5. Mã hóa và Tiến hóa
Tất cả đều thay đổi, không có gì đứng yên.
Heraclitus of Ephesus, được Plato trích dẫn trong Cratylus (360 TCN)
Các ứng dụng chắc chắn sẽ thay đổi theo thời gian. Tính năng được thêm vào hoặc sửa đổi khi các sản phẩm mới ra mắt, khi yêu cầu người dùng được hiểu rõ hơn, hoặc khi hoàn cảnh kinh doanh thay đổi. Trong Chương 2 chúng ta đã giới thiệu khái niệm evolvability (khả năng tiến hóa): chúng ta nên hướng đến xây dựng những hệ thống dễ thích nghi với sự thay đổi (xem “Evolvability: Making Change Easy”).
Trong hầu hết các trường hợp, một thay đổi về tính năng của ứng dụng cũng đòi hỏi thay đổi dữ liệu mà nó lưu trữ: có thể cần ghi thêm một trường hoặc kiểu bản ghi mới, hoặc dữ liệu hiện có cần được trình bày theo cách mới.
Các mô hình dữ liệu mà chúng ta đã thảo luận trong Chương 3 có những cách khác nhau để đối phó với sự thay đổi đó. Cơ sở dữ liệu quan hệ thường giả định rằng tất cả dữ liệu trong cơ sở dữ liệu tuân theo một schema: mặc dù schema đó có thể thay đổi (thông qua schema migration, tức là câu lệnh ALTER), tại bất kỳ thời điểm nào cũng chỉ có đúng một schema đang có hiệu lực. Ngược lại, các cơ sở dữ liệu schema-on-read (“schemaless”, không ràng buộc schema) không áp đặt schema, vì vậy cơ sở dữ liệu có thể chứa hỗn hợp các định dạng dữ liệu cũ và mới được ghi vào các thời điểm khác nhau (xem “Schema flexibility in the document model”).
Khi định dạng dữ liệu hoặc schema thay đổi, thường cần có một thay đổi tương ứng trong mã ứng dụng (ví dụ, bạn thêm một trường mới vào bản ghi, và mã ứng dụng bắt đầu đọc và ghi trường đó). Tuy nhiên, trong một ứng dụng lớn, các thay đổi mã thường không thể xảy ra tức thì:
- Với các ứng dụng phía máy chủ, bạn có thể muốn thực hiện rolling upgrade (nâng cấp cuốn chiếu, còn gọi là staged rollout), triển khai phiên bản mới lên một vài node một lúc, kiểm tra xem phiên bản mới có hoạt động ổn định không, rồi dần dần tiến hành trên tất cả các node. Điều này cho phép triển khai phiên bản mới mà không bị gián đoạn dịch vụ, từ đó khuyến khích phát hành thường xuyên hơn và cải thiện khả năng tiến hóa.
- Với các ứng dụng phía máy khách, bạn phụ thuộc vào người dùng, những người có thể không cài đặt bản cập nhật trong một thời gian dài.
Điều này có nghĩa là các phiên bản cũ và mới của mã, cũng như các định dạng dữ liệu cũ và mới, có thể đồng thời tồn tại trong hệ thống cùng một lúc. Để hệ thống tiếp tục hoạt động ổn định, chúng ta cần duy trì khả năng tương thích theo cả hai chiều:
- Backward compatibility (tương thích ngược)
- Mã mới có thể đọc dữ liệu được ghi bởi mã cũ.
- Forward compatibility (tương thích xuôi)
- Mã cũ có thể đọc dữ liệu được ghi bởi mã mới.
Backward compatibility thường không khó đạt được: với tư cách là tác giả của mã mới, bạn biết định dạng dữ liệu do mã cũ tạo ra, và vì vậy bạn có thể xử lý rõ ràng nó (nếu cần, đơn giản là giữ lại mã cũ để đọc dữ liệu cũ). Forward compatibility có thể khó hơn, vì nó đòi hỏi mã cũ bỏ qua các phần bổ sung được thực hiện bởi phiên bản mã mới hơn.
Một thách thức khác với forward compatibility được minh họa trong Hình 5-1. Giả sử bạn thêm một trường vào schema bản ghi, và mã mới tạo ra một bản ghi chứa trường mới đó và lưu vào cơ sở dữ liệu. Sau đó, một phiên bản cũ hơn của mã (chưa biết về trường mới) đọc bản ghi, cập nhật nó, và ghi lại. Trong tình huống này, hành vi mong muốn thường là mã cũ giữ nguyên trường mới, dù không thể giải thích được nó. Nhưng nếu bản ghi được giải mã thành một đối tượng mô hình mà không lưu lại các trường không xác định một cách tường minh, dữ liệu có thể bị mất, như trong Hình 5-1.
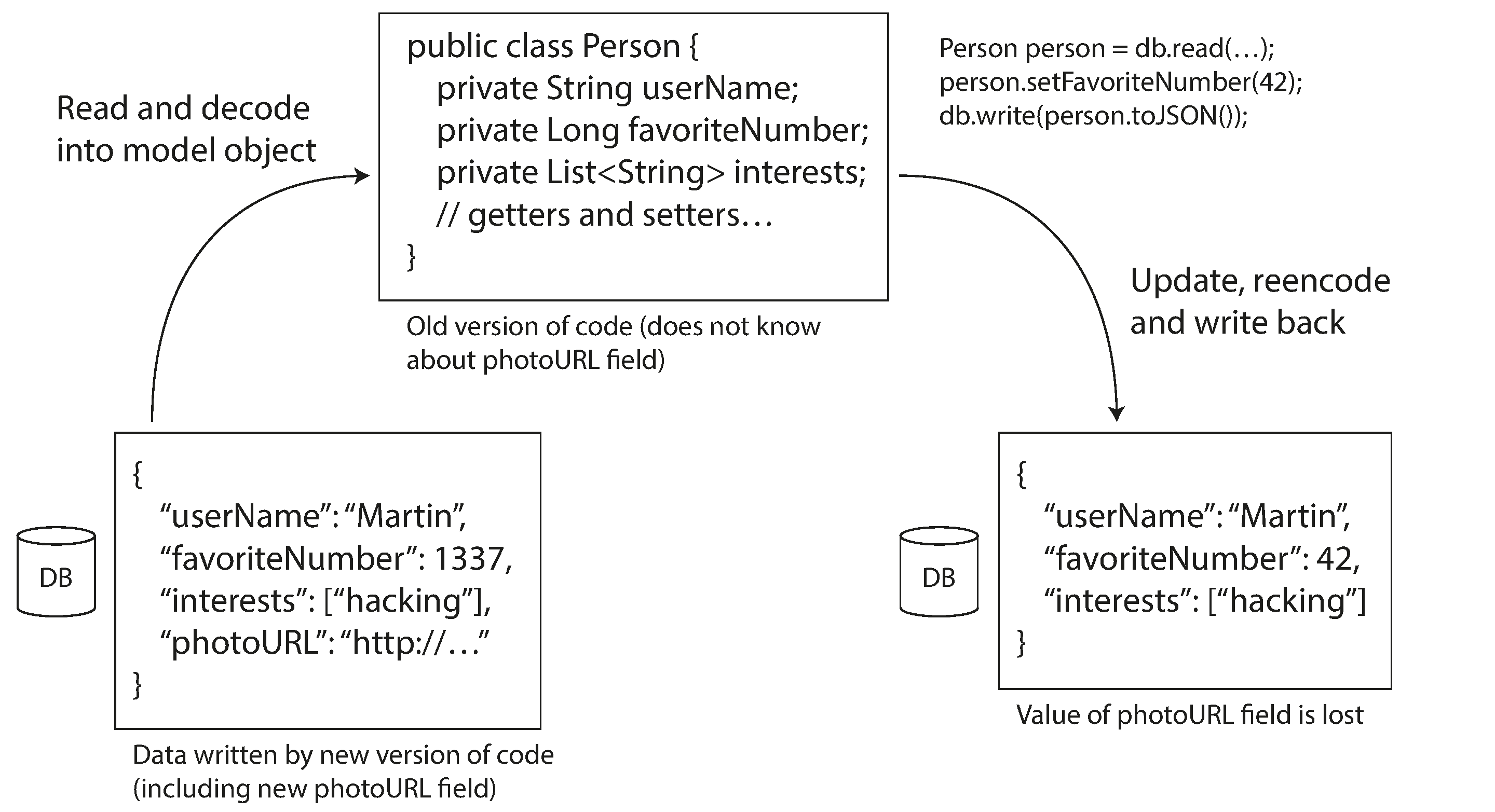
Trong chương này chúng ta sẽ xem xét một số định dạng mã hóa dữ liệu, bao gồm JSON, XML, Protocol Buffers, và Avro. Đặc biệt, chúng ta sẽ xem xét cách chúng xử lý các thay đổi schema và cách chúng hỗ trợ các hệ thống mà dữ liệu và mã cũ và mới cần cùng tồn tại. Sau đó chúng ta sẽ thảo luận về cách những định dạng đó được sử dụng để lưu trữ dữ liệu và giao tiếp: trong các cơ sở dữ liệu, web services, REST API, remote procedure call (RPC), workflow engine, và các hệ thống hướng sự kiện như actor và message queue.
Các Định dạng Mã hóa Dữ liệu
Các chương trình thường làm việc với dữ liệu theo (ít nhất) hai dạng biểu diễn khác nhau:
- Trong bộ nhớ, dữ liệu được lưu trữ dưới dạng object, struct, list, array, hash table, tree, v.v. Các cấu trúc dữ liệu này được tối ưu hóa để CPU truy cập và thao tác hiệu quả (thường sử dụng pointer).
- Khi bạn muốn ghi dữ liệu ra file hoặc gửi qua mạng, bạn phải mã hóa nó thành một dạng chuỗi byte khép kín (ví dụ, một tài liệu JSON). Vì pointer không có ý nghĩa với bất kỳ tiến trình nào khác, dạng biểu diễn chuỗi byte này thường trông khá khác so với các cấu trúc dữ liệu thường được sử dụng trong bộ nhớ.
Do đó, chúng ta cần một dạng chuyển đổi nào đó giữa hai biểu diễn này. Quá trình chuyển từ biểu diễn trong bộ nhớ sang chuỗi byte được gọi là encoding (mã hóa, còn gọi là serialization hay marshalling), và chiều ngược lại được gọi là decoding (parsing, deserialization, unmarshalling).
XUNG ĐỘT THUẬT NGỮ
Serialization thật không may cũng được sử dụng trong ngữ cảnh transaction (xem Chương 8), với một nghĩa hoàn toàn khác. Để tránh nhầm lẫn, chúng ta sẽ dùng encoding trong cuốn sách này, dù serialization có lẽ là thuật ngữ phổ biến hơn.
Có những trường hợp ngoại lệ mà encoding/decoding không cần thiết, ví dụ khi cơ sở dữ liệu hoạt động trực tiếp trên dữ liệu nén được tải từ đĩa, như đã thảo luận trong “Query Execution: Compilation and Vectorization”. Cũng có các định dạng dữ liệu zero-copy được thiết kế để dùng cả ở runtime lẫn trên đĩa/mạng, không cần bước chuyển đổi rõ ràng, chẳng hạn như Cap’n Proto và FlatBuffers.
Tuy nhiên, hầu hết các hệ thống cần chuyển đổi giữa object trong bộ nhớ và chuỗi byte phẳng. Đây là vấn đề rất phổ biến, nên có vô số thư viện và định dạng mã hóa để lựa chọn. Hãy cùng xem qua tổng quan ngắn gọn.
Các Định dạng Đặc thù theo Ngôn ngữ
Nhiều ngôn ngữ lập trình đi kèm với hỗ trợ tích hợp để mã hóa các object trong bộ nhớ thành chuỗi byte. Ví dụ, Java có java.io.Serializable, Python có pickle, Ruby có Marshal, v.v. Nhiều thư viện của bên thứ ba cũng tồn tại, chẳng hạn như Kryo cho Java.
Các thư viện mã hóa này rất tiện lợi vì chúng cho phép lưu và khôi phục các object trong bộ nhớ với rất ít mã bổ sung. Tuy nhiên, chúng cũng có một số vấn đề nghiêm trọng:
- Việc mã hóa thường gắn liền với một ngôn ngữ lập trình cụ thể, và đọc dữ liệu đó bằng ngôn ngữ khác rất khó khăn. Nếu bạn lưu trữ hoặc truyền dữ liệu theo định dạng như vậy, bạn đang tự ràng buộc mình với ngôn ngữ lập trình hiện tại trong một thời gian rất dài, và ngăn cản việc tích hợp hệ thống của bạn với các tổ chức khác (có thể dùng ngôn ngữ khác).
- Để khôi phục dữ liệu theo cùng các kiểu object, quá trình decoding cần có khả năng khởi tạo các class tùy ý. Đây thường là nguồn gốc của các vấn đề bảo mật 1: nếu kẻ tấn công có thể khiến ứng dụng của bạn giải mã một chuỗi byte tùy ý, chúng có thể khởi tạo các class tùy ý, từ đó thường cho phép thực hiện những hành động nguy hiểm như thực thi mã từ xa 2 3.
- Versioning dữ liệu thường là suy nghĩ muộn màng trong các thư viện này: vì chúng được thiết kế để mã hóa dữ liệu nhanh và dễ dàng, chúng thường bỏ qua các vấn đề khó chịu về forward và backward compatibility 4.
- Hiệu quả (thời gian CPU để mã hóa hoặc giải mã, và kích thước cấu trúc được mã hóa) cũng thường là suy nghĩ muộn màng. Ví dụ, serialization tích hợp sẵn của Java nổi tiếng vì hiệu suất kém và mã hóa cồng kềnh 5.
Vì những lý do này, việc sử dụng mã hóa tích hợp sẵn của ngôn ngữ cho bất kỳ mục đích nào khác ngoài những mục đích tạm thời là ý tưởng không tốt.
JSON, XML, và Các Biến thể Nhị phân
Khi chuyển sang các định dạng chuẩn hóa có thể được viết và đọc bởi nhiều ngôn ngữ lập trình, JSON và XML là những lựa chọn hiển nhiên. Chúng được biết đến rộng rãi, được hỗ trợ rộng rãi, và gần như cũng bị chê bai rộng rãi không kém. XML thường bị chỉ trích vì quá dài dòng và phức tạp không cần thiết 6. Sự phổ biến của JSON chủ yếu do nó được hỗ trợ tích hợp sẵn trong trình duyệt web và đơn giản hơn so với XML. CSV là một định dạng độc lập ngôn ngữ phổ biến khác, nhưng nó chỉ hỗ trợ dữ liệu dạng bảng mà không có cấu trúc lồng nhau.
JSON, XML, và CSV là các định dạng văn bản, do đó phần nào có thể đọc được bởi con người (dù cú pháp của chúng là chủ đề tranh luận phổ biến). Ngoài các vấn đề cú pháp bề ngoài, chúng cũng có một số vấn đề tinh tế hơn:
Có rất nhiều sự mơ hồ xung quanh việc mã hóa số. Trong XML và CSV, bạn không thể phân biệt giữa một số và một chuỗi tình cờ chỉ gồm các chữ số (trừ khi tham chiếu đến một schema bên ngoài). JSON phân biệt chuỗi và số, nhưng không phân biệt số nguyên và số dấu phẩy động, và không xác định độ chính xác.
Đây là vấn đề khi làm việc với các số lớn. Ví dụ, số nguyên lớn hơn 2⁵³ không thể được biểu diễn chính xác trong số dấu phẩy động độ chính xác kép IEEE 754, vì vậy những số như vậy trở nên không chính xác khi được phân tích trong ngôn ngữ sử dụng số dấu phẩy động, chẳng hạn như JavaScript 7. Một ví dụ về số lớn hơn 2⁵³ xuất hiện trên X (trước đây là Twitter), nơi sử dụng số 64-bit để định danh mỗi bài đăng. JSON trả về từ API bao gồm ID bài đăng hai lần, một lần dưới dạng số JSON và một lần dưới dạng chuỗi thập phân, để giải quyết thực tế là các số đó không được phân tích đúng bởi các ứng dụng JavaScript 8.
JSON và XML hỗ trợ tốt cho các chuỗi ký tự Unicode (tức là văn bản có thể đọc bởi con người), nhưng chúng không hỗ trợ chuỗi nhị phân (chuỗi byte không có mã hóa ký tự). Chuỗi nhị phân là một tính năng hữu ích, vì vậy người ta giải quyết hạn chế này bằng cách mã hóa dữ liệu nhị phân thành văn bản bằng Base64. Schema sau đó được dùng để chỉ ra rằng giá trị đó nên được hiểu là Base64-encoded. Cách này hoạt động, nhưng có phần vá víu và làm tăng kích thước dữ liệu lên 33%.
XML Schema và JSON Schema rất mạnh mẽ, và do đó khá phức tạp để học và triển khai. Vì cách hiểu đúng của dữ liệu (như số và chuỗi nhị phân) phụ thuộc vào thông tin trong schema, các ứng dụng không sử dụng XML/JSON schema cần phải hard-code logic encoding/decoding tương ứng.
CSV không có schema nào, vì vậy ứng dụng phải tự định nghĩa ý nghĩa của mỗi hàng và cột. Nếu thay đổi ứng dụng thêm một hàng hoặc cột mới, bạn phải xử lý thay đổi đó thủ công. CSV cũng là một định dạng khá mơ hồ (điều gì xảy ra nếu một giá trị chứa dấu phẩy hoặc ký tự xuống dòng?). Mặc dù các quy tắc escaping của nó đã được chỉ định chính thức 9, không phải tất cả các parser đều triển khai chúng đúng cách.
Dù có những nhược điểm này, JSON, XML, và CSV vẫn đủ tốt cho nhiều mục đích. Có khả năng chúng sẽ tiếp tục phổ biến, đặc biệt là định dạng trao đổi dữ liệu (tức là để gửi dữ liệu từ tổ chức này sang tổ chức khác). Trong những tình huống đó, miễn là mọi người đồng ý về định dạng là gì, thường không quan trọng định dạng đó đẹp hay hiệu quả đến đâu. Khó khăn khi khiến các tổ chức khác nhau đồng ý với bất kỳ điều gì lấn át hầu hết các mối quan tâm khác.
JSON Schema
JSON Schema đã được áp dụng rộng rãi như một cách mô hình hóa dữ liệu bất cứ khi nào nó được trao đổi giữa các hệ thống hoặc ghi vào bộ nhớ. Bạn sẽ tìm thấy JSON schema trong các web service (xem “Web services”) như một phần của đặc tả OpenAPI web service, trong các schema registry như Confluent Schema Registry và Red Hat Apicurio Registry, và trong các cơ sở dữ liệu như extension trình xác thực pg_jsonschema của PostgreSQL và cú pháp $jsonSchema của MongoDB.
Đặc tả JSON Schema cung cấp một số tính năng. Các schema bao gồm các kiểu nguyên thủy chuẩn gồm string, number, integer, object, array, boolean, hoặc null. Nhưng JSON Schema cũng cung cấp một đặc tả validation riêng cho phép các nhà phát triển đặt thêm ràng buộc trên các trường. Ví dụ, một trường port có thể có giá trị tối thiểu là 1 và tối đa là 65535.
JSON Schema có thể có content model mở hoặc đóng. Content model mở cho phép bất kỳ trường nào không được định nghĩa trong schema tồn tại với bất kỳ kiểu dữ liệu nào, trong khi content model đóng chỉ cho phép các trường được định nghĩa rõ ràng. Content model mở trong JSON Schema được kích hoạt khi additionalProperties được đặt thành true, đây là giá trị mặc định. Do đó, JSON Schema thường là định nghĩa về những gì không được phép (cụ thể là các giá trị không hợp lệ trên bất kỳ trường nào đã định nghĩa), thay vì những gì được phép trong schema.
Content model mở rất mạnh mẽ, nhưng có thể phức tạp. Ví dụ, giả sử bạn muốn định nghĩa một bản đồ (map) từ số nguyên (chẳng hạn ID) đến chuỗi. JSON không có kiểu map hay dictionary, chỉ có kiểu “object” có thể chứa các khóa chuỗi và giá trị thuộc bất kỳ kiểu nào. Bạn có thể ràng buộc kiểu này bằng JSON Schema để khóa chỉ chứa chữ số, và giá trị chỉ có thể là chuỗi, dùng patternProperties và additionalProperties như trong Ví dụ 5-1.
Ví dụ 5-1. JSON Schema mẫu với khóa là số nguyên và giá trị là chuỗi. Các khóa số nguyên được biểu diễn dưới dạng chuỗi chỉ chứa số nguyên vì JSON Schema yêu cầu tất cả khóa phải là chuỗi.
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"patternProperties": {
"^[0-9]+$": {
"type": "string"
}
},
"additionalProperties": false
}Ngoài content model mở và đóng cùng với các validator, JSON Schema hỗ trợ logic schema if/else có điều kiện, các kiểu có tên, tham chiếu đến các schema từ xa, và nhiều hơn nữa. Tất cả những điều này tạo nên một ngôn ngữ schema rất mạnh mẽ. Những tính năng đó cũng tạo ra các định nghĩa cồng kềnh. Việc phân giải các schema từ xa, lý luận về các quy tắc có điều kiện, hoặc phát triển schema theo cách tương thích xuôi hoặc ngược có thể rất khó khăn 10. Những mối lo tương tự cũng áp dụng cho XML Schema 11.
Mã hóa nhị phân
JSON ít dài dòng hơn XML, nhưng cả hai vẫn chiếm nhiều không gian hơn so với các định dạng nhị phân. Nhận xét này dẫn đến sự phát triển của rất nhiều định dạng mã hóa nhị phân cho JSON (MessagePack, CBOR, BSON, BJSON, UBJSON, BISON, Hessian, và Smile, để kể một vài cái) và cho XML (WBXML và Fast Infoset, ví dụ). Các định dạng này đã được áp dụng trong các lĩnh vực đặc thù, vì chúng gọn hơn và đôi khi phân tích nhanh hơn, nhưng không có định dạng nào được áp dụng rộng rãi như các phiên bản văn bản của JSON và XML 12.
Một số định dạng này mở rộng tập kiểu dữ liệu (ví dụ, phân biệt số nguyên và số dấu phẩy động, hoặc thêm hỗ trợ cho chuỗi nhị phân), nhưng ngoài ra chúng giữ nguyên mô hình dữ liệu JSON/XML. Đặc biệt, vì chúng không yêu cầu schema, chúng cần bao gồm tất cả tên trường của object trong dữ liệu đã mã hóa. Tức là, trong một mã hóa nhị phân của tài liệu JSON trong Ví dụ 5-2, chúng sẽ cần bao gồm các chuỗi userName, favoriteNumber, và interests ở đâu đó.
Ví dụ 5-2. Bản ghi mẫu mà chúng ta sẽ mã hóa theo một số định dạng nhị phân trong chương này
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}Hãy xem xét một ví dụ về MessagePack, một định dạng mã hóa nhị phân cho JSON. Hình 5-2 cho thấy chuỗi byte bạn nhận được nếu mã hóa tài liệu JSON trong Ví dụ 5-2 bằng MessagePack. Một vài byte đầu tiên như sau:
- Byte đầu tiên,
0x83, cho biết những gì theo sau là một object (bốn bit trên =0x80) với ba trường (bốn bit dưới =0x03). (Trong trường hợp bạn thắc mắc điều gì xảy ra nếu một object có nhiều hơn 15 trường, đến mức số trường không vừa trong bốn bit, thì khi đó nó có chỉ thị kiểu khác, và số trường được mã hóa trong hai hoặc bốn byte.) - Byte thứ hai,
0xa8, cho biết những gì theo sau là một chuỗi (bốn bit trên =0xa0) dài tám byte (bốn bit dưới =0x08). - Tám byte tiếp theo là tên trường
userNametrong ASCII. Vì độ dài đã được chỉ ra trước đó, không cần bất kỳ dấu hiệu nào để cho biết chuỗi kết thúc ở đâu (cũng không cần escaping). - Bảy byte tiếp theo mã hóa giá trị chuỗi sáu chữ cái
Martinvới tiền tố0xa6, v.v.
Mã hóa nhị phân dài 66 byte, chỉ ít hơn một chút so với 81 byte mà mã hóa JSON văn bản chiếm (khi đã loại bỏ khoảng trắng). Tất cả các mã hóa nhị phân của JSON đều tương tự nhau về mặt này. Không rõ liệu mức tiết kiệm không gian nhỏ như vậy (và có thể tăng tốc độ phân tích) có đáng đổi lấy việc mất khả năng đọc của con người không.
Trong các phần tiếp theo, chúng ta sẽ thấy cách có thể làm tốt hơn nhiều, và mã hóa cùng bản ghi đó chỉ trong 32 byte.

Protocol Buffers
Protocol Buffers (protobuf) là một thư viện mã hóa nhị phân được phát triển tại Google. Nó tương tự như Apache Thrift, vốn được phát triển ban đầu bởi Facebook 13; hầu hết những gì phần này nói về Protocol Buffers cũng áp dụng cho Thrift.
Protocol Buffers yêu cầu schema cho bất kỳ dữ liệu nào được mã hóa. Để mã hóa dữ liệu trong Ví dụ 5-2 bằng Protocol Buffers, bạn mô tả schema trong ngôn ngữ định nghĩa giao diện (IDL) của Protocol Buffers như sau:
syntax = "proto3";
message Person {
string user_name = 1;
int64 favorite_number = 2;
repeated string interests = 3;
}Protocol Buffers đi kèm với công cụ sinh mã nhận định nghĩa schema như trên và tạo ra các class triển khai schema đó trong nhiều ngôn ngữ lập trình. Mã ứng dụng của bạn có thể gọi mã được tạo này để mã hóa hoặc giải mã các bản ghi theo schema. Ngôn ngữ schema đơn giản hơn nhiều so với JSON Schema: nó chỉ định nghĩa các trường của bản ghi và kiểu của chúng, nhưng không hỗ trợ các ràng buộc phức tạp khác về giá trị có thể có của các trường.
Mã hóa Ví dụ 5-2 bằng encoder của Protocol Buffers cần 33 byte, như được hiển thị trong Hình 5-3 14.
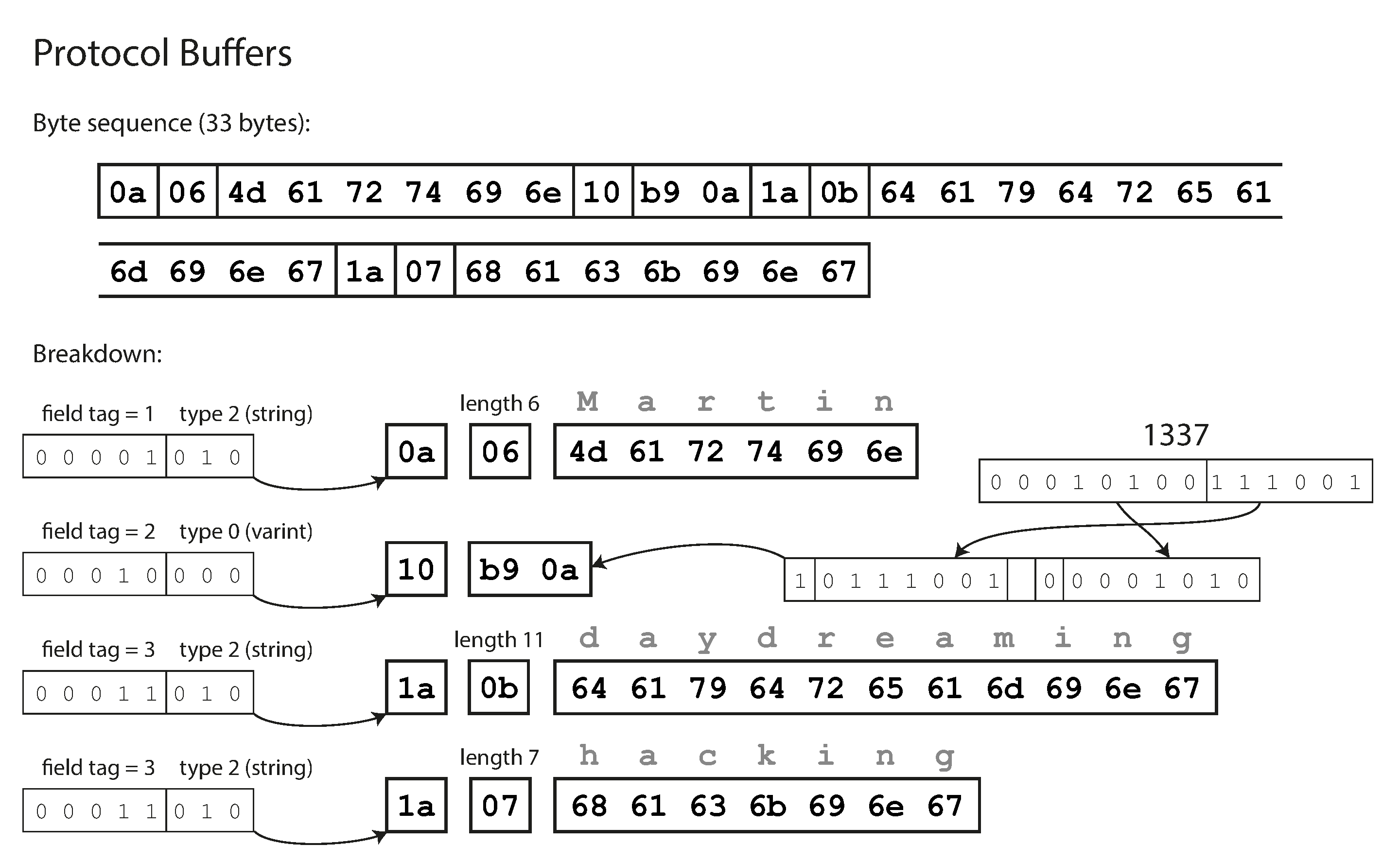
Tương tự như Hình 5-2, mỗi trường có một chú thích kiểu (để cho biết đó là chuỗi, số nguyên, v.v.) và, khi cần thiết, một chỉ báo độ dài (chẳng hạn như độ dài của chuỗi). Các chuỗi xuất hiện trong dữ liệu (“Martin”, “daydreaming”, “hacking”) cũng được mã hóa dưới dạng ASCII (chính xác hơn là UTF-8), tương tự như trước.
Sự khác biệt lớn so với Hình 5-2 là không có tên trường nào (userName, favoriteNumber, interests). Thay vào đó, dữ liệu được mã hóa chứa field tag (thẻ trường), là các số (1, 2, và 3). Đó là các số xuất hiện trong định nghĩa schema. Field tag giống như bí danh cho các trường: chúng là cách ngắn gọn để nói về trường nào đang được đề cập, mà không cần phải viết tên trường ra.
Như bạn có thể thấy, Protocol Buffers tiết kiệm thêm không gian bằng cách đóng gói kiểu trường và số tag vào một byte duy nhất. Nó sử dụng số nguyên có độ dài biến đổi: số 1337 được mã hóa trong hai byte, với bit trên cùng của mỗi byte dùng để chỉ ra liệu có còn thêm byte nữa không. Điều này có nghĩa là các số từ -64 đến 63 được mã hóa trong một byte, các số từ -8192 đến 8191 được mã hóa trong hai byte, v.v. Các số lớn hơn dùng nhiều byte hơn.
Protocol Buffers không có kiểu dữ liệu list hoặc array rõ ràng. Thay vào đó, modifier repeated trên trường interests cho biết trường đó chứa một danh sách các giá trị, thay vì một giá trị duy nhất. Trong mã hóa nhị phân, các phần tử danh sách được biểu diễn đơn giản là các lần xuất hiện lặp lại của cùng một field tag trong cùng một bản ghi.
Field tag và tiến hóa schema
Chúng ta đã nói trước đó rằng schema chắc chắn cần thay đổi theo thời gian. Chúng ta gọi đây là schema evolution (tiến hóa schema). Protocol Buffers xử lý các thay đổi schema như thế nào trong khi vẫn duy trì backward và forward compatibility?
Như bạn có thể thấy từ các ví dụ, một bản ghi đã mã hóa chỉ là sự nối tiếp của các trường đã mã hóa của nó. Mỗi trường được xác định bằng số tag (các số 1, 2, 3 trong schema mẫu) và được chú thích với kiểu dữ liệu (ví dụ: chuỗi hoặc số nguyên). Nếu giá trị của trường không được đặt, nó đơn giản bị bỏ qua khỏi bản ghi đã mã hóa. Từ đây bạn có thể thấy rằng field tag rất quan trọng đối với ý nghĩa của dữ liệu đã mã hóa. Bạn có thể thay đổi tên của một trường trong schema, vì dữ liệu đã mã hóa không bao giờ tham chiếu đến tên trường, nhưng bạn không thể thay đổi tag của trường, vì điều đó sẽ làm cho tất cả dữ liệu đã mã hóa hiện có trở nên không hợp lệ.
Bạn có thể thêm các trường mới vào schema, miễn là bạn đặt cho mỗi trường một số tag mới. Nếu mã cũ (không biết về số tag mới bạn đã thêm) cố đọc dữ liệu được ghi bởi mã mới, bao gồm một trường mới với số tag nó không nhận ra, nó có thể đơn giản bỏ qua trường đó. Chú thích kiểu dữ liệu cho phép parser xác định bao nhiêu byte cần bỏ qua, và lưu lại các trường không xác định để tránh vấn đề trong Hình 5-1. Điều này duy trì forward compatibility: mã cũ có thể đọc các bản ghi được ghi bởi mã mới.
Còn backward compatibility thì sao? Miễn là mỗi trường có số tag duy nhất, mã mới luôn có thể đọc dữ liệu cũ, vì số tag vẫn có cùng ý nghĩa. Nếu một trường được thêm vào schema mới, và bạn đọc dữ liệu cũ chưa chứa trường đó, nó sẽ được điền bằng giá trị mặc định (ví dụ, chuỗi rỗng nếu kiểu trường là chuỗi, hoặc không nếu là số).
Xóa một trường giống như thêm trường, với các mối lo về backward và forward compatibility bị đảo ngược. Bạn không bao giờ có thể dùng lại cùng số tag, vì bạn có thể vẫn có dữ liệu được ghi ở đâu đó bao gồm số tag cũ, và trường đó phải bị bỏ qua bởi mã mới. Các số tag đã dùng trong quá khứ có thể được đặt là reserved trong định nghĩa schema để đảm bảo chúng không bị quên.
Còn việc thay đổi kiểu dữ liệu của một trường thì sao? Điều đó có thể với một số kiểu, hãy kiểm tra tài liệu để biết chi tiết, nhưng có rủi ro là các giá trị sẽ bị cắt bớt. Ví dụ, giả sử bạn thay đổi số nguyên 32-bit thành số nguyên 64-bit. Mã mới có thể dễ dàng đọc dữ liệu được ghi bởi mã cũ, vì parser có thể điền các bit còn thiếu bằng các số không. Tuy nhiên, nếu mã cũ đọc dữ liệu được ghi bởi mã mới, mã cũ vẫn dùng biến 32-bit để lưu giá trị. Nếu giá trị 64-bit đã giải mã không vừa trong 32 bit, nó sẽ bị cắt bớt.
Avro
Apache Avro là một định dạng mã hóa nhị phân khác, thú vị ở chỗ nó khá khác biệt so với Protocol Buffers. Nó được khởi động vào năm 2009 như một dự án con của Hadoop, do Protocol Buffers không phù hợp với các trường hợp sử dụng của Hadoop 15.
Avro cũng sử dụng schema để chỉ định cấu trúc của dữ liệu được mã hóa. Nó có hai ngôn ngữ schema: một (Avro IDL) dành cho việc con người chỉnh sửa, và một (dựa trên JSON) dễ đọc hơn bởi máy. Giống như Protocol Buffers, ngôn ngữ schema này chỉ chỉ định các trường và kiểu của chúng, không có các quy tắc validation phức tạp như trong JSON Schema.
Schema mẫu của chúng ta, được viết bằng Avro IDL, có thể trông như thế này:
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}Biểu diễn JSON tương đương của schema đó như sau:
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]}Trước hết, hãy chú ý rằng không có số tag nào trong schema. Nếu chúng ta mã hóa bản ghi ví dụ (Ví dụ 5-2) bằng schema này, mã hóa nhị phân Avro chỉ dài 32 byte, đây là định dạng nhỏ gọn nhất trong tất cả các mã hóa chúng ta đã thấy. Sự phân tách của chuỗi byte được mã hóa được hiển thị trong Hình 5-4.
Nếu bạn kiểm tra chuỗi byte, bạn sẽ thấy rằng không có gì để xác định các trường hoặc kiểu dữ liệu của chúng. Việc mã hóa chỉ đơn giản bao gồm các giá trị được nối tiếp nhau. Một chuỗi chỉ là một tiền tố độ dài theo sau là các byte UTF-8, nhưng không có gì trong dữ liệu được mã hóa cho bạn biết đó là một chuỗi. Nó cũng có thể là một số nguyên, hoặc một thứ gì đó hoàn toàn khác. Một số nguyên được mã hóa bằng mã hóa độ dài thay đổi.
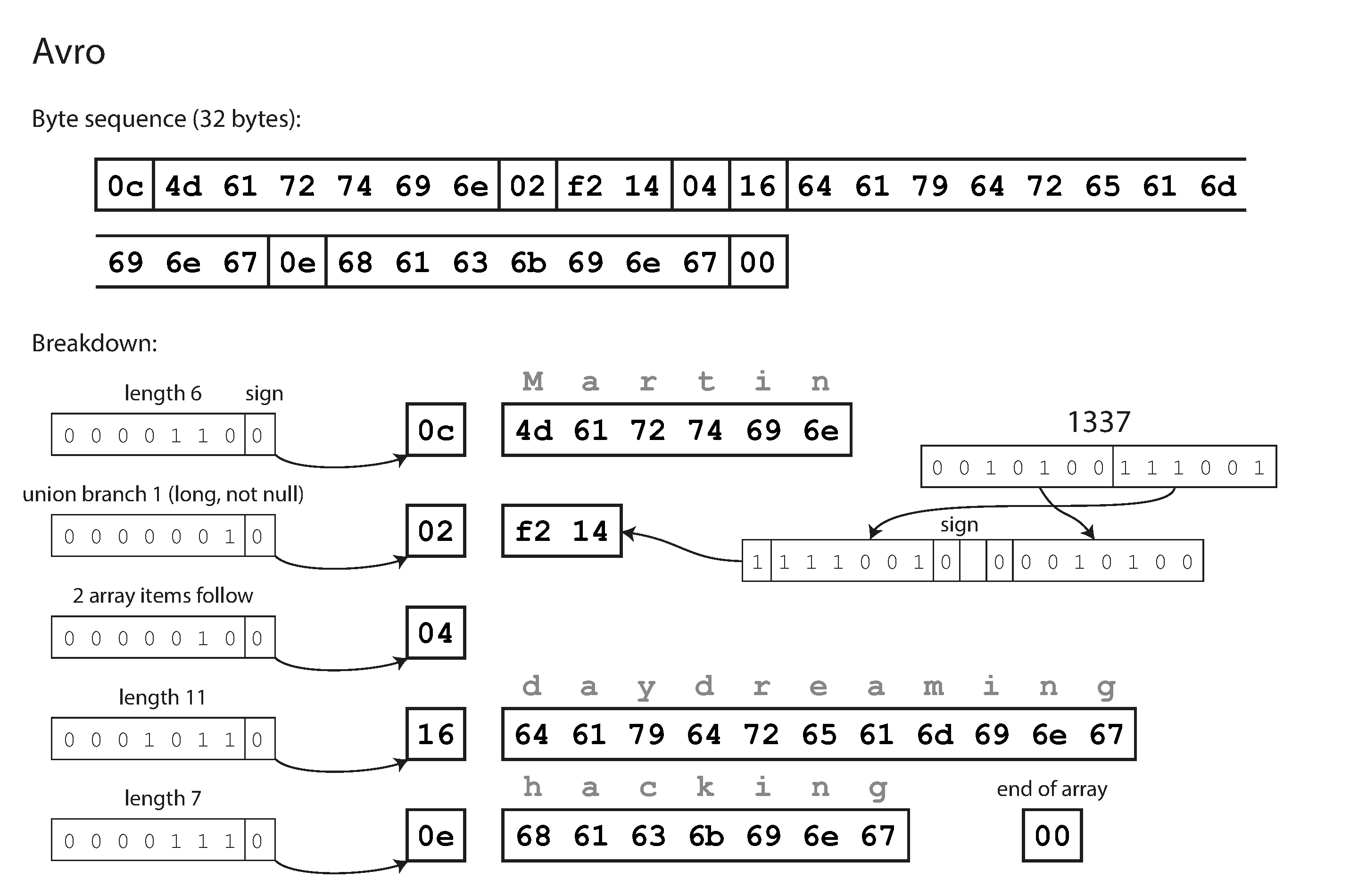
Để phân tích dữ liệu nhị phân, bạn duyệt qua các trường theo thứ tự xuất hiện trong schema và dùng schema để xác định kiểu dữ liệu của từng trường. Điều này có nghĩa là dữ liệu nhị phân chỉ có thể được giải mã đúng nếu code đọc dữ liệu đang sử dụng chính xác cùng một schema với code đã ghi dữ liệu. Bất kỳ sự không khớp nào trong schema giữa reader và writer đều dẫn đến dữ liệu được giải mã không chính xác.
Vậy, Avro hỗ trợ schema evolution (tiến hóa schema) như thế nào?
Schema của writer và schema của reader
Khi một ứng dụng muốn mã hóa một số dữ liệu (để ghi vào file hoặc cơ sở dữ liệu, để gửi qua mạng, v.v.), nó mã hóa dữ liệu bằng bất kỳ phiên bản schema nào mà nó biết, ví dụ schema đó có thể được biên dịch vào trong ứng dụng. Đây được gọi là writer’s schema (schema của writer).
Khi một ứng dụng muốn giải mã một số dữ liệu (đọc từ file hoặc cơ sở dữ liệu, nhận từ mạng, v.v.), nó sử dụng hai schema: writer’s schema giống hệt với schema được dùng để mã hóa, và reader’s schema (schema của reader), có thể khác nhau. Điều này được minh họa trong Hình 5-5. Reader’s schema xác định các trường của mỗi bản ghi mà code ứng dụng đang mong đợi, và kiểu dữ liệu của chúng.
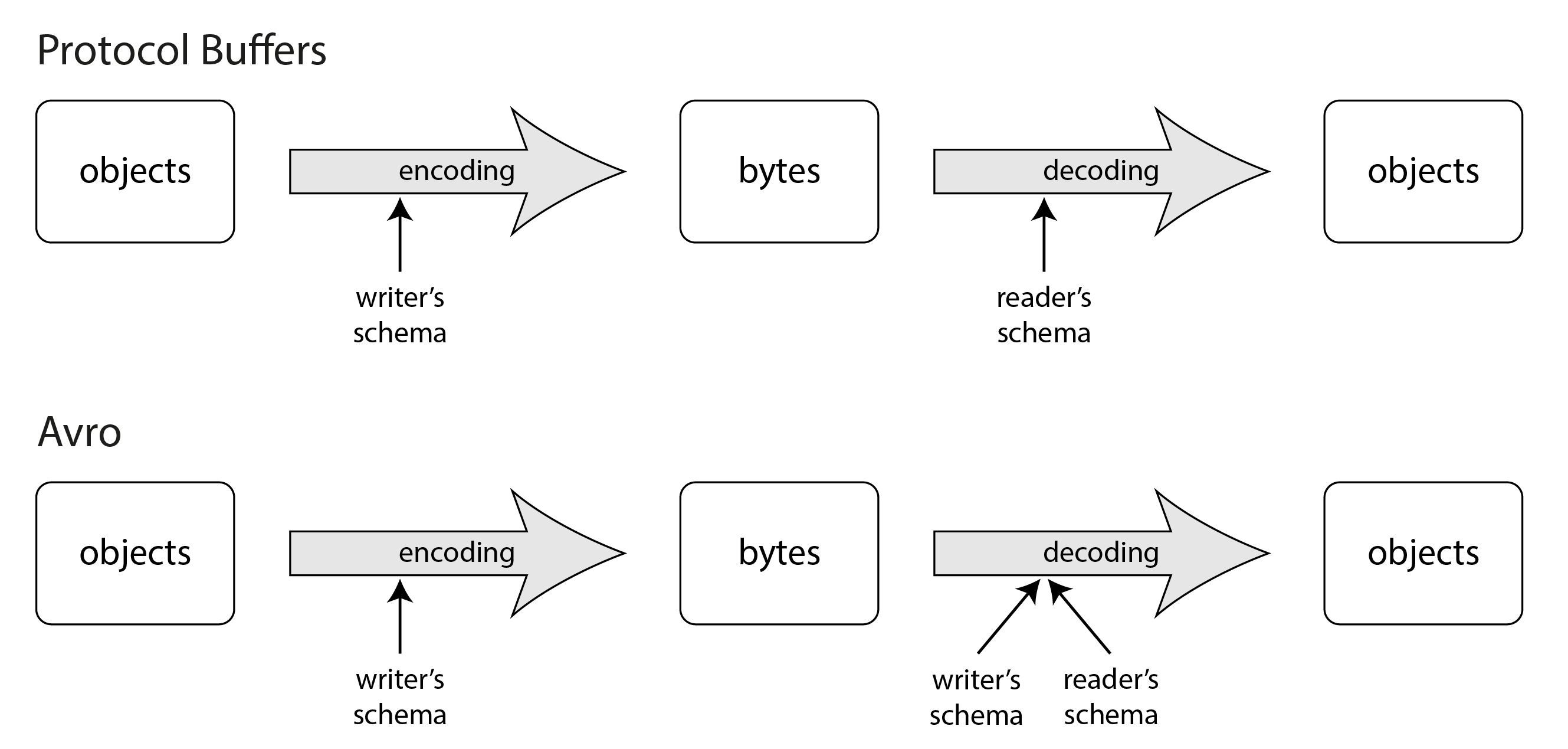
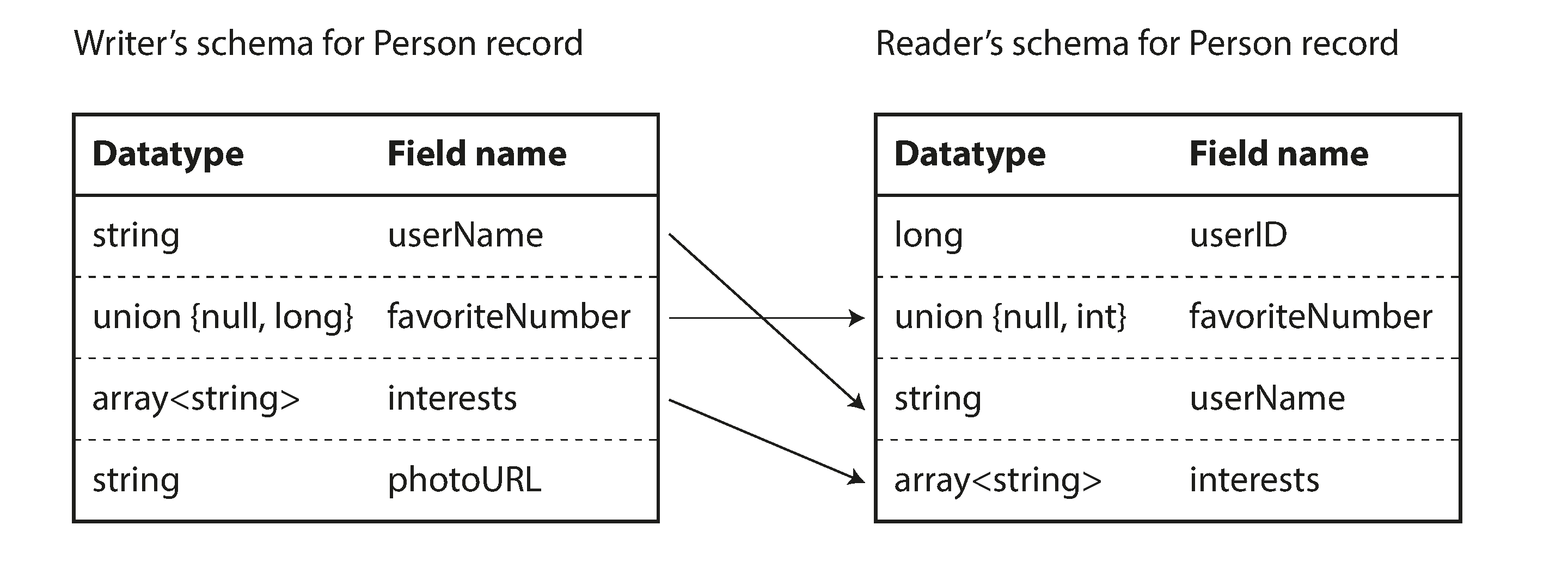
Nếu reader’s schema và writer’s schema giống nhau, việc giải mã rất dễ dàng. Nếu chúng khác nhau, Avro giải quyết sự khác biệt bằng cách đặt writer’s schema và reader’s schema cạnh nhau để dịch dữ liệu từ writer’s schema sang reader’s schema. Đặc tả Avro 16 17 xác định chính xác cách thức phân giải này hoạt động, và được minh họa trong Hình 5-6.
Ví dụ, không có vấn đề gì nếu writer’s schema và reader’s schema có các trường theo thứ tự khác nhau, vì quá trình phân giải schema khớp các trường theo tên trường. Nếu code đọc dữ liệu gặp một trường xuất hiện trong writer’s schema nhưng không có trong reader’s schema, nó sẽ bị bỏ qua. Nếu code đọc dữ liệu mong đợi một trường nào đó, nhưng writer’s schema không chứa trường có tên đó, nó sẽ được điền bằng giá trị mặc định được khai báo trong reader’s schema.
Các quy tắc schema evolution
Với Avro, forward compatibility (tương thích tiến) có nghĩa là bạn có thể dùng phiên bản mới của schema làm writer và phiên bản cũ của schema làm reader. Ngược lại, backward compatibility (tương thích lùi) có nghĩa là bạn có thể dùng phiên bản mới của schema làm reader và phiên bản cũ làm writer.
Để duy trì tính tương thích, bạn chỉ có thể thêm hoặc xóa một trường có giá trị mặc định. (Trường
favoriteNumber trong schema Avro của chúng ta có giá trị mặc định là null.) Ví dụ, giả sử bạn thêm một
trường với giá trị mặc định, trường mới này tồn tại trong schema mới nhưng không có trong schema cũ. Khi một
reader dùng schema mới đọc một bản ghi được ghi bằng schema cũ, giá trị mặc định sẽ được điền vào
cho trường bị thiếu.
Nếu bạn thêm một trường không có giá trị mặc định, các reader mới sẽ không thể đọc dữ liệu được ghi bởi các writer cũ, do đó bạn sẽ phá vỡ backward compatibility. Nếu bạn xóa một trường không có giá trị mặc định, các reader cũ sẽ không thể đọc dữ liệu được ghi bởi các writer mới, do đó bạn sẽ phá vỡ forward compatibility.
Trong một số ngôn ngữ lập trình, null là giá trị mặc định chấp nhận được cho bất kỳ biến nào, nhưng điều này không phải
trường hợp trong Avro: nếu bạn muốn cho phép một trường là null, bạn phải dùng union type (kiểu hợp nhất). Ví dụ,
union { null, long, string } field; chỉ ra rằng field có thể là một số, hoặc một chuỗi, hoặc null.
Bạn chỉ có thể dùng null làm giá trị mặc định nếu nó là nhánh đầu tiên của union. Điều này hơi
dài dòng hơn so với việc mặc định cho phép tất cả nullable, nhưng nó giúp ngăn chặn lỗi bằng cách rõ ràng
về những gì có thể và không thể là null 18.
Thay đổi kiểu dữ liệu của một trường là có thể, miễn là Avro có thể chuyển đổi kiểu đó. Thay đổi tên của một trường là có thể nhưng hơi phức tạp: reader’s schema có thể chứa các alias (bí danh) cho tên trường, vì vậy nó có thể khớp tên trường của writer’s schema cũ với các alias. Điều này có nghĩa là việc thay đổi tên trường là backward compatible nhưng không forward compatible. Tương tự, thêm một nhánh vào union type là backward compatible nhưng không forward compatible.
Nhưng writer’s schema là gì?
Có một câu hỏi quan trọng mà chúng ta đã bỏ qua cho đến nay: làm thế nào reader biết writer’s schema mà một phần dữ liệu cụ thể được mã hóa? Chúng ta không thể chỉ đơn giản đưa toàn bộ schema vào mỗi bản ghi, vì schema có thể sẽ lớn hơn nhiều so với dữ liệu được mã hóa, làm cho tất cả sự tiết kiệm không gian từ mã hóa nhị phân trở nên vô nghĩa.
Câu trả lời phụ thuộc vào ngữ cảnh mà Avro đang được sử dụng. Để đưa ra một vài ví dụ:
- File lớn chứa nhiều bản ghi
- Một cách dùng phổ biến cho Avro là lưu trữ một file lớn chứa hàng triệu bản ghi, tất cả được mã hóa bằng cùng một schema. (Chúng ta sẽ thảo luận về tình huống này trong Chương 11.) Trong trường hợp này, writer của file đó chỉ cần đưa writer’s schema một lần ở đầu file. Avro chỉ định một định dạng file (object container files) để làm điều này.
- Cơ sở dữ liệu với các bản ghi được ghi riêng lẻ
- Trong cơ sở dữ liệu, các bản ghi khác nhau có thể được ghi vào các thời điểm khác nhau bằng các writer’s schema khác nhau, bạn không thể giả định rằng tất cả các bản ghi sẽ có cùng schema. Giải pháp đơn giản nhất là đưa một số phiên bản vào đầu mỗi bản ghi được mã hóa, và giữ một danh sách các phiên bản schema trong cơ sở dữ liệu của bạn. Một reader có thể tải một bản ghi, trích xuất số phiên bản, và sau đó tải writer’s schema cho số phiên bản đó từ cơ sở dữ liệu. Sử dụng writer’s schema đó, nó có thể giải mã phần còn lại của bản ghi.
Schema registry của Confluent dành cho Apache Kafka 19 và Espresso của LinkedIn 20 hoạt động theo cách này, ví dụ như vậy.
- Gửi bản ghi qua kết nối mạng
- Khi hai tiến trình đang giao tiếp qua kết nối mạng hai chiều, chúng có thể thương lượng phiên bản schema khi thiết lập kết nối và sau đó sử dụng schema đó trong suốt thời gian tồn tại của kết nối. Giao thức Avro RPC (xem “Dataflow Through Services: REST and RPC”) hoạt động như vậy.
Cơ sở dữ liệu các phiên bản schema là điều hữu ích cần có trong bất kỳ trường hợp nào, vì nó hoạt động như tài liệu và cho bạn cơ hội kiểm tra tính tương thích schema 21. Làm số phiên bản, bạn có thể dùng một số nguyên tăng dần đơn giản, hoặc bạn có thể dùng một hash của schema.
Schema được tạo động
Một ưu điểm của cách tiếp cận của Avro, so với Protocol Buffers, là schema không chứa bất kỳ số tag nào. Nhưng tại sao điều này quan trọng? Vấn đề gì với việc giữ một vài số trong schema?
Sự khác biệt là Avro thân thiện hơn với các schema được tạo động. Ví dụ, giả sử bạn có một cơ sở dữ liệu quan hệ mà nội dung của nó bạn muốn dump ra file, và bạn muốn dùng định dạng nhị phân để tránh các vấn đề đã đề cập với các định dạng văn bản (JSON, CSV, XML). Nếu bạn dùng Avro, bạn có thể khá dễ dàng tạo một Avro schema (theo biểu diễn JSON chúng ta đã thấy trước đó) từ relational schema và mã hóa nội dung cơ sở dữ liệu bằng schema đó, dump tất cả vào một Avro object container file 22. Bạn có thể tạo một record schema cho mỗi bảng cơ sở dữ liệu, và mỗi cột trở thành một trường trong bản ghi đó. Tên cột trong cơ sở dữ liệu ánh xạ tới tên trường trong Avro.
Bây giờ, nếu database schema thay đổi (ví dụ, một bảng có thêm một cột và xóa một cột), bạn chỉ cần tạo một Avro schema mới từ database schema đã cập nhật và xuất dữ liệu trong Avro schema mới. Quá trình xuất dữ liệu không cần chú ý đến sự thay đổi schema, nó có thể đơn giản thực hiện việc chuyển đổi schema mỗi lần chạy. Bất kỳ ai đọc các file dữ liệu mới sẽ thấy rằng các trường của bản ghi đã thay đổi, nhưng vì các trường được xác định theo tên, writer’s schema đã cập nhật vẫn có thể được khớp với reader’s schema cũ.
Ngược lại, nếu bạn đang dùng Protocol Buffers cho mục đích này, các field tag có thể phải được gán thủ công: mỗi khi database schema thay đổi, một quản trị viên sẽ phải cập nhật thủ công ánh xạ từ tên cột cơ sở dữ liệu sang field tag. (Có thể tự động hóa điều này, nhưng schema generator sẽ phải rất cẩn thận để không gán các field tag đã được dùng trước đó.) Loại schema được tạo động này đơn giản không phải là mục tiêu thiết kế của Protocol Buffers, trong khi nó là của Avro.
Ưu điểm của Schemas
Như chúng ta đã thấy, Protocol Buffers và Avro đều dùng schema để mô tả định dạng mã hóa nhị phân. Các ngôn ngữ schema của chúng đơn giản hơn nhiều so với XML Schema hoặc JSON Schema, vốn hỗ trợ các quy tắc xác thực chi tiết hơn nhiều (ví dụ: “giá trị chuỗi của trường này phải khớp với biểu thức chính quy này” hoặc “giá trị số nguyên của trường này phải nằm trong khoảng từ 0 đến 100”). Vì Protocol Buffers và Avro đơn giản hơn để triển khai và đơn giản hơn để sử dụng, chúng đã phát triển để hỗ trợ một phạm vi khá rộng các ngôn ngữ lập trình.
Các ý tưởng mà các mã hóa này dựa trên không hề mới. Ví dụ, chúng có nhiều điểm chung với ASN.1, một ngôn ngữ định nghĩa schema được chuẩn hóa lần đầu vào năm 1984 23 24. Nó được dùng để định nghĩa các giao thức mạng khác nhau, và mã hóa nhị phân của nó (DER) vẫn được dùng để mã hóa các chứng chỉ SSL (X.509), ví dụ 25. ASN.1 hỗ trợ schema evolution bằng cách dùng số tag, tương tự như Protocol Buffers 26. Tuy nhiên, nó cũng rất phức tạp và được tài liệu hóa kém, vì vậy ASN.1 có lẽ không phải là lựa chọn tốt cho các ứng dụng mới.
Nhiều hệ thống dữ liệu cũng triển khai một số loại mã hóa nhị phân độc quyền cho dữ liệu của họ. Ví dụ, hầu hết các cơ sở dữ liệu quan hệ có một giao thức mạng mà qua đó bạn có thể gửi truy vấn đến cơ sở dữ liệu và nhận lại các phản hồi. Các giao thức đó thường dành riêng cho một cơ sở dữ liệu cụ thể, và nhà cung cấp cơ sở dữ liệu cung cấp một driver (ví dụ: sử dụng các API ODBC hoặc JDBC) để giải mã phản hồi từ giao thức mạng của cơ sở dữ liệu thành các cấu trúc dữ liệu trong bộ nhớ.
Vì vậy, chúng ta có thể thấy rằng mặc dù các định dạng dữ liệu văn bản như JSON, XML và CSV rất phổ biến, các mã hóa nhị phân dựa trên schema cũng là một lựa chọn khả thi. Chúng có một số thuộc tính hay:
- Chúng có thể nhỏ gọn hơn nhiều so với các biến thể “binary JSON” khác nhau, vì chúng có thể bỏ qua tên trường khỏi dữ liệu được mã hóa.
- Schema là một dạng tài liệu có giá trị, và vì schema cần thiết để giải mã, bạn có thể chắc chắn rằng nó được cập nhật (trong khi tài liệu được duy trì thủ công có thể dễ dàng sai lệch so với thực tế).
- Lưu giữ cơ sở dữ liệu các schema cho phép bạn kiểm tra forward và backward compatibility của các thay đổi schema, trước khi bất kỳ thứ gì được triển khai.
- Đối với người dùng các ngôn ngữ lập trình có kiểu tĩnh, khả năng tạo code từ schema rất hữu ích, vì nó cho phép kiểm tra kiểu tại thời điểm biên dịch.
Tóm lại, schema evolution cho phép cùng loại linh hoạt như các cơ sở dữ liệu JSON schemaless/schema-on-read cung cấp (xem “Schema flexibility in the document model”), đồng thời cũng cung cấp các đảm bảo tốt hơn về dữ liệu của bạn và công cụ tốt hơn.
Các Chế Độ Dataflow
Ở đầu chương này, chúng ta đã nói rằng bất cứ khi nào bạn muốn gửi một số dữ liệu đến một tiến trình khác mà bạn không chia sẻ bộ nhớ, ví dụ bất cứ khi nào bạn muốn gửi dữ liệu qua mạng hoặc ghi vào file, bạn cần mã hóa nó thành một chuỗi byte. Sau đó, chúng ta đã thảo luận về nhiều cách mã hóa khác nhau để làm điều này.
Chúng ta đã nói về forward và backward compatibility, vốn quan trọng cho khả năng tiến hóa (evolvability, giúp thay đổi trở nên dễ dàng bằng cách cho phép bạn nâng cấp các phần khác nhau của hệ thống một cách độc lập, và không phải thay đổi tất cả cùng một lúc). Tính tương thích là mối quan hệ giữa một tiến trình mã hóa dữ liệu và một tiến trình khác giải mã nó.
Đó là một ý tưởng khá trừu tượng, có nhiều cách dữ liệu có thể chảy từ tiến trình này sang tiến trình khác. Ai mã hóa dữ liệu, và ai giải mã nó? Trong phần còn lại của chương này, chúng ta sẽ khám phá một số cách phổ biến nhất mà dữ liệu chảy giữa các tiến trình:
- Qua cơ sở dữ liệu (xem “Dataflow Through Databases”)
- Qua các lời gọi dịch vụ (xem “Dataflow Through Services: REST and RPC”)
- Qua các workflow engine (xem “Durable Execution and Workflows”)
- Qua các message bất đồng bộ (xem “Event-Driven Architectures”)
Dataflow Qua Cơ Sở Dữ Liệu
Trong cơ sở dữ liệu, tiến trình ghi vào cơ sở dữ liệu mã hóa dữ liệu, và tiến trình đọc từ cơ sở dữ liệu giải mã nó. Có thể chỉ có một tiến trình duy nhất truy cập cơ sở dữ liệu, trong trường hợp đó reader chỉ đơn giản là một phiên bản sau của cùng tiến trình, trong trường hợp đó bạn có thể nghĩ về việc lưu trữ một thứ gì đó trong cơ sở dữ liệu như gửi tin nhắn cho bản thân mình trong tương lai.
Backward compatibility rõ ràng là cần thiết ở đây, ngược lại bản thân bạn trong tương lai sẽ không thể giải mã những gì bạn đã ghi trước đó.
Nói chung, nhiều tiến trình khác nhau thường xuyên truy cập vào cơ sở dữ liệu cùng một lúc. Các tiến trình đó có thể là một số ứng dụng hoặc dịch vụ khác nhau, hoặc chúng có thể đơn giản là một số phiên bản của cùng một dịch vụ (chạy song song để đảm bảo khả năng mở rộng hoặc khả năng chịu lỗi). Dù thế nào, trong môi trường mà ứng dụng đang thay đổi, một số tiến trình truy cập cơ sở dữ liệu có thể đang chạy code mới hơn và một số đang chạy code cũ hơn, ví dụ vì một phiên bản mới hiện đang được triển khai trong một rolling upgrade, một số phiên bản đã được cập nhật trong khi những phiên bản khác thì chưa.
Điều này có nghĩa là một giá trị trong cơ sở dữ liệu có thể được ghi bởi một phiên bản mới hơn của code, và sau đó được đọc bởi một phiên bản cũ hơn của code vẫn đang chạy. Do đó, forward compatibility cũng thường được yêu cầu đối với cơ sở dữ liệu.
Các giá trị khác nhau được ghi vào các thời điểm khác nhau
Cơ sở dữ liệu thường cho phép bất kỳ giá trị nào được cập nhật vào bất kỳ lúc nào. Điều này có nghĩa là trong một cơ sở dữ liệu, bạn có thể có một số giá trị được ghi cách đây năm mili giây, và một số giá trị được ghi cách đây năm năm.
Khi bạn triển khai một phiên bản mới của ứng dụng (ít nhất là ứng dụng phía máy chủ), bạn có thể hoàn toàn thay thế phiên bản cũ bằng phiên bản mới trong vài phút. Điều tương tự không đúng với nội dung cơ sở dữ liệu: dữ liệu năm năm tuổi vẫn sẽ ở đó, trong mã hóa gốc, trừ khi bạn đã ghi lại nó một cách rõ ràng từ đó. Quan sát này đôi khi được tóm tắt là data outlives code (dữ liệu sống lâu hơn code).
Viết lại (migrating, di chuyển) dữ liệu sang một schema mới chắc chắn là có thể, nhưng đây là việc tốn kém để
làm trên một tập dữ liệu lớn, vì vậy hầu hết các cơ sở dữ liệu tránh điều này nếu có thể. Hầu hết các cơ sở dữ liệu quan hệ cho phép
thay đổi schema đơn giản, chẳng hạn như thêm một cột mới với giá trị mặc định null, mà không cần ghi lại
dữ liệu hiện có. Khi một hàng cũ được đọc, cơ sở dữ liệu điền null cho bất kỳ cột nào bị thiếu
trong dữ liệu được mã hóa trên đĩa.
Do đó, schema evolution cho phép toàn bộ cơ sở dữ liệu xuất hiện như thể nó được mã hóa bằng một schema
duy nhất, mặc dù bộ nhớ nền có thể chứa các bản ghi được mã hóa với các phiên bản lịch sử
khác nhau của schema.
Các thay đổi schema phức tạp hơn, ví dụ thay đổi một thuộc tính giá trị đơn thành đa giá trị, hoặc di chuyển một số dữ liệu vào bảng riêng biệt, vẫn yêu cầu dữ liệu phải được ghi lại, thường ở cấp ứng dụng 27. Duy trì forward và backward compatibility qua các lần migration như vậy vẫn là một vấn đề nghiên cứu 28.
Lưu trữ lưu trữ
Có lẽ bạn lấy một snapshot của cơ sở dữ liệu theo thời gian, chẳng hạn cho mục đích sao lưu hoặc để tải vào một data warehouse (xem “Data Warehousing”). Trong trường hợp này, data dump thường được mã hóa bằng schema mới nhất, ngay cả khi mã hóa gốc trong cơ sở dữ liệu nguồn chứa một hỗn hợp các phiên bản schema từ các thời kỳ khác nhau. Vì bạn đang sao chép dữ liệu dù thế nào, bạn cũng có thể mã hóa bản sao dữ liệu một cách nhất quán.
Vì data dump được ghi trong một lần và sau đó không thay đổi, các định dạng như Avro object container files rất phù hợp. Đây cũng là một cơ hội tốt để mã hóa dữ liệu trong định dạng column-oriented (hướng cột) thân thiện với phân tích như Parquet (xem “Column Compression”).
Trong Chương 11, chúng ta sẽ nói thêm về việc sử dụng dữ liệu trong lưu trữ lưu trữ.
Dataflow Qua Dịch Vụ: REST và RPC
Khi bạn có các tiến trình cần giao tiếp qua mạng, có một vài cách khác nhau để sắp xếp giao tiếp đó. Cách sắp xếp phổ biến nhất là có hai vai trò: clients (máy khách) và servers (máy chủ). Các server phơi bày một API qua mạng, và các client có thể kết nối đến các server để gửi yêu cầu đến API đó. API mà server phơi bày được gọi là một service (dịch vụ).
Web hoạt động theo cách này: các client (trình duyệt web) gửi yêu cầu đến các web server, thực hiện GET request
để tải HTML, CSS, JavaScript, hình ảnh, v.v., và thực hiện POST request để gửi dữ liệu đến
server. API bao gồm một tập hợp các giao thức và định dạng dữ liệu chuẩn hóa (HTTP, URLs, SSL/TLS,
HTML, v.v.). Vì các trình duyệt web, web server và tác giả website hầu hết đồng ý về các tiêu chuẩn này,
bạn có thể dùng bất kỳ trình duyệt web nào để truy cập bất kỳ website nào (ít nhất là về lý thuyết!).
Trình duyệt web không phải là loại client duy nhất. Ví dụ, các ứng dụng native chạy trên thiết bị di động và máy tính để bàn thường nói chuyện với server, và các ứng dụng JavaScript phía client chạy bên trong các trình duyệt web cũng có thể thực hiện các HTTP request. Trong trường hợp này, phản hồi của server thường không phải là HTML để hiển thị cho con người, mà là dữ liệu trong một mã hóa thuận tiện để xử lý thêm bởi code ứng dụng phía client (thường nhất là JSON). Mặc dù HTTP có thể được dùng làm giao thức truyền tải, API được triển khai trên đó là dành riêng cho ứng dụng, và client và server cần đồng ý về các chi tiết của API đó.
Ở một số mặt, các dịch vụ tương tự như cơ sở dữ liệu: chúng thường cho phép client gửi và truy vấn dữ liệu. Tuy nhiên, trong khi cơ sở dữ liệu cho phép các truy vấn tùy ý bằng các ngôn ngữ truy vấn chúng ta đã thảo luận trong Chương 3, các dịch vụ phơi bày một API dành riêng cho ứng dụng chỉ cho phép các đầu vào và đầu ra được xác định trước bởi business logic (logic nghiệp vụ) của dịch vụ 29. Hạn chế này cung cấp một mức độ đóng gói: các dịch vụ có thể áp đặt các hạn chế chi tiết về những gì client có thể và không thể làm.
Một mục tiêu thiết kế chính của kiến trúc service-oriented/microservices là làm cho ứng dụng dễ dàng hơn để thay đổi và duy trì bằng cách làm cho các dịch vụ có thể triển khai và tiến hóa độc lập. Một nguyên tắc phổ biến là mỗi dịch vụ nên được sở hữu bởi một đội, và đội đó có thể phát hành các phiên bản mới của dịch vụ thường xuyên, mà không cần phối hợp với các đội khác. Do đó, chúng ta nên mong đợi các phiên bản cũ và mới của server và client đang chạy cùng một lúc, và do đó mã hóa dữ liệu được dùng bởi server và client phải tương thích giữa các phiên bản của service API.
Web services
Khi HTTP được dùng làm giao thức nền để nói chuyện với dịch vụ, nó được gọi là web service. Web service thường được sử dụng khi xây dựng kiến trúc service oriented hoặc microservices (đã thảo luận trước đó trong “Microservices and Serverless”). Thuật ngữ “web service” có lẽ hơi sai tên một chút, vì web service không chỉ được dùng trên web, mà trong nhiều ngữ cảnh khác nhau. Ví dụ:
- Một ứng dụng client chạy trên thiết bị của người dùng (ví dụ: một ứng dụng native trên thiết bị di động, hoặc một ứng dụng web JavaScript trong trình duyệt) thực hiện yêu cầu đến một dịch vụ qua HTTP. Các yêu cầu này thường đi qua internet công cộng.
- Một dịch vụ thực hiện yêu cầu đến một dịch vụ khác thuộc cùng một tổ chức, thường nằm trong cùng một datacenter, như một phần của kiến trúc service-oriented/microservices.
- Một dịch vụ thực hiện yêu cầu đến một dịch vụ thuộc sở hữu của một tổ chức khác, thường qua internet. Điều này được dùng để trao đổi dữ liệu giữa các hệ thống backend của các tổ chức khác nhau. Loại này bao gồm các public API được cung cấp bởi các dịch vụ trực tuyến, chẳng hạn như hệ thống xử lý thẻ tín dụng, hoặc OAuth để chia sẻ quyền truy cập vào dữ liệu người dùng.
Triết lý thiết kế dịch vụ phổ biến nhất là REST, được xây dựng dựa trên các nguyên tắc của HTTP 30 31. Nó nhấn mạnh vào các định dạng dữ liệu đơn giản, sử dụng URL để xác định tài nguyên và sử dụng các tính năng HTTP để kiểm soát cache, xác thực và thương lượng loại nội dung. Một API được thiết kế theo các nguyên tắc của REST được gọi là RESTful.
Code cần gọi một web service API phải biết endpoint HTTP nào cần truy vấn, và định dạng dữ liệu nào cần gửi và mong đợi trong phản hồi. Ngay cả khi một dịch vụ áp dụng các nguyên tắc thiết kế RESTful, client cần tìm hiểu các chi tiết này bằng cách nào đó. Các nhà phát triển dịch vụ thường dùng một interface definition language (IDL, ngôn ngữ định nghĩa giao diện) để định nghĩa và tài liệu hóa các endpoint API và mô hình dữ liệu của dịch vụ, và để tiến hóa chúng theo thời gian. Các nhà phát triển khác có thể dùng định nghĩa dịch vụ để xác định cách truy vấn dịch vụ. Hai IDL dịch vụ phổ biến nhất là OpenAPI (còn được gọi là Swagger 32) và gRPC. OpenAPI được dùng cho các web service gửi và nhận dữ liệu JSON, trong khi các dịch vụ gRPC gửi và nhận Protocol Buffers.
Các nhà phát triển thường viết định nghĩa dịch vụ OpenAPI trong JSON hoặc YAML; xem Ví dụ 5-3. Định nghĩa dịch vụ cho phép các nhà phát triển định nghĩa endpoint dịch vụ, tài liệu, phiên bản, mô hình dữ liệu và nhiều hơn nữa. Các định nghĩa gRPC trông tương tự, nhưng được định nghĩa bằng định nghĩa dịch vụ Protocol Buffers.
Ví dụ 5-3. Ví dụ định nghĩa dịch vụ OpenAPI trong YAML
openapi: 3.0.0
info:
title: Ping, Pong
version: 1.0.0
servers:
- url: http://localhost:8080
paths:
/ping:
get:
summary: Given a ping, returns a pong message
responses:
'200':
description: A pong
content:
application/json:
schema:
type: object
properties:
message:
type: string
example: Pong!Ngay cả khi triết lý thiết kế và IDL được áp dụng, các nhà phát triển vẫn phải viết code triển khai các lời gọi API của dịch vụ. Một service framework thường được áp dụng để đơn giản hóa nỗ lực này. Các service framework như Spring Boot, FastAPI và gRPC cho phép các nhà phát triển viết business logic cho mỗi endpoint API trong khi code framework xử lý routing, metrics, caching, xác thực, v.v. Ví dụ 5-4 cho thấy một ví dụ triển khai Python của dịch vụ được định nghĩa trong Ví dụ 5-3.
Ví dụ 5-4. Ví dụ dịch vụ FastAPI triển khai định nghĩa từ [Ví dụ 5-3](/vi/ch5#fig_open_api_def)
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI(title="Ping, Pong", version="1.0.0")
class PongResponse(BaseModel):
message: str = "Pong!"
@app.get("/ping", response_model=PongResponse,
summary="Given a ping, returns a pong message")
async def ping():
return PongResponse()Nhiều framework kết hợp định nghĩa dịch vụ và code server lại với nhau. Trong một số trường hợp, chẳng hạn như với framework Python FastAPI phổ biến, server được viết bằng code và IDL được tạo ra tự động. Trong các trường hợp khác, chẳng hạn như với gRPC, định nghĩa dịch vụ được viết trước, và scaffolding code server được tạo ra. Cả hai cách tiếp cận đều cho phép các nhà phát triển tạo ra các thư viện client và SDK bằng nhiều ngôn ngữ khác nhau từ định nghĩa dịch vụ. Ngoài việc tạo code, các công cụ IDL như Swagger có thể tạo tài liệu, xác minh tính tương thích thay đổi schema, và cung cấp giao diện người dùng đồ họa để nhà phát triển truy vấn và kiểm tra dịch vụ.
Các vấn đề với remote procedure calls (RPC)
Web service chỉ là sự hiện thân mới nhất của một dòng dài các công nghệ để thực hiện API request qua mạng, nhiều trong số chúng đã nhận được rất nhiều hype nhưng có những vấn đề nghiêm trọng. Enterprise JavaBeans (EJB) và Java’s Remote Method Invocation (RMI) bị giới hạn ở Java. The Distributed Architecture (CORBA) quá phức tạp và không cung cấp khả năng tương thích ngược hay tương thích xuôi 33. SOAP và bộ khung WS-* web services nhằm mục tiêu cung cấp khả năng tương tác giữa các nhà cung cấp khác nhau, nhưng cũng bị cản trở bởi sự phức tạp và các vấn đề tương thích 34 35 36.
Tất cả những thứ này đều dựa trên khái niệm remote procedure call (RPC, gọi thủ tục từ xa), tồn tại từ những năm 1970 37. Mô hình RPC cố gắng làm cho một yêu cầu tới dịch vụ mạng từ xa trông giống hệt như gọi một hàm hay phương thức trong ngôn ngữ lập trình của bạn, trong cùng một tiến trình (cách trừu tượng hóa này gọi là location transparency, minh bạch vị trí). Mặc dù RPC thoạt đầu có vẻ tiện lợi, nhưng cách tiếp cận này có khiếm khuyết cơ bản 38 39. Một yêu cầu mạng rất khác so với một lời gọi hàm cục bộ:
- Một lời gọi hàm cục bộ có thể đoán trước được và hoặc thành công hoặc thất bại, chỉ phụ thuộc vào các tham số trong tầm kiểm soát của bạn. Một yêu cầu mạng thì không thể đoán trước: yêu cầu hoặc phản hồi có thể bị mất do sự cố mạng, hoặc máy từ xa có thể chậm hay không khả dụng, và những vấn đề đó hoàn toàn nằm ngoài tầm kiểm soát của bạn. Sự cố mạng khá phổ biến, nên bạn cần phải dự trù chúng, ví dụ bằng cách thử lại (retry) một yêu cầu thất bại.
- Một lời gọi hàm cục bộ hoặc trả về kết quả, hoặc ném ra ngoại lệ, hoặc không bao giờ trả về (vì nó rơi vào vòng lặp vô hạn hoặc tiến trình bị crash). Một yêu cầu mạng có thêm một kết quả khả thi khác: nó có thể trả về mà không có kết quả, do timeout (hết thời gian chờ). Trong trường hợp đó, bạn đơn giản là không biết điều gì đã xảy ra: nếu bạn không nhận được phản hồi từ dịch vụ từ xa, bạn không có cách nào biết yêu cầu có đến nơi hay không. (Chúng ta thảo luận vấn đề này chi tiết hơn trong Chương 9.)
- Nếu bạn thử lại một yêu cầu mạng thất bại, có thể xảy ra trường hợp yêu cầu trước đó thực ra đã đến nơi, chỉ là phản hồi bị mất. Khi đó, việc thử lại sẽ khiến hành động được thực hiện nhiều lần, trừ khi bạn xây dựng cơ chế loại bỏ trùng lặp (idempotence, tính lũy đẳng) vào giao thức 40. Lời gọi hàm cục bộ không có vấn đề này. (Chúng ta thảo luận về tính lũy đẳng chi tiết hơn trong “Idempotence”.)
- Mỗi lần bạn gọi một hàm cục bộ, thường mất khoảng cùng một khoảng thời gian để thực thi. Một yêu cầu mạng chậm hơn nhiều so với lời gọi hàm, và độ trễ của nó cũng biến thiên rất lớn: khi thuận lợi, nó có thể hoàn thành trong chưa đầy một mili giây, nhưng khi mạng tắc nghẽn hoặc dịch vụ từ xa bị quá tải, nó có thể mất nhiều giây để làm đúng điều tương tự.
- Khi bạn gọi một hàm cục bộ, bạn có thể truyền hiệu quả các tham chiếu (con trỏ) đến các đối tượng trong bộ nhớ cục bộ. Khi bạn thực hiện một yêu cầu mạng, tất cả các tham số đó cần được mã hóa thành một chuỗi byte để gửi qua mạng. Điều đó ổn nếu các tham số là kiểu nguyên thủy bất biến như số hay chuỗi ngắn, nhưng nhanh chóng trở nên phức tạp với lượng dữ liệu lớn hơn và các đối tượng có thể thay đổi.
- Client và service có thể được triển khai bằng các ngôn ngữ lập trình khác nhau, vì vậy bộ khung RPC phải chuyển đổi kiểu dữ liệu từ ngôn ngữ này sang ngôn ngữ khác. Điều này có thể trở nên rắc rối, vì không phải tất cả các ngôn ngữ đều có cùng kiểu dữ liệu, ví dụ như vấn đề của JavaScript với các số lớn hơn 253 (xem “JSON, XML, and Binary Variants”). Vấn đề này không tồn tại trong một tiến trình đơn được viết bằng một ngôn ngữ duy nhất.
Tất cả các yếu tố này có nghĩa là không có ích gì khi cố làm cho một dịch vụ từ xa trông quá giống một đối tượng cục bộ trong ngôn ngữ lập trình của bạn, bởi vì về bản chất chúng là hai thứ hoàn toàn khác nhau. Một phần sức hút của REST là nó xử lý việc truyền trạng thái qua mạng như một quá trình tách biệt với lời gọi hàm.
Load balancers, service discovery, và service meshes
Tất cả các dịch vụ giao tiếp qua mạng. Vì lý do đó, một client phải biết địa chỉ của dịch vụ mà nó đang kết nối tới, một vấn đề gọi là service discovery (khám phá dịch vụ). Cách đơn giản nhất là cấu hình client kết nối tới địa chỉ IP và cổng nơi dịch vụ đang chạy. Cách cấu hình này sẽ hoạt động, nhưng nếu server ngừng hoạt động, được chuyển sang máy mới, hoặc bị quá tải, client phải được cấu hình lại thủ công.
Để cung cấp tính khả dụng cao hơn và khả năng mở rộng, thường có nhiều phiên bản của một dịch vụ chạy trên các máy khác nhau, bất kỳ máy nào trong số đó đều có thể xử lý một yêu cầu đến. Việc phân phối yêu cầu trên các phiên bản này được gọi là load balancing (cân bằng tải) 41. Có nhiều giải pháp load balancing và service discovery:
- Hardware load balancers (cân bằng tải phần cứng) là các thiết bị chuyên dụng được cài đặt trong các trung tâm dữ liệu. Chúng cho phép client kết nối tới một host và cổng duy nhất, và các kết nối đến được định tuyến tới một trong các server đang chạy dịch vụ. Các load balancer như vậy phát hiện sự cố mạng khi kết nối tới một server downstream và chuyển lưu lượng sang các server khác.
- Software load balancers (cân bằng tải phần mềm) hoạt động gần giống với hardware load balancers. Nhưng thay vì yêu cầu thiết bị đặc biệt, các software load balancer như Nginx và HAProxy là các ứng dụng có thể được cài đặt trên máy tiêu chuẩn.
- Domain name service (DNS) là cách các tên miền được phân giải trên Internet khi bạn mở một trang web. Nó hỗ trợ load balancing bằng cách cho phép nhiều địa chỉ IP được liên kết với một tên miền duy nhất. Client sau đó có thể được cấu hình để kết nối tới dịch vụ bằng tên miền thay vì địa chỉ IP, và lớp mạng của client chọn địa chỉ IP nào để sử dụng khi thực hiện kết nối. Một nhược điểm của cách tiếp cận này là DNS được thiết kế để truyền bá các thay đổi trong khoảng thời gian dài hơn, và để lưu vào bộ nhớ cache các mục DNS. Nếu các server được khởi động, dừng hoặc di chuyển thường xuyên, client có thể thấy các địa chỉ IP cũ mà không còn có server nào chạy trên đó nữa.
- Service discovery systems (hệ thống khám phá dịch vụ) sử dụng registry tập trung thay vì DNS để theo dõi endpoint nào của dịch vụ đang khả dụng. Khi một phiên bản dịch vụ mới khởi động, nó tự đăng ký với hệ thống service discovery bằng cách khai báo host và cổng mà nó đang lắng nghe, cùng với các siêu dữ liệu liên quan như thông tin sở hữu shard (xem Chương 7), vị trí trung tâm dữ liệu, và nhiều thông tin khác. Dịch vụ sau đó định kỳ gửi tín hiệu heartbeat tới hệ thống khám phá để báo hiệu rằng dịch vụ vẫn khả dụng.
Khi một client muốn kết nối tới một dịch vụ, nó trước tiên truy vấn hệ thống khám phá để lấy danh sách các endpoint khả dụng, sau đó kết nối trực tiếp tới endpoint đó. So với DNS, service discovery hỗ trợ môi trường động hơn nhiều nơi các phiên bản dịch vụ thay đổi thường xuyên. Các hệ thống khám phá cũng cung cấp cho client nhiều siêu dữ liệu hơn về dịch vụ mà chúng đang kết nối tới, cho phép client đưa ra các quyết định load balancing thông minh hơn.
- Service meshes là một hình thức load balancing phức tạp kết hợp software load balancers và service discovery. Không giống như các software load balancer truyền thống, chạy trên một máy riêng biệt, các load balancer trong service mesh thường được triển khai dưới dạng thư viện client trong tiến trình hoặc dưới dạng tiến trình hay container “sidecar” trên cả client và server. Các ứng dụng client kết nối tới load balancer dịch vụ cục bộ của chúng, và load balancer đó kết nối với load balancer của server. Từ đó, kết nối được định tuyến tới tiến trình server cục bộ.
Dù phức tạp, topology này mang lại một số ưu điểm. Vì client và server được định tuyến hoàn toàn qua các kết nối cục bộ, mã hóa kết nối có thể được xử lý hoàn toàn ở cấp độ load balancer. Điều này giúp client và server không phải xử lý sự phức tạp của chứng chỉ SSL và TLS. Các hệ thống mesh cũng cung cấp khả năng quan sát tinh vi. Chúng có thể theo dõi dịch vụ nào đang gọi dịch vụ nào theo thời gian thực, phát hiện sự cố, theo dõi tải lưu lượng, và nhiều hơn nữa.
Giải pháp nào phù hợp phụ thuộc vào nhu cầu của từng tổ chức. Những tổ chức vận hành trong môi trường dịch vụ rất động với một bộ điều phối như Kubernetes thường chọn chạy service mesh như Istio hoặc Linkerd. Cơ sở hạ tầng chuyên biệt như cơ sở dữ liệu hay hệ thống nhắn tin có thể cần load balancer được xây dựng riêng cho mục đích đó. Các triển khai đơn giản hơn được phục vụ tốt nhất bằng software load balancer.
Mã hóa dữ liệu và tính tiến hóa cho RPC
Để đảm bảo tính tiến hóa, điều quan trọng là RPC client và server có thể được thay đổi và triển khai một cách độc lập. So với dữ liệu chảy qua cơ sở dữ liệu (như đã mô tả trong phần trước), chúng ta có thể đưa ra một giả định đơn giản hóa trong trường hợp luồng dữ liệu qua dịch vụ: có thể giả định hợp lý rằng tất cả các server sẽ được cập nhật trước, và tất cả các client sau đó. Do đó, bạn chỉ cần tương thích ngược cho yêu cầu, và tương thích xuôi cho phản hồi.
Các thuộc tính tương thích ngược và tương thích xuôi của một sơ đồ RPC được kế thừa từ bất kỳ mã hóa nào nó sử dụng:
- gRPC (Protocol Buffers) và Avro RPC có thể được phát triển theo các quy tắc tương thích của định dạng mã hóa tương ứng.
- RESTful API thường sử dụng JSON cho phản hồi, và JSON hoặc tham số được mã hóa URI/form cho các yêu cầu. Việc thêm các tham số yêu cầu tùy chọn và thêm các trường mới vào các đối tượng phản hồi thường được coi là các thay đổi duy trì tương thích.
Tính tương thích dịch vụ trở nên khó khăn hơn bởi thực tế là RPC thường được sử dụng cho giao tiếp qua ranh giới tổ chức, vì vậy nhà cung cấp dịch vụ thường không có quyền kiểm soát client của họ và không thể buộc họ nâng cấp. Do đó, tính tương thích cần được duy trì trong thời gian dài, có thể là vô thời hạn. Nếu cần thực hiện một thay đổi phá vỡ tương thích, nhà cung cấp dịch vụ thường phải duy trì nhiều phiên bản API của dịch vụ song song.
Không có sự đồng thuận về cách phiên bản hóa API hoạt động như thế nào (tức là cách client có thể chỉ ra
phiên bản API nào nó muốn sử dụng 42).
Đối với các RESTful API, các cách tiếp cận phổ biến là sử dụng số
phiên bản trong URL hoặc trong HTTP header Accept. Đối với các dịch vụ sử dụng API key để xác định một
client cụ thể, một lựa chọn khác là lưu trữ phiên bản API mà client yêu cầu trên server và cho phép
cập nhật lựa chọn phiên bản này thông qua giao diện quản trị riêng 43.
Durable Execution và Workflows
Theo định nghĩa, các kiến trúc dựa trên dịch vụ có nhiều dịch vụ, mỗi dịch vụ chịu trách nhiệm cho các phần khác nhau của ứng dụng. Hãy xem xét một ứng dụng xử lý thanh toán tính phí thẻ tín dụng và nạp tiền vào tài khoản ngân hàng. Hệ thống này có thể có các dịch vụ khác nhau phụ trách phát hiện gian lận, tích hợp thẻ tín dụng, tích hợp ngân hàng, v.v.
Việc xử lý một khoản thanh toán trong ví dụ của chúng ta đòi hỏi nhiều lời gọi dịch vụ. Một dịch vụ xử lý thanh toán có thể gọi dịch vụ phát hiện gian lận để kiểm tra gian lận, gọi dịch vụ thẻ tín dụng để ghi nợ thẻ tín dụng, và gọi dịch vụ ngân hàng để nạp tiền đã ghi nợ, như được minh họa trong Hình 5-7. Chúng ta gọi chuỗi các bước này là workflow (luồng công việc), và mỗi bước là một task (nhiệm vụ). Workflow thường được định nghĩa dưới dạng đồ thị các task. Định nghĩa workflow có thể được viết bằng ngôn ngữ lập trình đa mục đích, ngôn ngữ miền cụ thể (DSL), hoặc ngôn ngữ đánh dấu như Business Process Execution Language (BPEL) 44.
TASKS, ACTIVITIES, AND FUNCTIONS
Các engine workflow khác nhau sử dụng các tên khác nhau cho task. Temporal, ví dụ, sử dụng thuật ngữ activity. Các engine khác gọi task là durable functions (hàm bền vững). Mặc dù tên gọi khác nhau, các khái niệm là như nhau.
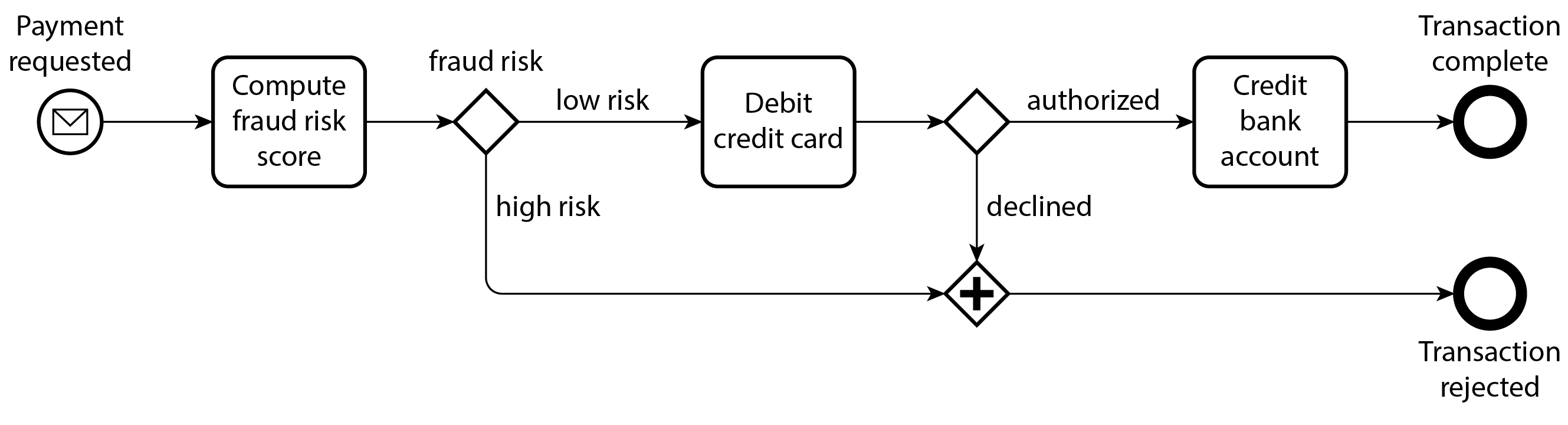
Hình 5-7. Ví dụ về một workflow được biểu diễn bằng Business Process Model and Notation (BPMN), một ký hiệu đồ họa.
Workflow được chạy, hay thực thi, bởi một workflow engine (engine luồng công việc). Workflow engine xác định khi nào chạy mỗi task, trên máy nào task phải được chạy, phải làm gì nếu một task thất bại (ví dụ, nếu máy bị crash trong khi task đang chạy), bao nhiêu task được phép thực thi song song, và nhiều hơn nữa.
Workflow engine thường bao gồm một orchestrator và một executor. Orchestrator chịu trách nhiệm lên lịch cho các task được thực thi và executor chịu trách nhiệm thực thi các task. Quá trình thực thi bắt đầu khi một workflow được kích hoạt. Orchestrator kích hoạt chính workflow đó nếu người dùng xác định lịch dựa trên thời gian, chẳng hạn như thực thi hàng giờ. Các nguồn bên ngoài như web service hoặc thậm chí con người cũng có thể kích hoạt thực thi workflow. Sau khi được kích hoạt, các executor được gọi để chạy task.
Có nhiều loại workflow engine giải quyết nhiều trường hợp sử dụng khác nhau. Một số, như Airflow, Dagster, và Prefect, tích hợp với các hệ thống dữ liệu và điều phối các task ETL. Một số khác, như Camunda và Orkes, cung cấp ký hiệu đồ họa cho workflow (như BPMN, được sử dụng trong Hình 5-7) để những người không phải kỹ sư có thể dễ dàng hơn trong việc định nghĩa và thực thi workflow. Và một số khác nữa, như Temporal và Restate, cung cấp durable execution (thực thi bền vững).
Durable execution
Các bộ khung durable execution đã trở thành một cách phổ biến để xây dựng các kiến trúc dựa trên dịch vụ yêu cầu tính giao dịch. Trong ví dụ thanh toán của chúng ta, chúng ta muốn xử lý mỗi khoản thanh toán đúng một lần. Một sự cố trong khi workflow đang thực thi có thể dẫn đến việc thẻ tín dụng bị tính phí, nhưng không có khoản nạp tiền vào tài khoản ngân hàng tương ứng. Trong kiến trúc dựa trên dịch vụ, chúng ta không thể đơn giản bọc hai task trong một giao dịch cơ sở dữ liệu. Hơn nữa, chúng ta có thể đang tương tác với các cổng thanh toán của bên thứ ba mà chúng ta có quyền kiểm soát hạn chế.
Các bộ khung durable execution là cách cung cấp exactly-once semantics (ngữ nghĩa chính xác một lần) cho workflow. Nếu một task thất bại, bộ khung sẽ thực thi lại task đó, nhưng sẽ bỏ qua bất kỳ lời gọi RPC hoặc thay đổi trạng thái nào mà task đã thực hiện thành công trước khi thất bại. Thay vào đó, bộ khung sẽ giả vờ thực hiện lời gọi, nhưng thực ra sẽ trả về kết quả từ lời gọi trước đó. Điều này khả thi vì các bộ khung durable execution ghi lại tất cả các lời gọi RPC và thay đổi trạng thái vào bộ lưu trữ bền vững như write-ahead log 45 46. Ví dụ 5-5 minh họa một định nghĩa workflow hỗ trợ durable execution sử dụng Temporal.
Ví dụ 5-5. Đoạn định nghĩa workflow Temporal cho workflow thanh toán trong [Hình 5-7](/vi/ch5#fig_encoding_workflow).
@workflow.defn
class PaymentWorkflow:
@workflow.run
async def run(self, payment: PaymentRequest) -> PaymentResult:
is_fraud = await workflow.execute_activity(
check_fraud,
payment,
start_to_close_timeout=timedelta(seconds=15),
)
if is_fraud:
return PaymentResultFraudulent
credit_card_response = await workflow.execute_activity(
debit_credit_card,
payment,
start_to_close_timeout=timedelta(seconds=15),
)
# ...Các bộ khung như Temporal không phải là không có thách thức. Các dịch vụ bên ngoài, chẳng hạn như cổng thanh toán của bên thứ ba trong ví dụ của chúng ta, vẫn phải cung cấp API có tính lũy đẳng. Các nhà phát triển phải nhớ sử dụng ID duy nhất cho các API này để ngăn chặn thực thi trùng lặp 47. Và vì các bộ khung durable execution ghi lại mỗi lời gọi RPC theo thứ tự, nó kỳ vọng rằng một lần thực thi tiếp theo sẽ thực hiện các lời gọi RPC theo cùng thứ tự. Điều này làm cho các thay đổi mã trở nên dễ vỡ: bạn có thể tạo ra hành vi không xác định chỉ bằng cách sắp xếp lại thứ tự các lời gọi hàm 48. Thay vì sửa đổi mã của một workflow hiện có, sẽ an toàn hơn khi triển khai một phiên bản mới của mã một cách riêng biệt, để các lần thực thi lại của các lần gọi workflow hiện có tiếp tục sử dụng phiên bản cũ, và chỉ các lần gọi mới mới sử dụng mã mới 49.
Tương tự, vì các bộ khung durable execution kỳ vọng phát lại tất cả mã một cách tất định (cùng đầu vào tạo ra cùng đầu ra), mã không tất định như bộ sinh số ngẫu nhiên hay đồng hồ hệ thống sẽ gây ra vấn đề 48. Các bộ khung thường cung cấp các triển khai tất định của riêng chúng cho các hàm thư viện như vậy, nhưng bạn phải nhớ sử dụng chúng. Trong một số trường hợp, chẳng hạn như với công cụ workflowcheck của Temporal, các bộ khung cung cấp công cụ phân tích tĩnh để xác định xem hành vi không tất định có được đưa vào hay không.
Note
Making code deterministic is a powerful idea, but tricky to do robustly. In “The Power of Determinism” we will return to this topic.
Kiến trúc hướng sự kiện (Event-Driven Architectures)
Trong phần cuối này, chúng ta sẽ xem xét sơ lược về event-driven architectures (kiến trúc hướng sự kiện), là một cách khác mà dữ liệu được mã hóa có thể chảy từ một tiến trình sang tiến trình khác. Một yêu cầu được gọi là event (sự kiện) hay message (tin nhắn); không giống như RPC, người gửi thường không chờ người nhận xử lý sự kiện. Hơn nữa, các sự kiện thường không được gửi tới người nhận qua một kết nối mạng trực tiếp, mà đi qua một trung gian gọi là message broker (cũng được gọi là event broker, message queue, hay message-oriented middleware), lưu trữ tin nhắn tạm thời. 50.
Sử dụng message broker có một số ưu điểm so với RPC trực tiếp:
- Nó có thể đóng vai trò bộ đệm nếu người nhận không khả dụng hoặc bị quá tải, và do đó cải thiện độ tin cậy của hệ thống.
- Nó có thể tự động gửi lại tin nhắn tới một tiến trình bị crash, và do đó ngăn tin nhắn bị mất.
- Nó tránh được nhu cầu về service discovery, vì người gửi không cần kết nối trực tiếp tới địa chỉ IP của người nhận.
- Nó cho phép cùng một tin nhắn được gửi tới nhiều người nhận.
- Nó tách biệt về mặt logic người gửi khỏi người nhận (người gửi chỉ đăng tải tin nhắn và không quan tâm ai tiêu thụ chúng).
Giao tiếp qua message broker là bất đồng bộ (asynchronous): người gửi không chờ tin nhắn được giao đến, mà chỉ gửi nó và sau đó quên đi. Có thể triển khai một mô hình đồng bộ giống RPC bằng cách để người gửi chờ phản hồi trên một kênh riêng biệt.
Message brokers
Trong quá khứ, bức tranh về message broker bị chi phối bởi phần mềm doanh nghiệp thương mại từ các công ty như TIBCO, IBM WebSphere, và webMethods, trước khi các triển khai mã nguồn mở như RabbitMQ, ActiveMQ, HornetQ, NATS, và Apache Kafka trở nên phổ biến. Gần đây hơn, các dịch vụ đám mây như Amazon Kinesis, Azure Service Bus, và Google Cloud Pub/Sub đã được áp dụng rộng rãi. Chúng ta sẽ so sánh chúng chi tiết hơn trong “Messaging Systems”.
Ngữ nghĩa giao tin chi tiết thay đổi theo triển khai và cấu hình, nhưng nói chung, hai mẫu phân phối tin nhắn được sử dụng phổ biến nhất:
- Một tiến trình thêm một tin nhắn vào một queue (hàng đợi) được đặt tên, và broker giao tin nhắn đó tới một consumer (người tiêu thụ) của hàng đợi đó. Nếu có nhiều consumer, một trong số họ nhận được tin nhắn.
- Một tiến trình đăng một tin nhắn lên một topic (chủ đề) được đặt tên, và broker giao tin nhắn đó tới tất cả subscriber (người đăng ký) của topic đó. Nếu có nhiều subscriber, tất cả đều nhận được tin nhắn.
Message broker thường không áp đặt bất kỳ mô hình dữ liệu cụ thể nào, một tin nhắn chỉ là một chuỗi byte với một số siêu dữ liệu, vì vậy bạn có thể sử dụng bất kỳ định dạng mã hóa nào. Một cách tiếp cận phổ biến là sử dụng Protocol Buffers, Avro, hoặc JSON, và triển khai schema registry bên cạnh message broker để lưu trữ tất cả các phiên bản schema hợp lệ và kiểm tra tính tương thích của chúng 19 21. AsyncAPI, một tương đương nhắn tin của OpenAPI, cũng có thể được sử dụng để chỉ định schema của tin nhắn.
Message broker khác nhau về mức độ bền vững của tin nhắn. Nhiều broker ghi tin nhắn vào đĩa, để chúng không bị mất trong trường hợp message broker bị crash hoặc cần được khởi động lại. Không giống như cơ sở dữ liệu, nhiều message broker tự động xóa tin nhắn sau khi chúng đã được tiêu thụ. Một số broker có thể được cấu hình để lưu trữ tin nhắn vô thời hạn, điều mà bạn sẽ cần nếu muốn sử dụng event sourcing (xem “Event Sourcing and CQRS”).
Nếu một consumer đăng lại tin nhắn tới một topic khác, bạn có thể cần cẩn thận để bảo tồn các trường không biết, để ngăn vấn đề được mô tả trước đó trong bối cảnh cơ sở dữ liệu (Hình 5-1).
Distributed actor frameworks
Actor model (mô hình actor) là một mô hình lập trình cho tính đồng thời trong một tiến trình đơn. Thay vì xử lý trực tiếp với các thread (và các vấn đề liên quan của race condition, locking, và deadlock), logic được đóng gói trong các actor. Mỗi actor thường đại diện cho một client hay thực thể, nó có thể có một số trạng thái cục bộ (không được chia sẻ với bất kỳ actor nào khác), và nó giao tiếp với các actor khác bằng cách gửi và nhận các tin nhắn bất đồng bộ. Giao tin không được đảm bảo: trong các tình huống lỗi nhất định, tin nhắn sẽ bị mất. Vì mỗi actor chỉ xử lý một tin nhắn tại một thời điểm, nó không cần lo lắng về thread, và mỗi actor có thể được lên lịch độc lập bởi bộ khung.
Trong distributed actor frameworks (bộ khung actor phân tán) như Akka, Orleans [^51], và Erlang/OTP, mô hình lập trình này được sử dụng để mở rộng ứng dụng qua nhiều node. Cơ chế truyền tin nhắn tương tự được sử dụng, bất kể người gửi và người nhận có trên cùng node hay các node khác nhau. Nếu chúng ở trên các node khác nhau, tin nhắn được mã hóa một cách trong suốt thành một chuỗi byte, gửi qua mạng, và giải mã ở phía bên kia.
Location transparency hoạt động tốt hơn trong actor model so với trong RPC, vì actor model đã giả định rằng tin nhắn có thể bị mất, ngay cả trong một tiến trình đơn. Mặc dù độ trễ qua mạng có thể cao hơn so với trong cùng một tiến trình, nhưng có ít sự không khớp cơ bản hơn giữa giao tiếp cục bộ và từ xa khi sử dụng actor model.
Một distributed actor framework về cơ bản tích hợp message broker và mô hình lập trình actor vào một bộ khung duy nhất. Tuy nhiên, nếu bạn muốn thực hiện rolling upgrade cho ứng dụng dựa trên actor, bạn vẫn phải lo lắng về tương thích xuôi và tương thích ngược, vì tin nhắn có thể được gửi từ một node chạy phiên bản mới tới một node chạy phiên bản cũ, và ngược lại. Điều này có thể đạt được bằng cách sử dụng một trong các cách mã hóa được thảo luận trong chương này.
Tóm tắt
Trong chương này, chúng ta đã xem xét một số cách chuyển đổi cấu trúc dữ liệu thành byte trên mạng hoặc byte trên đĩa. Chúng ta đã thấy cách chi tiết của các cách mã hóa này ảnh hưởng không chỉ đến hiệu quả của chúng, mà quan trọng hơn là đến kiến trúc của ứng dụng và các tùy chọn để phát triển chúng.
Cụ thể, nhiều dịch vụ cần hỗ trợ rolling upgrade, nơi một phiên bản mới của dịch vụ được triển khai dần dần cho một vài node mỗi lần, thay vì triển khai cho tất cả các node đồng thời. Rolling upgrade cho phép các phiên bản mới của dịch vụ được phát hành mà không có thời gian dừng (do đó khuyến khích các lần phát hành nhỏ thường xuyên hơn là các lần phát hành lớn hiếm hoi) và làm cho việc triển khai ít rủi ro hơn (cho phép các phát hành lỗi được phát hiện và quay lại trước khi ảnh hưởng đến số lượng lớn người dùng). Những thuộc tính này cực kỳ có lợi cho evolvability (tính tiến hóa), sự dễ dàng trong việc thực hiện các thay đổi đối với ứng dụng.
Trong quá trình rolling upgrade, hoặc vì nhiều lý do khác, chúng ta phải giả định rằng các node khác nhau đang chạy các phiên bản khác nhau của mã ứng dụng. Do đó, điều quan trọng là tất cả dữ liệu lưu thông trong hệ thống được mã hóa theo cách cung cấp tương thích ngược (mã mới có thể đọc dữ liệu cũ) và tương thích xuôi (mã cũ có thể đọc dữ liệu mới).
Chúng ta đã thảo luận về một số định dạng mã hóa dữ liệu và các thuộc tính tương thích của chúng:
- Các mã hóa đặc thù của ngôn ngữ lập trình bị giới hạn trong một ngôn ngữ lập trình duy nhất và thường không cung cấp tương thích xuôi và tương thích ngược.
- Các định dạng văn bản như JSON, XML, và CSV rất phổ biến, và tính tương thích của chúng phụ thuộc vào cách bạn sử dụng chúng. Chúng có các ngôn ngữ schema tùy chọn, đôi khi hữu ích và đôi khi là trở ngại. Những định dạng này phần nào mơ hồ về kiểu dữ liệu, vì vậy bạn phải cẩn thận với những thứ như số và chuỗi nhị phân.
- Các định dạng nhị phân dựa trên schema như Protocol Buffers và Avro cho phép mã hóa nhỏ gọn, hiệu quả với ngữ nghĩa tương thích xuôi và tương thích ngược được định nghĩa rõ ràng. Các schema có thể hữu ích cho tài liệu và tạo mã trong các ngôn ngữ kiểu tĩnh. Tuy nhiên, những định dạng này có nhược điểm là dữ liệu cần được giải mã trước khi con người có thể đọc được.
Chúng ta cũng đã thảo luận về một số chế độ luồng dữ liệu, minh họa các tình huống khác nhau mà trong đó các mã hóa dữ liệu quan trọng:
- Cơ sở dữ liệu, nơi tiến trình ghi vào cơ sở dữ liệu mã hóa dữ liệu và tiến trình đọc từ cơ sở dữ liệu giải mã nó
- RPC và REST API, nơi client mã hóa một yêu cầu, server giải mã yêu cầu và mã hóa một phản hồi, và client cuối cùng giải mã phản hồi
- Kiến trúc hướng sự kiện (sử dụng message broker hoặc actor), nơi các node giao tiếp bằng cách gửi cho nhau các tin nhắn được mã hóa bởi người gửi và giải mã bởi người nhận
Chúng ta có thể kết luận rằng với một chút cẩn thận, tương thích ngược/xuôi và rolling upgrade là hoàn toàn có thể đạt được. Chúc ứng dụng của bạn phát triển nhanh và việc triển khai của bạn diễn ra thường xuyên.
References
CWE-502: Deserialization of Untrusted Data. Common Weakness Enumeration, cwe.mitre.org, July 2006. Archived at perma.cc/26EU-UK9Y ↩︎
Steve Breen. What Do WebLogic, WebSphere, JBoss, Jenkins, OpenNMS, and Your Application Have in Common? This Vulnerability. foxglovesecurity.com, November 2015. Archived at perma.cc/9U97-UVVD ↩︎
Patrick McKenzie. What the Rails Security Issue Means for Your Startup. kalzumeus.com, January 2013. Archived at perma.cc/2MBJ-7PZ6 ↩︎
Brian Goetz. Towards Better Serialization. openjdk.org, June 2019. Archived at perma.cc/UK6U-GQDE ↩︎
Eishay Smith. jvm-serializers wiki. github.com, October 2023. Archived at perma.cc/PJP7-WCNG ↩︎
XML Is a Poor Copy of S-Expressions. wiki.c2.com, May 2013. Archived at perma.cc/7FAN-YBKL ↩︎
Julia Evans. Examples of floating point problems. jvns.ca, January 2023. Archived at perma.cc/M57L-QKKW ↩︎
Matt Harris. Snowflake: An Update and Some Very Important Information. Email to Twitter Development Talk mailing list, October 2010. Archived at perma.cc/8UBV-MZ3D ↩︎
Yakov Shafranovich. RFC 4180: Common Format and MIME Type for Comma-Separated Values (CSV) Files. IETF, October 2005. ↩︎
Andy Coates. Evolving JSON Schemas - Part I and Part II. creekservice.org, January 2024. Archived at perma.cc/MZW3-UA54 and perma.cc/GT5H-WKZ5 ↩︎
Pierre Genevès, Nabil Layaïda, and Vincent Quint. Ensuring Query Compatibility with Evolving XML Schemas. INRIA Technical Report 6711, November 2008. ↩︎
Tim Bray. Bits On the Wire. tbray.org, November 2019. Archived at perma.cc/3BT3-BQU3 ↩︎
Mark Slee, Aditya Agarwal, and Marc Kwiatkowski. Thrift: Scalable Cross-Language Services Implementation. Facebook technical report, April 2007. Archived at perma.cc/22BS-TUFB ↩︎
Martin Kleppmann. Schema Evolution in Avro, Protocol Buffers and Thrift. martin.kleppmann.com, December 2012. Archived at perma.cc/E4R2-9RJT ↩︎
Doug Cutting, Chad Walters, Jim Kellerman, et al. [PROPOSAL] New Subproject: Avro. Email thread on hadoop-general mailing list, lists.apache.org, April 2009. Archived at perma.cc/4A79-BMEB ↩︎
Apache Software Foundation. Apache Avro 1.12.0 Specification. avro.apache.org, August 2024. Archived at perma.cc/C36P-5EBQ ↩︎
Apache Software Foundation. Avro schemas as LL(1) CFG definitions. avro.apache.org, August 2024. Archived at perma.cc/JB44-EM9Q ↩︎
Tony Hoare. Null References: The Billion Dollar Mistake. Talk at QCon London, March 2009. ↩︎
Confluent, Inc. Schema Registry Overview. docs.confluent.io, 2024. Archived at perma.cc/92C3-A9JA ↩︎ ↩︎
Aditya Auradkar and Tom Quiggle. Introducing Espresso—LinkedIn’s Hot New Distributed Document Store. engineering.linkedin.com, January 2015. Archived at perma.cc/FX4P-VW9T ↩︎
Jay Kreps. Putting Apache Kafka to Use: A Practical Guide to Building a Stream Data Platform (Part 2). confluent.io, February 2015. Archived at perma.cc/8UA4-ZS5S ↩︎ ↩︎
Gwen Shapira. The Problem of Managing Schemas. oreilly.com, November 2014. Archived at perma.cc/BY8Q-RYV3 ↩︎
John Larmouth. ASN.1 Complete. Morgan Kaufmann, 1999. ISBN: 978-0-122-33435-1. Archived at perma.cc/GB7Y-XSXQ ↩︎
Burton S. Kaliski Jr. A Layman’s Guide to a Subset of ASN.1, BER, and DER. Technical Note, RSA Data Security, Inc., November 1993. Archived at perma.cc/2LMN-W9U8 ↩︎
Jacob Hoffman-Andrews. A Warm Welcome to ASN.1 and DER. letsencrypt.org, April 2020. Archived at perma.cc/CYT2-GPQ8 ↩︎
Lev Walkin. Question: Extensibility and Dropping Fields. lionet.info, September 2010. Archived at perma.cc/VX8E-NLH3 ↩︎
Jacqueline Xu. Online migrations at scale. stripe.com, February 2017. Archived at perma.cc/X59W-DK7Y ↩︎
Geoffrey Litt, Peter van Hardenberg, and Orion Henry. Project Cambria: Translate your data with lenses. Technical Report, Ink & Switch, October 2020. Archived at perma.cc/WA4V-VKDB ↩︎
Pat Helland. Data on the Outside Versus Data on the Inside. At 2nd Biennial Conference on Innovative Data Systems Research (CIDR), January 2005. ↩︎
Roy Thomas Fielding. Architectural Styles and the Design of Network-Based Software Architectures. PhD Thesis, University of California, Irvine, 2000. Archived at perma.cc/LWY9-7BPE ↩︎
Roy Thomas Fielding. REST APIs must be hypertext-driven." roy.gbiv.com, October 2008. Archived at perma.cc/M2ZW-8ATG ↩︎
OpenAPI Specification Version 3.1.0. swagger.io, February 2021. Archived at perma.cc/3S6S-K5M4 ↩︎
Michi Henning. The Rise and Fall of CORBA. Communications of the ACM, volume 51, issue 8, pages 52–57, August 2008. doi:10.1145/1378704.1378718 ↩︎
Pete Lacey. The S Stands for Simple. harmful.cat-v.org, November 2006. Archived at perma.cc/4PMK-Z9X7 ↩︎
Stefan Tilkov. Interview: Pete Lacey Criticizes Web Services. infoq.com, December 2006. Archived at perma.cc/JWF4-XY3P ↩︎
Tim Bray. The Loyal WS-Opposition. tbray.org, September 2004. Archived at perma.cc/J5Q8-69Q2 ↩︎
Andrew D. Birrell and Bruce Jay Nelson. Implementing Remote Procedure Calls. ACM Transactions on Computer Systems (TOCS), volume 2, issue 1, pages 39–59, February 1984. doi:10.1145/2080.357392 ↩︎
Jim Waldo, Geoff Wyant, Ann Wollrath, and Sam Kendall. A Note on Distributed Computing. Sun Microsystems Laboratories, Inc., Technical Report TR-94-29, November 1994. Archived at perma.cc/8LRZ-BSZR ↩︎
Steve Vinoski. Convenience over Correctness. IEEE Internet Computing, volume 12, issue 4, pages 89–92, July 2008. doi:10.1109/MIC.2008.75 ↩︎
Brandur Leach. Designing robust and predictable APIs with idempotency. stripe.com, February 2017. Archived at perma.cc/JD22-XZQT ↩︎
Sam Rose. Load Balancing. samwho.dev, April 2023. Archived at perma.cc/Q7BA-9AE2 ↩︎
Troy Hunt. Your API versioning is wrong, which is why I decided to do it 3 different wrong ways. troyhunt.com, February 2014. Archived at perma.cc/9DSW-DGR5 ↩︎
Brandur Leach. APIs as infrastructure: future-proofing Stripe with versioning. stripe.com, August 2017. Archived at perma.cc/L63K-USFW ↩︎
Alexandre Alves, Assaf Arkin, Sid Askary, et al. Web Services Business Process Execution Language Version 2.0. docs.oasis-open.org, April 2007. ↩︎
What is a Temporal Service? docs.temporal.io, 2024. Archived at perma.cc/32P3-CJ9V ↩︎
Stephan Ewen. Why we built Restate. restate.dev, August 2023. Archived at perma.cc/BJJ2-X75K ↩︎
Keith Tenzer and Joshua Smith. Idempotency and Durable Execution. temporal.io, February 2024. Archived at perma.cc/9LGW-PCLU ↩︎
What is a Temporal Workflow? docs.temporal.io, 2024. Archived at perma.cc/B5C5-Y396 ↩︎ ↩︎
Jack Kleeman. Solving durable execution’s immutability problem. restate.dev, February 2024. Archived at perma.cc/G55L-EYH5 ↩︎
Srinath Perera. Exploring Event-Driven Architecture: A Beginner’s Guide for Cloud Native Developers. wso2.com, August 2023. Archived at archive.org ↩︎