4. Lưu Trữ và Truy Xuất
Một trong những nỗi khổ của cuộc đời là mọi người đặt tên cho mọi thứ hơi sai một chút. Và vì vậy mà mọi thứ trở nên khó hiểu hơn so với khi chúng được đặt tên khác đi. Máy tính không chủ yếu thực hiện tính toán theo nghĩa làm số học. […] Chúng chủ yếu là các hệ thống lưu trữ hồ sơ.
Richard Feynman, hội thảo Idiosyncratic Thinking (1985)
Ở mức căn bản nhất, một cơ sở dữ liệu cần làm được hai việc: khi bạn đưa dữ liệu vào, nó phải lưu trữ dữ liệu đó; và khi bạn hỏi lại sau này, nó phải trả dữ liệu đó về cho bạn.
Trong Chương 3 chúng ta đã thảo luận về các mô hình dữ liệu và ngôn ngữ truy vấn, tức là định dạng bạn dùng để đưa dữ liệu vào cơ sở dữ liệu và giao diện để bạn có thể lấy lại dữ liệu sau này. Trong chương này chúng ta xem xét vấn đề tương tự từ góc độ của cơ sở dữ liệu: cơ sở dữ liệu có thể lưu trữ dữ liệu bạn cung cấp như thế nào, và làm sao tìm lại được dữ liệu đó khi bạn cần.
Tại sao bạn, với tư cách là một nhà phát triển ứng dụng, lại cần quan tâm đến cách cơ sở dữ liệu xử lý việc lưu trữ và truy xuất bên trong? Bạn có thể sẽ không tự xây dựng storage engine (cỗ máy lưu trữ) của riêng mình từ đầu, nhưng bạn cần lựa chọn một storage engine phù hợp cho ứng dụng của mình trong số nhiều lựa chọn có sẵn. Để cấu hình một storage engine hoạt động tốt với kiểu workload (khối lượng công việc) của bạn, bạn cần có hiểu biết sơ lược về những gì storage engine đang làm bên dưới.
Cụ thể, có sự khác biệt lớn giữa các storage engine được tối ưu cho các workload giao dịch (OLTP) và những engine được tối ưu cho phân tích (chúng ta đã giới thiệu sự phân biệt này trong “Hệ thống Phân tích so với Hệ thống Vận hành”). Chương này bắt đầu bằng việc xem xét hai họ storage engine cho OLTP: storage engine log-structured (có cấu trúc nhật ký) ghi ra các file dữ liệu bất biến, và các storage engine như B-tree cập nhật dữ liệu tại chỗ. Các cấu trúc này được dùng cho cả lưu trữ key-value lẫn secondary index (chỉ mục phụ).
Ở phần sau trong “Lưu Trữ Dữ Liệu cho Phân tích” chúng ta sẽ thảo luận về một họ storage engine được tối ưu cho phân tích, và trong “Chỉ mục Đa chiều và Toàn văn” chúng ta sẽ sơ lược về các index cho các truy vấn nâng cao hơn, chẳng hạn như truy xuất văn bản.
Lưu Trữ và Đánh Chỉ mục cho OLTP
Hãy xét cơ sở dữ liệu đơn giản nhất thế giới, được cài đặt bằng hai hàm Bash:
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}Hai hàm này cài đặt một kho lưu trữ key-value. Bạn có thể gọi db_set key value, để lưu key và value vào cơ sở dữ liệu. Key và value có thể là (hầu như) bất cứ thứ gì bạn muốn, ví dụ value có thể là một tài liệu JSON. Sau đó bạn có thể gọi db_get key, để tra cứu giá trị gần nhất được liên kết với key đó và trả về nó.
Và nó hoạt động được:
$ db_set 12 '{"name":"London","attractions":["Big Ben","London Eye"]}'
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}Định dạng lưu trữ rất đơn giản: một file văn bản trong đó mỗi dòng chứa một cặp key-value, được phân tách bằng dấu phẩy (tương tự file CSV, bỏ qua vấn đề escape). Mỗi lần gọi db_set sẽ thêm vào cuối file. Nếu bạn cập nhật một key nhiều lần, các phiên bản cũ của value sẽ không bị ghi đè mà bạn cần tìm lần xuất hiện cuối cùng của key trong file để tìm giá trị mới nhất (do đó có tail -n 1 trong db_get):
$ db_set 42 '{"name":"San Francisco","attractions":["Exploratorium"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Exploratorium"]}
$ cat database
12,{"name":"London","attractions":["Big Ben","London Eye"]}
42,{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
42,{"name":"San Francisco","attractions":["Exploratorium"]}Hàm db_set thực ra có hiệu năng khá tốt cho thứ gì đó đơn giản như vậy, bởi vì việc thêm vào cuối file thường rất hiệu quả. Tương tự với những gì db_set làm, nhiều cơ sở dữ liệu sử dụng nội bộ một log (nhật ký), là một file dữ liệu chỉ được ghi thêm (append-only). Các cơ sở dữ liệu thực phải xử lý nhiều vấn đề hơn (chẳng hạn xử lý ghi đồng thời, thu hồi dung lượng đĩa để log không tăng trưởng mãi mãi, và xử lý các bản ghi được ghi dở khi phục hồi sau sự cố), nhưng nguyên tắc cơ bản là như nhau. Log vô cùng hữu ích, và chúng ta sẽ gặp lại chúng nhiều lần trong cuốn sách này.
Note
Từ log thường được dùng để chỉ nhật ký ứng dụng, nơi ứng dụng xuất ra văn bản mô tả những gì đang xảy ra. Trong cuốn sách này, log được dùng theo nghĩa tổng quát hơn: một chuỗi bản ghi chỉ ghi thêm (append-only) trên đĩa. Nó không cần phải đọc được bởi người; nó có thể ở dạng nhị phân và chỉ dành cho mục đích nội bộ của hệ thống cơ sở dữ liệu.
Mặt khác, hàm db_get có hiệu năng rất tệ nếu bạn có nhiều bản ghi trong cơ sở dữ liệu. Mỗi lần bạn muốn tra cứu một key, db_get phải quét toàn bộ file cơ sở dữ liệu từ đầu đến cuối để tìm các lần xuất hiện của key đó. Theo thuật ngữ giải thuật, chi phí của một lần tra cứu là O(n): nếu bạn nhân đôi số bản ghi n trong cơ sở dữ liệu, một lần tra cứu mất gấp đôi thời gian. Điều đó không tốt.
Để tìm kiếm giá trị cho một key cụ thể trong cơ sở dữ liệu một cách hiệu quả, chúng ta cần một cấu trúc dữ liệu khác: một index (chỉ mục). Trong chương này chúng ta sẽ xem xét một loạt các cấu trúc đánh chỉ mục và so sánh chúng; ý tưởng chung là tổ chức dữ liệu theo một cách nhất định (ví dụ, sắp xếp theo một key nào đó) để việc định vị dữ liệu bạn muốn trở nên nhanh hơn. Nếu bạn muốn tìm kiếm cùng một dữ liệu theo nhiều cách khác nhau, bạn có thể cần nhiều index khác nhau trên các phần khác nhau của dữ liệu.
Index là một cấu trúc bổ sung được dẫn xuất từ dữ liệu chính. Nhiều cơ sở dữ liệu cho phép bạn thêm và xóa index mà không ảnh hưởng đến nội dung của cơ sở dữ liệu; nó chỉ ảnh hưởng đến hiệu năng của các truy vấn. Duy trì các cấu trúc bổ sung tạo ra chi phí overhead, đặc biệt là khi ghi. Đối với ghi, khó có gì đánh bại được hiệu năng của việc đơn giản ghi thêm vào file, vì đó là thao tác ghi đơn giản nhất có thể. Bất kỳ loại index nào cũng thường làm chậm tốc độ ghi, bởi vì index cũng cần được cập nhật mỗi khi dữ liệu được ghi.
Đây là một sự đánh đổi quan trọng trong các hệ thống lưu trữ: index được chọn tốt sẽ tăng tốc các truy vấn đọc, nhưng mỗi index tiêu tốn thêm dung lượng đĩa và làm chậm tốc độ ghi, đôi khi đáng kể 1. Vì lý do này, các cơ sở dữ liệu thường không tự động đánh chỉ mục mọi thứ theo mặc định, mà yêu cầu bạn, người viết ứng dụng hoặc quản trị cơ sở dữ liệu, tự chọn index thủ công dựa trên hiểu biết của bạn về các mẫu truy vấn điển hình của ứng dụng. Sau đó bạn có thể chọn các index mang lại lợi ích lớn nhất cho ứng dụng của mình mà không tạo ra nhiều overhead ghi hơn mức cần thiết.
Lưu Trữ Log-Structured
Để bắt đầu, hãy giả sử bạn muốn tiếp tục lưu trữ dữ liệu trong file chỉ ghi thêm được tạo bởi db_set, và bạn chỉ muốn tăng tốc đọc. Một cách bạn có thể làm điều này là giữ một hash map (bản đồ băm) trong bộ nhớ, trong đó mỗi key được ánh xạ đến byte offset trong file tại vị trí có thể tìm thấy giá trị gần nhất cho key đó, như minh họa trong Hình 4-1.
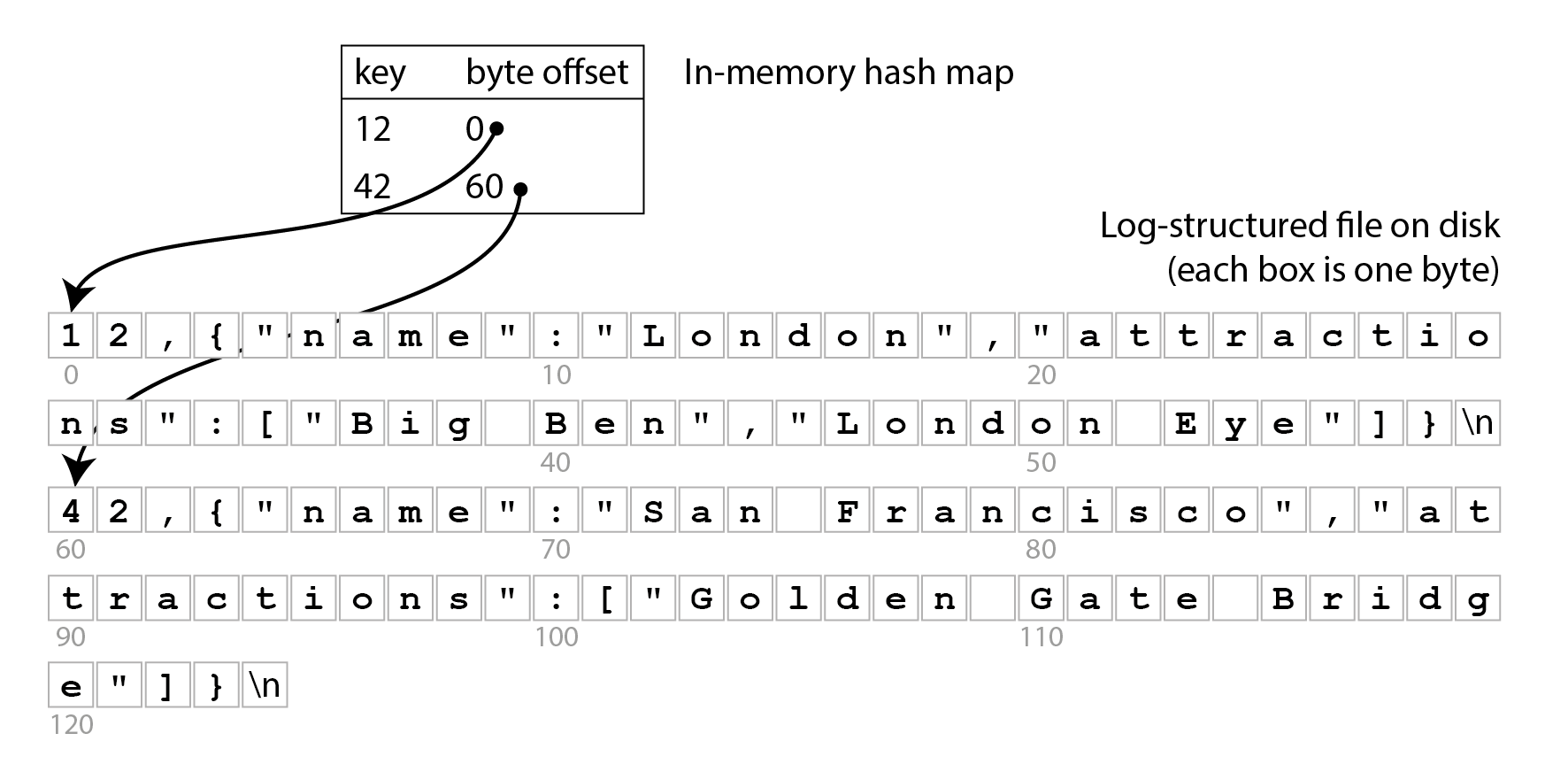
Mỗi khi bạn thêm một cặp key-value mới vào file, bạn cũng cập nhật hash map để phản ánh offset của dữ liệu bạn vừa ghi. Khi bạn muốn tra cứu một giá trị, bạn dùng hash map để tìm offset trong file log, tìm đến vị trí đó, và đọc giá trị. Nếu phần dữ liệu đó đã có trong cache của filesystem, một lần đọc sẽ không cần bất kỳ thao tác I/O nào lên đĩa.
Cách tiếp cận này nhanh hơn nhiều, nhưng vẫn gặp một số vấn đề:
- Bạn không bao giờ giải phóng dung lượng đĩa bị chiếm bởi các mục log cũ đã bị ghi đè; nếu bạn tiếp tục ghi vào cơ sở dữ liệu, bạn có thể hết dung lượng đĩa.
- Hash map không được lưu bền vững, vì vậy bạn phải xây dựng lại nó khi khởi động lại cơ sở dữ liệu, ví dụ bằng cách quét toàn bộ file log để tìm byte offset mới nhất cho mỗi key. Điều này làm chậm quá trình khởi động lại nếu bạn có nhiều dữ liệu.
- Hash table phải vừa trong bộ nhớ. Về nguyên tắc, bạn có thể duy trì một hash table trên đĩa, nhưng tiếc là rất khó để một hash map trên đĩa hoạt động tốt. Nó đòi hỏi nhiều thao tác I/O ngẫu nhiên, tốn kém khi phình to ra và va chạm hash (hash collision) đòi hỏi logic phức tạp 2.
- Truy vấn phạm vi (range query) không hiệu quả. Ví dụ, bạn không thể dễ dàng quét qua tất cả các key từ
10000đến19999, bạn sẽ phải tra cứu từng key riêng lẻ trong hash map.
Định dạng file SSTable
Trên thực tế, hash table không được dùng nhiều cho các index cơ sở dữ liệu, thay vào đó phổ biến hơn là lưu dữ liệu trong một cấu trúc được sắp xếp theo key 3. Một ví dụ về cấu trúc như vậy là Sorted String Table, hay SSTable (bảng chuỗi đã sắp xếp) cho ngắn gọn, như thể hiện trong Hình 4-2. Định dạng file này cũng lưu các cặp key-value, nhưng đảm bảo chúng được sắp xếp theo key, và mỗi key chỉ xuất hiện một lần trong file.
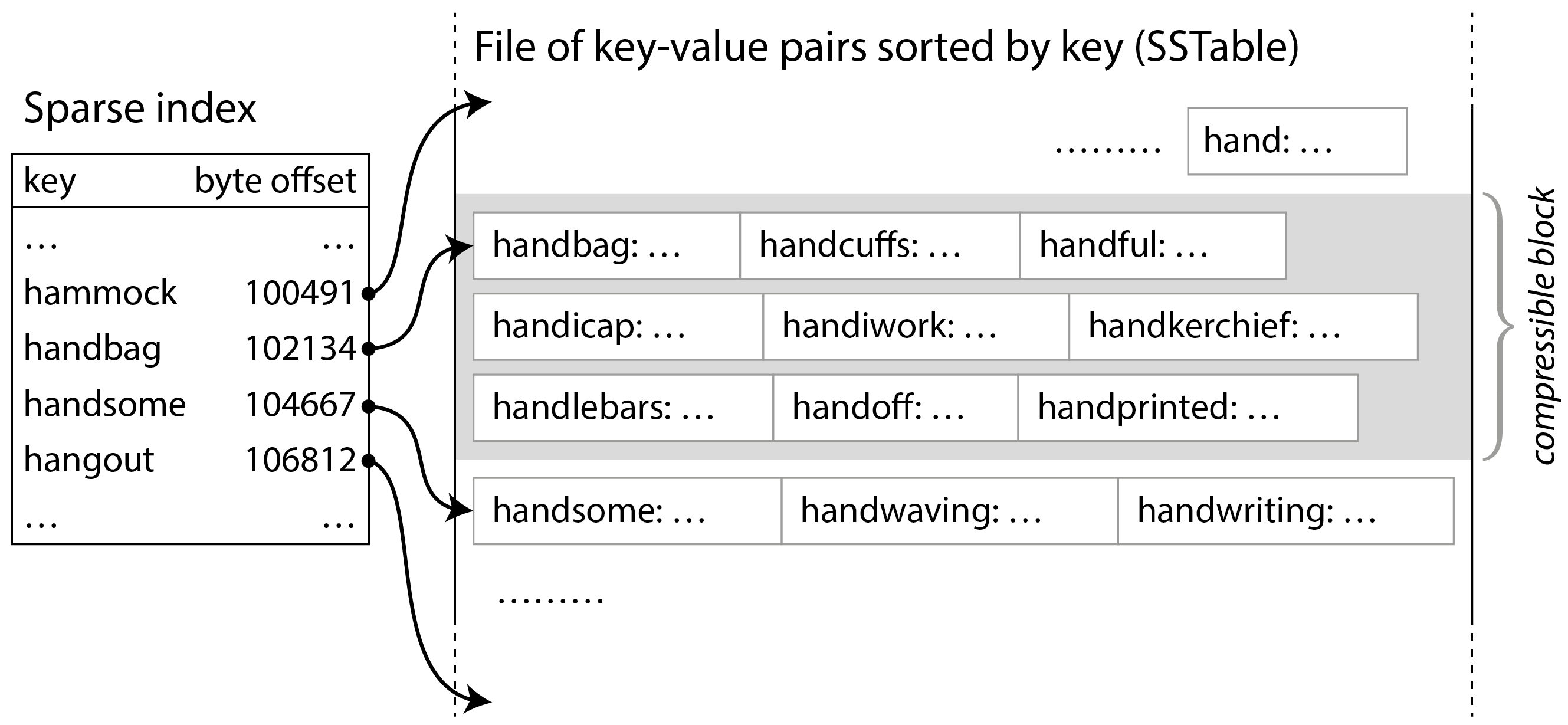
Giờ bạn không cần giữ tất cả các key trong bộ nhớ: bạn có thể nhóm các cặp key-value trong một SSTable thành các block (khối) vài kilobyte, rồi lưu key đầu tiên của mỗi block vào index. Loại index này, chỉ lưu một số key, được gọi là sparse (thưa). Index này được lưu trong một phần riêng biệt của SSTable, ví dụ sử dụng một B-tree bất biến, trie, hoặc cấu trúc dữ liệu khác cho phép truy vấn nhanh chóng tra cứu một key cụ thể 4.
Ví dụ, trong Hình 4-2, key đầu tiên của một block là handbag, và key đầu tiên của block tiếp theo là handsome. Bây giờ giả sử bạn đang tìm key handiwork, key này không xuất hiện trong sparse index. Do sắp xếp, bạn biết rằng handiwork phải nằm giữa handbag và handsome. Nghĩa là bạn có thể tìm đến offset của handbag và quét file từ đó cho đến khi tìm thấy handiwork (hoặc không, nếu key không có trong file). Một block vài kilobyte có thể được quét rất nhanh.
Hơn nữa, mỗi block bản ghi có thể được nén (chỉ ra bởi vùng tô bóng trong Hình 4-2). Ngoài việc tiết kiệm dung lượng đĩa, nén cũng giảm mức sử dụng băng thông I/O, đổi lại bằng việc dùng thêm một chút thời gian CPU.
Xây dựng và hợp nhất SSTable
Định dạng file SSTable tốt hơn cho việc đọc so với log chỉ ghi thêm, nhưng nó làm cho việc ghi trở nên khó khăn hơn. Chúng ta không thể đơn giản ghi thêm vào cuối, vì khi đó file sẽ không còn được sắp xếp (trừ khi các key tình cờ được ghi theo thứ tự tăng dần). Nếu chúng ta phải viết lại toàn bộ SSTable mỗi khi một key được chèn vào đâu đó ở giữa, thì việc ghi sẽ trở nên quá tốn kém.
Chúng ta có thể giải quyết vấn đề này bằng cách tiếp cận log-structured, là sự kết hợp giữa log chỉ ghi thêm và file đã sắp xếp:
- Khi có một lần ghi đến, thêm nó vào một cấu trúc dữ liệu dạng map có thứ tự trong bộ nhớ, chẳng hạn red-black tree, skip list 5, hoặc trie 6. Với các cấu trúc dữ liệu này, bạn có thể chèn key theo bất kỳ thứ tự nào, tra cứu chúng hiệu quả, và đọc lại theo thứ tự đã sắp xếp. Cấu trúc dữ liệu trong bộ nhớ này được gọi là memtable.
- Khi memtable lớn hơn một ngưỡng nhất định (thường là vài megabyte), ghi nó ra đĩa theo thứ tự đã sắp xếp dưới dạng file SSTable. Chúng ta gọi file SSTable mới này là segment (phân đoạn) gần nhất của cơ sở dữ liệu, và nó được lưu dưới dạng file riêng biệt cùng với các segment cũ hơn. Mỗi segment có một index riêng về nội dung của nó. Trong khi segment mới đang được ghi ra đĩa, cơ sở dữ liệu có thể tiếp tục ghi vào một instance memtable mới, và bộ nhớ của memtable cũ được giải phóng khi việc ghi SSTable hoàn tất.
- Để đọc giá trị cho một key nào đó, trước tiên hãy thử tìm key trong memtable và segment trên đĩa gần nhất. Nếu không có, hãy tìm trong segment cũ hơn tiếp theo, v.v. cho đến khi bạn tìm thấy key hoặc đến segment cũ nhất. Nếu key không xuất hiện trong bất kỳ segment nào, nó không tồn tại trong cơ sở dữ liệu.
- Theo định kỳ, chạy một quá trình hợp nhất và compaction (nén gọn) ở nền để kết hợp các file segment và loại bỏ các giá trị đã bị ghi đè hoặc xóa.
Hợp nhất các segment hoạt động tương tự như thuật toán mergesort 5. Quá trình được minh họa trong Hình 4-3: bắt đầu đọc các file đầu vào song song, nhìn vào key đầu tiên trong mỗi file, sao chép key nhỏ nhất (theo thứ tự sắp xếp) vào file đầu ra, và lặp lại. Nếu cùng một key xuất hiện trong nhiều hơn một file đầu vào, chỉ giữ lại giá trị gần nhất hơn. Quá trình này tạo ra một file segment hợp nhất mới, cũng được sắp xếp theo key, với một giá trị cho mỗi key, và sử dụng bộ nhớ tối thiểu vì chúng ta có thể duyệt qua các SSTable từng key một.

Để đảm bảo rằng dữ liệu trong memtable không bị mất nếu cơ sở dữ liệu gặp sự cố, storage engine lưu một log riêng biệt trên đĩa mà mỗi lần ghi được thêm vào ngay lập tức. Log này không được sắp xếp theo key, nhưng điều đó không quan trọng, vì mục đích duy nhất của nó là khôi phục memtable sau một sự cố. Mỗi khi memtable đã được ghi ra SSTable, phần tương ứng của log có thể bị loại bỏ.
Nếu bạn muốn xóa một key và giá trị liên quan của nó, bạn phải thêm một bản ghi xóa đặc biệt gọi là tombstone (bia mộ) vào file dữ liệu. Khi các segment log được hợp nhất, tombstone báo cho quá trình hợp nhất loại bỏ mọi giá trị trước đó của key đã xóa. Sau khi tombstone được hợp nhất vào segment cũ nhất, nó có thể bị loại bỏ.
Thuật toán được mô tả ở đây về cơ bản là những gì được sử dụng trong RocksDB 7, Cassandra, Scylla, và HBase 8, tất cả đều được lấy cảm hứng từ bài báo Bigtable của Google 9 (đã giới thiệu các thuật ngữ SSTable và memtable).
Thuật toán ban đầu được công bố năm 1996 dưới tên Log-Structured Merge-Tree hay LSM-Tree 10, xây dựng dựa trên các công trình trước đó về log-structured filesystem 11. Vì lý do này, các storage engine dựa trên nguyên tắc hợp nhất và compacting các file đã sắp xếp thường được gọi là LSM storage engine.
Trong các LSM storage engine, một file segment được ghi trong một lần (hoặc bằng cách ghi memtable ra hoặc bằng cách hợp nhất một số segment hiện có), và sau đó nó là bất biến. Việc hợp nhất và compaction các segment có thể được thực hiện trong một luồng nền, và trong khi nó đang diễn ra, chúng ta vẫn có thể tiếp tục phục vụ các lần đọc bằng cách sử dụng các file segment cũ. Khi quá trình hợp nhất hoàn tất, chúng ta chuyển các yêu cầu đọc sang sử dụng segment hợp nhất mới thay vì các segment cũ, và sau đó các file segment cũ có thể được xóa.
Các file segment không nhất thiết phải được lưu trên đĩa cục bộ: chúng cũng phù hợp để ghi vào object storage. SlateDB và Delta Lake 12 áp dụng cách tiếp cận này chẳng hạn.
Việc có các file segment bất biến cũng đơn giản hóa việc phục hồi sau sự cố: nếu sự cố xảy ra trong khi đang ghi memtable hoặc trong khi hợp nhất các segment, cơ sở dữ liệu có thể chỉ cần xóa SSTable chưa hoàn thành và bắt đầu lại. Log lưu bền vững các lần ghi vào memtable có thể chứa các bản ghi không đầy đủ nếu có sự cố xảy ra khi đang ghi dở một bản ghi, hoặc nếu đĩa bị đầy; điều này thường được phát hiện bằng cách bao gồm checksum trong log và loại bỏ các mục log bị hỏng hoặc không đầy đủ. Chúng ta sẽ nói thêm về độ bền và phục hồi sau sự cố trong Chương 8.
Bloom filter
Với LSM storage, việc đọc một key được cập nhật lần cuối từ lâu, hoặc không tồn tại, có thể chậm, vì storage engine cần kiểm tra nhiều file segment. Để tăng tốc các lần đọc như vậy, các LSM storage engine thường bao gồm một Bloom filter 13 trong mỗi segment, cung cấp một cách nhanh chóng nhưng xấp xỉ để kiểm tra xem một key cụ thể có xuất hiện trong một SSTable cụ thể hay không.
Hình 4-4 cho thấy một ví dụ về Bloom filter chứa hai key và 16 bit (trong thực tế, nó sẽ chứa nhiều key hơn và nhiều bit hơn). Đối với mỗi key trong SSTable, chúng ta tính một hàm băm, tạo ra một tập hợp các số sau đó được hiểu là các chỉ số vào mảng bit 14.
Chúng ta đặt các bit tương ứng với các chỉ số đó thành 1 và để phần còn lại là 0. Ví dụ, key handbag băm thành các số (2, 9, 4), vì vậy chúng ta đặt bit thứ 2, thứ 9 và thứ 4 thành 1. Bitmap sau đó được lưu như một phần của SSTable, cùng với sparse index của các key. Điều này tốn thêm một chút dung lượng, nhưng Bloom filter thường nhỏ so với phần còn lại của SSTable.
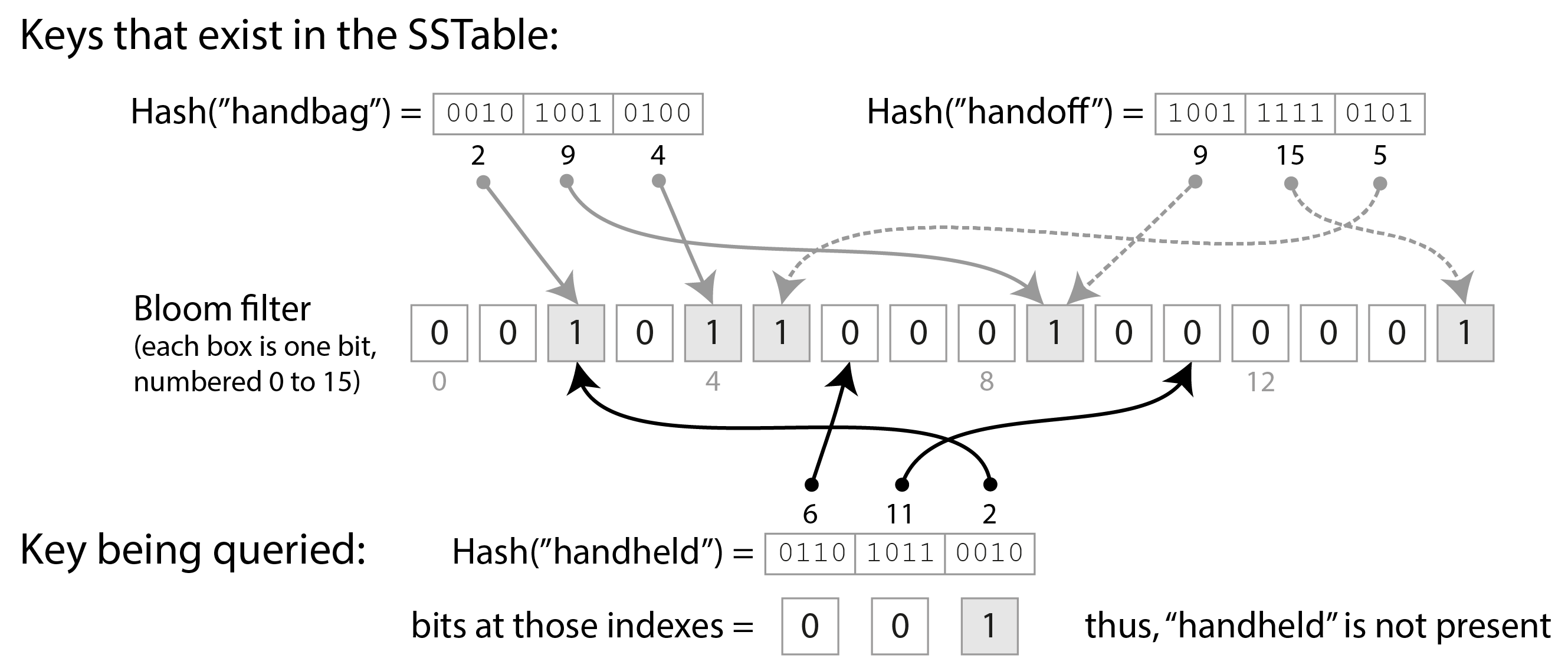
Khi chúng ta muốn biết liệu một key có xuất hiện trong SSTable hay không, chúng ta tính cùng một hàm băm của key đó như trước, và kiểm tra các bit tại các chỉ số đó. Ví dụ, trong Hình 4-4, chúng ta đang truy vấn key handheld, băm thành (6, 11, 2). Một trong các bit đó là 1 (cụ thể là bit số 2), trong khi hai bit kia là 0. Các kiểm tra này có thể được thực hiện cực kỳ nhanh bằng cách sử dụng các phép toán bitwise mà mọi CPU đều hỗ trợ.
Nếu ít nhất một trong các bit là 0, chúng ta biết chắc rằng key không xuất hiện trong SSTable. Nếu tất cả các bit trong truy vấn đều là 1, có khả năng key có trong SSTable, nhưng cũng có thể là tình cờ tất cả các bit đó đã được đặt thành 1 bởi các key khác. Trường hợp này khi có vẻ như một key hiện diện, dù thực ra không phải vậy, được gọi là false positive (dương tính giả).
Xác suất của false positive phụ thuộc vào số lượng key, số bit được đặt cho mỗi key, và tổng số bit trong Bloom filter. Bạn có thể dùng công cụ tính toán trực tuyến để tính ra các thông số phù hợp cho ứng dụng của mình 15. Theo kinh nghiệm, bạn cần phân bổ 10 bit dung lượng Bloom filter cho mỗi key trong SSTable để đạt xác suất false positive là 1%, và xác suất giảm đi mười lần cho mỗi 5 bit bổ sung bạn phân bổ cho mỗi key.
Trong bối cảnh LSM storage engine, false positive không phải là vấn đề:
- Nếu Bloom filter cho biết một key không có mặt, chúng ta có thể bỏ qua SSTable đó một cách an toàn, vì chúng ta có thể chắc chắn rằng nó không chứa key.
- Nếu Bloom filter cho biết key có mặt, chúng ta phải tham khảo sparse index và giải mã block các cặp key-value để kiểm tra xem key có thực sự ở đó hay không. Nếu đó là false positive, chúng ta đã làm thêm một chút công việc không cần thiết, nhưng về cơ bản không có hại gì, chúng ta chỉ tiếp tục tìm kiếm với segment cũ hơn tiếp theo.
Chiến lược compaction
Một chi tiết quan trọng là cách LSM storage chọn thời điểm thực hiện compaction và SSTable nào được đưa vào compaction. Nhiều hệ thống lưu trữ dựa trên LSM cho phép bạn cấu hình chiến lược compaction nào sẽ sử dụng, và một số lựa chọn phổ biến là 16 17:
- Size-tiered compaction (compaction theo bậc kích thước)
- Các SSTable mới hơn và nhỏ hơn được hợp nhất liên tiếp vào các SSTable cũ hơn và lớn hơn. Các SSTable chứa dữ liệu cũ hơn có thể trở nên rất lớn, và việc hợp nhất chúng đòi hỏi nhiều dung lượng đĩa tạm thời. Ưu điểm của chiến lược này là nó có thể xử lý thông lượng ghi rất cao.
- Leveled compaction (compaction theo bậc)
- Phạm vi key được chia thành các SSTable nhỏ hơn và dữ liệu cũ hơn được chuyển vào các “cấp độ” riêng biệt, cho phép compaction tiến hành dần dần hơn và sử dụng ít dung lượng đĩa hơn so với chiến lược size-tiered. Chiến lược này hiệu quả hơn cho việc đọc so với size-tiered compaction vì storage engine cần đọc ít SSTable hơn để kiểm tra xem chúng có chứa key không.
Theo kinh nghiệm, size-tiered compaction hoạt động tốt hơn nếu bạn chủ yếu ghi và ít đọc, trong khi leveled compaction hoạt động tốt hơn nếu workload của bạn chủ yếu là đọc. Nếu bạn ghi một số lượng nhỏ key thường xuyên và một số lượng lớn key hiếm khi, leveled compaction cũng có thể có lợi 18.
Dù có nhiều sắc thái, ý tưởng cơ bản của LSM-tree, giữ một dòng chảy các SSTable được hợp nhất ở nền, là đơn giản và hiệu quả. Chúng ta thảo luận chi tiết hơn về đặc điểm hiệu năng của chúng trong “So sánh B-Tree và LSM-Tree”.
EMBEDDED STORAGE ENGINE
Nhiều cơ sở dữ liệu chạy như một dịch vụ chấp nhận các truy vấn qua mạng, nhưng cũng có các cơ sở dữ liệu embedded (nhúng) không phơi bày API mạng. Thay vào đó, chúng là các thư viện chạy trong cùng tiến trình với code ứng dụng của bạn, thường đọc và ghi file trên đĩa cục bộ, và bạn tương tác với chúng thông qua các lời gọi hàm thông thường. Ví dụ về embedded storage engine bao gồm RocksDB, SQLite, LMDB, DuckDB, và KùzuDB 19.
Cơ sở dữ liệu embedded được dùng rất phổ biến trong các ứng dụng di động để lưu trữ dữ liệu cục bộ của người dùng. Ở backend, chúng có thể là lựa chọn phù hợp nếu dữ liệu đủ nhỏ để vừa trên một máy duy nhất, và nếu không có nhiều giao dịch đồng thời. Ví dụ, trong một hệ thống đa thuê bao (multitenant) trong đó mỗi thuê bao đủ nhỏ và hoàn toàn tách biệt với những người khác (tức là bạn không cần chạy các truy vấn kết hợp dữ liệu từ nhiều thuê bao), bạn có thể dùng một instance cơ sở dữ liệu embedded riêng biệt cho mỗi thuê bao 20.
Các phương pháp lưu trữ và truy xuất chúng ta thảo luận trong chương này được sử dụng trong cả cơ sở dữ liệu embedded lẫn client-server. Trong Chương 6 và Chương 7 chúng ta sẽ thảo luận các kỹ thuật để mở rộng cơ sở dữ liệu trên nhiều máy.
B-Tree
Cách tiếp cận log-structured rất phổ biến, nhưng không phải là hình thức duy nhất của lưu trữ key-value. Cấu trúc được sử dụng rộng rãi nhất để đọc và ghi các bản ghi cơ sở dữ liệu theo key là B-tree.
Được giới thiệu vào năm 1970 21 và được gọi là “phổ biến ở khắp nơi” chưa đầy 10 năm sau 22, B-tree đã vượt qua được thử thách của thời gian rất tốt. Chúng vẫn là cài đặt index tiêu chuẩn trong hầu hết các cơ sở dữ liệu quan hệ, và nhiều cơ sở dữ liệu phi quan hệ cũng dùng chúng.
Giống như SSTable, B-tree giữ các cặp key-value được sắp xếp theo key, cho phép tra cứu key-value hiệu quả và truy vấn phạm vi. Nhưng đó là điểm tương đồng duy nhất: B-tree có triết lý thiết kế rất khác.
Các index log-structured chúng ta đã thấy trước đó chia nhỏ cơ sở dữ liệu thành các segment có kích thước thay đổi, thường là vài megabyte hoặc hơn, được ghi một lần và sau đó là bất biến. Ngược lại, B-tree chia nhỏ cơ sở dữ liệu thành các block hay page có kích thước cố định, và có thể ghi đè một trang tại chỗ. Một page thường có kích thước 4 KiB, nhưng PostgreSQL hiện dùng 8 KiB và MySQL dùng 16 KiB theo mặc định.
Mỗi page có thể được xác định bằng một số trang (page number), cho phép một page tham chiếu đến một page khác, tương tự như con trỏ, nhưng trên đĩa thay vì trong bộ nhớ. Nếu tất cả các page được lưu trong cùng một file, nhân số trang với kích thước trang sẽ cho chúng ta byte offset trong file nơi page đó nằm. Chúng ta có thể dùng các tham chiếu page này để xây dựng một cây page, như minh họa trong Hình 4-5.
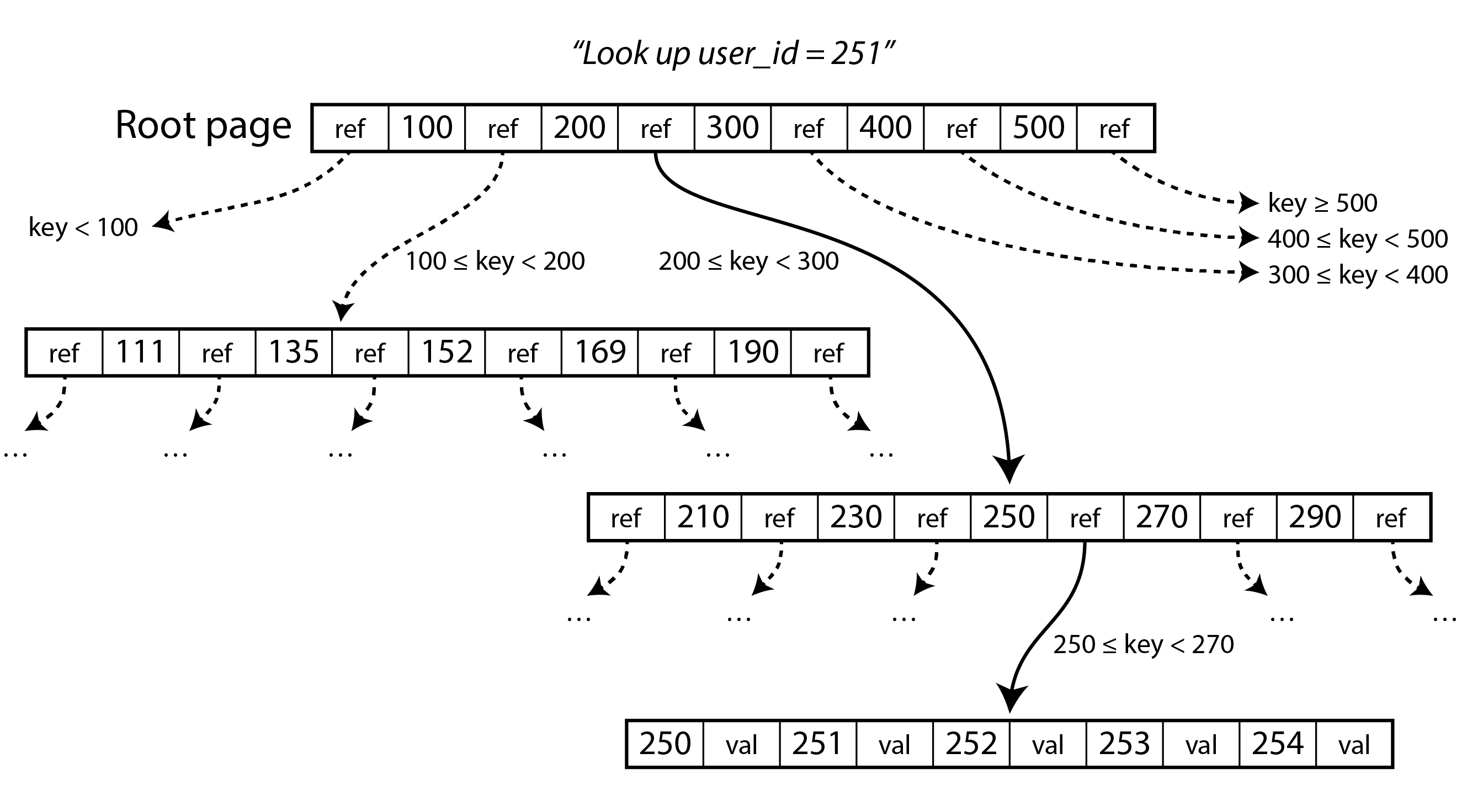
Một page được chỉ định là root của B-tree; bất cứ khi nào bạn muốn tra cứu một key trong index, bạn bắt đầu từ đây. Page chứa nhiều key và tham chiếu đến các trang con. Mỗi trang con chịu trách nhiệm về một phạm vi key liên tục, và các key giữa các tham chiếu cho biết ranh giới giữa các phạm vi đó nằm ở đâu. (Cấu trúc này đôi khi được gọi là B+ tree, nhưng chúng ta không cần phân biệt nó với các biến thể B-tree khác.)
Trong ví dụ ở Hình 4-5, chúng ta đang tìm key 251, vì vậy chúng ta biết rằng chúng ta cần theo tham chiếu page giữa các ranh giới 200 và 300. Điều đó đưa chúng ta đến một page trông tương tự tiếp tục chia nhỏ phạm vi 200-300 thành các phạm vi con. Cuối cùng chúng ta xuống đến một page chứa các key riêng lẻ (một leaf page), chứa giá trị cho mỗi key inline hoặc chứa tham chiếu đến các page nơi giá trị có thể được tìm thấy.
Số lượng tham chiếu đến các trang con trong một page của B-tree được gọi là branching factor (hệ số phân nhánh). Ví dụ, trong Hình 4-5 branching factor là sáu. Trên thực tế, branching factor phụ thuộc vào lượng không gian cần để lưu trữ các tham chiếu page và ranh giới phạm vi, nhưng thường là vài trăm.
Nếu bạn muốn cập nhật giá trị của một key hiện có trong B-tree, bạn tìm kiếm leaf page chứa key đó, và ghi đè page đó trên đĩa bằng một phiên bản chứa giá trị mới. Nếu bạn muốn thêm một key mới, bạn cần tìm page có phạm vi bao gồm key mới và thêm nó vào page đó. Nếu không có đủ không gian trống trong page để chứa key mới, page đó được tách thành hai page nửa đầy, và page cha được cập nhật để phản ánh sự phân chia mới của các phạm vi key.
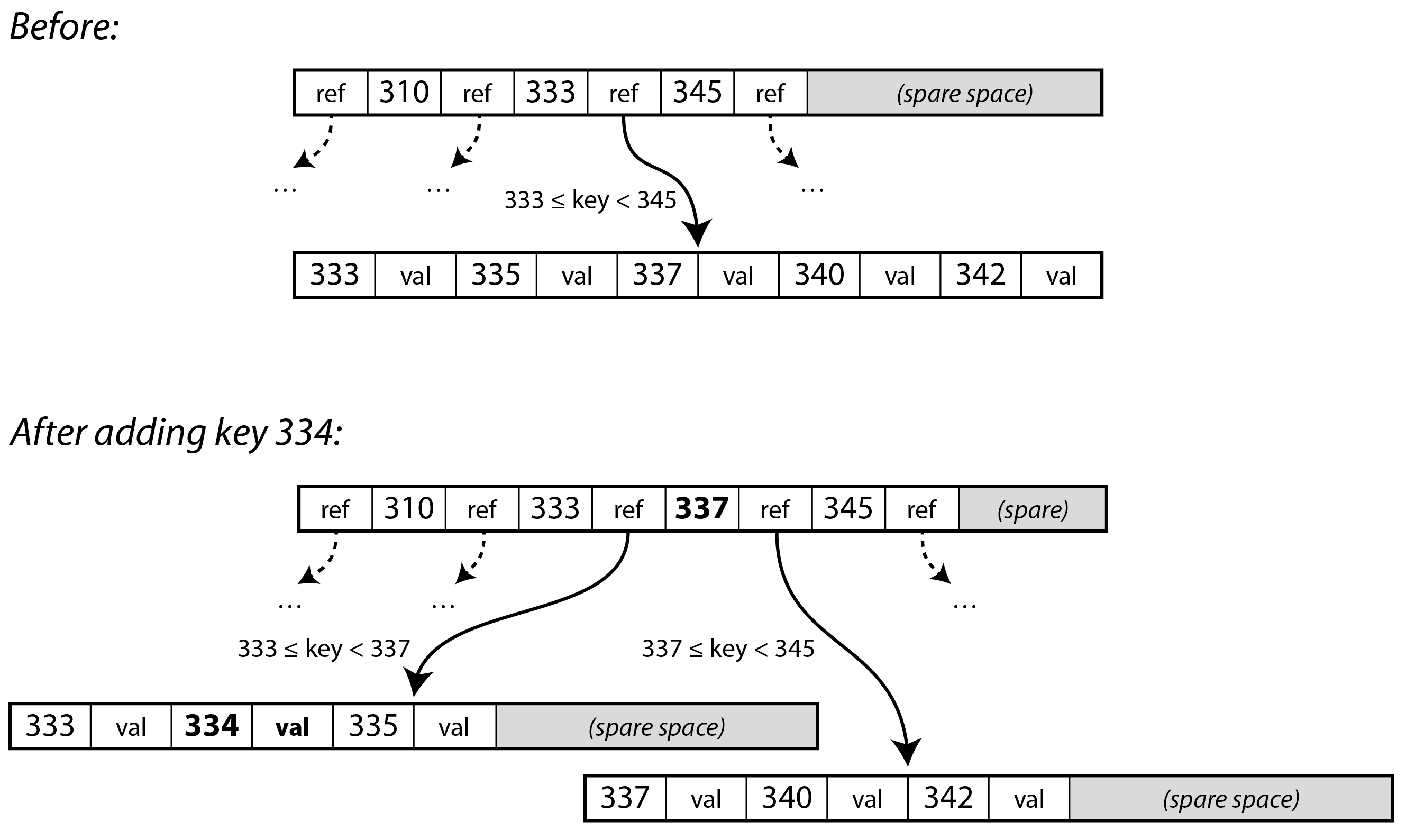
Trong ví dụ của Hình 4-6, chúng ta muốn chèn key 334, nhưng page cho phạm vi 333-345 đã đầy. Do đó chúng ta tách nó thành một page cho phạm vi 333-337 (bao gồm key mới), và một page cho 337-344. Chúng ta cũng phải cập nhật page cha để có tham chiếu đến cả hai trang con, với giá trị ranh giới 337 giữa chúng. Nếu page cha không có đủ không gian cho tham chiếu mới, nó cũng có thể cần được tách, và các lần tách có thể tiếp tục lên đến root của cây. Khi root bị tách, chúng ta tạo một root mới phía trên nó. Việc xóa key (có thể yêu cầu các node được hợp nhất) phức tạp hơn 5.
Thuật toán này đảm bảo rằng cây luôn cân bằng: một B-tree với n key luôn có độ sâu O(log n). Hầu hết các cơ sở dữ liệu có thể vừa trong một B-tree sâu ba hoặc bốn cấp, vì vậy bạn không cần theo nhiều tham chiếu page để tìm page bạn đang tìm kiếm. (Một cây bốn cấp với các page 4 KiB và branching factor 500 có thể lưu trữ lên đến 250 TB.)
Làm cho B-tree đáng tin cậy
Thao tác ghi cơ bản của B-tree là ghi đè một page trên đĩa bằng dữ liệu mới. Người ta giả định rằng việc ghi đè không thay đổi vị trí của page; tức là tất cả các tham chiếu đến page đó vẫn nguyên vẹn khi page được ghi đè. Điều này trái ngược hoàn toàn với các index log-structured như LSM-tree, chỉ ghi thêm vào file (và cuối cùng xóa các file lỗi thời) nhưng không bao giờ sửa đổi file tại chỗ.
Ghi đè nhiều page cùng một lúc, như trong một lần tách page, là một thao tác nguy hiểm: nếu cơ sở dữ liệu gặp sự cố sau khi chỉ một số page đã được ghi, bạn sẽ có một cây bị hỏng (ví dụ, có thể có một page mồ côi không phải là con của bất kỳ cha nào). Nếu phần cứng không thể ghi nguyên tử một trang hoàn chỉnh, bạn cũng có thể có một page được ghi một phần (điều này được gọi là torn page 23).
Để làm cho cơ sở dữ liệu có khả năng chịu đựng sự cố, thông thường các cài đặt B-tree bao gồm một cấu trúc dữ liệu bổ sung trên đĩa: một write-ahead log (WAL, nhật ký ghi trước). Đây là một file chỉ ghi thêm mà mỗi lần sửa đổi B-tree phải được ghi vào trước khi có thể được áp dụng vào các trang của cây. Khi cơ sở dữ liệu khởi động lại sau một sự cố, log này được dùng để khôi phục B-tree về trạng thái nhất quán 2 24. Trong các filesystem, cơ chế tương đương được gọi là journaling (ghi nhật ký).
Để cải thiện hiệu năng, các cài đặt B-tree thường không ghi ngay mỗi trang đã sửa đổi ra đĩa, mà buffer các trang B-tree trong bộ nhớ trong một thời gian trước. Write-ahead log sau đó cũng đảm bảo rằng dữ liệu không bị mất trong trường hợp sự cố: miễn là dữ liệu đã được ghi vào WAL và flush ra đĩa bằng lời gọi hệ thống fsync(), dữ liệu sẽ bền vững vì cơ sở dữ liệu sẽ có thể phục hồi nó sau một sự cố 25.
Các biến thể B-tree
Vì B-tree đã tồn tại lâu như vậy, nhiều biến thể đã được phát triển qua nhiều năm. Chỉ đề cập một vài:
- Thay vì ghi đè các page và duy trì WAL để phục hồi sau sự cố, một số cơ sở dữ liệu (như LMDB) sử dụng scheme copy-on-write (sao chép khi ghi) 26. Một page đã sửa đổi được ghi vào một vị trí khác, và một phiên bản mới của các page cha trong cây được tạo ra, trỏ đến vị trí mới. Cách tiếp cận này cũng hữu ích cho kiểm soát đồng thời, như chúng ta sẽ thấy trong “Snapshot Isolation và Repeatable Read”.
- Chúng ta có thể tiết kiệm không gian trong các page bằng cách không lưu trữ toàn bộ key mà rút gọn nó. Đặc biệt trong các page bên trong của cây, các key chỉ cần cung cấp đủ thông tin để đóng vai trò là ranh giới giữa các phạm vi key. Đóng gói nhiều key hơn vào một page cho phép cây có branching factor cao hơn, và do đó ít cấp hơn.
- Để tăng tốc quét qua phạm vi key theo thứ tự đã sắp xếp, một số cài đặt B-tree cố gắng bố cục cây sao cho các leaf page xuất hiện theo thứ tự tuần tự trên đĩa, giảm số lần tìm kiếm đĩa. Tuy nhiên, khó duy trì thứ tự đó khi cây phát triển.
- Các con trỏ bổ sung đã được thêm vào cây. Ví dụ, mỗi leaf page có thể có tham chiếu đến các trang anh em bên trái và bên phải, cho phép quét các key theo thứ tự mà không cần nhảy trở lại các page cha.
So Sánh B-Tree và LSM-Tree
Theo kinh nghiệm, LSM-tree phù hợp hơn cho các ứng dụng ghi nhiều, trong khi B-tree nhanh hơn cho việc đọc 27 28. Tuy nhiên, các benchmark thường nhạy cảm với chi tiết của workload. Bạn cần kiểm tra các hệ thống với workload cụ thể của mình để có sự so sánh hợp lệ. Hơn nữa, đây không phải là lựa chọn hoàn toàn một trong hai giữa LSM và B-tree: các storage engine đôi khi pha trộn đặc điểm của cả hai cách tiếp cận, ví dụ bằng cách có nhiều B-tree và hợp nhất chúng theo kiểu LSM. Trong phần này chúng ta sẽ thảo luận ngắn gọn một vài điều đáng cân nhắc khi đo lường hiệu năng của một storage engine.
Hiệu năng đọc
Trong B-tree, tra cứu một key liên quan đến việc đọc một page ở mỗi cấp của B-tree. Vì số cấp thường khá nhỏ, điều này có nghĩa là các lần đọc từ B-tree thường nhanh và có hiệu năng có thể dự đoán được. Trong một LSM storage engine, các lần đọc thường phải kiểm tra nhiều SSTable khác nhau ở các giai đoạn compaction khác nhau, nhưng Bloom filter giúp giảm số lượng thao tác I/O đĩa thực tế cần thiết. Cả hai cách tiếp cận đều có thể hoạt động tốt, và cái nào nhanh hơn phụ thuộc vào chi tiết của storage engine và workload.
Truy vấn phạm vi đơn giản và nhanh trên B-tree, vì chúng có thể sử dụng cấu trúc đã sắp xếp của cây. Trên LSM storage, truy vấn phạm vi cũng có thể tận dụng việc sắp xếp SSTable, nhưng chúng cần quét tất cả các segment song song và kết hợp kết quả. Bloom filter không giúp ích cho truy vấn phạm vi (vì bạn sẽ cần tính hàm băm của mọi key có thể có trong phạm vi, điều đó không thực tế), khiến truy vấn phạm vi tốn kém hơn truy vấn điểm trong cách tiếp cận LSM 29.
Thông lượng ghi cao có thể gây ra các đỉnh độ trễ trong một log-structured storage engine nếu memtable bị đầy. Điều này xảy ra nếu dữ liệu không thể được ghi ra đĩa đủ nhanh, có thể vì quá trình compaction không thể theo kịp với các lần ghi đến. Nhiều storage engine, bao gồm RocksDB, thực hiện backpressure (áp lực ngược) trong tình huống này: chúng tạm dừng tất cả các lần đọc và ghi cho đến khi memtable đã được ghi ra đĩa 30 31.
Về thông lượng đọc, các SSD hiện đại (đặc biệt là NVMe) có thể thực hiện nhiều yêu cầu đọc độc lập song song. Cả LSM-tree và B-tree đều có thể cung cấp thông lượng đọc cao, nhưng các storage engine cần được thiết kế cẩn thận để tận dụng sự song song này 32.
Ghi tuần tự so với ghi ngẫu nhiên
Với B-tree, nếu ứng dụng ghi các key rải rác khắp không gian key, các thao tác đĩa kết quả cũng rải rác ngẫu nhiên, vì các page mà storage engine cần ghi đè có thể nằm ở bất kỳ đâu trên đĩa. Mặt khác, một log-structured storage engine ghi toàn bộ các file segment cùng một lúc (hoặc ghi memtable ra hoặc trong khi compacting các segment hiện có), lớn hơn nhiều so với một trang trong B-tree.
Mẫu của nhiều lần ghi nhỏ rải rác (như trong B-tree) được gọi là random writes (ghi ngẫu nhiên), trong khi mẫu của ít lần ghi lớn (như trong LSM-tree) được gọi là sequential writes (ghi tuần tự). Các đĩa thường có thông lượng ghi tuần tự cao hơn thông lượng ghi ngẫu nhiên, có nghĩa là một log-structured storage engine thường có thể xử lý thông lượng ghi cao hơn trên cùng phần cứng so với B-tree. Sự khác biệt này đặc biệt lớn trên ổ đĩa cứng quay (HDD); trên ổ trạng thái rắn (SSD) mà hầu hết các cơ sở dữ liệu sử dụng ngày nay, sự khác biệt nhỏ hơn, nhưng vẫn đáng chú ý (xem “Ghi Tuần Tự so với Ghi Ngẫu Nhiên trên SSD”).
GHI TUẦN TỰ SO VỚI GHI NGẪU NHIÊN TRÊN SSD
Trên ổ đĩa cứng quay (HDD), ghi tuần tự nhanh hơn nhiều so với ghi ngẫu nhiên: một lần ghi ngẫu nhiên phải di chuyển cơ học đầu đọc đến một vị trí mới và đợi phần đĩa quay đúng đi qua bên dưới đầu đọc, mất vài mili giây, là cả một cõi vĩnh hằng theo thước đo thời gian điện toán. Tuy nhiên, SSD (ổ trạng thái rắn) bao gồm NVMe (Non-Volatile Memory Express, tức bộ nhớ flash gắn vào bus PCI Express) đã vượt qua HDD trong nhiều trường hợp sử dụng, và chúng không bị giới hạn bởi các ràng buộc cơ học như vậy.
Tuy nhiên, SSD cũng có thông lượng cao hơn cho ghi tuần tự so với ghi ngẫu nhiên. Lý do là bộ nhớ flash có thể được đọc hoặc ghi một trang (thường là 4 KiB) một lúc, nhưng chỉ có thể được xóa một block (thường là 512 KiB) một lúc. Một số trang trong một block có thể chứa dữ liệu hợp lệ, trong khi các trang khác có thể chứa dữ liệu không còn cần thiết nữa. Trước khi xóa một block, controller phải trước tiên di chuyển các trang chứa dữ liệu hợp lệ vào các block khác; quá trình này được gọi là garbage collection (GC, thu gom rác) 33.
Một workload ghi tuần tự ghi các chunk dữ liệu lớn hơn một lúc, vì vậy có khả năng toàn bộ block 512 KiB thuộc về một file duy nhất; khi file đó sau này bị xóa, toàn bộ block có thể được xóa mà không cần thực hiện bất kỳ GC nào. Mặt khác, với workload ghi ngẫu nhiên, có nhiều khả năng một block chứa hỗn hợp các trang với dữ liệu hợp lệ và không hợp lệ, vì vậy GC phải thực hiện nhiều công việc hơn trước khi một block có thể được xóa 34 35 36.
Băng thông ghi bị GC tiêu thụ sẽ không còn sẵn có cho ứng dụng. Hơn nữa, các lần ghi bổ sung do GC thực hiện góp phần vào việc mài mòn bộ nhớ flash; do đó, ghi ngẫu nhiên làm hao mòn ổ đĩa nhanh hơn ghi tuần tự.
Write amplification (khuếch đại ghi)
Với bất kỳ loại storage engine nào, một yêu cầu ghi từ ứng dụng biến thành nhiều thao tác I/O trên đĩa bên dưới. Với LSM-tree, một giá trị đầu tiên được ghi vào log để đảm bảo độ bền, rồi lại khi memtable được ghi ra đĩa, và lại mỗi khi cặp key-value là một phần của compaction. (Nếu các giá trị lớn hơn đáng kể so với các key, overhead này có thể được giảm bằng cách lưu các giá trị riêng biệt với các key, và chỉ thực hiện compaction trên các SSTable chứa key và tham chiếu đến giá trị 37.)
Một index B-tree phải ghi mỗi mảnh dữ liệu ít nhất hai lần: một lần vào write-ahead log, và một lần vào page cây. Ngoài ra, chúng đôi khi cần ghi ra toàn bộ một page, ngay cả khi chỉ vài byte trong page đó thay đổi, để đảm bảo B-tree có thể được phục hồi đúng sau sự cố hoặc mất điện 38 39.
Nếu bạn lấy tổng số byte được ghi ra đĩa trong một workload nào đó, và chia cho số byte bạn phải ghi nếu bạn chỉ đơn giản ghi một log chỉ ghi thêm mà không có index, bạn sẽ có được write amplification (khuếch đại ghi). (Đôi khi write amplification được định nghĩa theo số thao tác I/O thay vì byte.) Trong các ứng dụng ghi nặng, điểm nghẽn cổ chai có thể là tốc độ mà cơ sở dữ liệu có thể ghi ra đĩa. Trong trường hợp này, write amplification càng cao thì số lần ghi mỗi giây càng ít mà nó có thể xử lý trong băng thông đĩa sẵn có.
Write amplification là vấn đề trong cả LSM-tree lẫn B-tree. Cái nào tốt hơn phụ thuộc vào nhiều yếu tố, chẳng hạn độ dài của các key và giá trị, và tần suất bạn ghi đè các key hiện có so với chèn các key mới. Đối với các workload điển hình, LSM-tree có xu hướng có write amplification thấp hơn vì chúng không phải ghi toàn bộ page và chúng có thể nén các chunk của SSTable 40. Đây là một yếu tố khác làm cho LSM storage engine phù hợp tốt cho các workload ghi nặng.
Ngoài việc ảnh hưởng đến thông lượng, write amplification cũng liên quan đến sự mài mòn của SSD: một storage engine có write amplification thấp hơn sẽ làm hao mòn SSD chậm hơn.
Khi đo thông lượng ghi của một storage engine, điều quan trọng là chạy thử nghiệm đủ lâu để các tác động của write amplification trở nên rõ ràng. Khi ghi vào một LSM-tree rỗng, chưa có compaction nào diễn ra, vì vậy toàn bộ băng thông đĩa đều có sẵn cho các lần ghi mới. Khi cơ sở dữ liệu phát triển, các lần ghi mới cần chia sẻ băng thông đĩa với compaction.
Sử dụng dung lượng đĩa
B-tree có thể bị phân mảnh (fragmented) theo thời gian: ví dụ, nếu một số lượng lớn key bị xóa, file cơ sở dữ liệu có thể chứa nhiều page không còn được B-tree sử dụng. Các phần thêm mới vào B-tree có thể dùng những page trống đó, nhưng chúng không thể dễ dàng được trả lại cho hệ điều hành vì chúng nằm giữa file, vì vậy chúng vẫn chiếm dung lượng trên filesystem. Do đó, các cơ sở dữ liệu cần một tiến trình nền di chuyển các page để đặt chúng tốt hơn, chẳng hạn như tiến trình vacuum trong PostgreSQL 25.
Phân mảnh ít gây ra vấn đề hơn trong LSM-tree, vì quá trình compaction định kỳ viết lại các file dữ liệu anyway, và SSTable không có các page với không gian chưa dùng. Hơn nữa, các block cặp key-value có thể được nén tốt hơn trong SSTable, và do đó thường tạo ra các file nhỏ hơn trên đĩa so với B-tree. Các key và giá trị đã bị ghi đè tiếp tục chiếm dung lượng cho đến khi chúng bị xóa bởi một compaction, nhưng overhead này khá thấp khi sử dụng leveled compaction 40 41. Size-tiered compaction (xem “Chiến lược compaction”) sử dụng nhiều dung lượng đĩa hơn, đặc biệt là tạm thời trong quá trình compaction.
Việc có nhiều bản sao của một số dữ liệu trên đĩa cũng có thể là vấn đề khi bạn cần xóa một số dữ liệu và chắc chắn rằng nó thực sự đã bị xóa (có thể để tuân thủ các quy định bảo vệ dữ liệu). Ví dụ, trong hầu hết các LSM storage engine, một bản ghi đã xóa vẫn có thể tồn tại ở các cấp cao hơn cho đến khi tombstone đại diện cho việc xóa đã được truyền qua tất cả các cấp compaction, điều này có thể mất nhiều thời gian. Các thiết kế storage engine chuyên biệt có thể truyền bá các lần xóa nhanh hơn 42.
Mặt khác, tính bất biến của các file segment SSTable hữu ích nếu bạn muốn lấy một snapshot của cơ sở dữ liệu tại một thời điểm nào đó (ví dụ để sao lưu hoặc tạo bản sao của cơ sở dữ liệu để kiểm thử): bạn có thể ghi memtable ra và ghi lại các file segment nào tồn tại tại thời điểm đó. Miễn là bạn không xóa các file là một phần của snapshot, bạn không cần thực sự sao chép chúng. Trong B-tree có các page được ghi đè, việc lấy snapshot hiệu quả như vậy khó hơn nhiều.
Chỉ Mục Đa Cột và Chỉ Mục Phụ
Cho đến nay chúng ta chỉ thảo luận về các index key-value, giống như một index primary key (khóa chính) trong mô hình quan hệ. Một primary key xác định duy nhất một hàng trong một bảng quan hệ, hoặc một document trong cơ sở dữ liệu document, hoặc một đỉnh trong cơ sở dữ liệu đồ thị. Các bản ghi khác trong cơ sở dữ liệu có thể tham chiếu đến hàng/document/đỉnh đó bằng primary key (hoặc ID), và index được dùng để giải quyết các tham chiếu như vậy.
Cũng rất phổ biến khi có các secondary index (chỉ mục phụ). Trong cơ sở dữ liệu quan hệ, bạn có thể tạo nhiều secondary index trên cùng một bảng bằng lệnh CREATE INDEX, cho phép bạn tìm kiếm theo các cột khác ngoài primary key. Ví dụ, trong Hình 3-1 trong Chương 3, bạn rất có thể sẽ có một secondary index trên các cột user_id để bạn có thể tìm tất cả các hàng thuộc cùng một user trong mỗi bảng.
Một secondary index có thể dễ dàng được xây dựng từ một index key-value. Sự khác biệt chính là trong một secondary index, các giá trị được đánh chỉ mục không nhất thiết là duy nhất; tức là có thể có nhiều hàng (document, đỉnh) dưới cùng một mục index. Điều này có thể được giải quyết theo hai cách: hoặc bằng cách làm cho mỗi giá trị trong index là một danh sách các định danh hàng khớp (như danh sách posting trong một full-text index) hoặc bằng cách làm cho mỗi mục là duy nhất bằng cách thêm định danh hàng vào cuối nó. Các storage engine có cập nhật tại chỗ, như B-tree, và log-structured storage đều có thể được dùng để cài đặt một index.
Lưu trữ giá trị bên trong index
Key trong một index là thứ mà các truy vấn tìm kiếm, nhưng giá trị có thể là một trong nhiều thứ:
- Nếu dữ liệu thực tế (hàng, document, đỉnh) được lưu trực tiếp trong cấu trúc index, nó được gọi là clustered index (chỉ mục cụm). Ví dụ, trong storage engine InnoDB của MySQL, primary key của một bảng luôn là một clustered index, và trong SQL Server, bạn có thể chỉ định một clustered index cho mỗi bảng 43.
- Thay vào đó, giá trị có thể là một tham chiếu đến dữ liệu thực tế: hoặc là primary key của hàng đang xét (InnoDB làm điều này cho các secondary index), hoặc là một tham chiếu trực tiếp đến một vị trí trên đĩa. Trong trường hợp sau, nơi các hàng được lưu trữ được gọi là heap file (file đống), và nó lưu trữ dữ liệu không theo thứ tự cụ thể nào (nó có thể chỉ ghi thêm, hoặc nó có thể theo dõi các hàng đã xóa để ghi đè chúng bằng dữ liệu mới sau này). Ví dụ, Postgres sử dụng cách tiếp cận heap file 44.
- Một điểm trung gian giữa hai cách là covering index (chỉ mục bao phủ) hay index with included columns (chỉ mục có cột bao gồm), lưu một số cột của bảng trong index, ngoài việc lưu toàn bộ hàng trong heap hoặc trong primary key clustered index 45. Điều này cho phép một số truy vấn được trả lời chỉ bằng index mà không cần giải quyết primary key hoặc tìm trong heap file (trong trường hợp đó, index được nói là cover truy vấn). Điều này có thể làm cho một số truy vấn nhanh hơn, nhưng việc sao chép dữ liệu có nghĩa là index sử dụng nhiều dung lượng đĩa hơn và làm chậm ghi.
Các index đã thảo luận cho đến nay chỉ ánh xạ một key duy nhất đến một giá trị. Nếu bạn cần truy vấn nhiều cột của một bảng (hoặc nhiều trường trong một document) đồng thời, xem “Chỉ mục Đa chiều và Toàn văn”.
Khi cập nhật một giá trị mà không thay đổi key, cách tiếp cận heap file có thể cho phép bản ghi được ghi đè tại chỗ, miễn là giá trị mới không lớn hơn giá trị cũ. Tình huống phức tạp hơn nếu giá trị mới lớn hơn, vì nó có thể cần được chuyển đến một vị trí mới trong heap nơi có đủ không gian. Trong trường hợp đó, hoặc tất cả các index cần được cập nhật để trỏ đến vị trí heap mới của bản ghi, hoặc một con trỏ chuyển tiếp được để lại ở vị trí heap cũ 2.
Giữ mọi thứ trong bộ nhớ
Các cấu trúc dữ liệu đã thảo luận cho đến nay trong chương này đều là câu trả lời cho các giới hạn của đĩa. So với bộ nhớ chính, đĩa khó xử lý hơn. Với cả đĩa từ và SSD, dữ liệu trên đĩa cần được bố cục cẩn thận nếu bạn muốn có hiệu năng tốt khi đọc và ghi. Tuy nhiên, chúng ta chấp nhận sự khó khăn này vì đĩa có hai ưu điểm đáng kể: chúng bền vững (nội dung không bị mất khi tắt điện) và chúng có chi phí thấp hơn mỗi gigabyte so với RAM.
Khi RAM trở nên rẻ hơn, lập luận về chi phí mỗi gigabyte dần bị xói mòn. Nhiều dataset không quá lớn, vì vậy khá khả thi để giữ chúng hoàn toàn trong bộ nhớ, có thể được phân tán trên nhiều máy. Điều này đã dẫn đến sự phát triển của cơ sở dữ liệu trong bộ nhớ (in-memory database).
Một số kho key-value trong bộ nhớ, chẳng hạn Memcached, chỉ dành cho mục đích caching, trong đó có thể chấp nhận được việc mất dữ liệu khi máy được khởi động lại. Nhưng các cơ sở dữ liệu trong bộ nhớ khác hướng đến độ bền, có thể đạt được bằng phần cứng đặc biệt (chẳng hạn RAM có pin dự phòng), bằng cách ghi log các thay đổi ra đĩa, ghi snapshot định kỳ ra đĩa, hoặc bằng cách nhân bản trạng thái trong bộ nhớ sang các máy khác.
Khi một cơ sở dữ liệu trong bộ nhớ được khởi động lại, nó cần tải lại trạng thái của mình, hoặc từ đĩa hoặc qua mạng từ một bản sao (replica) (trừ khi phần cứng đặc biệt được sử dụng). Mặc dù ghi ra đĩa, nó vẫn là một cơ sở dữ liệu trong bộ nhớ, vì đĩa chỉ được dùng như một log chỉ ghi thêm để đảm bảo độ bền, và các lần đọc được phục vụ hoàn toàn từ bộ nhớ. Ghi ra đĩa cũng có ưu điểm vận hành: các file trên đĩa có thể dễ dàng được sao lưu, kiểm tra và phân tích bởi các tiện ích bên ngoài.
Các sản phẩm như VoltDB, SingleStore và Oracle TimesTen là cơ sở dữ liệu trong bộ nhớ với mô hình quan hệ, và các nhà cung cấp tuyên bố rằng họ có thể cung cấp những cải thiện hiệu năng lớn bằng cách loại bỏ tất cả các overhead và các nhà cung cấp khẳng định rằng họ có thể mang lại những cải thiện hiệu năng đáng kể bằng cách loại bỏ toàn bộ chi phí liên quan đến việc quản lý các cấu trúc dữ liệu trên đĩa 46 47. RAMCloud là một kho lưu trữ key-value (khóa-giá trị) mã nguồn mở, lưu trữ trong bộ nhớ có tính bền vững (sử dụng phương pháp log-structured cho dữ liệu trong bộ nhớ lẫn dữ liệu trên đĩa) 48.
Redis và Couchbase cung cấp độ bền yếu hơn bằng cách ghi xuống đĩa không đồng bộ.
Trái với trực giác thông thường, lợi thế hiệu năng của các cơ sở dữ liệu in-memory (trong bộ nhớ) không đến từ việc chúng không cần đọc từ đĩa. Ngay cả một storage engine (bộ máy lưu trữ) dựa trên đĩa cũng có thể không bao giờ cần đọc từ đĩa nếu bạn có đủ bộ nhớ, bởi vì hệ điều hành vẫn lưu cache các khối đĩa được dùng gần đây trong bộ nhớ. Thay vào đó, các cơ sở dữ liệu in-memory có thể nhanh hơn vì chúng tránh được chi phí mã hóa các cấu trúc dữ liệu trong bộ nhớ thành dạng có thể ghi xuống đĩa 49.
Ngoài hiệu năng, một lĩnh vực thú vị khác của cơ sở dữ liệu in-memory là khả năng cung cấp các mô hình dữ liệu khó triển khai với các index dựa trên đĩa. Ví dụ, Redis cung cấp giao diện giống cơ sở dữ liệu cho nhiều loại cấu trúc dữ liệu khác nhau như priority queue (hàng đợi ưu tiên) và set (tập hợp). Do lưu toàn bộ dữ liệu trong bộ nhớ, việc triển khai của nó tương đối đơn giản.
Lưu Trữ Dữ Liệu Cho Phân Tích
Mô hình dữ liệu của một data warehouse (kho dữ liệu) thường là quan hệ, vì SQL nhìn chung rất phù hợp cho các truy vấn phân tích. Có nhiều công cụ phân tích dữ liệu đồ họa có thể sinh ra các câu truy vấn SQL, trực quan hóa kết quả và cho phép các nhà phân tích khám phá dữ liệu (thông qua các thao tác như drill-down và slicing and dicing).
Nhìn bề ngoài, một data warehouse và một cơ sở dữ liệu OLTP quan hệ trông có vẻ giống nhau, vì cả hai đều có giao diện truy vấn SQL. Tuy nhiên, nội bộ của các hệ thống có thể khác nhau đáng kể, vì chúng được tối ưu hóa cho các mẫu truy vấn rất khác nhau. Nhiều nhà cung cấp cơ sở dữ liệu hiện nay tập trung hỗ trợ hoặc xử lý giao dịch hoặc khối lượng công việc phân tích, nhưng không phải cả hai.
Một số cơ sở dữ liệu, chẳng hạn như Microsoft SQL Server, SAP HANA và SingleStore, hỗ trợ cả xử lý giao dịch lẫn data warehousing trong cùng một sản phẩm. Tuy nhiên, các cơ sở dữ liệu HTAP (hybrid transactional and analytical processing, xử lý giao dịch và phân tích lai) này (được giới thiệu trong “Data Warehousing”) ngày càng trở thành hai storage engine và query engine riêng biệt, được truy cập qua một giao diện SQL chung 50 51 52 53.
Cloud Data Warehouse
Các nhà cung cấp data warehouse như Teradata, Vertica và SAP HANA bán cả giải pháp on-premises (tại chỗ) theo giấy phép thương mại lẫn giải pháp cloud. Nhưng khi nhiều khách hàng của họ chuyển lên cloud, các cloud data warehouse mới như Google Cloud BigQuery, Amazon Redshift và Snowflake cũng được áp dụng rộng rãi. Khác với các data warehouse truyền thống, cloud data warehouse tận dụng cơ sở hạ tầng cloud có khả năng mở rộng như object storage (lưu trữ đối tượng) và các nền tảng tính toán serverless.
Cloud data warehouse có xu hướng tích hợp tốt hơn với các dịch vụ cloud khác và linh hoạt hơn. Ví dụ, nhiều cloud warehouse hỗ trợ thu thập log tự động và cung cấp tích hợp dễ dàng với các framework xử lý dữ liệu như Dataflow của Google Cloud hay Kinesis của Amazon Web Services. Các warehouse này cũng linh hoạt hơn vì chúng tách biệt tính toán truy vấn khỏi tầng lưu trữ 54. Dữ liệu được lưu trữ trên object storage thay vì đĩa cục bộ, giúp dễ dàng điều chỉnh dung lượng lưu trữ và tài nguyên tính toán cho truy vấn một cách độc lập, như chúng ta đã thấy trong “Cloud-Native System Architecture”.
Các data warehouse mã nguồn mở như Apache Hive, Trino và Apache Spark cũng đã phát triển cùng với cloud. Khi lưu trữ dữ liệu phân tích đã chuyển sang data lake (hồ dữ liệu) trên object storage, các data warehouse mã nguồn mở bắt đầu được tách ra thành các thành phần riêng biệt 55. Các thành phần sau đây, trước đây được tích hợp trong một hệ thống duy nhất như Apache Hive, nay thường được triển khai dưới dạng các thành phần tách biệt:
- Query engine (Bộ máy truy vấn)
- Các query engine như Trino, Apache DataFusion và Presto phân tích cú pháp câu truy vấn SQL, tối ưu chúng thành các execution plan (kế hoạch thực thi) và thực thi chúng trên dữ liệu. Thực thi thường yêu cầu các tác vụ xử lý dữ liệu phân tán, song song. Một số query engine cung cấp khả năng thực thi tác vụ tích hợp sẵn, trong khi những cái khác chọn sử dụng các framework thực thi của bên thứ ba như Apache Spark hay Apache Flink.
- Storage format (Định dạng lưu trữ)
- Storage format xác định cách các hàng của một bảng được mã hóa dưới dạng byte trong một tệp, sau đó thường được lưu trữ trong object storage hoặc một hệ thống tệp phân tán 12. Dữ liệu này sau đó có thể được truy cập bởi query engine, nhưng cũng bởi các ứng dụng khác sử dụng data lake. Ví dụ về các storage format là Parquet, ORC, Lance hoặc Nimble, và chúng ta sẽ tìm hiểu thêm về chúng trong phần tiếp theo.
- Table format (Định dạng bảng)
- Các tệp được viết theo Apache Parquet và các storage format tương tự thường là bất biến sau khi viết. Để hỗ trợ chèn và xóa hàng, một table format như Apache Iceberg hoặc Delta format của Databricks được sử dụng. Table format chỉ định một file format xác định những tệp nào tạo thành một bảng cùng với schema của bảng. Các định dạng như vậy cũng cung cấp các tính năng nâng cao như time travel (khả năng truy vấn một bảng tại thời điểm trước đó), thu gom rác và thậm chí là transaction (giao dịch).
- Data catalog (Danh mục dữ liệu)
- Giống như table format xác định những tệp nào tạo thành một bảng, một data catalog xác định những bảng nào tạo nên một cơ sở dữ liệu. Catalog được dùng để tạo, đổi tên và xóa bảng. Khác với storage format và table format, data catalog như Polaris của Snowflake và Unity Catalog của Databricks thường chạy dưới dạng dịch vụ độc lập có thể truy vấn qua giao diện REST. Apache Iceberg cũng cung cấp một catalog, có thể chạy bên trong một client hoặc như một tiến trình riêng biệt. Các query engine sử dụng thông tin catalog khi đọc và ghi bảng. Truyền thống, catalog và query engine được tích hợp với nhau, nhưng việc tách chúng ra đã cho phép các hệ thống data discovery (khám phá dữ liệu) và data governance (quản trị dữ liệu) (được thảo luận trong “Data Systems, Law, and Society”) truy cập metadata của catalog.
Lưu Trữ Định Hướng Cột
Như đã thảo luận trong “Stars and Snowflakes: Schemas for Analytics”, các data warehouse theo quy ước thường sử dụng một schema quan hệ với một bảng fact (thực tế) lớn chứa các tham chiếu khóa ngoại đến các bảng dimension (chiều). Nếu bạn có hàng nghìn tỷ hàng và petabyte dữ liệu trong các bảng fact, việc lưu trữ và truy vấn chúng một cách hiệu quả trở thành một bài toán đầy thách thức. Các bảng dimension thường nhỏ hơn nhiều (hàng triệu hàng), vì vậy trong phần này chúng ta sẽ tập trung vào việc lưu trữ các bảng fact.
Mặc dù các bảng fact thường có hơn 100 cột, một truy vấn data warehouse điển hình chỉ truy cập 4
hoặc 5 trong số đó tại một thời điểm (truy vấn "SELECT *" hiếm khi cần thiết cho phân tích) 52. Hãy xem truy vấn trong
Ví dụ 4-1: nó truy cập một số lượng lớn hàng (mỗi lần ai đó
mua trái cây hoặc kẹo trong năm dương lịch 2024), nhưng chỉ cần truy cập ba cột của
bảng fact_sales: date_key, product_sk,
và quantity. Truy vấn bỏ qua tất cả các cột còn lại.
Ví dụ 4-1. Phân tích xem mọi người có xu hướng mua trái cây tươi hay kẹo nhiều hơn tùy theo ngày trong tuần
SELECT
dim_date.weekday, dim_product.category,
SUM(fact_sales.quantity) AS quantity_sold
FROM fact_sales
JOIN dim_date ON fact_sales.date_key = dim_date.date_key
JOIN dim_product ON fact_sales.product_sk = dim_product.product_sk
WHERE
dim_date.year = 2024 AND
dim_product.category IN ('Fresh fruit', 'Candy')
GROUP BY
dim_date.weekday, dim_product.category;Làm thế nào chúng ta có thể thực thi truy vấn này một cách hiệu quả?
Trong hầu hết các cơ sở dữ liệu OLTP, lưu trữ được bố trí theo kiểu row-oriented (định hướng hàng): tất cả các giá trị từ một hàng của bảng được lưu trữ cạnh nhau. Cơ sở dữ liệu document cũng tương tự: toàn bộ document thường được lưu trữ dưới dạng một chuỗi byte liên tục. Bạn có thể thấy điều này trong ví dụ CSV ở Hình 4-1.
Để xử lý một truy vấn như Ví dụ 4-1, bạn có thể có các index trên
fact_sales.date_key và/hoặc fact_sales.product_sk để cho storage engine biết nơi tìm
tất cả các giao dịch bán hàng cho một ngày cụ thể hoặc một sản phẩm cụ thể. Nhưng sau đó, một storage engine row-oriented vẫn cần tải tất cả các hàng đó (mỗi hàng gồm hơn 100 thuộc tính) từ đĩa vào
bộ nhớ, phân tích cú pháp và lọc những hàng không đáp ứng điều kiện yêu cầu. Điều đó có thể mất
rất nhiều thời gian.
Ý tưởng đằng sau lưu trữ column-oriented (định hướng cột, hay columnar) rất đơn giản: đừng lưu trữ tất cả các giá trị từ một hàng cùng nhau, mà hãy lưu trữ tất cả các giá trị từ mỗi cột cùng nhau 56. Nếu mỗi cột được lưu trữ riêng biệt, một truy vấn chỉ cần đọc và phân tích cú pháp những cột được sử dụng trong truy vấn đó, điều này có thể tiết kiệm rất nhiều công việc. Hình 4-7 minh họa nguyên tắc này bằng cách sử dụng phiên bản mở rộng của bảng fact từ Hình 3-5.
Note
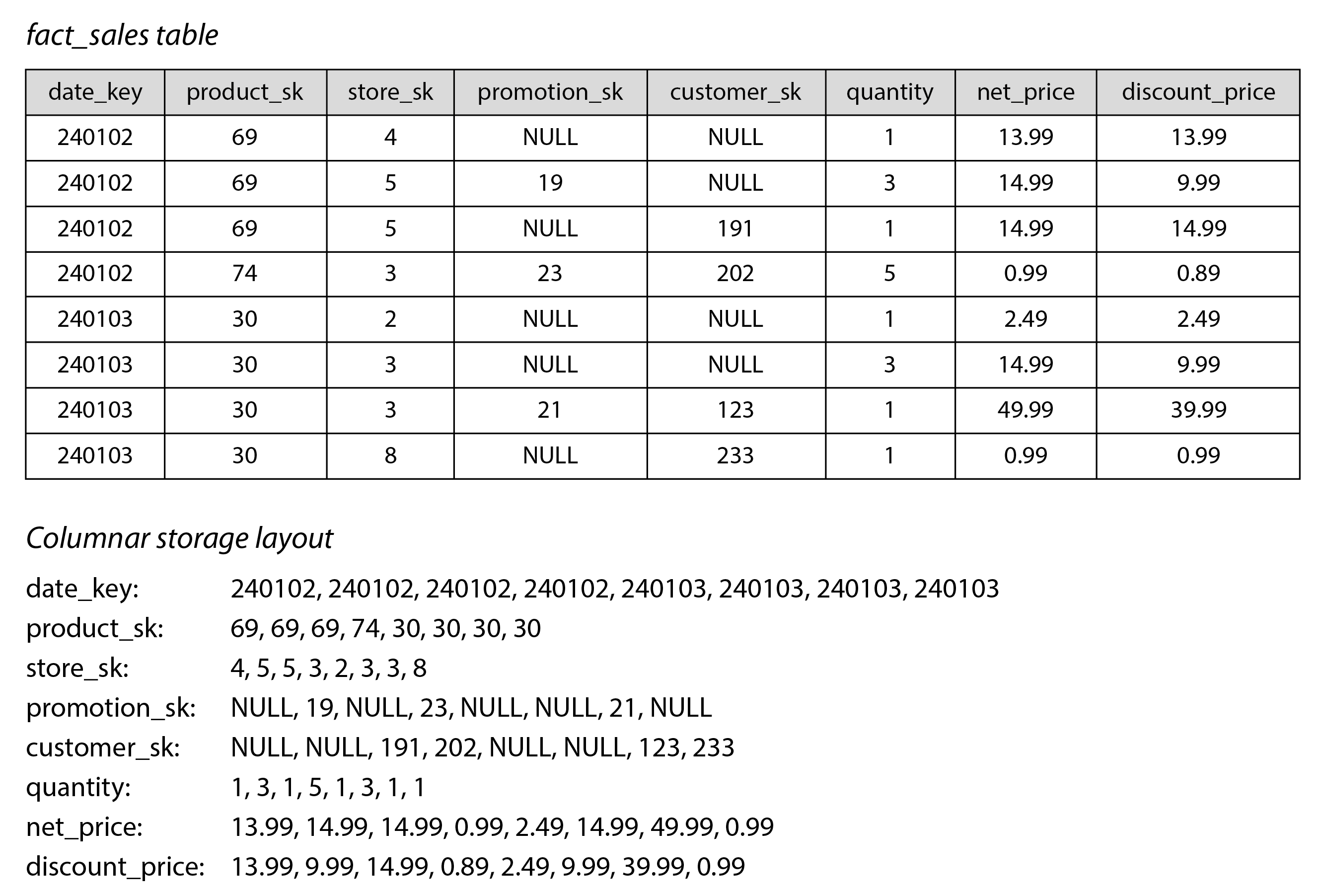
Bố cục lưu trữ column-oriented phụ thuộc vào việc mỗi cột lưu trữ các hàng theo cùng một thứ tự. Do đó, nếu bạn cần tái tạo lại một hàng hoàn chỉnh, bạn có thể lấy mục thứ 23 từ mỗi cột riêng lẻ và ghép chúng lại để tạo thành hàng thứ 23 của bảng.
Thực ra, các columnar storage engine không thực sự lưu trữ toàn bộ một cột (có thể chứa hàng nghìn tỷ hàng) trong một lần. Thay vào đó, chúng chia bảng thành các khối gồm hàng nghìn hoặc hàng triệu hàng, và trong mỗi khối chúng lưu trữ các giá trị từ mỗi cột riêng biệt 60. Vì nhiều truy vấn được giới hạn trong một khoảng thời gian cụ thể, việc tạo mỗi khối chứa các hàng cho một khoảng thời gian nhất định là thông lệ phổ biến. Một truy vấn sau đó chỉ cần tải các cột nó cần trong những khối có giao với khoảng ngày được yêu cầu.
Lưu trữ columnar được sử dụng trong hầu hết tất cả các cơ sở dữ liệu phân tích ngày nay 60, từ các cloud data warehouse quy mô lớn như Snowflake 61 đến các cơ sở dữ liệu nhúng một nút (single-node) như DuckDB 62, và các hệ thống phân tích sản phẩm như Pinot 63 và Druid 64. Nó được sử dụng trong các storage format như Parquet, ORC 65 66, Lance 67 và Nimble 68, cũng như các định dạng phân tích in-memory như Apache Arrow 65 69 và Pandas/NumPy 70. Một số cơ sở dữ liệu time-series, chẳng hạn như InfluxDB IOx 71 và TimescaleDB 72, cũng dựa trên lưu trữ column-oriented.
Nén Cột
Ngoài việc chỉ tải từ đĩa những cột được yêu cầu cho một truy vấn, chúng ta có thể tiếp tục giảm nhu cầu về thông lượng đĩa và băng thông mạng bằng cách nén dữ liệu. May mắn thay, lưu trữ column-oriented thường rất phù hợp để nén.
Hãy nhìn vào các chuỗi giá trị cho mỗi cột trong Hình 4-7: chúng thường trông khá lặp đi lặp lại, đó là dấu hiệu tốt cho việc nén. Tùy thuộc vào dữ liệu trong cột, các kỹ thuật nén khác nhau có thể được sử dụng. Một kỹ thuật đặc biệt hiệu quả trong các data warehouse là bitmap encoding (mã hóa bitmap), được minh họa trong Hình 4-8.

Thường thì số lượng giá trị phân biệt trong một cột nhỏ hơn so với số lượng hàng (ví dụ, một nhà bán lẻ có thể có hàng tỷ giao dịch bán hàng, nhưng chỉ có 100.000 sản phẩm phân biệt). Chúng ta có thể lấy một cột với n giá trị phân biệt và chuyển nó thành n bitmap riêng biệt: một bitmap cho mỗi giá trị phân biệt, với một bit cho mỗi hàng. Bit là 1 nếu hàng có giá trị đó, và 0 nếu không.
Một tùy chọn là lưu trữ các bitmap đó bằng một bit mỗi hàng. Tuy nhiên, các bitmap này thường chứa rất nhiều số không (chúng ta gọi là chúng thưa). Trong trường hợp đó, các bitmap có thể được mã hóa thêm bằng run-length encoding (mã hóa độ dài chuỗi lặp): đếm số lượng số không hoặc số một liên tiếp và lưu trữ số đó, như được hiển thị ở phần dưới của Hình 4-8. Các kỹ thuật như roaring bitmaps chuyển đổi giữa hai biểu diễn bitmap, sử dụng cái nào gọn nhất 73. Điều này có thể làm cho việc mã hóa một cột trở nên cực kỳ hiệu quả.
Các bitmap index như vậy rất phù hợp cho các loại truy vấn phổ biến trong data warehouse. Ví dụ:
WHERE product_sk IN (31, 68, 69):- Tải ba bitmap cho
product_sk = 31,product_sk = 68vàproduct_sk = 69, và tính toán bitwise OR của ba bitmap, điều này có thể được thực hiện rất hiệu quả. WHERE product_sk = 30 AND store_sk = 3:- Tải bitmap cho
product_sk = 30vàstore_sk = 3, và tính toán bitwise AND. Điều này hoạt động vì các cột chứa các hàng theo cùng thứ tự, vì vậy bit thứ k trong bitmap của một cột tương ứng với cùng hàng như bit thứ k trong bitmap của cột khác.
Bitmap cũng có thể được dùng để trả lời các truy vấn đồ thị, chẳng hạn như tìm tất cả người dùng của một mạng xã hội được theo dõi bởi người dùng X và cũng theo dõi người dùng Y 74. Còn có nhiều lược đồ nén khác nhau cho các cơ sở dữ liệu columnar, bạn có thể tìm thấy trong các tài liệu tham khảo 75.
Note
Đừng nhầm lẫn cơ sở dữ liệu column-oriented với mô hình dữ liệu wide-column (còn được gọi là column-family), trong đó một hàng có thể có hàng nghìn cột, và không yêu cầu tất cả các hàng phải có cùng cột 9. Mặc dù tên gọi tương tự, cơ sở dữ liệu wide-column là row-oriented, vì chúng lưu trữ tất cả giá trị từ một hàng cùng nhau. Bigtable của Google, Apache Accumulo và HBase là các ví dụ về mô hình wide-column.
Thứ Tự Sắp Xếp Trong Lưu Trữ Cột
Trong một column store, thứ tự lưu trữ các hàng không nhất thiết phải quan trọng. Dễ nhất là lưu trữ chúng theo thứ tự chúng được chèn vào, vì khi đó việc chèn một hàng mới chỉ có nghĩa là thêm vào cuối mỗi cột. Tuy nhiên, chúng ta có thể chọn áp đặt một thứ tự, như chúng ta đã làm với SSTable trước đó, và dùng đó làm cơ chế lập chỉ mục.
Lưu ý rằng việc sắp xếp từng cột một cách độc lập sẽ không có ý nghĩa, vì khi đó chúng ta sẽ không còn biết những mục nào trong các cột thuộc cùng một hàng. Chúng ta chỉ có thể tái tạo một hàng vì chúng ta biết rằng mục thứ k trong một cột thuộc cùng hàng với mục thứ k trong cột khác.
Thay vào đó, dữ liệu cần được sắp xếp theo từng hàng hoàn chỉnh, mặc dù nó được lưu trữ theo cột.
Quản trị viên cơ sở dữ liệu có thể chọn các cột mà bảng cần được sắp xếp theo, dựa trên
kiến thức về các truy vấn phổ biến. Ví dụ, nếu các truy vấn thường nhắm vào các khoảng ngày, chẳng hạn như
tháng trước, việc đặt date_key làm khóa sắp xếp đầu tiên có thể hợp lý. Sau đó truy vấn có thể
chỉ quét các hàng từ tháng trước, sẽ nhanh hơn nhiều so với quét tất cả các hàng.
Một cột thứ hai có thể xác định thứ tự sắp xếp của các hàng có cùng giá trị trong cột đầu tiên.
Ví dụ, nếu date_key là khóa sắp xếp đầu tiên trong Hình 4-7, thì
product_sk có thể là khóa sắp xếp thứ hai để tất cả các giao dịch bán hàng cùng sản phẩm trong cùng
ngày được nhóm lại trong lưu trữ. Điều đó sẽ giúp các truy vấn cần nhóm hoặc lọc giao dịch bán hàng theo
sản phẩm trong một khoảng ngày nhất định.
Một lợi thế khác của thứ tự sắp xếp là nó có thể giúp nén các cột. Nếu cột sắp xếp chính không có nhiều giá trị phân biệt, thì sau khi sắp xếp, nó sẽ có các chuỗi dài mà cùng một giá trị lặp lại nhiều lần liên tiếp. Một run-length encoding đơn giản, như chúng ta đã dùng cho các bitmap trong Hình 4-8, có thể nén cột đó xuống còn vài kilobyte, ngay cả khi bảng có hàng tỷ hàng.
Hiệu ứng nén đó mạnh nhất ở khóa sắp xếp đầu tiên. Khóa sắp xếp thứ hai và thứ ba sẽ lộn xộn hơn, và do đó không có các chuỗi dài của giá trị lặp lại. Các cột ở vị trí thấp hơn trong ưu tiên sắp xếp xuất hiện về cơ bản theo thứ tự ngẫu nhiên, vì vậy chúng có thể sẽ không nén tốt. Nhưng việc sắp xếp một vài cột đầu tiên vẫn là lợi ích tổng thể.
Ghi Vào Lưu Trữ Column-Oriented
Chúng ta đã thấy trong “Characterizing Transaction Processing and Analytics” rằng các thao tác đọc trong data warehouse thường bao gồm các phép tổng hợp trên số lượng lớn hàng; lưu trữ column-oriented, nén và sắp xếp đều giúp làm cho các truy vấn đọc đó nhanh hơn. Các thao tác ghi trong data warehouse thường là nhập dữ liệu hàng loạt, thường qua quy trình ETL.
Với lưu trữ columnar, việc ghi một hàng riêng lẻ vào giữa một bảng đã sắp xếp sẽ rất kém hiệu quả, vì bạn sẽ phải viết lại tất cả các cột đã nén từ vị trí chèn trở đi. Tuy nhiên, việc ghi hàng loạt nhiều hàng cùng lúc san đều chi phí của việc viết lại các cột đó, làm cho nó hiệu quả.
Một phương pháp log-structured thường được sử dụng để thực hiện ghi theo lô. Tất cả các thao tác ghi trước tiên đi vào một cửa hàng in-memory được sắp xếp theo hàng. Khi đủ lượng ghi đã tích lũy, chúng được hợp nhất với các tệp được mã hóa cột trên đĩa và ghi vào các tệp mới theo lô. Vì các tệp cũ vẫn bất biến, và các tệp mới được ghi trong một lần, object storage rất phù hợp để lưu trữ các tệp này.
Các truy vấn cần kiểm tra cả dữ liệu cột trên đĩa lẫn các thao tác ghi gần đây trong bộ nhớ, và kết hợp cả hai. Query execution engine (bộ máy thực thi truy vấn) ẩn sự phân biệt này khỏi người dùng. Từ góc độ của một nhà phân tích, dữ liệu đã được sửa đổi bằng các lệnh insert, update hoặc delete sẽ được phản ánh ngay lập tức trong các truy vấn tiếp theo. Snowflake, Vertica, Apache Pinot, Apache Druid và nhiều hệ thống khác thực hiện điều này 61 63 64 76.
Thực Thi Truy Vấn: Biên Dịch và Vector Hóa
Một truy vấn SQL phức tạp cho phân tích được chia nhỏ thành một query plan (kế hoạch truy vấn) gồm nhiều giai đoạn, được gọi là operator (toán tử), có thể được phân tán trên nhiều máy để thực thi song song. Các query planner có thể thực hiện nhiều tối ưu hóa bằng cách chọn operator nào sẽ sử dụng, theo thứ tự nào để thực hiện chúng và nơi chạy từng operator.
Trong mỗi operator, query engine cần thực hiện nhiều thao tác khác nhau với các giá trị trong một cột, chẳng hạn như tìm tất cả các hàng mà giá trị nằm trong một tập giá trị cụ thể (có thể là một phần của phép join), hoặc kiểm tra xem giá trị có lớn hơn 15 không. Nó cũng cần xem xét nhiều cột cho cùng một hàng, ví dụ để tìm tất cả các giao dịch bán hàng mà sản phẩm là chuối và cửa hàng là một cửa hàng cụ thể.
Đối với các truy vấn data warehouse cần quét qua hàng triệu hàng, chúng ta cần lo lắng không chỉ về lượng dữ liệu cần đọc từ đĩa, mà còn về thời gian CPU cần thiết để thực thi các operator phức tạp. Loại operator đơn giản nhất giống như một trình thông dịch cho ngôn ngữ lập trình: trong khi lặp qua từng hàng, nó kiểm tra một cấu trúc dữ liệu đại diện cho truy vấn để tìm ra những so sánh hoặc tính toán nào cần thực hiện trên những cột nào. Thật không may, điều này quá chậm cho nhiều mục đích phân tích. Hai cách tiếp cận thay thế để thực thi truy vấn hiệu quả đã xuất hiện 77:
- Query compilation (Biên dịch truy vấn)
- Query engine lấy câu truy vấn SQL và tạo ra mã để thực thi nó. Mã lặp qua các hàng từng cái một, xem xét các giá trị trong các cột cần quan tâm, thực hiện bất kỳ so sánh hoặc tính toán nào cần thiết và sao chép các giá trị cần thiết vào output buffer nếu các điều kiện yêu cầu được thỏa mãn. Query engine biên dịch mã được tạo ra thành machine code (mã máy) (thường sử dụng compiler hiện có như LLVM), sau đó chạy nó trên dữ liệu được mã hóa cột đã được tải vào bộ nhớ. Cách tiếp cận sinh mã này tương tự với cách tiếp cận biên dịch just-in-time (JIT) được sử dụng trong Java Virtual Machine (JVM) và các runtime tương tự.
- Vectorized processing (Xử lý vector hóa)
- Truy vấn được thông dịch, không biên dịch, nhưng được làm nhanh bằng cách xử lý nhiều giá trị từ một cột trong một lô, thay vì lặp qua từng hàng một. Một tập cố định các operator định sẵn được tích hợp vào cơ sở dữ liệu; chúng ta có thể truyền đối số cho chúng và nhận lại một lô kết quả 50 75.
Ví dụ, chúng ta có thể truyền cột product_sk và ID của “chuối” cho một equality operator (toán tử đẳng thức),
và nhận lại một bitmap (một bit cho mỗi giá trị trong cột đầu vào, là 1 nếu đó là chuối); sau đó chúng ta có thể
truyền cột store_sk và ID của cửa hàng cần quan tâm cho cùng equality operator,
và nhận lại một bitmap khác; rồi chúng ta có thể truyền hai bitmap cho một operator “bitwise AND”, như
được hiển thị trong Hình 4-9. Kết quả sẽ là một bitmap chứa số 1 cho tất cả các giao dịch bán chuối trong
một cửa hàng cụ thể.

Hai cách tiếp cận rất khác nhau về mặt triển khai, nhưng cả hai đều được sử dụng trong thực tế 77. Cả hai đều có thể đạt được hiệu năng rất tốt bằng cách tận dụng các đặc điểm của CPU hiện đại:
- ưu tiên truy cập bộ nhớ tuần tự hơn truy cập ngẫu nhiên để giảm cache miss 78,
- thực hiện hầu hết công việc trong các vòng lặp bên trong chặt chẽ (tức là với số lượng lệnh nhỏ và không có lời gọi hàm) để giữ cho pipeline xử lý lệnh CPU bận rộn và tránh misprediction nhánh,
- sử dụng tính song song như nhiều luồng và lệnh single-instruction-multi-data (SIMD) 79 80, và
- hoạt động trực tiếp trên dữ liệu đã nén mà không cần giải mã nó thành một biểu diễn in-memory riêng biệt, điều này tiết kiệm chi phí cấp phát bộ nhớ và sao chép.
Materialized View và Data Cube
Chúng ta đã gặp materialized view (khung nhìn vật hóa) trong “Materializing and Updating Timelines”: trong mô hình dữ liệu quan hệ, chúng là đối tượng giống bảng mà nội dung là kết quả của một số truy vấn. Điểm khác biệt là materialized view là một bản sao thực sự của kết quả truy vấn, được ghi vào đĩa, trong khi virtual view (khung nhìn ảo) chỉ là một cách viết tắt cho các câu truy vấn. Khi bạn đọc từ một virtual view, SQL engine mở rộng nó thành truy vấn cơ bản của view ngay lập tức rồi xử lý truy vấn đã mở rộng.
Khi dữ liệu cơ bản thay đổi, một materialized view cần được cập nhật tương ứng. Một số cơ sở dữ liệu có thể làm điều đó tự động, và cũng có các hệ thống như Materialize chuyên về duy trì materialized view 81. Thực hiện các cập nhật như vậy có nghĩa là nhiều công việc hơn khi ghi, nhưng materialized view có thể cải thiện hiệu năng đọc trong các khối lượng công việc cần thực hiện lặp đi lặp lại cùng một truy vấn.
Materialized aggregate (tổng hợp vật hóa) là một loại materialized view có thể hữu ích trong data warehouse. Như
đã thảo luận trước đó, các truy vấn data warehouse thường liên quan đến hàm tổng hợp, chẳng hạn như COUNT, SUM,
AVG, MIN hoặc MAX trong SQL. Nếu cùng một phép tổng hợp được sử dụng bởi nhiều truy vấn khác nhau, việc xử lý dữ liệu thô mỗi lần có thể lãng phí. Tại sao không cache một số các giá trị đếm hoặc tổng mà
các truy vấn sử dụng thường xuyên nhất? Một data cube hay OLAP cube thực hiện điều này bằng cách tạo ra một lưới các phép tổng hợp được nhóm theo các chiều khác nhau 82.
Hình 4-10 cho thấy một ví dụ.
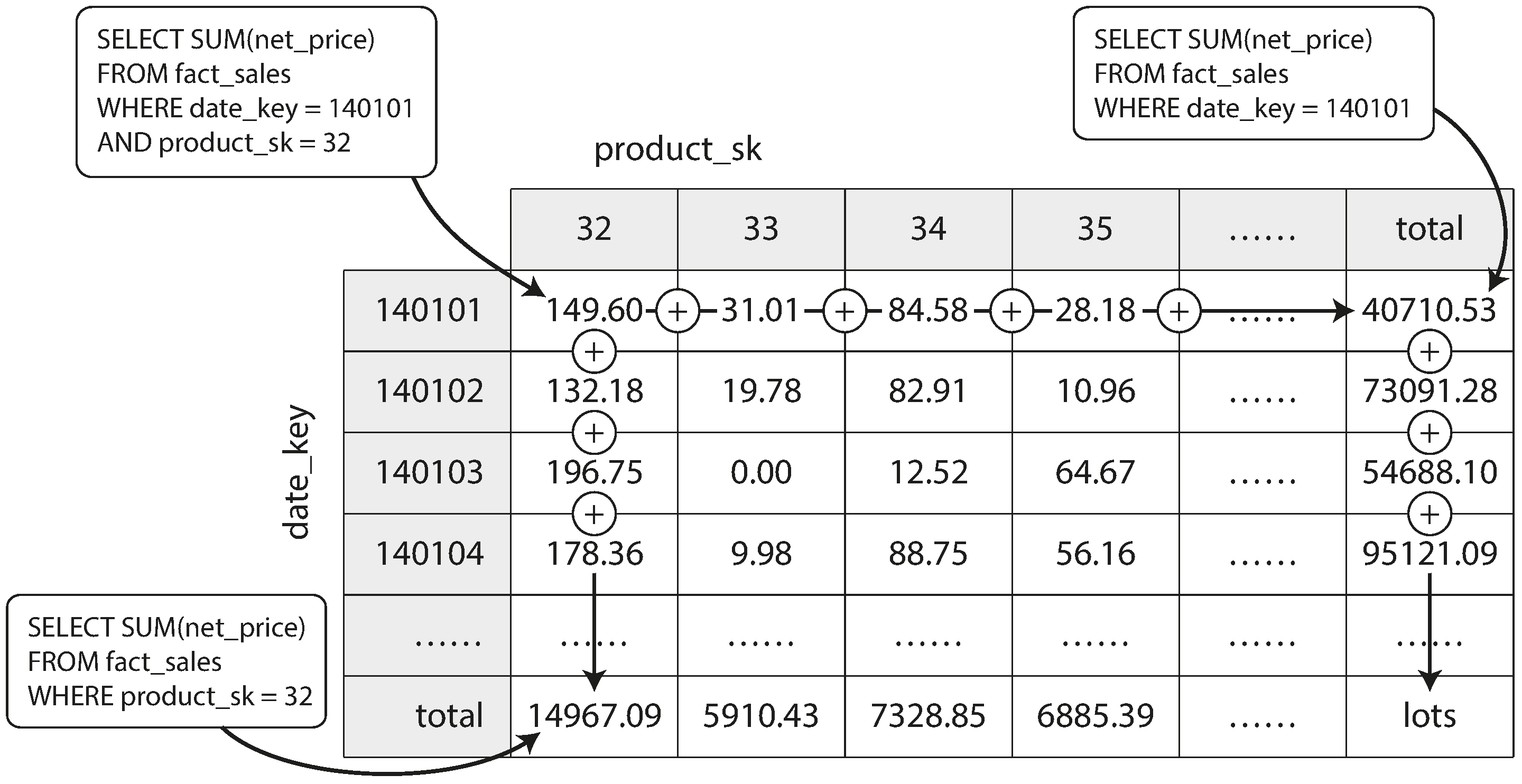
Hãy tưởng tượng rằng mỗi fact (sự kiện) chỉ có khóa ngoại đến đúng hai dimension table (bảng chiều), cụ thể trong Hình 4-10
là date_key và product_sk. Khi đó ta có thể vẽ một bảng hai chiều, với
ngày tháng dọc theo một trục và sản phẩm dọc theo trục kia. Mỗi ô chứa giá trị tổng hợp (ví dụ SUM) của
một thuộc tính (ví dụ net_price) của tất cả các fact có tổ hợp ngày-sản phẩm tương ứng. Sau đó ta có thể áp dụng
cùng phép tổng hợp dọc theo mỗi hàng hoặc cột để thu được một bản tóm tắt đã bị rút gọn đi một
chiều (doanh số theo sản phẩm bất kể ngày tháng, hoặc doanh số theo ngày bất kể sản phẩm).
Nhìn chung, các fact thường có hơn hai chiều. Trong Hình 3-5 có năm chiều: ngày tháng, sản phẩm, cửa hàng, khuyến mãi và khách hàng. Thật khó để hình dung một hypercube (siêu khối) năm chiều trông như thế nào, nhưng nguyên tắc vẫn giống nhau: mỗi ô chứa doanh số của một tổ hợp ngày-sản phẩm-cửa hàng-khuyến mãi-khách hàng cụ thể. Các giá trị này sau đó có thể được tóm tắt lặp đi lặp lại theo từng chiều.
Ưu điểm của materialized data cube (khối dữ liệu được vật thể hóa) là một số truy vấn trở nên rất nhanh vì chúng thực chất đã được tính toán trước. Ví dụ, nếu bạn muốn biết tổng doanh số theo cửa hàng trong ngày hôm qua, bạn chỉ cần nhìn vào tổng dọc theo chiều phù hợp, không cần quét hàng triệu bản ghi.
Nhược điểm là data cube không có tính linh hoạt như khi truy vấn dữ liệu thô. Ví dụ, không có cách nào tính được tỷ lệ doanh số đến từ các mặt hàng có giá hơn 100 đô la, vì giá cả không phải một trong các chiều. Do đó, hầu hết data warehouse đều cố giữ lại nhiều dữ liệu thô nhất có thể, và chỉ dùng các tổng hợp như data cube để tăng hiệu suất cho một số truy vấn nhất định.
Chỉ Mục Đa Chiều và Tìm Kiếm Toàn Văn
Các B-tree và LSM-tree mà chúng ta đã thấy trong nửa đầu chương này cho phép truy vấn phạm vi trên một thuộc tính duy nhất: ví dụ, nếu khóa là tên người dùng, bạn có thể dùng chúng làm chỉ mục để tìm hiệu quả tất cả các tên bắt đầu bằng chữ L. Nhưng đôi khi, tìm kiếm theo một thuộc tính duy nhất là chưa đủ.
Loại chỉ mục nhiều cột phổ biến nhất được gọi là concatenated index (chỉ mục nối ghép), đơn giản là kết hợp nhiều trường thành một khóa bằng cách nối các cột lại với nhau (định nghĩa chỉ mục xác định thứ tự ghép nối các trường). Điều này giống như một cuốn danh bạ điện thoại giấy truyền thống, vốn cung cấp chỉ mục từ (họ, tên) đến số điện thoại. Do thứ tự sắp xếp, chỉ mục có thể dùng để tìm tất cả những người có họ cụ thể, hoặc tất cả những người có tổ hợp họ-tên cụ thể. Tuy nhiên, chỉ mục này vô dụng nếu bạn muốn tìm tất cả những người có tên riêng cụ thể.
Mặt khác, multi-dimensional index (chỉ mục đa chiều) cho phép truy vấn nhiều cột cùng một lúc. Một trường hợp mà điều này đặc biệt quan trọng là dữ liệu địa lý. Ví dụ, một trang web tìm kiếm nhà hàng có thể có cơ sở dữ liệu chứa vĩ độ và kinh độ của mỗi nhà hàng. Khi người dùng đang xem các nhà hàng trên bản đồ, trang web cần tìm tất cả các nhà hàng trong vùng bản đồ hình chữ nhật mà người dùng đang xem. Điều này đòi hỏi một truy vấn phạm vi hai chiều như sau:
SELECT * FROM restaurants WHERE latitude > 51.4946 AND latitude < 51.5079
AND longitude > -0.1162 AND longitude < -0.1004;Một concatenated index trên các cột vĩ độ và kinh độ không thể trả lời loại truy vấn đó một cách hiệu quả: nó có thể cho bạn tất cả các nhà hàng trong một phạm vi vĩ độ (nhưng ở bất kỳ kinh độ nào), hoặc tất cả các nhà hàng trong một phạm vi kinh độ (nhưng ở bất cứ đâu giữa Bắc và Nam cực), nhưng không thể đồng thời cả hai.
Một lựa chọn là chuyển đổi vị trí hai chiều thành một số duy nhất bằng cách dùng space-filling curve (đường cong lấp đầy không gian), sau đó dùng một B-tree index thông thường 83. Phổ biến hơn, các spatial index (chỉ mục không gian) chuyên dụng như R-tree hoặc Bkd-tree 84 được sử dụng; chúng phân chia không gian sao cho các điểm dữ liệu gần nhau có xu hướng được nhóm vào cùng một cây con. Ví dụ, PostGIS triển khai chỉ mục địa lý dưới dạng R-tree thông qua cơ chế Generalized Search Tree indexing của PostgreSQL 85. Cũng có thể dùng lưới tam giác, hình vuông, hoặc lục giác đều đặn 86.
Multi-dimensional index không chỉ dành cho vị trí địa lý. Ví dụ, trên một trang thương mại điện tử bạn có thể dùng chỉ mục ba chiều trên các chiều (red, green, blue) để tìm các sản phẩm trong một dải màu nhất định, hoặc trong cơ sở dữ liệu quan trắc thời tiết bạn có thể có một chỉ mục hai chiều trên (date, temperature) để tìm hiệu quả tất cả các quan trắc trong năm 2013 có nhiệt độ từ 25 đến 30℃. Với chỉ mục một chiều, bạn phải hoặc là quét tất cả các bản ghi từ năm 2013 (bất kể nhiệt độ) rồi lọc theo nhiệt độ, hoặc ngược lại. Chỉ mục 2D có thể thu hẹp phạm vi đồng thời theo thời gian và nhiệt độ 87.
Tìm Kiếm Toàn Văn
Full-text search (tìm kiếm toàn văn) cho phép bạn tìm kiếm trong một tập hợp các tài liệu văn bản (trang web, mô tả sản phẩm, v.v.) theo các từ khóa có thể xuất hiện ở bất kỳ đâu trong văn bản 88. Information retrieval (truy hồi thông tin) là một chủ đề lớn, chuyên biệt, thường liên quan đến xử lý ngôn ngữ cụ thể: ví dụ, một số ngôn ngữ châu Á được viết không có khoảng cách hoặc dấu câu giữa các từ, và do đó việc tách văn bản thành các từ đòi hỏi một mô hình cho biết chuỗi ký tự nào tạo thành một từ. Tìm kiếm toàn văn cũng thường liên quan đến việc khớp các từ tương tự nhưng không hoàn toàn giống nhau (chẳng hạn lỗi chính tả hoặc các dạng ngữ pháp khác nhau của từ) và các từ đồng nghĩa. Những vấn đề đó vượt ra ngoài phạm vi của cuốn sách này.
Tuy nhiên, ở mức cốt lõi, bạn có thể nghĩ về tìm kiếm toàn văn như một loại truy vấn đa chiều khác: trong trường hợp này, mỗi từ có thể xuất hiện trong văn bản (một term, tức từ khóa) là một chiều. Một tài liệu chứa term x có giá trị 1 trong chiều x, và một tài liệu không chứa x có giá trị 0. Tìm kiếm các tài liệu nhắc đến “red apples” có nghĩa là một truy vấn tìm kiếm giá trị 1 trong chiều red, và đồng thời giá trị 1 trong chiều apples. Số chiều có thể rất lớn.
Cấu trúc dữ liệu mà nhiều search engine (công cụ tìm kiếm) dùng để trả lời các truy vấn như vậy được gọi là inverted index (chỉ mục ngược). Đây là cấu trúc key-value trong đó khóa là một term, và giá trị là danh sách các ID của tất cả các tài liệu chứa term đó (the postings list, tức danh sách tài liệu chứa từ). Nếu các ID tài liệu là các số liên tiếp, postings list cũng có thể được biểu diễn dưới dạng sparse bitmap (bitmap thưa), như trong Hình 4-8: bit thứ n trong bitmap của term x là 1 nếu tài liệu có ID n chứa term x 89.
Việc tìm tất cả các tài liệu chứa cả hai term x và y giờ tương tự như một truy vấn data warehouse theo kiểu vectorized tìm các hàng thỏa mãn hai điều kiện (Hình 4-9): tải hai bitmap của term x và y rồi tính phép AND theo bit. Ngay cả khi bitmap được mã hóa run-length, thao tác này có thể được thực hiện rất hiệu quả.
Ví dụ, Lucene, công cụ đánh chỉ mục toàn văn được dùng bởi Elasticsearch và Solr, hoạt động theo cách này 90. Nó lưu trữ ánh xạ từ term đến postings list trong các tệp sắp xếp theo kiểu SSTable, được hợp nhất ở nền bằng cách tiếp cận log-structured tương tự như chúng ta đã thấy trước đó trong chương này 91. Kiểu chỉ mục GIN của PostgreSQL cũng dùng postings list để hỗ trợ tìm kiếm toàn văn và đánh chỉ mục bên trong các tài liệu JSON 92 93.
Thay vì tách văn bản thành các từ, một cách thay thế là tìm tất cả các chuỗi con có độ dài n,
gọi là n-gram. Ví dụ, các trigram (n = 3) của chuỗi
"hello" là "hel", "ell", và "llo". Nếu ta xây dựng inverted index của tất cả trigram, ta có thể
tìm kiếm trong các tài liệu theo bất kỳ chuỗi con nào dài ít nhất ba ký tự. Trigram
index thậm chí cho phép sử dụng biểu thức chính quy trong các truy vấn tìm kiếm; nhược điểm là chúng khá lớn 94.
Để xử lý lỗi chính tả trong tài liệu hoặc truy vấn, Lucene có thể tìm kiếm văn bản theo các từ trong một khoảng edit distance (khoảng cách chỉnh sửa) nhất định (edit distance bằng 1 có nghĩa là một chữ cái đã được thêm, xóa hoặc thay thế) 95. Nó thực hiện điều này bằng cách lưu trữ tập hợp các term dưới dạng finite state automaton (ô-tô-mát trạng thái hữu hạn) trên các ký tự trong khóa, tương tự như trie 96, và biến đổi nó thành Levenshtein automaton, hỗ trợ tìm kiếm hiệu quả các từ trong một khoảng edit distance cho trước 97.
Vector Embedding
Semantic search (tìm kiếm ngữ nghĩa) vượt ra ngoài từ đồng nghĩa và lỗi chính tả để cố gắng hiểu các khái niệm trong tài liệu và ý định của người dùng. Ví dụ, nếu trang trợ giúp của bạn chứa một trang có tiêu đề “cancelling your subscription” (hủy đăng ký), người dùng vẫn có thể tìm thấy trang đó khi tìm kiếm “how to close my account” (làm thế nào để đóng tài khoản) hoặc “terminate contract” (chấm dứt hợp đồng), vốn gần nghĩa nhau dù dùng các từ hoàn toàn khác nhau.
Để hiểu ngữ nghĩa của một tài liệu, tức ý nghĩa của nó, các search engine ngữ nghĩa dùng embedding model (mô hình nhúng) để dịch một tài liệu thành một vector (vectơ) các giá trị dấu phẩy động, gọi là vector embedding (vectơ nhúng). Vector biểu diễn một điểm trong không gian đa chiều, và mỗi giá trị dấu phẩy động biểu diễn vị trí của tài liệu dọc theo trục của một chiều. Các embedding model tạo ra các vector embedding gần nhau (trong không gian đa chiều này) khi các tài liệu đầu vào của chúng có ngữ nghĩa tương tự nhau.
Note
We saw the term vectorized processing in “Query Execution: Compilation and Vectorization”. Vectors in semantic search have a different meaning. In vectorized processing, the vector refers to a batch of bits that can be processed with specially optimized code. In embedding models, vectors are a list of floating point numbers that represent a location in multi-dimensional space.
Ví dụ, một vector embedding ba chiều cho một trang Wikipedia về nông nghiệp có thể là
[0.1, 0.22, 0.11]. Một trang Wikipedia về rau củ sẽ khá gần, có thể với embedding
là [0.13, 0.19, 0.24]. Một trang về star schema có thể có embedding là [0.82, 0.39, -0.74],
tương đối xa. Nhìn vào là ta có thể thấy hai vector đầu gần nhau hơn vector thứ ba.
Các embedding model dùng vector lớn hơn nhiều (thường hơn 1.000 con số), nhưng các nguyên tắc vẫn giống nhau. Ta không cố gắng hiểu ý nghĩa của từng con số; chúng đơn giản là cách để các embedding model chỉ đến một vị trí trong không gian đa chiều trừu tượng. Search engine dùng các hàm khoảng cách như cosine similarity (độ tương đồng cosine) hoặc Euclidean distance (khoảng cách Euclid) để đo khoảng cách giữa các vector. Cosine similarity đo cosin của góc giữa hai vector để xác định mức độ gần của chúng, trong khi Euclidean distance đo khoảng cách đường thẳng giữa hai điểm trong không gian.
Nhiều embedding model đầu tiên như Word2Vec 98, BERT 99, và GPT 100 làm việc với dữ liệu văn bản. Các mô hình như vậy thường được triển khai dưới dạng mạng nơ-ron. Các nhà nghiên cứu tiếp tục tạo ra các embedding model cho video, âm thanh, và hình ảnh. Gần đây hơn, kiến trúc mô hình đã trở nên multimodal (đa phương thức): một mô hình duy nhất có thể tạo ra vector embedding cho nhiều loại dữ liệu như văn bản và hình ảnh.
Các search engine ngữ nghĩa dùng embedding model để tạo ra vector embedding khi người dùng nhập một truy vấn. Truy vấn của người dùng và ngữ cảnh liên quan (chẳng hạn vị trí của người dùng) được đưa vào embedding model. Sau khi embedding model tạo ra vector embedding của truy vấn, search engine phải tìm các tài liệu có vector embedding tương tự bằng cách dùng vector index (chỉ mục vectơ).
Vector index lưu trữ các vector embedding của một tập hợp tài liệu. Để truy vấn chỉ mục, bạn truyền vào vector embedding của truy vấn, và chỉ mục trả về các tài liệu có vector gần nhất với vector truy vấn. Vì các R-tree mà chúng ta đã thấy trước đây không hoạt động tốt với các vector có nhiều chiều, các vector index chuyên dụng được sử dụng, chẳng hạn:
- Flat index
- Các vector được lưu trong chỉ mục nguyên trạng. Một truy vấn phải đọc mọi vector và đo khoảng cách của nó đến vector truy vấn. Flat index chính xác, nhưng việc đo khoảng cách giữa truy vấn và từng vector thì chậm.
- Inverted file (IVF) index
- Không gian vector được phân cụm thành các phân vùng (gọi là centroid, tâm cụm) của các vector để giảm số vector cần so sánh. IVF index nhanh hơn flat index, nhưng chỉ có thể cho kết quả gần đúng: truy vấn và một tài liệu có thể rơi vào các phân vùng khác nhau dù chúng gần nhau. Một truy vấn trên IVF index trước tiên xác định probe (lần thử), đơn giản là số phân vùng cần kiểm tra. Các truy vấn dùng nhiều probe hơn sẽ chính xác hơn, nhưng sẽ chậm hơn vì phải so sánh nhiều vector hơn.
- Hierarchical Navigable Small World (HNSW)
- HNSW index duy trì nhiều lớp của không gian vector, như minh họa trong Hình 4-11. Mỗi lớp được biểu diễn dưới dạng đồ thị, trong đó các nút biểu diễn vector, và các cạnh biểu diễn sự gần gũi với các vector lân cận. Một truy vấn bắt đầu bằng cách xác định vector gần nhất trong lớp trên cùng, vốn có ít nút. Truy vấn sau đó di chuyển đến cùng nút đó trong lớp phía dưới và đi theo các cạnh trong lớp đó, vốn dày đặc hơn, để tìm vector gần hơn với vector truy vấn. Quá trình tiếp tục cho đến khi đạt lớp cuối cùng. Giống như IVF index, HNSW index cũng cho kết quả gần đúng.
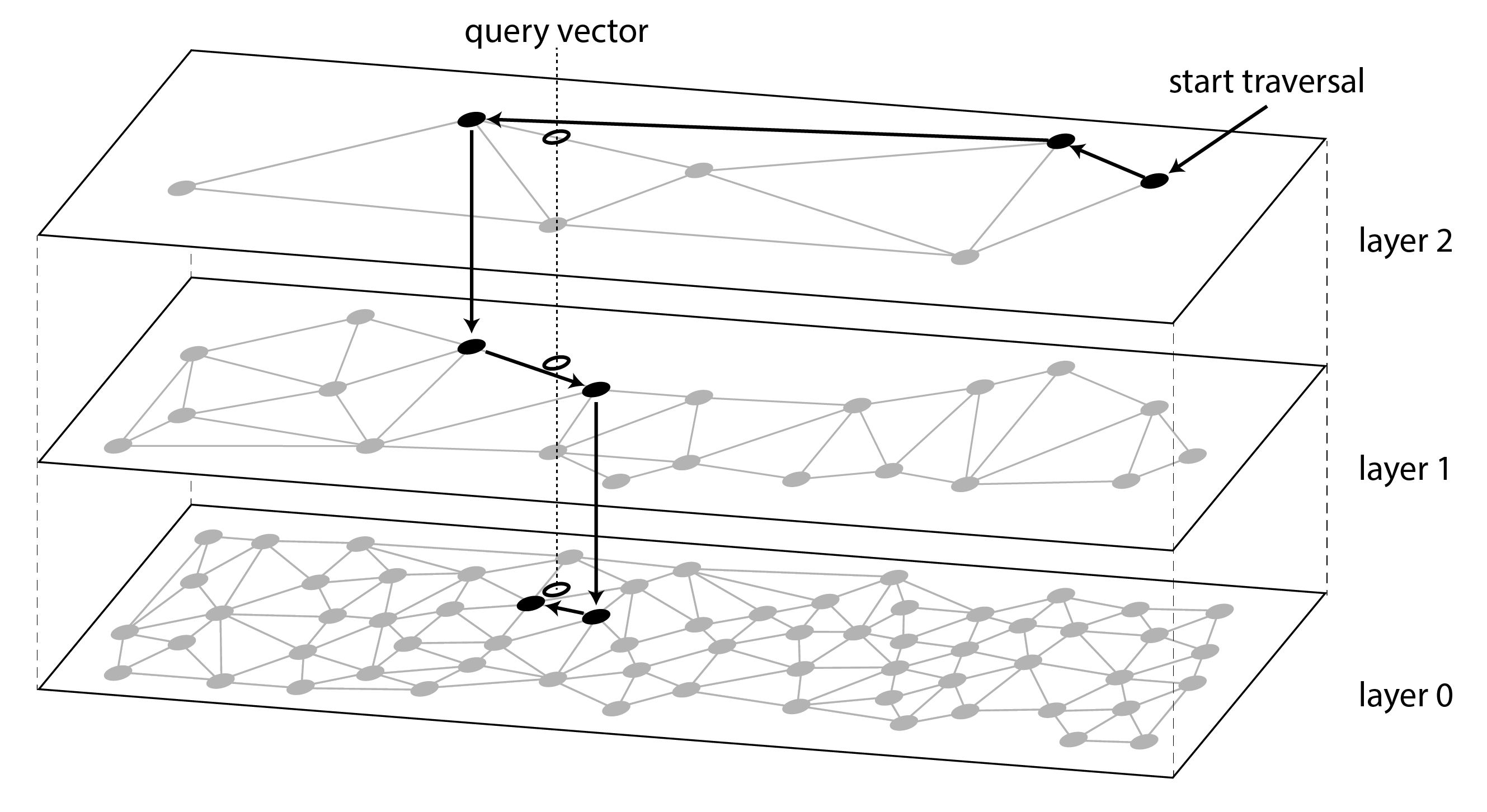
Nhiều vector database phổ biến triển khai IVF và HNSW index. Thư viện Faiss của Facebook có nhiều biến thể của mỗi loại 101, và pgvector của PostgreSQL cũng hỗ trợ cả hai 102. Chi tiết đầy đủ về các thuật toán IVF và HNSW nằm ngoài phạm vi cuốn sách này, nhưng các bài báo gốc là nguồn tài liệu tuyệt vời 103 104.
Tóm Tắt
Trong chương này, chúng ta đã cố gắng tìm hiểu tận cùng cách các cơ sở dữ liệu thực hiện lưu trữ và truy hồi. Điều gì xảy ra khi bạn lưu dữ liệu vào cơ sở dữ liệu, và cơ sở dữ liệu làm gì khi bạn truy vấn lại dữ liệu đó sau này?
“Analytical versus Operational Systems” đã giới thiệu sự phân biệt giữa transaction processing (xử lý giao dịch, OLTP) và analytics (phân tích, OLAP). Trong chương này, chúng ta thấy rằng các storage engine được tối ưu cho OLTP trông rất khác so với những engine được tối ưu cho analytics:
- Các hệ thống OLTP được tối ưu cho khối lượng lớn các yêu cầu, mỗi yêu cầu đọc và ghi một số ít bản ghi, và cần phản hồi nhanh. Các bản ghi thường được truy cập qua primary key (khóa chính) hoặc secondary index (chỉ mục phụ), và các chỉ mục này thường là ánh xạ có thứ tự từ khóa đến bản ghi, cũng hỗ trợ truy vấn phạm vi.
- Data warehouse và các hệ thống phân tích tương tự được tối ưu cho các truy vấn đọc phức tạp quét qua số lượng lớn bản ghi. Chúng thường dùng column-oriented storage layout (cách lưu trữ theo cột) với nén để giảm thiểu lượng dữ liệu mà truy vấn cần đọc từ đĩa, và biên dịch just-in-time các truy vấn hoặc vectorization để giảm thiểu thời gian CPU dành cho xử lý dữ liệu.
Về phía OLTP, chúng ta đã thấy các storage engine từ hai trường phái chính:
- Cách tiếp cận log-structured, chỉ cho phép thêm vào các tệp và xóa các tệp lỗi thời, nhưng không bao giờ cập nhật một tệp đã được ghi. SSTables, LSM-tree, RocksDB, Cassandra, HBase, Scylla, Lucene và các hệ thống khác thuộc nhóm này. Nhìn chung, storage engine theo kiểu log-structured có xu hướng cung cấp thông lượng ghi cao.
- Cách tiếp cận update-in-place (cập nhật tại chỗ), vốn coi đĩa là tập hợp các trang có kích thước cố định có thể bị ghi đè. B-tree, ví dụ điển hình nhất của triết lý này, được dùng trong tất cả các cơ sở dữ liệu quan hệ OLTP lớn và cũng nhiều cơ sở dữ liệu phi quan hệ. Theo nguyên tắc chung, B-tree có xu hướng tốt hơn cho đọc, cung cấp thông lượng đọc cao hơn và thời gian phản hồi thấp hơn so với lưu trữ log-structured.
Sau đó, chúng ta xem xét các chỉ mục có thể tìm kiếm theo nhiều điều kiện cùng một lúc: multidimensional index như R-tree có thể tìm kiếm các điểm trên bản đồ theo vĩ độ và kinh độ cùng lúc, và full-text search index có thể tìm kiếm nhiều từ khóa xuất hiện trong cùng một văn bản. Cuối cùng, vector database được dùng cho semantic search trên các tài liệu văn bản và phương tiện khác; chúng dùng các vector với số chiều lớn hơn và tìm các tài liệu tương tự bằng cách so sánh độ tương đồng vector.
Với tư cách là một nhà phát triển ứng dụng, nếu bạn được trang bị kiến thức về cấu trúc bên trong của các storage engine, bạn sẽ ở vị trí tốt hơn để biết công cụ nào phù hợp nhất với ứng dụng cụ thể của mình. Nếu bạn cần điều chỉnh các tham số tuning của cơ sở dữ liệu, sự hiểu biết này cho phép bạn hình dung được hiệu ứng mà một giá trị cao hơn hoặc thấp hơn có thể mang lại.
Mặc dù chương này không thể biến bạn thành chuyên gia về tuning bất kỳ storage engine cụ thể nào, nhưng hy vọng nó đã trang bị cho bạn đủ từ vựng và ý tưởng để bạn có thể hiểu được tài liệu của cơ sở dữ liệu mà bạn chọn.
References
Nikolay Samokhvalov. How partial, covering, and multicolumn indexes may slow down UPDATEs in PostgreSQL. postgres.ai, October 2021. Archived at perma.cc/PBK3-F4G9 ↩︎
Goetz Graefe. Modern B-Tree Techniques. Foundations and Trends in Databases, volume 3, issue 4, pages 203–402, August 2011. doi:10.1561/1900000028 ↩︎ ↩︎ ↩︎
Evan Jones. Why databases use ordered indexes but programming uses hash tables. evanjones.ca, December 2019. Archived at perma.cc/NJX8-3ZZD ↩︎
Branimir Lambov. CEP-25: Trie-indexed SSTable format. cwiki.apache.org, November 2022. Archived at perma.cc/HD7W-PW8U. Linked Google Doc archived at perma.cc/UL6C-AAAE ↩︎
Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein: Introduction to Algorithms, 3rd edition. MIT Press, 2009. ISBN: 978-0-262-53305-8 ↩︎ ↩︎ ↩︎
Branimir Lambov. Trie Memtables in Cassandra. Proceedings of the VLDB Endowment, volume 15, issue 12, pages 3359–3371, August 2022. doi:10.14778/3554821.3554828 ↩︎
Dhruba Borthakur. The History of RocksDB. rocksdb.blogspot.com, November 2013. Archived at perma.cc/Z7C5-JPSP ↩︎
Matteo Bertozzi. Apache HBase I/O – HFile. blog.cloudera.com, June 2012. Archived at perma.cc/U9XH-L2KL ↩︎
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber. Bigtable: A Distributed Storage System for Structured Data. At 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006. ↩︎ ↩︎
Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. The Log-Structured Merge-Tree (LSM-Tree). Acta Informatica, volume 33, issue 4, pages 351–385, June 1996. doi:10.1007/s002360050048 ↩︎
Mendel Rosenblum and John K. Ousterhout. The Design and Implementation of a Log-Structured File System. ACM Transactions on Computer Systems, volume 10, issue 1, pages 26–52, February 1992. doi:10.1145/146941.146943 ↩︎
Michael Armbrust, Tathagata Das, Liwen Sun, Burak Yavuz, Shixiong Zhu, Mukul Murthy, Joseph Torres, Herman van Hovell, Adrian Ionescu, Alicja Łuszczak, Michał Świtakowski, Michał Szafrański, Xiao Li, Takuya Ueshin, Mostafa Mokhtar, Peter Boncz, Ali Ghodsi, Sameer Paranjpye, Pieter Senster, Reynold Xin, and Matei Zaharia. Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores. Proceedings of the VLDB Endowment, volume 13, issue 12, pages 3411–3424, August 2020. doi:10.14778/3415478.3415560 ↩︎ ↩︎
Burton H. Bloom. Space/Time Trade-offs in Hash Coding with Allowable Errors. Communications of the ACM, volume 13, issue 7, pages 422–426, July 1970. doi:10.1145/362686.362692 ↩︎
Adam Kirsch and Michael Mitzenmacher. Less Hashing, Same Performance: Building a Better Bloom Filter. Random Structures & Algorithms, volume 33, issue 2, pages 187–218, September 2008. doi:10.1002/rsa.20208 ↩︎
Thomas Hurst. Bloom Filter Calculator. hur.st, September 2023. Archived at perma.cc/L3AV-6VC2 ↩︎
Chen Luo and Michael J. Carey. LSM-based storage techniques: a survey. The VLDB Journal, volume 29, pages 393–418, July 2019. doi:10.1007/s00778-019-00555-y ↩︎
Subhadeep Sarkar and Manos Athanassoulis. Dissecting, Designing, and Optimizing LSM-based Data Stores. Tutorial at ACM International Conference on Management of Data (SIGMOD), June 2022. Slides archived at perma.cc/93B3-E827 ↩︎
Mark Callaghan. Name that compaction algorithm. smalldatum.blogspot.com, August 2018. Archived at perma.cc/CN4M-82DY ↩︎
Prashanth Rao. Embedded databases (1): The harmony of DuckDB, KùzuDB and LanceDB. thedataquarry.com, August 2023. Archived at perma.cc/PA28-2R35 ↩︎
Hacker News discussion. Bluesky migrates to single-tenant SQLite. news.ycombinator.com, October 2023. Archived at perma.cc/69LM-5P6X ↩︎
Rudolf Bayer and Edward M. McCreight. Organization and Maintenance of Large Ordered Indices. Boeing Scientific Research Laboratories, Mathematical and Information Sciences Laboratory, report no. 20, July 1970. doi:10.1145/1734663.1734671 ↩︎
Douglas Comer. The Ubiquitous B-Tree. ACM Computing Surveys, volume 11, issue 2, pages 121–137, June 1979. doi:10.1145/356770.356776 ↩︎
Alex Miller. Torn Write Detection and Protection. transactional.blog, April 2025. Archived at perma.cc/G7EB-33EW ↩︎
C. Mohan and Frank Levine. ARIES/IM: An Efficient and High Concurrency Index Management Method Using Write-Ahead Logging. At ACM International Conference on Management of Data (SIGMOD), June 1992. doi:10.1145/130283.130338 ↩︎
Hironobu Suzuki. The Internals of PostgreSQL. interdb.jp, 2017. ↩︎ ↩︎
Howard Chu. LDAP at Lightning Speed. At Build Stuff ‘14, November 2014. Archived at perma.cc/GB6Z-P8YH ↩︎
Manos Athanassoulis, Michael S. Kester, Lukas M. Maas, Radu Stoica, Stratos Idreos, Anastasia Ailamaki, and Mark Callaghan. Designing Access Methods: The RUM Conjecture. At 19th International Conference on Extending Database Technology (EDBT), March 2016. doi:10.5441/002/edbt.2016.42 ↩︎
Ben Stopford. Log Structured Merge Trees. benstopford.com, February 2015. Archived at perma.cc/E5BV-KUJ6 ↩︎
Mark Callaghan. The Advantages of an LSM vs a B-Tree. smalldatum.blogspot.co.uk, January 2016. Archived at perma.cc/3TYZ-EFUD ↩︎
Oana Balmau, Florin Dinu, Willy Zwaenepoel, Karan Gupta, Ravishankar Chandhiramoorthi, and Diego Didona. SILK: Preventing Latency Spikes in Log-Structured Merge Key-Value Stores. At USENIX Annual Technical Conference, July 2019. ↩︎
Igor Canadi, Siying Dong, Mark Callaghan, et al. RocksDB Tuning Guide. github.com, 2023. Archived at perma.cc/UNY4-MK6C ↩︎
Gabriel Haas and Viktor Leis. What Modern NVMe Storage Can Do, and How to Exploit it: High-Performance I/O for High-Performance Storage Engines. Proceedings of the VLDB Endowment, volume 16, issue 9, pages 2090-2102. doi:10.14778/3598581.3598584 ↩︎
Emmanuel Goossaert. Coding for SSDs. codecapsule.com, February 2014. ↩︎
Jack Vanlightly. Is sequential IO dead in the era of the NVMe drive? jack-vanlightly.com, May 2023. Archived at perma.cc/7TMZ-TAPU ↩︎
Alibaba Cloud Storage Team. Storage System Design Analysis: Factors Affecting NVMe SSD Performance (2). alibabacloud.com, January 2019. Archived at archive.org ↩︎
Xiao-Yu Hu and Robert Haas. The Fundamental Limit of Flash Random Write Performance: Understanding, Analysis and Performance Modelling. dominoweb.draco.res.ibm.com, March 2010. Archived at perma.cc/8JUL-4ZDS ↩︎
Lanyue Lu, Thanumalayan Sankaranarayana Pillai, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. WiscKey: Separating Keys from Values in SSD-conscious Storage. At 4th USENIX Conference on File and Storage Technologies (FAST), February 2016. ↩︎
Peter Zaitsev. Innodb Double Write. percona.com, August 2006. Archived at perma.cc/NT4S-DK7T ↩︎
Tomas Vondra. On the Impact of Full-Page Writes. 2ndquadrant.com, November 2016. Archived at perma.cc/7N6B-CVL3 ↩︎
Mark Callaghan. Read, write & space amplification - B-Tree vs LSM. smalldatum.blogspot.com, November 2015. Archived at perma.cc/S487-WK5P ↩︎ ↩︎
Mark Callaghan. Choosing Between Efficiency and Performance with RocksDB. At Code Mesh, November 2016. Video at youtube.com/watch?v=tgzkgZVXKB4 ↩︎
Subhadeep Sarkar, Tarikul Islam Papon, Dimitris Staratzis, Zichen Zhu, and Manos Athanassoulis. Enabling Timely and Persistent Deletion in LSM-Engines. ACM Transactions on Database Systems, volume 48, issue 3, article no. 8, August 2023. doi:10.1145/3599724 ↩︎
Lukas Fittl. Postgres vs. SQL Server: B-Tree Index Differences & the Benefit of Deduplication. pganalyze.com, April 2025. Archived at perma.cc/XY6T-LTPX ↩︎
Drew Silcock. How Postgres stores data on disk – this one’s a page turner. drew.silcock.dev, August 2024. Archived at perma.cc/8K7K-7VJ2 ↩︎
Joe Webb. Using Covering Indexes to Improve Query Performance. simple-talk.com, September 2008. Archived at perma.cc/6MEZ-R5VR ↩︎
Michael Stonebraker, Samuel Madden, Daniel J. Abadi, Stavros Harizopoulos, Nabil Hachem, and Pat Helland. The End of an Architectural Era (It’s Time for a Complete Rewrite). At 33rd International Conference on Very Large Data Bases (VLDB), September 2007. ↩︎
VoltDB Technical Overview White Paper. VoltDB, 2017. Archived at perma.cc/B9SF-SK5G ↩︎
Stephen M. Rumble, Ankita Kejriwal, and John K. Ousterhout. Log-Structured Memory for DRAM-Based Storage. At 12th USENIX Conference on File and Storage Technologies (FAST), February 2014. ↩︎
Stavros Harizopoulos, Daniel J. Abadi, Samuel Madden, and Michael Stonebraker. OLTP Through the Looking Glass, and What We Found There. At ACM International Conference on Management of Data (SIGMOD), June 2008. doi:10.1145/1376616.1376713 ↩︎
Per-Åke Larson, Cipri Clinciu, Campbell Fraser, Eric N. Hanson, Mostafa Mokhtar, Michal Nowakiewicz, Vassilis Papadimos, Susan L. Price, Srikumar Rangarajan, Remus Rusanu, and Mayukh Saubhasik. Enhancements to SQL Server Column Stores. At ACM International Conference on Management of Data (SIGMOD), June 2013. doi:10.1145/2463676.2463708 ↩︎ ↩︎
Franz Färber, Norman May, Wolfgang Lehner, Philipp Große, Ingo Müller, Hannes Rauhe, and Jonathan Dees. The SAP HANA Database – An Architecture Overview. IEEE Data Engineering Bulletin, volume 35, issue 1, pages 28–33, March 2012. ↩︎
Michael Stonebraker. The Traditional RDBMS Wisdom Is (Almost Certainly) All Wrong. Presentation at EPFL, May 2013. ↩︎ ↩︎
Adam Prout, Szu-Po Wang, Joseph Victor, Zhou Sun, Yongzhu Li, Jack Chen, Evan Bergeron, Eric Hanson, Robert Walzer, Rodrigo Gomes, and Nikita Shamgunov. Cloud-Native Transactions and Analytics in SingleStore. At ACM International Conference on Management of Data (SIGMOD), June 2022. doi:10.1145/3514221.3526055 ↩︎
Tino Tereshko and Jordan Tigani. BigQuery under the hood. cloud.google.com, January 2016. Archived at perma.cc/WP2Y-FUCF ↩︎
Wes McKinney. The Road to Composable Data Systems: Thoughts on the Last 15 Years and the Future. wesmckinney.com, September 2023. Archived at perma.cc/6L2M-GTJX ↩︎
Michael Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran, and Stan Zdonik. C-Store: A Column-oriented DBMS. At 31st International Conference on Very Large Data Bases (VLDB), pages 553–564, September 2005. ↩︎
Julien Le Dem. Dremel Made Simple with Parquet. blog.twitter.com, September 2013. ↩︎
Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, and Theo Vassilakis. Dremel: Interactive Analysis of Web-Scale Datasets. At 36th International Conference on Very Large Data Bases (VLDB), pages 330–339, September 2010. doi:10.14778/1920841.1920886 ↩︎
Joe Kearney. Understanding Record Shredding: storing nested data in columns. joekearney.co.uk, December 2016. Archived at perma.cc/ZD5N-AX5D ↩︎
Jamie Brandon. A shallow survey of OLAP and HTAP query engines. scattered-thoughts.net, September 2023. Archived at perma.cc/L3KH-J4JF ↩︎ ↩︎
Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, and Philipp Unterbrunner. The Snowflake Elastic Data Warehouse. At ACM International Conference on Management of Data (SIGMOD), pages 215–226, June 2016. doi:10.1145/2882903.2903741 ↩︎ ↩︎
Mark Raasveldt and Hannes Mühleisen. Data Management for Data Science Towards Embedded Analytics. At 10th Conference on Innovative Data Systems Research (CIDR), January 2020. ↩︎
Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li, and Ravi Aringunram. Pinot: Realtime OLAP for 530 Million Users. At ACM International Conference on Management of Data (SIGMOD), pages 583–594, May 2018. doi:10.1145/3183713.3190661 ↩︎ ↩︎
Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, and Deep Ganguli. Druid: A Real-time Analytical Data Store. At ACM International Conference on Management of Data (SIGMOD), June 2014. doi:10.1145/2588555.2595631 ↩︎ ↩︎
Chunwei Liu, Anna Pavlenko, Matteo Interlandi, and Brandon Haynes. Deep Dive into Common Open Formats for Analytical DBMSs. Proceedings of the VLDB Endowment, volume 16, issue 11, pages 3044–3056, July 2023. doi:10.14778/3611479.3611507 ↩︎ ↩︎
Xinyu Zeng, Yulong Hui, Jiahong Shen, Andrew Pavlo, Wes McKinney, and Huanchen Zhang. An Empirical Evaluation of Columnar Storage Formats. Proceedings of the VLDB Endowment, volume 17, issue 2, pages 148–161. doi:10.14778/3626292.3626298 ↩︎
Weston Pace. Lance v2: A columnar container format for modern data. blog.lancedb.com, April 2024. Archived at perma.cc/ZK3Q-S9VJ ↩︎
Yoav Helfman. Nimble, A New Columnar File Format. At VeloxCon, April 2024. ↩︎
Wes McKinney. Apache Arrow: High-Performance Columnar Data Framework. At CMU Database Group – Vaccination Database Tech Talks, December 2021. ↩︎
Wes McKinney. Python for Data Analysis, 3rd Edition. O’Reilly Media, August 2022. ISBN: 9781098104023 ↩︎
Paul Dix. The Design of InfluxDB IOx: An In-Memory Columnar Database Written in Rust with Apache Arrow. At CMU Database Group – Vaccination Database Tech Talks, May 2021. ↩︎
Carlota Soto and Mike Freedman. Building Columnar Compression for Large PostgreSQL Databases. timescale.com, March 2024. Archived at perma.cc/7KTF-V3EH ↩︎
Daniel Lemire, Gregory Ssi‐Yan‐Kai, and Owen Kaser. Consistently faster and smaller compressed bitmaps with Roaring. Software: Practice and Experience, volume 46, issue 11, pages 1547–1569, November 2016. doi:10.1002/spe.2402 ↩︎
Jaz Volpert. An entire Social Network in 1.6GB (GraphD Part 2). jazco.dev, April 2024. Archived at perma.cc/L27Z-QVMG ↩︎
Daniel J. Abadi, Peter Boncz, Stavros Harizopoulos, Stratos Idreos, and Samuel Madden. The Design and Implementation of Modern Column-Oriented Database Systems. Foundations and Trends in Databases, volume 5, issue 3, pages 197–280, December 2013. doi:10.1561/1900000024 ↩︎ ↩︎
Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, and Chuck Bear. The Vertica Analytic Database: C-Store 7 Years Later. Proceedings of the VLDB Endowment, volume 5, issue 12, pages 1790–1801, August 2012. doi:10.14778/2367502.2367518 ↩︎
Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo, and Peter Boncz. Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask. Proceedings of the VLDB Endowment, volume 11, issue 13, pages 2209–2222, September 2018. doi:10.14778/3275366.3284966 ↩︎ ↩︎
Forrest Smith. Memory Bandwidth Napkin Math. forrestthewoods.com, February 2020. Archived at perma.cc/Y8U4-PS7N ↩︎
Peter Boncz, Marcin Zukowski, and Niels Nes. MonetDB/X100: Hyper-Pipelining Query Execution. At 2nd Biennial Conference on Innovative Data Systems Research (CIDR), January 2005. ↩︎
Jingren Zhou and Kenneth A. Ross. Implementing Database Operations Using SIMD Instructions. At ACM International Conference on Management of Data (SIGMOD), pages 145–156, June 2002. doi:10.1145/564691.564709 ↩︎
Kevin Bartley. OLTP Queries: Transfer Expensive Workloads to Materialize. materialize.com, August 2024. Archived at perma.cc/4TYM-TYD8 ↩︎
Jim Gray, Surajit Chaudhuri, Adam Bosworth, Andrew Layman, Don Reichart, Murali Venkatrao, Frank Pellow, and Hamid Pirahesh. Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals. Data Mining and Knowledge Discovery, volume 1, issue 1, pages 29–53, March 2007. doi:10.1023/A:1009726021843 ↩︎
Frank Ramsak, Volker Markl, Robert Fenk, Martin Zirkel, Klaus Elhardt, and Rudolf Bayer. Integrating the UB-Tree into a Database System Kernel. At 26th International Conference on Very Large Data Bases (VLDB), September 2000. ↩︎
Octavian Procopiuc, Pankaj K. Agarwal, Lars Arge, and Jeffrey Scott Vitter. Bkd-Tree: A Dynamic Scalable kd-Tree. At 8th International Symposium on Spatial and Temporal Databases (SSTD), pages 46–65, July 2003. doi:10.1007/978-3-540-45072-6_4 ↩︎
Joseph M. Hellerstein, Jeffrey F. Naughton, and Avi Pfeffer. Generalized Search Trees for Database Systems. At 21st International Conference on Very Large Data Bases (VLDB), September 1995. ↩︎
Isaac Brodsky. H3: Uber’s Hexagonal Hierarchical Spatial Index. eng.uber.com, June 2018. Archived at archive.org ↩︎
Robert Escriva, Bernard Wong, and Emin Gün Sirer. HyperDex: A Distributed, Searchable Key-Value Store. At ACM SIGCOMM Conference, August 2012. doi:10.1145/2377677.2377681 ↩︎
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. Introduction to Information Retrieval. Cambridge University Press, 2008. ISBN: 978-0-521-86571-5, available online at nlp.stanford.edu/IR-book ↩︎
Jianguo Wang, Chunbin Lin, Yannis Papakonstantinou, and Steven Swanson. An Experimental Study of Bitmap Compression vs. Inverted List Compression. At ACM International Conference on Management of Data (SIGMOD), pages 993–1008, May 2017. doi:10.1145/3035918.3064007 ↩︎
Adrien Grand. What is in a Lucene Index? At Lucene/Solr Revolution, November 2013. Archived at perma.cc/Z7QN-GBYY ↩︎
Michael McCandless. Visualizing Lucene’s Segment Merges. blog.mikemccandless.com, February 2011. Archived at perma.cc/3ZV8-72W6 ↩︎
Lukas Fittl. Understanding Postgres GIN Indexes: The Good and the Bad. pganalyze.com, December 2021. Archived at perma.cc/V3MW-26H6 ↩︎
Jimmy Angelakos. The State of (Full) Text Search in PostgreSQL 12. At FOSDEM, February 2020. Archived at perma.cc/J6US-3WZS ↩︎
Alexander Korotkov. Index support for regular expression search. At PGConf.EU Prague, October 2012. Archived at perma.cc/5RFZ-ZKDQ ↩︎
Michael McCandless. Lucene’s FuzzyQuery Is 100 Times Faster in 4.0. blog.mikemccandless.com, March 2011. Archived at perma.cc/E2WC-GHTW ↩︎
Steffen Heinz, Justin Zobel, and Hugh E. Williams. Burst Tries: A Fast, Efficient Data Structure for String Keys. ACM Transactions on Information Systems, volume 20, issue 2, pages 192–223, April 2002. doi:10.1145/506309.506312 ↩︎
Klaus U. Schulz and Stoyan Mihov. Fast String Correction with Levenshtein Automata. International Journal on Document Analysis and Recognition, volume 5, issue 1, pages 67–85, November 2002. doi:10.1007/s10032-002-0082-8 ↩︎
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. At International Conference on Learning Representations (ICLR), May 2013. doi:10.48550/arXiv.1301.3781 ↩︎
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. At Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, volume 1, pages 4171–4186, June 2019. doi:10.18653/v1/N19-1423 ↩︎
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving Language Understanding by Generative Pre-Training. openai.com, June 2018. Archived at perma.cc/5N3C-DJ4C ↩︎
Matthijs Douze, Maria Lomeli, and Lucas Hosseini. Faiss indexes. github.com, August 2024. Archived at perma.cc/2EWG-FPBS ↩︎
Varik Matevosyan. Understanding pgvector’s HNSW Index Storage in Postgres. lantern.dev, August 2024. Archived at perma.cc/B2YB-JB59 ↩︎
Dmitry Baranchuk, Artem Babenko, and Yury Malkov. Revisiting the Inverted Indices for Billion-Scale Approximate Nearest Neighbors. At European Conference on Computer Vision (ECCV), pages 202–216, September 2018. doi:10.1007/978-3-030-01258-8_13 ↩︎
Yury A. Malkov and Dmitry A. Yashunin. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence, volume 42, issue 4, pages 824–836, April 2020. doi:10.1109/TPAMI.2018.2889473 ↩︎