu Cui, Zhuhe Fang, Xiaoyu Ma, Fei Xu, Li Shen, Liu Tang, Yuxing Zhou, Menglong Huang, Wan Wei, Cong Liu, Jian Zhang, Jianjun Li, Xuelian Wu, Lingyu Song, Ruoxi Sun, Shuaipeng Yu, Lei Zhao, Nicholas Cameron, Liquan Pei, and Xin Tang. TiDB: a Raft-based HTAP database. Proceedings of the VLDB Endowment, volume 13, issue 12, pages 3072–3084. doi:10.14778/3415478.3415535 ↩︎
Mallory Knodel and Niels ten Oever. Terminology, Power, and Inclusive Language in Internet-Drafts and RFCs. IETF Internet-Draft, August 2023. Archived at perma.cc/5ZY9-725E ↩︎
Buck Hodges. Postmortem: VSTS 4 September 2018. devblogs.microsoft.com, September 2018. Archived at perma.cc/ZF5R-DYZS ↩︎
Gunnar Morling. Leader Election With S3 Conditional Writes. www.morling.dev, August 2024. Archived at perma.cc/7V2N-J78Y ↩︎
Vignesh Chandramohan, Rohan Desai, and Chris Riccomini. SlateDB Manifest Design. github.com, May 2024. Archived at perma.cc/8EUY-P32Z ↩︎
Stas Kelvich. Why does Neon use Paxos instead of Raft, and what’s the difference? neon.tech, August 2022. Archived at perma.cc/SEZ4-2GXU ↩︎
Dimitri Fontaine. An introduction to the pg_auto_failover project. tapoueh.org, November 2021. Archived at perma.cc/3WH5-6BAF ↩︎
Jesse Newland. GitHub availability this week. github.blog, September 2012. Archived at perma.cc/3YRF-FTFJ ↩︎
Mark Imbriaco. Downtime last Saturday. github.blog, December 2012. Archived at perma.cc/M7X5-E8SQ ↩︎
John Hugg. ‘All In’ with Determinism for Performance and Testing in Distributed Systems. At Strange Loop, September 2015. ↩︎
Hironobu Suzuki. The Internals of PostgreSQL. interdb.jp, 2017. ↩︎
Amit Kapila. WAL Internals of PostgreSQL. At PostgreSQL Conference (PGCon), May 2012. Archived at perma.cc/6225-3SUX ↩︎
Amit Kapila. Evolution of Logical Replication. amitkapila16.blogspot.com, September 2023. Archived at perma.cc/F9VX-JLER ↩︎
Aru Petchimuthu. Upgrade your Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL database, Part 2: Using the pglogical extension. aws.amazon.com, August 2021. Archived at perma.cc/RXT8-FS2T ↩︎
Yogeshwer Sharma, Philippe Ajoux, Petchean Ang, David Callies, Abhishek Choudhary, Laurent Demailly, Thomas Fersch, Liat Atsmon Guz, Andrzej Kotulski, Sachin Kulkarni, Sanjeev Kumar, Harry Li, Jun Li, Evgeniy Makeev, Kowshik Prakasam, Robbert van Renesse, Sabyasachi Roy, Pratyush Seth, Yee Jiun Song, Benjamin Wester, Kaushik Veeraraghavan, and Peter Xie. Wormhole: Reliable Pub-Sub to Support Geo-Replicated Internet Services. At 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI), May 2015. ↩︎
Douglas B. Terry. Replicated Data Consistency Explained Through Baseball. Microsoft Research, Technical Report MSR-TR-2011-137, October 2011. Archived at perma.cc/F4KZ-AR38 ↩︎ ↩︎ ↩︎
Douglas B. Terry, Alan J. Demers, Karin Petersen, Mike J. Spreitzer, Marvin M. Theher, and Brent B. Welch. Session Guarantees for Weakly Consistent Replicated Data. At 3rd International Conference on Parallel and Distributed Information Systems (PDIS), September 1994. doi:10.1109/PDIS.1994.331722 ↩︎ ↩︎
Werner Vogels. Eventually Consistent. ACM Queue, volume 6, issue 6, pages 14–19, October 2008. doi:10.1145/1466443.1466448 ↩︎
Simon Willison. Reply to: “My thoughts about Fly.io (so far) and other newish technology I’m getting into”. news.ycombinator.com, May 2022. Archived at perma.cc/ZRV4-WWV8 ↩︎
Nithin Tharakan. Scaling Bitbucket’s Database. atlassian.com, October 2020. Archived at perma.cc/JAB7-9FGX ↩︎
Terry Pratchett. Reaper Man: A Discworld Novel. Victor Gollancz, 1991. ISBN: 978-0-575-04979-6 ↩︎
Peter Bailis, Alan Fekete, Michael J. Franklin, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. Coordination Avoidance in Database Systems. Proceedings of the VLDB Endowment, volume 8, issue 3, pages 185–196, November 2014. doi:10.14778/2735508.2735509 ↩︎
Yaser Raja and Peter Celentano. PostgreSQL bi-directional replication using pglogical. aws.amazon.com, January 2022. Archived at https://perma.cc/BUQ2-5QWN ↩︎
Robert Hodges. If You *Must* Deploy Multi-Master Replication, Read This First. scale-out-blog.blogspot.com, April 2012. Archived at perma.cc/C2JN-F6Y8 ↩︎ ↩︎
Lars Hofhansl. HBASE-7709: Infinite Loop Possible in Master/Master Replication. issues.apache.org, January 2013. Archived at perma.cc/24G2-8NLC ↩︎
John Day-Richter. What’s Different About the New Google Docs: Making Collaboration Fast. drive.googleblog.com, September 2010. Archived at perma.cc/5TL8-TSJ2 ↩︎ ↩︎
Evan Wallace. How Figma’s multiplayer technology works. figma.com, October 2019. Archived at perma.cc/L49H-LY4D ↩︎
Tuomas Artman. Scaling the Linear Sync Engine. linear.app, June 2023. ↩︎
Amr Saafan. Why Sync Engines Might Be the Future of Web Applications. nilebits.com, September 2024. Archived at perma.cc/5N73-5M3V ↩︎
Isaac Hagoel. Are Sync Engines The Future of Web Applications? dev.to, July 2024. Archived at perma.cc/R9HF-BKKL ↩︎
Sujay Jayakar. A Map of Sync. stack.convex.dev, October 2024. Archived at perma.cc/82R3-H42A ↩︎
Alex Feyerke. Designing Offline-First Web Apps. alistapart.com, December 2013. Archived at perma.cc/WH7R-S2DS ↩︎
Martin Kleppmann, Adam Wiggins, Peter van Hardenberg, and Mark McGranaghan. Local-first software: You own your data, in spite of the cloud. At ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward!), October 2019, pages 154–178. doi:10.1145/3359591.3359737 ↩︎
Martin Kleppmann. The past, present, and future of local-first. At Local-First Conference, May 2024. ↩︎
Conrad Hofmeyr. API Calling is to Sync Engines as jQuery is to React. powersync.com, November 2024. Archived at perma.cc/2FP9-7WJJ ↩︎
Peter van Hardenberg and Martin Kleppmann. PushPin: Towards Production-Quality Peer-to-Peer Collaboration. At 7th Workshop on Principles and Practice of Consistency for Distributed Data (PaPoC), April 2020. doi:10.1145/3380787.3393683 ↩︎
Leonard Kawell, Jr., Steven Beckhardt, Timothy Halvorsen, Raymond Ozzie, and Irene Greif. Replicated document management in a group communication system. At ACM Conference on Computer-Supported Cooperative Work (CSCW), September 1988. doi:10.1145/62266.1024798 ↩︎
Ricky Pusch. Explaining how fighting games use delay-based and rollback netcode. words.infil.net and arstechnica.com, October 2019. Archived at perma.cc/DE7W-RDJ8 ↩︎
Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall, and Werner Vogels. Dynamo: Amazon’s Highly Available Key-Value Store. At 21st ACM Symposium on Operating Systems Principles (SOSP), October 2007. doi:10.1145/1323293.1294281 ↩︎ ↩︎ ↩︎ ↩︎
Marc Shapiro, Nuno Preguiça, Carlos Baquero, and Marek Zawirski. A Comprehensive Study of Convergent and Commutative Replicated Data Types. INRIA Research Report no. 7506, January 2011. ↩︎
Chengzheng Sun and Clarence Ellis. Operational Transformation in Real-Time Group Editors: Issues, Algorithms, and Achievements. At ACM Conference on Computer Supported Cooperative Work (CSCW), November 1998. doi:10.1145/289444.289469 ↩︎
Joseph Gentle and Martin Kleppmann. Collaborative Text Editing with Eg-walker: Better, Faster, Smaller. At 20th European Conference on Computer Systems (EuroSys), March 2025. doi:10.1145/3689031.3696076 ↩︎
Dharma Shukla. Azure Cosmos DB: Pushing the frontier of globally distributed databases. azure.microsoft.com, September 2018. Archived at perma.cc/UT3B-HH6R ↩︎
David K. Gifford. Weighted Voting for Replicated Data. At 7th ACM Symposium on Operating Systems Principles (SOSP), December 1979. doi:10.1145/800215.806583 ↩︎ ↩︎
Heidi Howard, Dahlia Malkhi, and Alexander Spiegelman. Flexible Paxos: Quorum Intersection Revisited. At 20th International Conference on Principles of Distributed Systems (OPODIS), December 2016. doi:10.4230/LIPIcs.OPODIS.2016.25 ↩︎
Joseph Blomstedt. Bringing Consistency to Riak. At RICON West, October 2012. ↩︎
Peter Bailis, Shivaram Venkataraman, Michael J. Franklin, Joseph M. Hellerstein, and Ion Stoica. Quantifying eventual consistency with PBS. The VLDB Journal, volume 23, pages 279–302, April 2014. doi:10.1007/s00778-013-0330-1 ↩︎
Colin Breck. Shared-Nothing Architectures for Server Replication and Synchronization. blog.colinbreck.com, December 2019. Archived at perma.cc/48P3-J6CJ ↩︎ ↩︎
Jeffrey Dean and Luiz André Barroso. The Tail at Scale. Communications of the ACM, volume 56, issue 2, pages 74–80, February 2013. doi:10.1145/2408776.2408794 ↩︎
Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R. Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao. Gray Failure: The Achilles’ Heel of Cloud-Scale Systems. At 16th Workshop on Hot Topics in Operating Systems (HotOS), May 2017. doi:10.1145/3102980.3103005 ↩︎
Leslie Lamport. Time, Clocks, and the Ordering of Events in a Distributed System. Communications of the ACM, volume 21, issue 7, pages 558–565, July 1978. doi:10.1145/359545.359563 ↩︎ ↩︎
D. Stott Parker Jr., Gerald J. Popek, Gerard Rudisin, Allen Stoughton, Bruce J. Walker, Evelyn Walton, Johanna M. Chow, David Edwards, Stephen Kiser, and Charles Kline. Detection of Mutual Inconsistency in Distributed Systems. IEEE Transactions on Software Engineering, volume SE-9, issue 3, pages 240–247, May 1983. doi:10.1109/TSE.1983.236733 ↩︎
Nuno Preguiça, Carlos Baquero, Paulo Sérgio Almeida, Victor Fonte, and Ricardo Gonçalves. Dotted Version Vectors: Logical Clocks for Optimistic Replication. arXiv:1011.5808, November 2010. ↩︎
Giridhar Manepalli. Clocks and Causality - Ordering Events in Distributed Systems. exhypothesi.com, November 2022. Archived at perma.cc/8REU-KVLQ ↩︎ ↩︎
Sean Cribbs. A Brief History of Time in Riak. At RICON, October 2014. Archived at perma.cc/7U9P-6JFX ↩︎
Russell Brown. Vector Clocks Revisited Part 2: Dotted Version Vectors. riak.com, November 2015. Archived at perma.cc/96QP-W98R ↩︎
Carlos Baquero. Version Vectors Are Not Vector Clocks. haslab.wordpress.com, July 2011. Archived at perma.cc/7PNU-4AMG ↩︎
Reinhard Schwarz and Friedemann Mattern. Detecting Causal Relationships in Distributed Computations: In Search of the Holy Grail. Distributed Computing, volume 7, issue 3, pages 149–174, March 1994. doi:10.1007/BF02277859 ↩︎