3. Mô hình dữ liệu và ngôn ngữ truy vấn
Giới hạn của ngôn ngữ tôi chính là giới hạn của thế giới tôi.
Ludwig Wittgenstein, Tractatus Logico-Philosophicus (1922)
Mô hình dữ liệu (data model) có lẽ là phần quan trọng nhất trong quá trình phát triển phần mềm, vì chúng có ảnh hưởng sâu rộng: không chỉ đến cách phần mềm được viết, mà còn đến cách chúng ta suy nghĩ về vấn đề mà mình đang giải quyết.
Hầu hết các ứng dụng được xây dựng bằng cách xếp chồng nhiều lớp mô hình dữ liệu lên nhau. Đối với mỗi lớp, câu hỏi then chốt là: dữ liệu được biểu diễn như thế nào theo lớp ngay bên dưới? Ví dụ:
- Với tư cách là một lập trình viên ứng dụng, bạn nhìn vào thế giới thực (nơi có con người, tổ chức, hàng hóa, hành động, luồng tiền, cảm biến, v.v.) và mô hình hóa chúng thành các đối tượng (object) hoặc cấu trúc dữ liệu (data structure), cùng các API thao tác trên những cấu trúc đó. Những cấu trúc này thường đặc thù với ứng dụng của bạn.
- Khi muốn lưu trữ những cấu trúc dữ liệu đó, bạn biểu diễn chúng theo một mô hình dữ liệu đa năng, chẳng hạn như tài liệu JSON hoặc XML, các bảng trong cơ sở dữ liệu quan hệ, hoặc các đỉnh và cạnh trong đồ thị. Những mô hình dữ liệu này chính là chủ đề của chương này.
- Các kỹ sư xây dựng phần mềm cơ sở dữ liệu của bạn đã quyết định một cách biểu diễn dữ liệu dạng tài liệu/quan hệ/đồ thị đó dưới dạng byte trong bộ nhớ, trên đĩa, hoặc qua mạng. Cách biểu diễn này có thể cho phép dữ liệu được truy vấn, tìm kiếm, thao tác và xử lý theo nhiều cách khác nhau. Chúng ta sẽ thảo luận về các thiết kế bộ máy lưu trữ (storage engine) trong Chương 4.
- Ở các tầng thấp hơn nữa, các kỹ sư phần cứng đã tìm ra cách biểu diễn byte bằng dòng điện, xung ánh sáng, từ trường và nhiều phương tiện khác.
Trong một ứng dụng phức tạp có thể có nhiều tầng trung gian hơn, chẳng hạn như các API được xây dựng trên API khác, nhưng ý tưởng cơ bản vẫn như vậy: mỗi lớp che giấu sự phức tạp của các lớp bên dưới bằng cách cung cấp một mô hình dữ liệu rõ ràng. Những trừu tượng hóa (abstraction) này cho phép các nhóm người khác nhau, chẳng hạn như các kỹ sư tại nhà cung cấp cơ sở dữ liệu và các lập trình viên ứng dụng sử dụng cơ sở dữ liệu đó, cộng tác hiệu quả với nhau.
Nhiều mô hình dữ liệu khác nhau được sử dụng rộng rãi trong thực tế, thường phục vụ cho các mục đích khác nhau. Một số loại dữ liệu và một số truy vấn dễ biểu đạt trong mô hình này nhưng lại khó xử lý trong mô hình khác. Trong chương này chúng ta sẽ khám phá những sự đánh đổi (trade-off) đó bằng cách so sánh mô hình quan hệ (relational model), mô hình tài liệu (document model), các mô hình dữ liệu dạng đồ thị (graph-based data model), event sourcing và dataframe. Chúng ta cũng sẽ xem qua các ngôn ngữ truy vấn cho phép làm việc với những mô hình này. Sự so sánh này sẽ giúp bạn quyết định khi nào nên dùng mô hình nào.
THUẬT NGỮ: NGÔN NGỮ TRUY VẤN KHAI BÁO
Nhiều ngôn ngữ truy vấn trong chương này (chẳng hạn SQL, Cypher, SPARQL hoặc Datalog) là khai báo (declarative), nghĩa là bạn chỉ định mẫu dữ liệu mà bạn muốn, tức là những điều kiện mà kết quả phải thỏa mãn và cách bạn muốn dữ liệu được biến đổi (ví dụ: sắp xếp, nhóm và tổng hợp), mà không cần chỉ rõ làm thế nào để đạt được mục tiêu đó. Bộ tối ưu hóa truy vấn (query optimizer) của hệ thống cơ sở dữ liệu có thể tự quyết định dùng chỉ mục nào, thuật toán join nào, và thứ tự thực hiện các phần của truy vấn.
Ngược lại, với hầu hết các ngôn ngữ lập trình bạn phải viết một thuật toán, tức là chỉ dẫn máy tính thực hiện các phép toán theo thứ tự nào. Ngôn ngữ truy vấn khai báo hấp dẫn vì nó thường ngắn gọn và dễ viết hơn so với thuật toán tường minh. Nhưng quan trọng hơn, nó còn che giấu các chi tiết triển khai của bộ máy truy vấn, khiến hệ thống cơ sở dữ liệu có thể cải thiện hiệu suất mà không yêu cầu thay đổi gì ở phía các truy vấn 1.
Ví dụ, cơ sở dữ liệu có thể thực thi một truy vấn khai báo song song trên nhiều lõi CPU và nhiều máy chủ mà bạn không cần lo lắng về cách triển khai tính song song đó 2. Nếu viết thuật toán bằng tay, bạn sẽ phải tốn rất nhiều công sức để tự triển khai việc thực thi song song như vậy.
Mô hình quan hệ và mô hình tài liệu
Mô hình dữ liệu được biết đến rộng rãi nhất hiện nay có lẽ là SQL, dựa trên mô hình quan hệ (relational model) do Edgar Codd đề xuất năm 1970 3: dữ liệu được tổ chức thành các quan hệ (relation, gọi là bảng trong SQL), trong đó mỗi quan hệ là một tập hợp không có thứ tự các bộ giá trị (tuple, gọi là hàng trong SQL).
Mô hình quan hệ ban đầu chỉ là một đề xuất lý thuyết, và nhiều người hồi đó nghi ngờ liệu nó có thể được triển khai hiệu quả hay không. Tuy nhiên, đến giữa những năm 1980, các hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) và SQL đã trở thành công cụ được chọn lựa của hầu hết những ai cần lưu trữ và truy vấn dữ liệu có cấu trúc nhất định. Nhiều trường hợp sử dụng quản lý dữ liệu vẫn bị chi phối bởi dữ liệu quan hệ hàng thập kỷ sau đó, ví dụ như phân tích kinh doanh (xem “Lược đồ sao và bông tuyết: Lược đồ cho phân tích”).
Qua nhiều năm, đã có nhiều cách tiếp cận cạnh tranh về lưu trữ và truy vấn dữ liệu. Vào những năm 1970 và đầu những năm 1980, mô hình mạng (network model) và mô hình phân cấp (hierarchical model) là các lựa chọn thay thế chính, nhưng mô hình quan hệ đã thống trị cả hai. Cơ sở dữ liệu hướng đối tượng (object database) xuất hiện rồi lại biến mất vào cuối những năm 1980 và đầu những năm 1990. Cơ sở dữ liệu XML xuất hiện vào đầu những năm 2000, nhưng chỉ được áp dụng ở phạm vi hẹp. Mỗi đối thủ cạnh tranh với mô hình quan hệ đã tạo ra nhiều tiếng vang trong thời điểm của mình, nhưng chưa bao giờ kéo dài 4. Thay vào đó, SQL đã phát triển để tích hợp thêm các kiểu dữ liệu khác ngoài phần lõi quan hệ, ví dụ bổ sung hỗ trợ XML, JSON và dữ liệu đồ thị 5.
Vào những năm 2010, NoSQL là từ khóa thời thượng mới nhất cố gắng lật đổ sự thống trị của cơ sở dữ liệu quan hệ. NoSQL không chỉ một công nghệ duy nhất mà là một tập hợp lỏng lẻo các ý tưởng xoay quanh các mô hình dữ liệu mới, tính linh hoạt của lược đồ (schema), khả năng mở rộng và xu hướng hướng tới mô hình cấp phép mã nguồn mở. Một số cơ sở dữ liệu tự gọi mình là NewSQL, nhằm cung cấp khả năng mở rộng của hệ thống NoSQL kết hợp với mô hình dữ liệu và đảm bảo giao dịch của cơ sở dữ liệu quan hệ truyền thống. Các ý tưởng NoSQL và NewSQL đã có ảnh hưởng rất lớn đến thiết kế các hệ thống dữ liệu, nhưng khi các nguyên tắc này được áp dụng rộng rãi, việc sử dụng những thuật ngữ đó đã dần mờ nhạt.
Một tác động lâu dài của phong trào NoSQL là sự phổ biến của mô hình tài liệu (document model), thường biểu diễn dữ liệu dưới dạng JSON. Mô hình này ban đầu được phổ biến bởi các cơ sở dữ liệu tài liệu chuyên dụng như MongoDB và Couchbase, mặc dù hầu hết các cơ sở dữ liệu quan hệ hiện nay cũng đã bổ sung hỗ trợ JSON. So với các bảng quan hệ, thường bị xem là có lược đồ cứng nhắc và thiếu linh hoạt, tài liệu JSON được coi là linh hoạt hơn.
Ưu và nhược điểm của dữ liệu tài liệu và quan hệ đã được tranh luận rộng rãi; hãy cùng xem xét một số điểm chính của cuộc tranh luận đó.
Sự không khớp giữa đối tượng và quan hệ
Nhiều ứng dụng hiện nay được phát triển bằng các ngôn ngữ lập trình hướng đối tượng (object-oriented programming language), điều này dẫn đến một phê bình phổ biến về mô hình dữ liệu SQL: nếu dữ liệu được lưu trong các bảng quan hệ, thì cần có một tầng chuyển đổi phức tạp giữa các đối tượng trong mã ứng dụng và mô hình cơ sở dữ liệu gồm bảng, hàng và cột. Sự không khớp giữa hai mô hình này đôi khi được gọi là sự không khớp trở kháng (impedance mismatch).
Note
Thuật ngữ impedance mismatch (sự không khớp trở kháng) được mượn từ điện tử học. Mỗi mạch điện có một trở kháng nhất định (điện trở với dòng xoay chiều) ở đầu vào và đầu ra. Khi bạn kết nối đầu ra của một mạch với đầu vào của mạch khác, công suất truyền qua kết nối đạt tối đa nếu trở kháng đầu ra và đầu vào của hai mạch khớp với nhau. Sự không khớp trở kháng có thể gây ra phản xạ tín hiệu và các sự cố khác.
Object-relational mapping (ORM)
Các framework ORM (ánh xạ đối tượng-quan hệ) như ActiveRecord và Hibernate giúp giảm lượng mã soạn sẵn (boilerplate code) cần thiết cho tầng chuyển đổi này, nhưng chúng thường bị chỉ trích 6. Một số vấn đề thường được nêu ra là:
- ORM phức tạp và không thể che giấu hoàn toàn sự khác biệt giữa hai mô hình, vì vậy các nhà phát triển vẫn phải suy nghĩ về cả biểu diễn quan hệ lẫn biểu diễn đối tượng của dữ liệu.
- ORM thường chỉ được dùng trong phát triển ứng dụng OLTP (xem “Phân biệt xử lý giao dịch và phân tích”); các kỹ sư dữ liệu cần cung cấp dữ liệu cho mục đích phân tích vẫn phải làm việc trực tiếp với biểu diễn quan hệ bên dưới, vì vậy thiết kế lược đồ quan hệ vẫn quan trọng ngay cả khi dùng ORM.
- Nhiều ORM chỉ hoạt động với cơ sở dữ liệu OLTP quan hệ. Các tổ chức có hệ thống dữ liệu đa dạng như công cụ tìm kiếm, cơ sở dữ liệu đồ thị và hệ thống NoSQL có thể thấy sự hỗ trợ ORM còn thiếu sót.
- Một số ORM tự động tạo lược đồ quan hệ, nhưng những lược đồ này có thể không thuận tiện cho người dùng truy cập dữ liệu quan hệ trực tiếp, và có thể kém hiệu quả với cơ sở dữ liệu bên dưới. Việc tùy chỉnh lược đồ và quá trình sinh truy vấn của ORM có thể phức tạp và phủ nhận lợi ích ban đầu của việc dùng ORM.
- ORM khiến dễ vô tình viết các truy vấn kém hiệu quả, chẳng hạn vấn đề truy vấn N+1 (N+1 query problem) 7. Ví dụ, giả sử bạn muốn hiển thị danh sách bình luận của người dùng trên một trang, bạn thực hiện một truy vấn trả về N bình luận, mỗi bình luận chứa ID của tác giả. Để hiển thị tên tác giả, bạn cần tra cứu ID trong bảng người dùng. Khi viết SQL trực tiếp, bạn có thể thực hiện join này trong truy vấn và trả về tên tác giả cùng với mỗi bình luận, nhưng với ORM bạn có thể bị phát sinh một truy vấn riêng cho bảng người dùng với mỗi trong số N bình luận để tra cứu tác giả, dẫn đến tổng cộng N+1 truy vấn cơ sở dữ liệu, chậm hơn so với thực hiện join trong cơ sở dữ liệu. Để tránh vấn đề này, bạn có thể phải yêu cầu ORM tải thông tin tác giả cùng lúc với việc tải bình luận.
Tuy nhiên, ORM cũng có những ưu điểm:
- Đối với dữ liệu phù hợp với mô hình quan hệ, một dạng chuyển đổi nào đó giữa biểu diễn quan hệ lưu trữ và biểu diễn đối tượng trong bộ nhớ là không thể tránh khỏi, và ORM giúp giảm lượng mã soạn sẵn cần thiết cho quá trình chuyển đổi này. Các truy vấn phức tạp có thể vẫn cần được xử lý bên ngoài ORM, nhưng ORM có thể hỗ trợ tốt với các trường hợp đơn giản và lặp đi lặp lại.
- Một số ORM hỗ trợ lưu cache kết quả truy vấn cơ sở dữ liệu, có thể giúp giảm tải cho cơ sở dữ liệu.
- ORM cũng có thể hỗ trợ quản lý các lần di chuyển lược đồ (schema migration) và các hoạt động quản trị khác.
Mô hình tài liệu cho quan hệ một-nhiều
Không phải mọi dữ liệu đều phù hợp với biểu diễn quan hệ; hãy xem một ví dụ để khám phá giới hạn của mô hình quan hệ. Hình 3-1 minh họa cách một bản sơ yếu lý lịch (hồ sơ LinkedIn) có thể được biểu diễn trong lược đồ quan hệ. Hồ sơ tổng thể có thể được xác định bởi một định danh duy nhất, user_id. Các trường như first_name và last_name xuất hiện đúng một lần cho mỗi người dùng, vì vậy chúng có thể được mô hình hóa thành các cột trong bảng users.
Hầu hết mọi người đều đã làm nhiều công việc trong sự nghiệp của mình (positions), và mỗi người có thể có số lần học tập và số thông tin liên lạc khác nhau. Một cách biểu diễn các quan hệ một-nhiều (one-to-many relationship) như vậy là đặt positions, education và contact information vào các bảng riêng biệt, với khóa ngoại (foreign key) tham chiếu đến bảng users, như trong Hình 3-1.
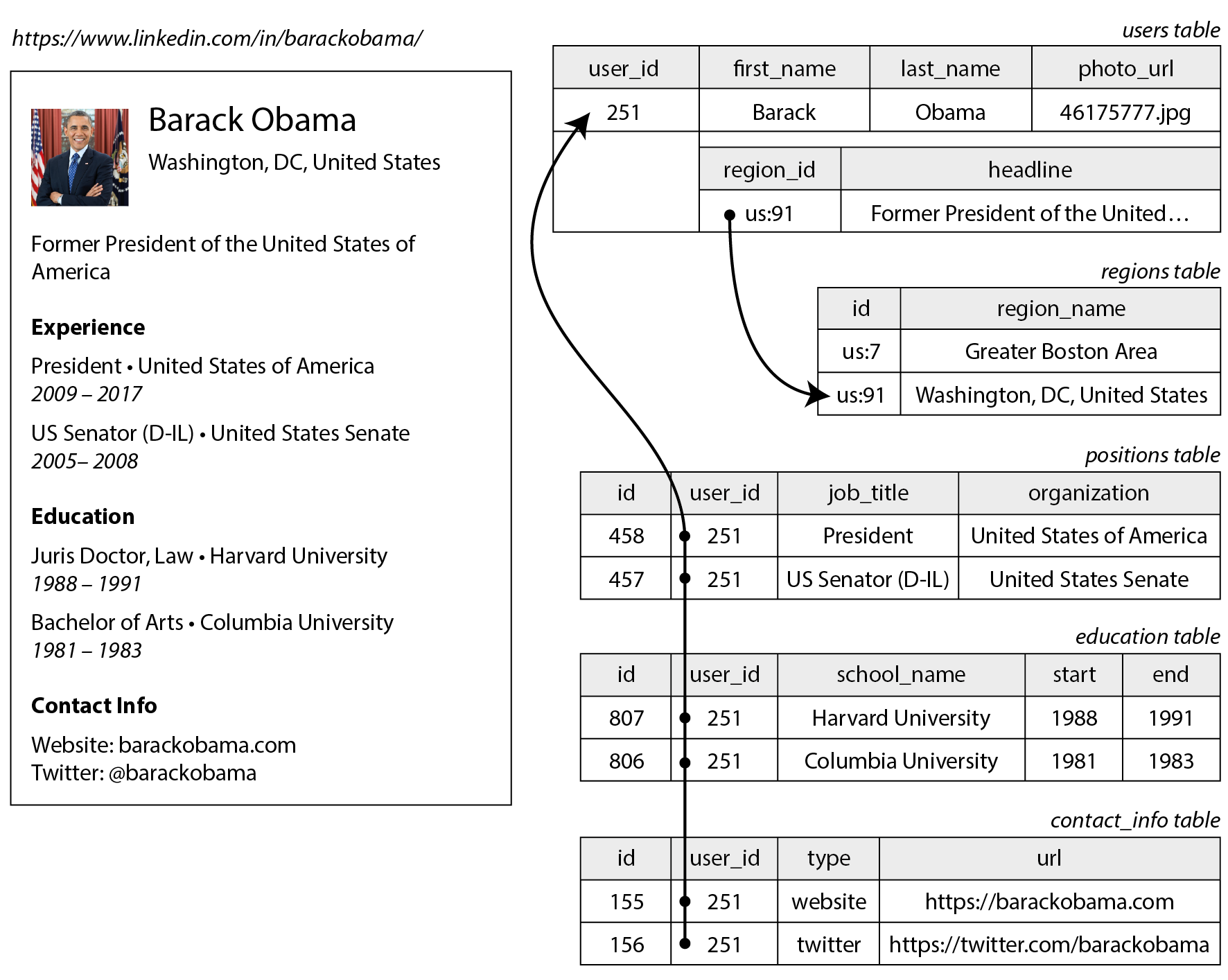
Một cách khác biểu diễn cùng thông tin đó, có lẽ tự nhiên hơn và gần với cấu trúc đối tượng trong mã ứng dụng hơn, là dưới dạng tài liệu JSON như trong Ví dụ 3-1.
Ví dụ 3-1. Biểu diễn hồ sơ LinkedIn dưới dạng tài liệu JSON
{
"user_id": 251,
"first_name": "Barack",
"last_name": "Obama",
"headline": "Former President of the United States of America",
"region_id": "us:91",
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "President", "organization": "United States of America"},
{"job_title": "US Senator (D-IL)", "organization": "United States Senate"}
],
"education": [
{"school_name": "Harvard University", "start": 1988, "end": 1991},
{"school_name": "Columbia University", "start": 1981, "end": 1983}
],
"contact_info": {
"website": "https://barackobama.com",
"twitter": "https://twitter.com/barackobama"
}
}Một số nhà phát triển cảm thấy mô hình JSON giúp giảm sự không khớp trở kháng giữa mã ứng dụng và tầng lưu trữ. Tuy nhiên, như chúng ta sẽ thấy trong Chương 5, cũng có những vấn đề với JSON ở vai trò định dạng mã hóa dữ liệu. Sự thiếu lược đồ thường được trích dẫn là một ưu điểm; chúng ta sẽ thảo luận về điều này trong “Tính linh hoạt của lược đồ trong mô hình tài liệu”.
Biểu diễn JSON có tính cục bộ (locality) tốt hơn so với lược đồ nhiều bảng trong Hình 3-1 (xem “Tính cục bộ dữ liệu cho đọc và ghi”). Nếu bạn muốn tải một hồ sơ trong ví dụ quan hệ, bạn cần thực hiện nhiều truy vấn (truy vấn từng bảng theo user_id) hoặc thực hiện một phép join nhiều chiều phức tạp giữa bảng users và các bảng phụ thuộc 8. Trong biểu diễn JSON, tất cả thông tin liên quan đều ở một chỗ, giúp truy vấn nhanh hơn và đơn giản hơn.
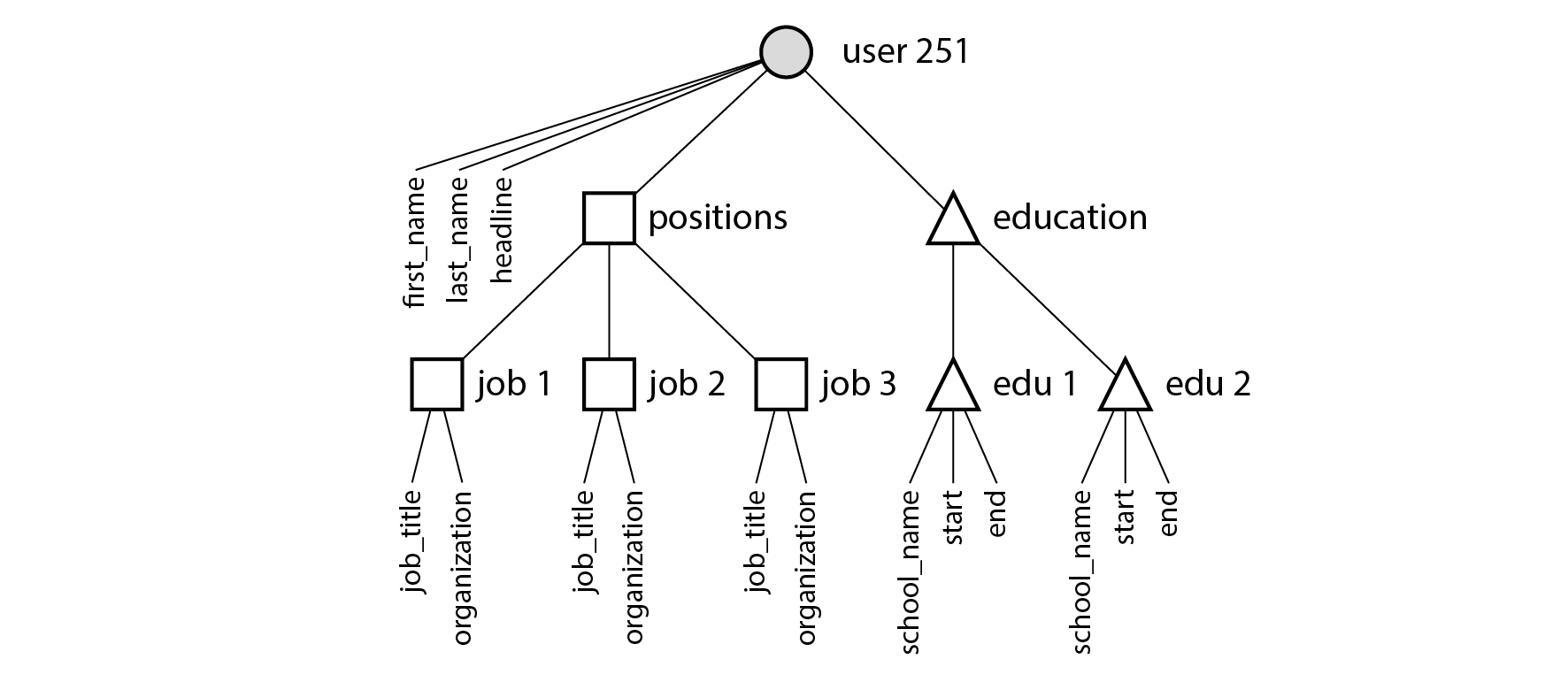
Các quan hệ một-nhiều từ hồ sơ người dùng đến các vị trí công việc, lịch sử học tập và thông tin liên lạc của người dùng hàm ý một cấu trúc cây trong dữ liệu, và biểu diễn JSON làm cho cấu trúc cây này trở nên tường minh (xem Hình 3-2).
Note
Loại quan hệ này đôi khi được gọi là một-ít (one-to-few) thay vì một-nhiều (one-to-many), vì một bản sơ yếu lý lịch thường chỉ có một số ít vị trí công việc 9 10. Trong các tình huống có thể có số lượng thực sự lớn các mục liên quan, chẳng hạn như bình luận trên một bài đăng mạng xã hội của người nổi tiếng có thể lên đến hàng nghìn bình luận, việc nhúng tất cả chúng vào cùng một tài liệu có thể quá cồng kềnh, vì vậy cách tiếp cận quan hệ trong Hình 3-1 sẽ tốt hơn.
Chuẩn hóa, phi chuẩn hóa và phép join
Trong Ví dụ 3-1 ở phần trước, region_id được cho dưới dạng ID, không phải chuỗi văn bản thuần "Washington, DC, United States". Tại sao?
Nếu giao diện người dùng có trường nhập văn bản tự do cho khu vực, thì hợp lý khi lưu dưới dạng chuỗi văn bản thuần. Nhưng có những lợi thế khi có danh sách tiêu chuẩn hóa các vùng địa lý, và để người dùng chọn từ danh sách thả xuống hoặc bộ gợi ý tự động:
- Định dạng và chính tả nhất quán trên các hồ sơ
- Tránh sự mơ hồ nếu có nhiều nơi cùng tên (nếu chuỗi chỉ là “Washington”, liệu nó có nghĩa là DC hay tiểu bang Washington?)
- Dễ cập nhật: tên chỉ được lưu ở một nơi, vì vậy dễ cập nhật toàn bộ nếu cần thay đổi (ví dụ, đổi tên thành phố do sự kiện chính trị)
- Hỗ trợ bản địa hóa: khi trang web được dịch sang các ngôn ngữ khác, các danh sách tiêu chuẩn hóa có thể được bản địa hóa, để khu vực có thể hiển thị bằng ngôn ngữ của người xem
- Tìm kiếm tốt hơn: ví dụ, tìm kiếm người ở vùng Đông Duyên hải Hoa Kỳ có thể khớp hồ sơ này, vì danh sách các vùng có thể mã hóa thực tế là Washington nằm ở Đông Duyên hải (điều này không rõ ràng từ chuỗi
"Washington, DC")
Việc lưu ID hay chuỗi văn bản là câu hỏi về chuẩn hóa (normalization). Khi bạn dùng ID, dữ liệu của bạn được chuẩn hóa hơn: thông tin có ý nghĩa với con người (chẳng hạn văn bản Washington, DC) chỉ được lưu ở một nơi, và mọi thứ tham chiếu đến nó đều dùng ID (chỉ có ý nghĩa trong phạm vi cơ sở dữ liệu). Khi bạn lưu trực tiếp văn bản, bạn đang sao chép thông tin có ý nghĩa với con người trong mọi bản ghi sử dụng nó; biểu diễn này gọi là phi chuẩn hóa (denormalized).
Ưu điểm của việc dùng ID là vì nó không có ý nghĩa với con người, nó không bao giờ cần thay đổi: ID có thể giữ nguyên, ngay cả khi thông tin mà nó xác định thay đổi. Bất cứ điều gì có ý nghĩa với con người có thể cần thay đổi vào một lúc nào đó trong tương lai, và nếu thông tin đó bị sao chép, tất cả các bản sao thừa đều cần được cập nhật. Điều đó đòi hỏi nhiều code hơn, nhiều thao tác ghi hơn, nhiều không gian đĩa hơn và có nguy cơ mất nhất quán (trong đó một số bản sao thông tin được cập nhật nhưng một số khác thì không).
Nhược điểm của biểu diễn chuẩn hóa là mỗi khi bạn muốn hiển thị một bản ghi chứa ID, bạn phải thực hiện một tra cứu bổ sung để giải quyết ID thành thứ gì đó có thể đọc được bởi con người. Trong mô hình dữ liệu quan hệ, điều này được thực hiện bằng một phép join, ví dụ:
SELECT users.*, regions.region_name
FROM users
JOIN regions ON users.region_id = regions.id
WHERE users.id = 251;Các cơ sở dữ liệu tài liệu có thể lưu cả dữ liệu chuẩn hóa và phi chuẩn hóa, nhưng chúng thường gắn liền với phi chuẩn hóa, một phần vì mô hình dữ liệu JSON giúp dễ dàng lưu các trường phi chuẩn hóa bổ sung, và một phần vì hỗ trợ join yếu trong nhiều cơ sở dữ liệu tài liệu khiến chuẩn hóa trở nên bất tiện. Một số cơ sở dữ liệu tài liệu không hỗ trợ join chút nào, vì vậy bạn phải thực hiện chúng trong mã ứng dụng, tức là bạn trước tiên tải một tài liệu chứa ID, rồi thực hiện truy vấn thứ hai để giải quyết ID đó thành tài liệu khác. Trong MongoDB, cũng có thể thực hiện join bằng toán tử $lookup trong một aggregation pipeline:
db.users.aggregate([
{ $match: { _id: 251 } },
{ $lookup: {
from: "regions",
localField: "region_id",
foreignField: "_id",
as: "region"
} }
])Sự đánh đổi của chuẩn hóa
Trong ví dụ sơ yếu lý lịch, trong khi trường region_id là tham chiếu vào một tập hợp vùng tiêu chuẩn hóa, thì tên organization (công ty hoặc cơ quan nơi người đó làm việc) và school_name (nơi họ học) chỉ là các chuỗi. Biểu diễn này là phi chuẩn hóa: nhiều người có thể đã làm việc ở cùng một công ty, nhưng không có ID nào liên kết họ.
Có lẽ tổ chức và trường học nên là các thực thể, và hồ sơ nên tham chiếu đến ID của chúng thay vì tên của chúng? Các lập luận tương tự cho việc tham chiếu ID của một vùng cũng áp dụng ở đây. Ví dụ, giả sử chúng ta muốn bao gồm logo của trường học hoặc công ty ngoài tên của họ:
- Trong biểu diễn phi chuẩn hóa, chúng ta sẽ bao gồm URL hình ảnh của logo trên hồ sơ của từng cá nhân; điều này làm cho tài liệu JSON tự chứa đầy đủ, nhưng gây đau đầu nếu chúng ta cần thay đổi logo, vì chúng ta phải tìm tất cả các lần xuất hiện của URL cũ và cập nhật chúng 9.
- Trong biểu diễn chuẩn hóa, chúng ta sẽ tạo một thực thể đại diện cho tổ chức hoặc trường học, và lưu tên, URL logo và có thể các thuộc tính khác (mô tả, nguồn tin tức, v.v.) một lần trên thực thể đó. Mỗi sơ yếu lý lịch đề cập đến tổ chức đó sau đó chỉ cần tham chiếu ID của nó, và việc cập nhật logo rất dễ dàng.
Về nguyên tắc chung, dữ liệu chuẩn hóa thường ghi nhanh hơn (vì chỉ có một bản sao), nhưng truy vấn chậm hơn (vì cần join); dữ liệu phi chuẩn hóa thường đọc nhanh hơn (ít join hơn), nhưng ghi tốn kém hơn (nhiều bản sao cần cập nhật, nhiều không gian đĩa hơn). Bạn có thể thấy hữu ích khi xem phi chuẩn hóa như một dạng dữ liệu dẫn xuất (“Hệ thống bản ghi và dữ liệu dẫn xuất”), vì bạn cần thiết lập một quy trình để cập nhật các bản sao thừa của dữ liệu.
Ngoài chi phí thực hiện tất cả các cập nhật này, bạn cũng cần xem xét tính nhất quán của cơ sở dữ liệu nếu một tiến trình gặp sự cố giữa chừng trong khi thực hiện cập nhật. Các cơ sở dữ liệu cung cấp giao dịch nguyên tử (xem “Tính nguyên tử”) giúp dễ dàng duy trì tính nhất quán hơn, nhưng không phải tất cả cơ sở dữ liệu đều cung cấp tính nguyên tử trên nhiều tài liệu. Cũng có thể đảm bảo tính nhất quán thông qua xử lý luồng (stream processing), mà chúng ta thảo luận trong “Giữ các hệ thống đồng bộ”.
Chuẩn hóa thường tốt hơn cho các hệ thống OLTP, nơi cả đọc và cập nhật đều cần nhanh; các hệ thống phân tích thường hoạt động tốt hơn với dữ liệu phi chuẩn hóa, vì chúng thực hiện cập nhật theo lô, và hiệu suất của các truy vấn chỉ đọc là mối quan tâm chủ đạo. Hơn nữa, trong các hệ thống quy mô nhỏ đến vừa, mô hình dữ liệu chuẩn hóa thường tốt nhất, vì bạn không phải lo lắng về việc giữ nhiều bản sao dữ liệu nhất quán với nhau, và chi phí thực hiện join là chấp nhận được. Tuy nhiên, trong các hệ thống quy mô rất lớn, chi phí join có thể trở nên có vấn đề.
Phi chuẩn hóa trong nghiên cứu điển hình về mạng xã hội
Trong “Nghiên cứu điển hình: Dòng thời gian trang chủ mạng xã hội” chúng ta đã so sánh biểu diễn chuẩn hóa (Hình 2-1) và biểu diễn phi chuẩn hóa (dòng thời gian được tính toán trước, vật liệu hóa): ở đây, phép join giữa posts và follows quá tốn kém, và dòng thời gian được vật liệu hóa là bộ nhớ cache kết quả của phép join đó. Quá trình fan-out chèn một bài đăng mới vào dòng thời gian của những người theo dõi là cách chúng ta duy trì tính nhất quán của biểu diễn phi chuẩn hóa.
Tuy nhiên, việc triển khai dòng thời gian vật liệu hóa tại X (trước đây là Twitter) không lưu trữ văn bản thực tế của mỗi bài đăng: mỗi mục thực sự chỉ lưu ID bài đăng, ID của người dùng đã đăng bài, và một chút thông tin bổ sung để xác định bài repost và bài trả lời 11. Nói cách khác, đó là kết quả được tính toán trước của (xấp xỉ) truy vấn sau:
SELECT posts.id, posts.sender_id
FROM posts
FROM posts
JOIN follows ON posts.sender_id = follows.followee_id
WHERE follows.follower_id = current_user
ORDER BY posts.timestamp DESC
LIMIT 1000Điều này có nghĩa là mỗi khi timeline được đọc, dịch vụ vẫn cần thực hiện hai phép join: tra cứu post ID để lấy nội dung bài viết thực sự (cũng như các số liệu thống kê như số lượt thích và số phản hồi), và tra cứu hồ sơ người gửi theo ID (để lấy tên người dùng, ảnh đại diện và các thông tin khác). Quá trình tra cứu thông tin có thể đọc được theo ID này được gọi là hydrating (điền dữ liệu) các ID, và về bản chất đây là một phép join được thực hiện trong mã ứng dụng 11.
Lý do chỉ lưu trữ các ID trong timeline đã tính toán trước là dữ liệu mà chúng tham chiếu thay đổi nhanh: số lượt thích và phản hồi có thể thay đổi nhiều lần mỗi giây trên một bài đăng phổ biến, và một số người dùng thường xuyên thay đổi tên người dùng hoặc ảnh đại diện của họ. Vì timeline nên hiển thị số lượt thích mới nhất và ảnh đại diện khi được xem, sẽ không có lý gì để denormalize thông tin này vào materialized timeline. Hơn nữa, chi phí lưu trữ sẽ tăng đáng kể do việc denormalize như vậy.
Ví dụ này cho thấy việc phải thực hiện join khi đọc dữ liệu không phải, như đôi khi người ta khẳng định, là trở ngại để tạo ra các dịch vụ có hiệu suất cao và khả năng mở rộng tốt. Hydrating post ID và user ID thực ra là một thao tác khá dễ dàng để mở rộng quy mô, vì nó song song hóa tốt, và chi phí không phụ thuộc vào số lượng tài khoản bạn đang theo dõi hay số lượng người theo dõi bạn.
Nếu bạn cần quyết định có nên denormalize gì đó trong ứng dụng của mình hay không, nghiên cứu tình huống mạng xã hội cho thấy sự lựa chọn không rõ ràng ngay lập tức: cách tiếp cận có khả năng mở rộng tốt nhất có thể liên quan đến việc denormalize một số thứ và để các thứ khác ở dạng normalized. Bạn sẽ phải xem xét cẩn thận tần suất thay đổi thông tin, và chi phí của các thao tác đọc và ghi (có thể bị chi phối bởi các trường hợp ngoại lệ, như người dùng có nhiều follows/followers trong trường hợp mạng xã hội điển hình). Normalization và denormalization không vốn dĩ tốt hay xấu, chúng chỉ là sự đánh đổi về hiệu suất của các thao tác đọc và ghi, cũng như lượng công sức cần thiết để triển khai.
Quan hệ Nhiều-Một và Nhiều-Nhiều (Many-to-One and Many-to-Many Relationships)
Trong khi positions và education trong Hình 3-1 là các ví dụ về
quan hệ một-nhiều hoặc một-ít (một résumé có nhiều positions, nhưng mỗi position chỉ thuộc về
một résumé), trường region_id là ví dụ về quan hệ nhiều-một (many-to-one) (nhiều người sống
ở cùng một khu vực, nhưng chúng ta giả định rằng mỗi người chỉ sống ở một khu vực tại bất kỳ
thời điểm nào).
Nếu chúng ta giới thiệu các thực thể cho các tổ chức và trường học, và tham chiếu chúng theo ID từ résumé, thì chúng ta cũng có quan hệ nhiều-nhiều (many-to-many) (một người đã làm việc cho nhiều tổ chức, và một tổ chức có nhiều nhân viên hiện tại hoặc cũ). Trong mô hình quan hệ, một mối quan hệ như vậy thường được biểu diễn dưới dạng associative table (bảng liên kết) hoặc join table (bảng nối), như được hiển thị trong Hình 3-3: mỗi position liên kết một user ID với một organization ID.
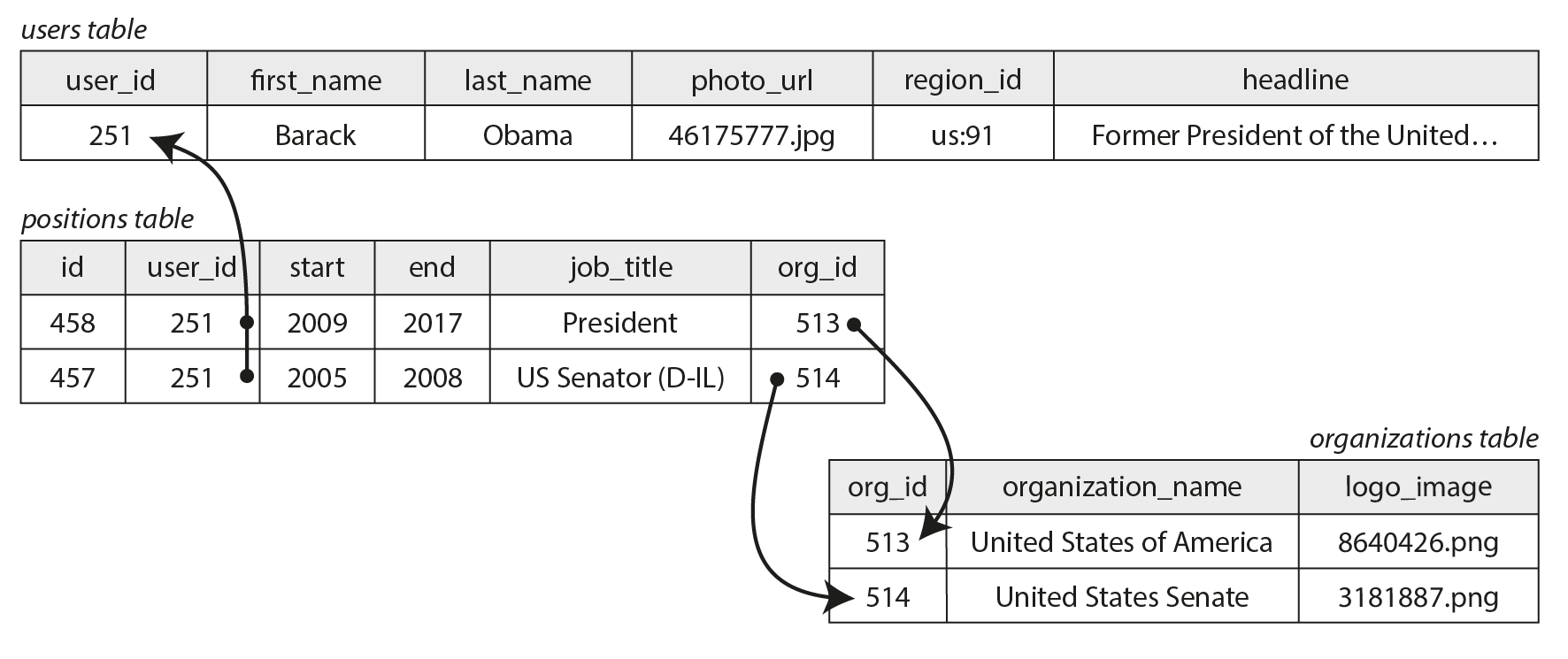
Quan hệ nhiều-một và nhiều-nhiều không dễ dàng phù hợp trong một tài liệu JSON tự chứa; chúng phù hợp hơn với biểu diễn dạng normalized. Trong mô hình tài liệu, một biểu diễn có thể được cho trong Ví dụ 3-2 và được minh họa trong Hình 3-4: dữ liệu trong mỗi hình chữ nhật đứt nét có thể được nhóm thành một tài liệu, nhưng các liên kết đến tổ chức và trường học tốt nhất nên được biểu diễn dưới dạng tham chiếu đến các tài liệu khác.
Ví dụ 3-2. Một résumé tham chiếu các tổ chức theo ID.
{
"user_id": 251,
"first_name": "Barack",
"last_name": "Obama",
"positions": [
{"start": 2009, "end": 2017, "job_title": "President", "org_id": 513},
{"start": 2005, "end": 2008, "job_title": "US Senator (D-IL)", "org_id": 514}
],
...
}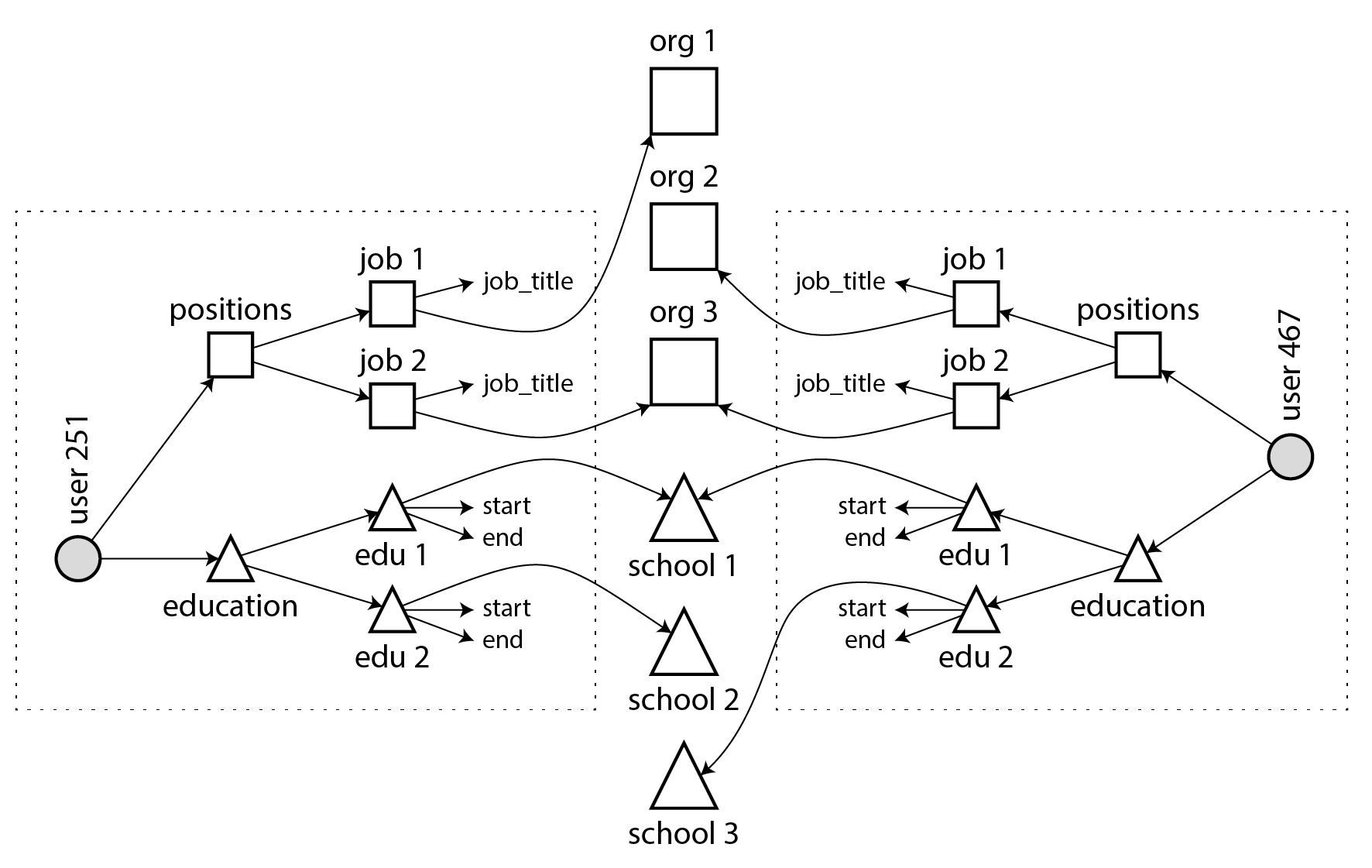
Quan hệ nhiều-nhiều thường cần được truy vấn theo “cả hai chiều”: ví dụ, tìm tất cả các tổ chức mà một người cụ thể đã làm việc, và tìm tất cả những người đã làm việc tại một tổ chức cụ thể. Một cách để cho phép các truy vấn như vậy là lưu trữ các tham chiếu ID ở cả hai phía, tức là, một résumé bao gồm ID của mỗi tổ chức nơi người đó đã làm việc, và tài liệu tổ chức bao gồm các ID của các résumé đề cập đến tổ chức đó. Biểu diễn này là denormalized, vì mối quan hệ được lưu trữ ở hai nơi, có thể trở nên không nhất quán với nhau.
Biểu diễn normalized lưu trữ mối quan hệ ở chỉ một nơi, và dựa vào secondary indexes (chỉ
mục phụ) (mà chúng ta thảo luận trong Chương 4) để cho phép mối quan hệ
được truy vấn hiệu quả theo cả hai chiều. Trong schema quan hệ của Hình 3-3,
chúng ta sẽ yêu cầu cơ sở dữ liệu tạo index trên cả cột user_id và cột org_id của bảng
positions.
Trong mô hình tài liệu của Ví dụ 3-2, cơ sở dữ liệu cần
đánh index trường org_id của các đối tượng bên trong mảng positions. Nhiều cơ sở dữ liệu
tài liệu và cơ sở dữ liệu quan hệ có hỗ trợ JSON có thể tạo các index như vậy trên các giá
trị bên trong một tài liệu.
Stars and Snowflakes: Schemas cho Analytics
Data warehouses (kho dữ liệu) (xem “Data Warehousing”) thường là quan hệ, và có một số quy ước được sử dụng rộng rãi cho cấu trúc của các bảng trong data warehouse: star schema (lược đồ hình sao), snowflake schema (lược đồ hình bông tuyết), dimensional modeling (mô hình chiều) 12, và one big table (OBT, một bảng lớn). Các cấu trúc này được tối ưu hóa cho nhu cầu của các nhà phân tích kinh doanh. Các quy trình ETL dịch dữ liệu từ các hệ thống vận hành sang schema này.
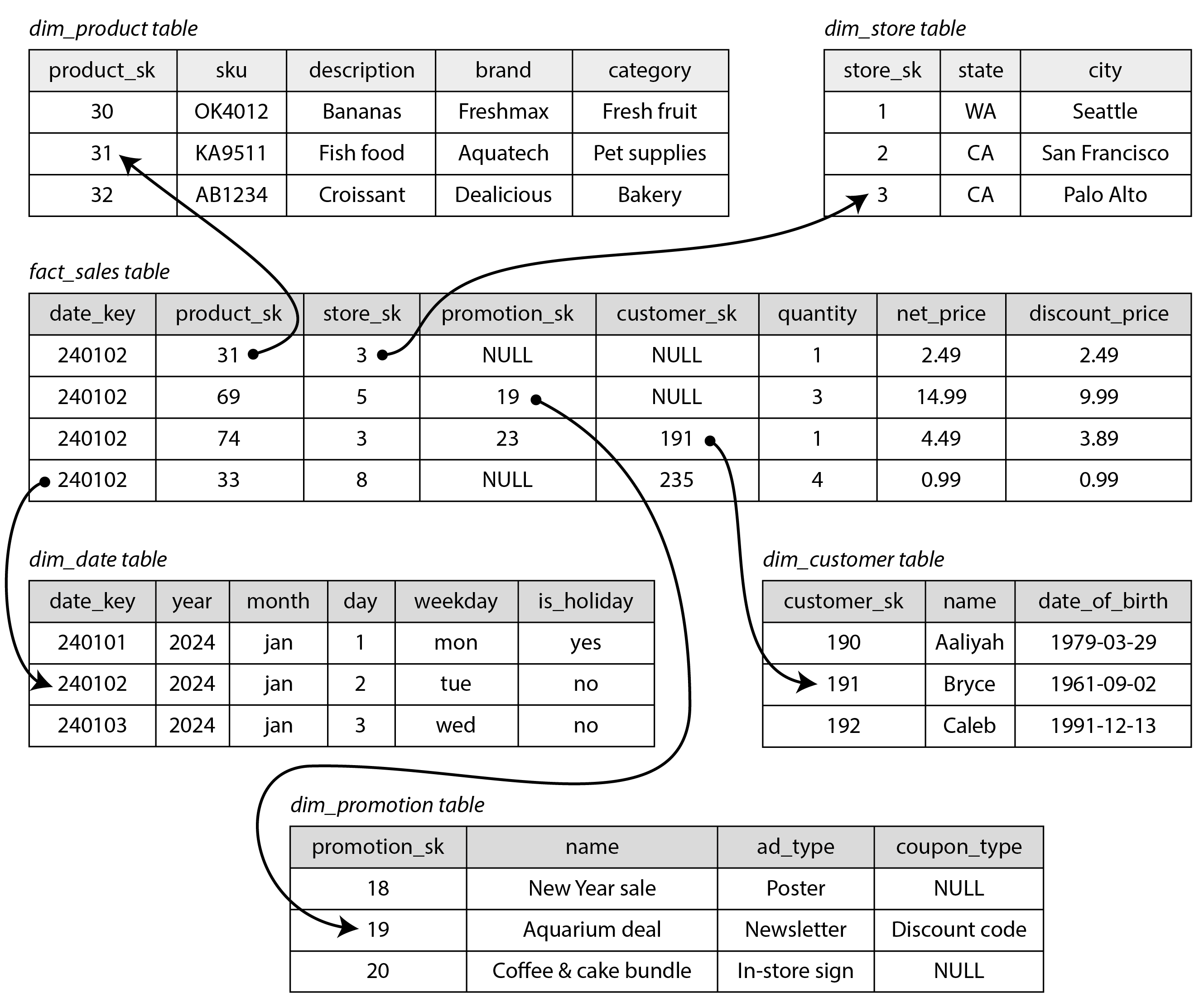
Hình 3-5 hiển thị một ví dụ về star schema có thể được tìm thấy trong
data warehouse của một nhà bán lẻ hàng tạp hóa. Ở trung tâm của schema là fact table (bảng
sự kiện) (trong ví dụ này, nó được gọi là fact_sales). Mỗi hàng của fact table đại diện
cho một sự kiện xảy ra tại một thời điểm cụ thể (ở đây, mỗi hàng đại diện cho việc khách hàng
mua một sản phẩm). Nếu chúng ta phân tích lưu lượng truy cập trang web thay vì doanh số bán
lẻ, mỗi hàng có thể đại diện cho một lần xem trang hoặc một lần nhấp chuột của người dùng.
Thông thường, các sự kiện được ghi lại dưới dạng các sự kiện riêng lẻ, vì điều này cho phép tối đa sự linh hoạt trong phân tích sau này. Tuy nhiên, điều này có nghĩa là fact table có thể trở nên cực kỳ lớn. Một doanh nghiệp lớn có thể có nhiều petabyte lịch sử giao dịch trong data warehouse của mình, chủ yếu được biểu diễn dưới dạng fact tables.
Một số cột trong fact table là các thuộc tính, chẳng hạn như giá sản phẩm được bán và chi phí mua từ nhà cung cấp (cho phép tính toán biên lợi nhuận). Các cột khác trong fact table là các khóa ngoại tham chiếu đến các bảng khác, được gọi là dimension tables (bảng chiều). Khi mỗi hàng trong fact table đại diện cho một sự kiện, các dimensions đại diện cho ai, cái gì, ở đâu, khi nào, như thế nào, và tại sao của sự kiện.
Ví dụ, trong Hình 3-5, một trong những dimensions là sản phẩm được
bán. Mỗi hàng trong bảng dim_product đại diện cho một loại sản phẩm đang được bán, bao gồm
đơn vị lưu kho (SKU), mô tả, tên thương hiệu, danh mục, hàm lượng chất béo, kích thước đóng
gói, v.v. Mỗi hàng trong bảng fact_sales sử dụng khóa ngoại để chỉ ra sản phẩm nào đã được
bán trong giao dịch cụ thể đó. Các truy vấn thường liên quan đến nhiều phép join đến nhiều
dimension tables.
Ngay cả ngày và giờ cũng thường được biểu diễn bằng dimension tables, vì điều này cho phép mã hóa thêm thông tin về ngày (chẳng hạn như ngày lễ), cho phép các truy vấn phân biệt giữa doanh số bán hàng vào ngày lễ và ngày thường.
Hình 3-5 là một ví dụ về star schema. Tên gọi xuất phát từ thực tế là khi các mối quan hệ bảng được trực quan hóa, fact table ở giữa, được bao quanh bởi các dimension tables; các kết nối đến các bảng này giống như các tia của một ngôi sao.
Một biến thể của template này được gọi là snowflake schema (lược đồ bông tuyết), trong đó
các dimensions được phân tách thêm thành các subdimensions (chiều con). Ví dụ, có thể có các
bảng riêng biệt cho thương hiệu và danh mục sản phẩm, và mỗi hàng trong bảng dim_product có
thể tham chiếu thương hiệu và danh mục dưới dạng khóa ngoại, thay vì lưu trữ chúng dưới dạng
chuỗi trong bảng dim_product. Snowflake schemas được normalized hơn star schemas, nhưng star
schemas thường được ưa thích hơn vì chúng đơn giản hơn cho các nhà phân tích khi làm việc 12.
Trong một data warehouse điển hình, các bảng thường khá rộng: fact tables thường có hơn 100
cột, đôi khi vài trăm. Dimension tables cũng có thể rộng, vì chúng bao gồm tất cả các metadata
có thể liên quan đến phân tích, ví dụ, bảng dim_store có thể bao gồm thông tin chi tiết về
các dịch vụ nào được cung cấp tại mỗi cửa hàng, liệu nó có tiệm bánh trong cửa hàng không,
diện tích sàn, ngày cửa hàng được mở lần đầu, khi nào được cải tạo lần cuối, cách xa đường cao
tốc gần nhất bao nhiêu, v.v.
Star schema hoặc snowflake schema chủ yếu bao gồm các quan hệ nhiều-một (ví dụ: nhiều lần bán hàng xảy ra cho một sản phẩm cụ thể, tại một cửa hàng cụ thể), được biểu diễn dưới dạng fact table có khóa ngoại vào dimension tables, hoặc dimensions vào sub-dimensions. Về nguyên tắc, các loại quan hệ khác có thể tồn tại, nhưng chúng thường được denormalize để đơn giản hóa các truy vấn. Ví dụ, nếu khách hàng mua nhiều sản phẩm khác nhau cùng một lúc, giao dịch nhiều mặt hàng đó không được biểu diễn một cách rõ ràng; thay vào đó, có một hàng riêng biệt trong fact table cho mỗi sản phẩm được mua, và tất cả những facts đó chỉ tình cờ có cùng customer ID, store ID, và timestamp.
Một số schema data warehouse đẩy denormalization đi xa hơn và bỏ hoàn toàn dimension tables, thay vào đó gộp thông tin trong các dimensions thành các cột denormalized trên fact table (về cơ bản, tính toán trước phép join giữa fact table và dimension tables). Cách tiếp cận này được gọi là one big table (OBT), và mặc dù nó đòi hỏi nhiều không gian lưu trữ hơn, đôi khi nó cho phép các truy vấn nhanh hơn 13.
Trong bối cảnh analytics, việc denormalize như vậy không gây vấn đề, vì dữ liệu thường đại diện cho nhật ký dữ liệu lịch sử sẽ không thay đổi (ngoại trừ đôi khi sửa lỗi). Các vấn đề về tính nhất quán dữ liệu và chi phí ghi xảy ra với denormalization trong các hệ thống OLTP không đáng lo ngại như trong analytics.
Khi Nào Nên Dùng Mô Hình Nào
Các lập luận chính ủng hộ mô hình dữ liệu tài liệu là tính linh hoạt về schema, hiệu suất tốt hơn nhờ locality (cục bộ dữ liệu), và việc đối với một số ứng dụng nó gần hơn với mô hình đối tượng được sử dụng bởi ứng dụng. Mô hình quan hệ đáp lại bằng cách cung cấp hỗ trợ tốt hơn cho các phép join, quan hệ nhiều-một, và nhiều-nhiều. Hãy xem xét các lập luận này chi tiết hơn.
Nếu dữ liệu trong ứng dụng của bạn có cấu trúc giống tài liệu (tức là, một cây của các quan hệ
một-nhiều, trong đó thường toàn bộ cây được tải cùng một lúc), thì có lẽ là ý tưởng tốt khi
sử dụng mô hình tài liệu. Kỹ thuật quan hệ shredding (phân mảnh), tức là phân tách cấu trúc
giống tài liệu thành nhiều bảng (như positions, education, và contact_info trong
Hình 3-1), có thể dẫn đến các schema cồng kềnh và mã ứng dụng
phức tạp không cần thiết.
Mô hình tài liệu có những hạn chế: ví dụ, bạn không thể tham chiếu trực tiếp đến một mục lồng nhau trong một tài liệu, mà thay vào đó bạn cần nói điều gì đó như “mục thứ hai trong danh sách positions của người dùng 251”. Nếu bạn cần tham chiếu các mục lồng nhau, cách tiếp cận quan hệ hoạt động tốt hơn, vì bạn có thể tham chiếu bất kỳ mục nào trực tiếp theo ID của nó.
Một số ứng dụng cho phép người dùng chọn thứ tự của các mục: ví dụ, hãy tưởng tượng một danh sách việc cần làm hoặc trình theo dõi vấn đề nơi người dùng có thể kéo và thả các nhiệm vụ để sắp xếp lại chúng. Mô hình tài liệu hỗ trợ tốt các ứng dụng như vậy, vì các mục (hoặc ID của chúng) chỉ cần được lưu trữ trong một mảng JSON để xác định thứ tự của chúng. Trong cơ sở dữ liệu quan hệ không có cách chuẩn để biểu diễn các danh sách có thể sắp xếp lại như vậy, và nhiều thủ thuật được sử dụng: sắp xếp theo cột số nguyên (yêu cầu đánh số lại khi bạn chèn vào giữa), danh sách liên kết của các ID, hoặc fractional indexing (đánh chỉ số phân số) 14 15 16.
Tính linh hoạt về schema trong mô hình tài liệu
Hầu hết các cơ sở dữ liệu tài liệu, và hỗ trợ JSON trong cơ sở dữ liệu quan hệ, không áp đặt bất kỳ schema nào trên dữ liệu trong các tài liệu. Hỗ trợ XML trong cơ sở dữ liệu quan hệ thường đi kèm với xác thực schema tùy chọn. Không có schema có nghĩa là các khóa và giá trị tùy ý có thể được thêm vào một tài liệu, và khi đọc, các client không có bảo đảm về những trường nào mà tài liệu có thể chứa.
Cơ sở dữ liệu tài liệu đôi khi được gọi là schemaless (không có schema), nhưng điều đó gây hiểu lầm, vì mã đọc dữ liệu thường giả định một loại cấu trúc nào đó, tức là có một implicit schema (schema ngầm định), nhưng nó không được cơ sở dữ liệu thực thi 17. Thuật ngữ chính xác hơn là schema-on-read (schema khi đọc, cấu trúc của dữ liệu là ngầm định và chỉ được diễn giải khi dữ liệu được đọc), trái ngược với schema-on-write (schema khi ghi, cách tiếp cận truyền thống của cơ sở dữ liệu quan hệ, trong đó schema là rõ ràng và cơ sở dữ liệu đảm bảo tất cả dữ liệu tuân theo nó khi dữ liệu được ghi) 18.
Schema-on-read tương tự như kiểm tra kiểu động (runtime) trong các ngôn ngữ lập trình, trong khi schema-on-write tương tự như kiểm tra kiểu tĩnh (compile-time). Cũng như những người ủng hộ kiểm tra kiểu tĩnh và động có những cuộc tranh luận lớn về ưu điểm tương đối của chúng 19, việc áp dụng schema trong cơ sở dữ liệu là một chủ đề gây tranh cãi, và nói chung không có câu trả lời đúng hay sai.
Sự khác biệt giữa các cách tiếp cận đặc biệt đáng chú ý trong các tình huống mà một ứng dụng muốn thay đổi định dạng dữ liệu của mình. Ví dụ, giả sử bạn hiện đang lưu trữ tên đầy đủ của mỗi người dùng trong một trường, và bạn muốn lưu trữ tên và họ riêng biệt 20. Trong cơ sở dữ liệu tài liệu, bạn chỉ cần bắt đầu viết các tài liệu mới với các trường mới và có mã trong ứng dụng xử lý trường hợp khi các tài liệu cũ được đọc. Ví dụ:
if (user && user.name && !user.first_name) {
// Documents written before Dec 8, 2023 don't have first_name
user.first_name = user.name.split(" ")[0];
}Nhược điểm của cách tiếp cận này là mọi phần của ứng dụng đọc từ cơ sở dữ liệu giờ đây cần xử lý các tài liệu ở định dạng cũ có thể đã được viết từ rất lâu. Mặt khác, trong cơ sở dữ liệu schema-on-write, bạn thường sẽ thực hiện một migration (di chuyển schema) theo hướng:
ALTER TABLE users ADD COLUMN first_name text DEFAULT NULL;
UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQLTrong hầu hết các cơ sở dữ liệu quan hệ, việc thêm một cột với giá trị mặc định là nhanh và
không có vấn đề, ngay cả trên các bảng lớn. Tuy nhiên, chạy câu lệnh UPDATE có thể chậm trên
một bảng lớn, vì mỗi hàng cần được viết lại, và các thao tác schema khác (như thay đổi kiểu dữ
liệu của một cột) cũng thường yêu cầu toàn bộ bảng phải được sao chép.
Nhiều công cụ khác nhau tồn tại để cho phép loại thay đổi schema này được thực hiện trong nền
mà không có thời gian chết 21 22 23 24, nhưng việc thực hiện các migration như vậy
trên các cơ sở dữ liệu lớn vẫn còn thách thức về mặt vận hành. Các migration phức tạp có thể
được tránh bằng cách chỉ thêm cột first_name với giá trị mặc định là NULL (nhanh), và điền
vào lúc đọc, giống như bạn làm với cơ sở dữ liệu tài liệu.
Cách tiếp cận schema-on-read có lợi thế nếu các mục trong collection không có cùng cấu trúc vì một lý do nào đó (tức là, dữ liệu không đồng nhất), ví dụ vì:
- Có nhiều loại đối tượng khác nhau, và không thực tế khi đặt mỗi loại đối tượng vào bảng riêng của nó.
- Cấu trúc của dữ liệu được xác định bởi các hệ thống bên ngoài mà bạn không có quyền kiểm soát và có thể thay đổi bất kỳ lúc nào.
Trong các tình huống như thế này, một schema có thể gây hại nhiều hơn là giúp ích, và các tài liệu không có schema có thể là mô hình dữ liệu tự nhiên hơn nhiều. Nhưng trong các trường hợp mà tất cả các bản ghi được mong đợi có cùng cấu trúc, schema là một cơ chế hữu ích để ghi lại và thực thi cấu trúc đó. Chúng ta sẽ thảo luận về schema và schema evolution (sự phát triển của schema) chi tiết hơn trong Chương 5.
Locality dữ liệu cho các thao tác đọc và ghi
Một tài liệu thường được lưu trữ dưới dạng một chuỗi liên tục duy nhất, được mã hóa dưới dạng JSON, XML, hoặc một biến thể nhị phân của chúng (chẳng hạn như BSON của MongoDB). Nếu ứng dụng của bạn thường cần truy cập toàn bộ tài liệu (ví dụ, để hiển thị nó trên một trang web), có một lợi thế hiệu suất từ storage locality (cục bộ lưu trữ) này. Nếu dữ liệu được phân tán trên nhiều bảng, như trong Hình 3-1, nhiều lần tra cứu index được yêu cầu để lấy tất cả dữ liệu, có thể đòi hỏi nhiều lần đọc đĩa hơn và mất nhiều thời gian hơn.
Lợi thế về locality chỉ áp dụng nếu bạn cần các phần lớn của tài liệu cùng một lúc. Cơ sở dữ liệu thường cần tải toàn bộ tài liệu, điều này có thể lãng phí nếu bạn chỉ cần truy cập một phần nhỏ của một tài liệu lớn. Khi cập nhật một tài liệu, toàn bộ tài liệu thường cần được viết lại. Vì những lý do này, nhìn chung được khuyến nghị rằng bạn nên giữ các tài liệu khá nhỏ và tránh các cập nhật nhỏ thường xuyên cho một tài liệu.
Tuy nhiên, ý tưởng lưu trữ dữ liệu liên quan cùng nhau vì locality không chỉ giới hạn trong mô hình tài liệu. Ví dụ, cơ sở dữ liệu Spanner của Google cung cấp cùng thuộc tính locality trong mô hình dữ liệu quan hệ, bằng cách cho phép schema khai báo rằng các hàng của một bảng nên được xen kẽ (lồng nhau) trong bảng cha 25. Oracle cho phép điều tương tự, sử dụng tính năng được gọi là multi-table index cluster tables 26. Mô hình dữ liệu wide-column (cột rộng) được phổ biến bởi Bigtable của Google, và được sử dụng ví dụ trong HBase và Accumulo, có khái niệm column families (họ cột), có mục đích tương tự trong việc quản lý locality 27.
Ngôn ngữ truy vấn cho tài liệu
Một sự khác biệt khác giữa cơ sở dữ liệu quan hệ và tài liệu là ngôn ngữ hoặc API mà bạn sử dụng để truy vấn nó. Hầu hết các cơ sở dữ liệu quan hệ được truy vấn bằng SQL, nhưng các cơ sở dữ liệu tài liệu thì đa dạng hơn. Một số chỉ cho phép truy cập khóa-giá trị theo khóa chính, trong khi các cơ sở dữ liệu khác cũng cung cấp secondary indexes để truy vấn các giá trị bên trong tài liệu, và một số cung cấp ngôn ngữ truy vấn phong phú.
Cơ sở dữ liệu XML thường được truy vấn bằng XQuery và XPath, được thiết kế để cho phép các truy vấn phức tạp, bao gồm các phép join trên nhiều tài liệu, và cũng định dạng kết quả của chúng dưới dạng XML 28. JSON Pointer 29 và JSONPath 30 cung cấp tương đương với XPath cho JSON.
Aggregation pipeline của MongoDB, với toán tử $lookup cho các phép join mà chúng ta đã thấy
trong “Normalization, Denormalization, and Joins”, là
một ví dụ về ngôn ngữ truy vấn cho các collection tài liệu JSON.
Hãy xem xét một ví dụ khác để hiểu rõ hơn về ngôn ngữ này, lần này là một phép tổng hợp (aggregation), đặc biệt cần thiết cho analytics. Hãy tưởng tượng bạn là một nhà sinh vật học biển, và bạn thêm một bản ghi quan sát vào cơ sở dữ liệu của mình mỗi khi bạn thấy động vật trong đại dương. Bây giờ bạn muốn tạo một báo cáo cho biết bạn đã nhìn thấy bao nhiêu con cá mập mỗi tháng. Trong PostgreSQL bạn có thể diễn đạt truy vấn đó như sau:
SELECT date_trunc('month', observation_timestamp) AS observation_month, ❶
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;❶ : Hàm date_trunc('month', timestamp) xác định tháng lịch chứa timestamp, và trả về một
timestamp khác đại diện cho đầu tháng đó. Nói cách khác, nó làm tròn timestamp xuống tháng
gần nhất.
Truy vấn này trước tiên lọc các quan sát để chỉ hiển thị các loài trong họ Sharks, sau đó
nhóm các quan sát theo tháng lịch mà chúng xảy ra, và cuối cùng cộng số lượng động vật được
nhìn thấy trong tất cả các quan sát trong tháng đó. Cùng một truy vấn có thể được diễn đạt
bằng aggregation pipeline của MongoDB như sau:
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{ $group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
} }
]);Ngôn ngữ aggregation pipeline có tính biểu đạt tương tự như một tập hợp con của SQL, nhưng nó sử dụng cú pháp dựa trên JSON thay vì cú pháp kiểu câu tiếng Anh của SQL; sự khác biệt có lẽ là vấn đề sở thích.
Sự hội tụ của cơ sở dữ liệu tài liệu và quan hệ
Cơ sở dữ liệu tài liệu và cơ sở dữ liệu quan hệ ban đầu là những cách tiếp cận rất khác nhau đối với việc quản lý dữ liệu, nhưng chúng đã trở nên giống nhau hơn theo thời gian 31. Các cơ sở dữ liệu quan hệ đã thêm hỗ trợ cho các kiểu JSON và các toán tử truy vấn, và khả năng đánh index các thuộc tính bên trong tài liệu. Một số cơ sở dữ liệu tài liệu (như MongoDB, Couchbase, và RethinkDB) đã thêm hỗ trợ cho các phép join, secondary indexes, và ngôn ngữ truy vấn khai báo.
Sự hội tụ của các mô hình này là tin tốt cho các nhà phát triển ứng dụng, vì mô hình quan hệ và mô hình tài liệu hoạt động tốt nhất khi bạn có thể kết hợp cả hai trong cùng một cơ sở dữ liệu. Nhiều cơ sở dữ liệu tài liệu cần các tham chiếu theo kiểu quan hệ đến các tài liệu khác, và nhiều cơ sở dữ liệu quan hệ có các phần mà tính linh hoạt về schema có lợi. Các hybrid (lai) quan hệ-tài liệu là một sự kết hợp mạnh mẽ.
Note
Mô tả ban đầu của Codd về mô hình quan hệ 3 thực ra cho phép điều gì đó tương tự như JSON trong một schema quan hệ. Ông gọi nó là nonsimple domains (miền không đơn giản). Ý tưởng là một giá trị trong một hàng không chỉ cần là một kiểu dữ liệu nguyên thủy như số hoặc chuỗi, mà còn có thể là một quan hệ lồng nhau (bảng), vì vậy bạn có thể có một cấu trúc cây lồng nhau tùy ý như một giá trị, giống như hỗ trợ JSON hoặc XML được thêm vào SQL hơn 30 năm sau.
Các Mô Hình Dữ Liệu Dạng Đồ Thị
Chúng ta đã thấy rằng kiểu quan hệ là đặc điểm phân biệt quan trọng giữa các mô hình dữ liệu khác nhau. Nếu ứng dụng của bạn chủ yếu có quan hệ một-nhiều (dữ liệu cấu trúc cây) và ít quan hệ khác giữa các bản ghi, mô hình tài liệu là phù hợp.
Nhưng nếu quan hệ nhiều-nhiều rất phổ biến trong dữ liệu của bạn thì sao? Mô hình quan hệ có thể xử lý các trường hợp đơn giản của quan hệ nhiều-nhiều, nhưng khi các kết nối trong dữ liệu trở nên phức tạp hơn, việc mô hình hóa dữ liệu dưới dạng đồ thị (graph) trở nên tự nhiên hơn.
Một đồ thị gồm hai loại đối tượng: đỉnh (vertices, còn gọi là node hoặc entity) và cạnh (edges, còn gọi là relationship hoặc arc). Nhiều loại dữ liệu có thể được mô hình hóa dưới dạng đồ thị. Các ví dụ điển hình bao gồm:
- Đồ thị mạng xã hội (Social graphs)
- Đỉnh là người dùng, và cạnh biểu thị những người quen biết nhau.
- Đồ thị web (The web graph)
- Đỉnh là các trang web, và cạnh biểu thị các liên kết HTML đến các trang khác.
- Mạng lưới đường bộ hoặc đường sắt (Road or rail networks)
- Đỉnh là các nút giao, và cạnh biểu thị các con đường hoặc tuyến đường sắt giữa chúng.
Các thuật toán nổi tiếng có thể hoạt động trên các đồ thị này: ví dụ, các ứng dụng dẫn đường bản đồ tìm kiếm đường đi ngắn nhất giữa hai điểm trong mạng lưới đường bộ, và PageRank có thể được sử dụng trên đồ thị web để xác định mức độ phổ biến của một trang web và từ đó xếp hạng trong kết quả tìm kiếm 32.
Đồ thị có thể được biểu diễn theo nhiều cách khác nhau. Trong mô hình danh sách kề (adjacency list), mỗi đỉnh lưu trữ các ID của các đỉnh lân cận cách một cạnh. Ngoài ra, bạn có thể dùng ma trận kề (adjacency matrix), một mảng hai chiều trong đó mỗi hàng và mỗi cột tương ứng với một đỉnh, giá trị bằng không khi không có cạnh giữa đỉnh hàng và đỉnh cột, và giá trị bằng một nếu có cạnh. Danh sách kề phù hợp cho việc duyệt đồ thị, còn ma trận phù hợp cho học máy (xem “Dataframes, Matrices, and Arrays”).
Trong các ví dụ vừa nêu, tất cả các đỉnh trong đồ thị biểu diễn cùng một loại đối tượng (người, trang web, hoặc nút giao đường bộ). Tuy nhiên, đồ thị không bị giới hạn ở dữ liệu đồng nhất (homogeneous) như vậy: một ứng dụng mạnh mẽ không kém của đồ thị là cung cấp cách lưu trữ nhất quán các loại đối tượng hoàn toàn khác nhau trong một cơ sở dữ liệu duy nhất. Ví dụ:
- Facebook duy trì một đồ thị duy nhất với nhiều loại đỉnh và cạnh khác nhau: đỉnh biểu diễn người dùng, địa điểm, sự kiện, lượt check-in, và bình luận của người dùng; cạnh biểu thị những người là bạn bè với nhau, lượt check-in nào xảy ra ở địa điểm nào, ai bình luận bài đăng nào, ai tham dự sự kiện nào, v.v. 33.
- Đồ thị tri thức (Knowledge graphs) được các công cụ tìm kiếm sử dụng để ghi lại các sự kiện về các thực thể thường xuất hiện trong truy vấn tìm kiếm, chẳng hạn như tổ chức, người và địa điểm 34. Thông tin này thu được bằng cách thu thập và phân tích văn bản trên các trang web; một số trang web, chẳng hạn như Wikidata, cũng công bố dữ liệu đồ thị dưới dạng có cấu trúc.
Có một số cách khác nhau nhưng có liên quan để cấu trúc và truy vấn dữ liệu trong đồ thị. Trong phần này chúng ta sẽ thảo luận về mô hình property graph (được triển khai bởi Neo4j, Memgraph, KùzuDB 35 và những cái khác 36) và mô hình triple-store (được triển khai bởi Datomic, AllegroGraph, Blazegraph và những cái khác). Hai mô hình này khá tương đồng về những gì chúng có thể biểu diễn, và một số cơ sở dữ liệu đồ thị (như Amazon Neptune) hỗ trợ cả hai mô hình.
Chúng ta cũng sẽ xem xét bốn ngôn ngữ truy vấn cho đồ thị (Cypher, SPARQL, Datalog và GraphQL), cũng như hỗ trợ SQL để truy vấn đồ thị. Còn có các ngôn ngữ truy vấn đồ thị khác, chẳng hạn như Gremlin 37, nhưng những ngôn ngữ này sẽ cho chúng ta cái nhìn tổng quan đại diện.
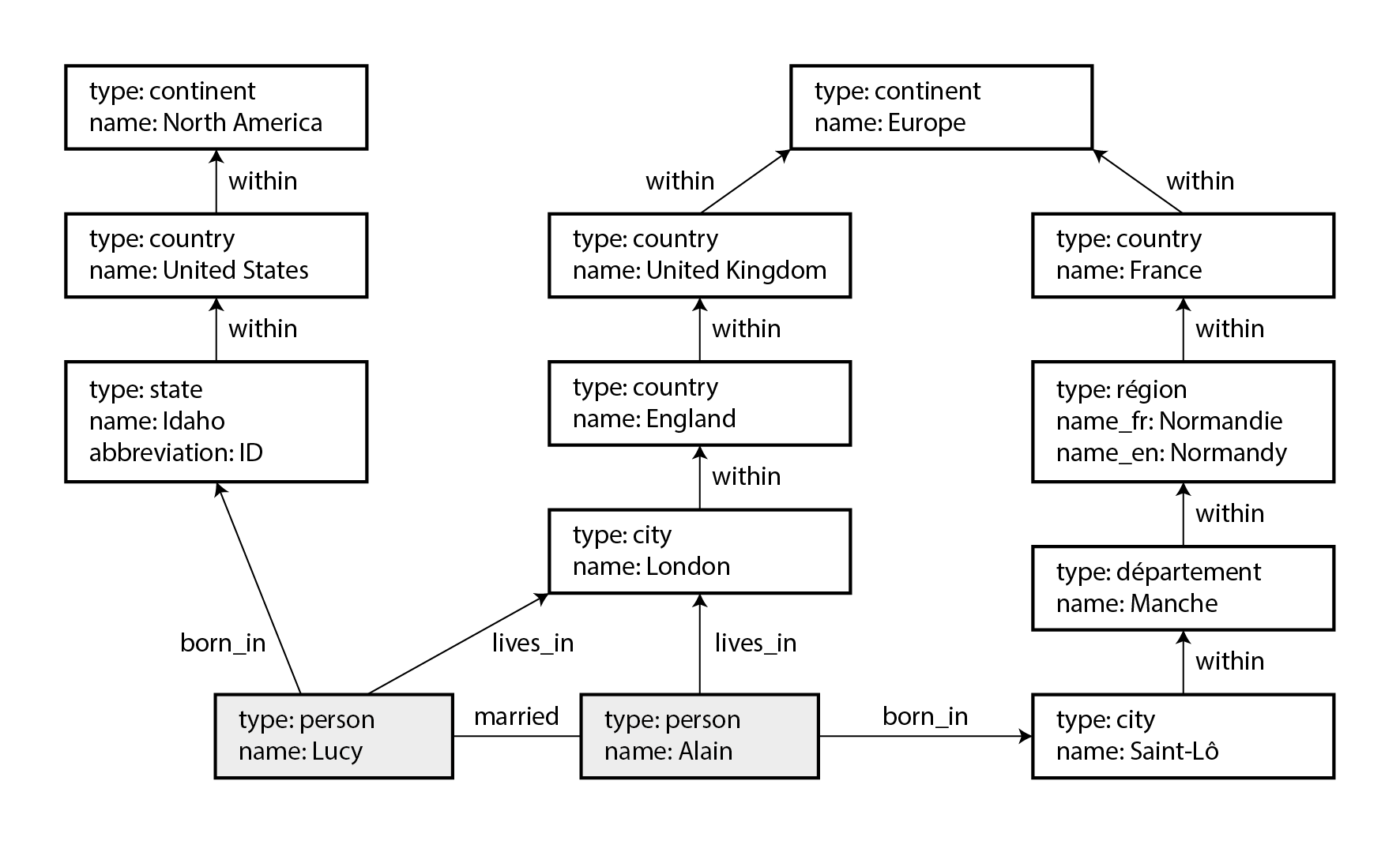
Để minh họa các ngôn ngữ và mô hình khác nhau này, phần này sử dụng đồ thị được trình bày trong Hình 3-6 làm ví dụ xuyên suốt. Đồ thị này có thể được lấy từ một mạng xã hội hoặc cơ sở dữ liệu phả hệ: nó hiển thị hai người, Lucy từ Idaho và Alain từ Saint-Lô, Pháp. Họ đã kết hôn và đang sống ở London. Mỗi người và mỗi địa điểm được biểu diễn dưới dạng một đỉnh, và các mối quan hệ giữa họ dưới dạng cạnh. Ví dụ này sẽ giúp minh họa một số truy vấn dễ thực hiện trong cơ sở dữ liệu đồ thị nhưng khó trong các mô hình khác.
Property Graph
Trong mô hình property graph (còn gọi là labeled property graph, đồ thị thuộc tính có nhãn), mỗi đỉnh bao gồm:
- Một định danh duy nhất (unique identifier)
- Một nhãn (label, chuỗi ký tự) để mô tả loại đối tượng mà đỉnh này biểu diễn
- Một tập hợp các cạnh đi ra (outgoing edges)
- Một tập hợp các cạnh đi vào (incoming edges)
- Một tập hợp các thuộc tính (properties, cặp khóa-giá trị)
Mỗi cạnh bao gồm:
- Một định danh duy nhất
- Đỉnh mà cạnh bắt đầu (đỉnh đuôi, tail vertex)
- Đỉnh mà cạnh kết thúc (đỉnh đầu, head vertex)
- Một nhãn để mô tả loại quan hệ giữa hai đỉnh
- Một tập hợp các thuộc tính (cặp khóa-giá trị)
Bạn có thể hình dung một kho lưu trữ đồ thị gồm hai bảng quan hệ, một bảng cho đỉnh và một bảng cho cạnh, như được trình bày trong Ví dụ 3-3 (lược đồ này sử dụng kiểu dữ liệu jsonb của PostgreSQL để lưu trữ các thuộc tính của mỗi đỉnh hoặc cạnh). Đỉnh đầu và đỉnh đuôi được lưu trữ cho mỗi cạnh; nếu bạn muốn tập hợp các cạnh đi vào hoặc đi ra của một đỉnh, bạn có thể truy vấn bảng edges theo head_vertex hoặc tail_vertex.
Example 3-3. Representing a property graph using a relational schema
CREATE TABLE vertices (
vertex_id integer PRIMARY KEY,
label text,
properties jsonb
);
CREATE TABLE edges (
edge_id integer PRIMARY KEY,
tail_vertex integer REFERENCES vertices (vertex_id),
head_vertex integer REFERENCES vertices (vertex_id),
label text,
properties jsonb
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);Một số khía cạnh quan trọng của mô hình này là:
- Bất kỳ đỉnh nào cũng có thể có một cạnh kết nối nó với bất kỳ đỉnh nào khác. Không có lược đồ nào hạn chế những loại thứ gì có thể hoặc không thể được liên kết với nhau.
- Với bất kỳ đỉnh nào, bạn có thể tìm thấy hiệu quả cả cạnh đi vào lẫn cạnh đi ra của nó, và do đó duyệt (traverse) đồ thị, tức là đi theo một đường dẫn qua chuỗi các đỉnh, cả tiến lẫn lùi.
(Đó là lý do tại sao Ví dụ 3-3 có chỉ mục trên cả hai cột
tail_vertexvàhead_vertex.) - Bằng cách sử dụng các nhãn khác nhau cho các loại đỉnh và quan hệ khác nhau, bạn có thể lưu trữ nhiều loại thông tin khác nhau trong một đồ thị duy nhất, trong khi vẫn duy trì mô hình dữ liệu gọn gàng.
Bảng cạnh (edges table) giống như bảng kết hợp nhiều-nhiều/bảng join mà chúng ta đã thấy trong “Many-to-One and Many-to-Many Relationships”, được tổng quát hóa để cho phép lưu nhiều loại quan hệ khác nhau trong cùng một bảng. Cũng có thể có chỉ mục trên các nhãn và thuộc tính, cho phép tìm kiếm hiệu quả các đỉnh hoặc cạnh có thuộc tính nhất định.
Note
A limitation of graph models is that an edge can only associate two vertices with each other, whereas a relational join table can represent three-way or even higher-degree relationships by having multiple foreign key references on a single row. Such relationships can be represented in a graph by creating an additional vertex corresponding to each row of the join table, and edges to/from that vertex, or by using a hypergraph.
Những tính năng đó mang lại cho đồ thị rất nhiều linh hoạt cho việc mô hình hóa dữ liệu, như được minh họa trong Hình 3-6. Hình này cho thấy một số điều khó biểu diễn trong lược đồ quan hệ truyền thống, chẳng hạn như các cấu trúc vùng khác nhau ở các quốc gia khác nhau (Pháp có département và région, trong khi Mỹ có county và state), những điểm đặc biệt lịch sử như một quốc gia nằm trong một quốc gia khác (tạm thời bỏ qua sự phức tạp của các nhà nước có chủ quyền), và mức độ chi tiết khác nhau của dữ liệu (nơi cư trú hiện tại của Lucy được chỉ định đến cấp thành phố, trong khi nơi sinh của cô chỉ được chỉ định ở cấp bang).
Bạn có thể hình dung việc mở rộng đồ thị để bao gồm nhiều sự kiện khác về Lucy và Alain, hoặc những người khác. Ví dụ, bạn có thể dùng nó để chỉ ra bất kỳ dị ứng thực phẩm nào họ có (bằng cách giới thiệu một đỉnh cho mỗi chất gây dị ứng, và một cạnh giữa một người và chất gây dị ứng để chỉ ra sự dị ứng), và liên kết các chất gây dị ứng với một tập hợp các đỉnh cho thấy thực phẩm nào chứa chất nào. Sau đó bạn có thể viết một truy vấn để tìm ra những gì an toàn cho mỗi người ăn. Đồ thị phù hợp cho khả năng tiến hóa (evolvability): khi bạn thêm tính năng vào ứng dụng của mình, đồ thị có thể dễ dàng được mở rộng để thích nghi với các thay đổi trong cấu trúc dữ liệu của ứng dụng.
Ngôn Ngữ Truy Vấn Cypher
Cypher là ngôn ngữ truy vấn cho property graph, ban đầu được tạo ra cho cơ sở dữ liệu đồ thị Neo4j, và sau này được phát triển thành một tiêu chuẩn mở gọi là openCypher 38. Ngoài Neo4j, Cypher được hỗ trợ bởi Memgraph, KùzuDB 35, Amazon Neptune, Apache AGE (với lưu trữ trong PostgreSQL), và những cái khác. Tên này được đặt theo một nhân vật trong bộ phim The Matrix và không liên quan đến mật mã học (cipher) 39.
Ví dụ 3-4 trình bày truy vấn Cypher để chèn phần bên trái của Hình 3-6 vào một cơ sở dữ liệu đồ thị. Phần còn lại của đồ thị có thể được thêm vào tương tự. Mỗi đỉnh được đặt một tên ký hiệu như usa hoặc idaho. Tên đó không được lưu trong cơ sở dữ liệu, mà chỉ được sử dụng nội bộ trong truy vấn để tạo cạnh giữa các đỉnh, sử dụng ký hiệu mũi tên: (idaho) -[:WITHIN]-> (usa) tạo một cạnh có nhãn WITHIN, với idaho là đỉnh đuôi và usa là đỉnh đầu.
Example 3-4. A subset of the data in [Figure 3-6](/en/ch3#fig_datamodels_graph), represented as a Cypher query
CREATE
(namerica :Location {name:'North America', type:'continent'}),
(usa :Location {name:'United States', type:'country' }),
(idaho :Location {name:'Idaho', type:'state' }),
(lucy :Person {name:'Lucy' }),
(idaho) -[:WITHIN ]-> (usa) -[:WITHIN]-> (namerica),
(lucy) -[:BORN_IN]-> (idaho)Khi tất cả các đỉnh và cạnh của Hình 3-6 được thêm vào cơ sở dữ liệu, chúng ta có thể bắt đầu đặt ra những câu hỏi thú vị: ví dụ, tìm tên của tất cả những người di cư từ Hoa Kỳ đến Châu Âu. Tức là, tìm tất cả các đỉnh có cạnh BORN_IN đến một địa điểm trong Mỹ, và cũng có cạnh LIVING_IN đến một địa điểm trong Châu Âu, và trả về thuộc tính name của mỗi đỉnh đó.
Ví dụ 3-5 cho thấy cách biểu diễn truy vấn đó trong Cypher. Cùng ký hiệu mũi tên được sử dụng trong mệnh đề MATCH để tìm các mẫu trong đồ thị: (person) -[:BORN_IN]-> () khớp với bất kỳ hai đỉnh nào được kết nối bởi một cạnh có nhãn BORN_IN. Đỉnh đuôi của cạnh đó được gán cho biến person, và đỉnh đầu để không tên.
Example 3-5. Cypher query to find people who emigrated from the US to Europe
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (:Location {name:'Europe'})
RETURN person.nameTruy vấn có thể được đọc như sau:
Tìm bất kỳ đỉnh nào (gọi là
person) thỏa mãn cả hai điều kiện sau:
personcó một cạnhBORN_INđi ra đến một đỉnh nào đó. Từ đỉnh đó, bạn có thể đi theo chuỗi các cạnhWITHINđi ra cho đến khi đến được một đỉnh có kiểuLocation, với thuộc tínhnamebằng"United States".- Cùng đỉnh
personđó cũng có một cạnhLIVES_INđi ra. Đi theo cạnh đó, rồi một chuỗi các cạnhWITHINđi ra, bạn cuối cùng đến được một đỉnh có kiểuLocation, với thuộc tínhnamebằng"Europe".Với mỗi đỉnh
personnhư vậy, trả về thuộc tínhname.
Có một số cách thực thi truy vấn có thể. Mô tả ở đây gợi ý rằng bạn bắt đầu bằng cách quét tất cả người dùng trong cơ sở dữ liệu, kiểm tra nơi sinh và nơi cư trú của mỗi người, và chỉ trả về những người đáp ứng tiêu chí.
Nhưng tương đương, bạn cũng có thể bắt đầu từ hai đỉnh Location và làm ngược lại. Nếu có chỉ mục trên thuộc tính name, bạn có thể tìm hiệu quả hai đỉnh biểu diễn Mỹ và Châu Âu. Sau đó bạn có thể tiến hành tìm tất cả các địa điểm (bang, vùng, thành phố, v.v.) ở Mỹ và Châu Âu tương ứng bằng cách đi theo tất cả các cạnh WITHIN đi vào. Cuối cùng, bạn có thể tìm kiếm những người có thể được tìm thấy qua cạnh BORN_IN hoặc LIVES_IN đi vào tại một trong các đỉnh địa điểm.
Truy Vấn Đồ Thị trong SQL
Ví dụ 3-3 gợi ý rằng dữ liệu đồ thị có thể được biểu diễn trong cơ sở dữ liệu quan hệ. Nhưng nếu chúng ta đặt dữ liệu đồ thị trong cấu trúc quan hệ, chúng ta có thể truy vấn nó bằng SQL không?
Câu trả lời là có, nhưng với một số khó khăn. Mỗi cạnh bạn duyệt trong một truy vấn đồ thị thực chất là một phép join với bảng edges. Trong cơ sở dữ liệu quan hệ, bạn thường biết trước những join nào bạn cần trong truy vấn. Mặt khác, trong một truy vấn đồ thị, bạn có thể cần duyệt qua một số lượng cạnh biến đổi trước khi tìm thấy đỉnh bạn đang tìm, tức là số lượng join không cố định trước.
Trong ví dụ của chúng ta, điều đó xảy ra trong mẫu () -[:WITHIN*0..]-> () trong truy vấn Cypher. Cạnh LIVES_IN của một người có thể trỏ đến bất kỳ loại địa điểm nào: một con phố, một thành phố, một quận, một vùng, một bang, v.v. Một thành phố có thể nằm WITHIN một vùng, một vùng WITHIN một bang, một bang WITHIN một quốc gia, v.v. Cạnh LIVES_IN có thể trỏ trực tiếp đến đỉnh địa điểm bạn đang tìm, hoặc nó có thể cách vài cấp trong hệ thống phân cấp địa điểm.
Trong Cypher, :WITHIN*0.. biểu diễn điều đó rất súc tích: nó có nghĩa là “đi theo cạnh WITHIN, không hoặc nhiều lần.” Nó giống như toán tử * trong biểu thức chính quy.
Kể từ SQL:1999, ý tưởng về các đường duyệt có độ dài biến đổi trong một truy vấn có thể được biểu diễn bằng thứ gọi là biểu thức bảng chung đệ quy (recursive common table expressions, cú pháp WITH RECURSIVE). Ví dụ 3-6 cho thấy cùng truy vấn đó, tìm tên những người di cư từ Mỹ đến Châu Âu, được biểu diễn trong SQL bằng kỹ thuật này. Tuy nhiên, cú pháp rất rườm rà so với Cypher.
Example 3-6. The same query as [Example 3-5](/en/ch3#fig_cypher_query), written in SQL using recursive common table expressions
WITH RECURSIVE
-- in_usa is the set of vertex IDs of all locations within the United States
in_usa(vertex_id) AS (
SELECT vertex_id FROM vertices
WHERE label = 'Location' AND properties->>'name' = 'United States' ❶
UNION
SELECT edges.tail_vertex FROM edges ❷
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'within'
),
-- in_europe is the set of vertex IDs of all locations within Europe
in_europe(vertex_id) AS (
SELECT vertex_id FROM vertices
WHERE label = 'location' AND properties->>'name' = 'Europe' ❸
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'within'
),
-- born_in_usa is the set of vertex IDs of all people born in the US
born_in_usa(vertex_id) AS ( ❹
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'born_in'
),
-- lives_in_europe is the set of vertex IDs of all people living in Europe
lives_in_europe(vertex_id) AS ( ❺
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'lives_in'
)
SELECT vertices.properties->>'name'
FROM vertices
-- join to find those people who were both born in the US *and* live in Europe
JOIN born_in_usa ON vertices.vertex_id = born_in_usa.vertex_id ❻
JOIN lives_in_europe ON vertices.vertex_id = lives_in_europe.vertex_id;❶: Đầu tiên tìm đỉnh có thuộc tính name với giá trị "United States", và đặt nó làm phần tử đầu tiên của tập hợp đỉnh in_usa.
❷: Đi theo tất cả các cạnh within đi vào từ các đỉnh trong tập hợp in_usa, và thêm chúng vào cùng tập hợp, cho đến khi tất cả các cạnh within đi vào đã được duyệt qua.
❸: Làm tương tự bắt đầu từ đỉnh có thuộc tính name với giá trị "Europe", và xây dựng tập hợp đỉnh in_europe.
❹: Với mỗi đỉnh trong tập hợp in_usa, đi theo các cạnh born_in đi vào để tìm những người sinh ra ở một nơi nào đó trong Hoa Kỳ.
❺: Tương tự, với mỗi đỉnh trong tập hợp in_europe, đi theo các cạnh lives_in đi vào để tìm những người sống ở Châu Âu.
❻: Cuối cùng, lấy giao của tập hợp những người sinh ra ở Mỹ với tập hợp những người sống ở Châu Âu, bằng cách join chúng.
Thực tế là một truy vấn Cypher 4 dòng cần đến 31 dòng trong SQL cho thấy sự khác biệt lớn mà việc chọn đúng mô hình dữ liệu và ngôn ngữ truy vấn có thể tạo ra. Và đây mới chỉ là khởi đầu; còn nhiều chi tiết cần xem xét, ví dụ như xử lý vòng lặp, và lựa chọn giữa duyệt theo chiều rộng hoặc chiều sâu 40.
Oracle có một phần mở rộng SQL khác cho truy vấn đệ quy, mà nó gọi là hierarchical (phân cấp) 41.
Tuy nhiên, tình hình có thể đang cải thiện: tại thời điểm viết bài, có kế hoạch thêm một ngôn ngữ truy vấn đồ thị gọi là GQL vào tiêu chuẩn SQL 42 43, ngôn ngữ này sẽ cung cấp cú pháp lấy cảm hứng từ Cypher, GSQL 44 và PGQL 45.
Triple-Store và SPARQL
Mô hình triple-store về cơ bản tương đương với mô hình property graph, chỉ sử dụng các từ khác nhau để mô tả cùng một ý tưởng. Tuy nhiên, nó vẫn đáng được thảo luận, vì có nhiều công cụ và ngôn ngữ cho triple-store có thể là những bổ sung có giá trị cho bộ công cụ xây dựng ứng dụng của bạn.
Trong một triple-store, tất cả thông tin được lưu trữ dưới dạng các câu lệnh ba phần rất đơn giản: (chủ thể, vị từ, đối tượng) hay (subject, predicate, object). Ví dụ, trong bộ ba (Jim, thích, chuối), Jim là chủ thể, thích là vị từ (động từ), và chuối là đối tượng.
Chủ thể của một bộ ba tương đương với một đỉnh trong đồ thị. Đối tượng là một trong hai thứ:
- Một giá trị của kiểu dữ liệu nguyên thủy, chẳng hạn như chuỗi hoặc số. Trong trường hợp đó, vị từ và đối tượng của bộ ba tương đương với khóa và giá trị của một thuộc tính trên đỉnh chủ thể.
Sử dụng ví dụ từ Hình 3-6, (lucy, birthYear, 1989) giống như một đỉnh
lucyvới các thuộc tính{"birthYear": 1989}. - Một đỉnh khác trong đồ thị. Trong trường hợp đó, vị từ là một cạnh trong đồ thị, chủ thể là đỉnh đuôi, và đối tượng là đỉnh đầu. Ví dụ, trong (lucy, marriedTo, alain) thì chủ thể và đối tượng lucy và alain đều là đỉnh, và vị từ marriedTo là nhãn của cạnh kết nối chúng.
Note
To be precise, databases that offer a triple-like data model often need to store some additional metadata on each tuple. For example, AWS Neptune uses quads (4-tuples) by adding a graph ID to each triple 46; triple 46; Datomic sử dụng 5-tuple, mở rộng mỗi triple với một transaction ID và một boolean để chỉ định việc xóa 47. Vì các cơ sở dữ liệu này vẫn giữ cấu trúc cơ bản subject-predicate-object (chủ thể-vị từ-đối tượng) đã giải thích ở trên, cuốn sách này vẫn gọi chúng là triple-store.
Ví dụ 3-7 hiển thị cùng dữ liệu như trong Ví dụ 3-4, được viết dưới dạng triple theo định dạng gọi là Turtle, một tập con của Notation3 (N3) 48.
Ví dụ 3-7. Một tập con của dữ liệu trong [Hình 3-6](/vi/ch3#fig_datamodels_graph), được biểu diễn dưới dạng Turtle triple
@prefix : <urn:example:>.
_:lucy a :Person.
_:lucy :name "Lucy".
_:lucy :bornIn _:idaho.
_:idaho a :Location.
_:idaho :name "Idaho".
_:idaho :type "state".
_:idaho :within _:usa.
_:usa a :Location.
_:usa :name "United States".
_:usa :type "country".
_:usa :within _:namerica.
_:namerica a :Location.
_:namerica :name "North America".
_:namerica :type "continent".Trong ví dụ này, các đỉnh của đồ thị được viết dưới dạng _:someName. Tên này không có ý nghĩa gì
bên ngoài tệp này; nó tồn tại chỉ vì nếu không có nó, chúng ta sẽ không biết những triple nào tham chiếu đến
cùng một đỉnh. Khi vị từ biểu diễn một cạnh, đối tượng là một đỉnh, ví dụ như _:idaho :within _:usa. Khi vị từ là một thuộc tính, đối tượng là một chuỗi ký tự (string literal), ví dụ như _:usa :name "United States".
Việc lặp lại cùng một chủ thể nhiều lần khá dư thừa, nhưng may mắn thay bạn có thể dùng dấu chấm phẩy để nói nhiều điều về cùng một chủ thể. Điều này khiến định dạng Turtle khá dễ đọc: xem Ví dụ 3-8.
Ví dụ 3-8. Cách viết dữ liệu trong [Ví dụ 3-7](/vi/ch3#fig_graph_n3_triples) ngắn gọn hơn
@prefix : <urn:example:>.
_:lucy a :Person; :name "Lucy"; :bornIn _:idaho.
_:idaho a :Location; :name "Idaho"; :type "state"; :within _:usa.
_:usa a :Location; :name "United States"; :type "country"; :within _:namerica.
_:namerica a :Location; :name "North America"; :type "continent".THE SEMANTIC WEB
Một phần nỗ lực nghiên cứu và phát triển liên quan đến triple-store xuất phát từ Semantic Web (Web ngữ nghĩa),
một sáng kiến đầu những năm 2000 nhằm tạo điều kiện trao đổi dữ liệu trên toàn internet bằng cách công bố dữ liệu không chỉ dưới dạng
trang web cho người đọc, mà còn ở định dạng chuẩn hóa, có thể đọc được bởi máy. Mặc dù Semantic Web
theo như hình dung ban đầu đã không thành công 49 50,
di sản của dự án Semantic Web vẫn còn tồn tại trong một số công nghệ cụ thể: các chuẩn linked data
(dữ liệu liên kết) như JSON-LD 51, ontology (bản thể học) dùng trong khoa học y sinh 52, Open Graph protocol của Facebook 53
(được dùng để hiển thị preview liên kết 54), knowledge graph (đồ thị tri thức) như Wikidata, và các từ vựng chuẩn hóa cho dữ liệu có cấu trúc được duy trì bởi schema.org.
Triple-store là một công nghệ Semantic Web khác đã tìm được ứng dụng ngoài phạm vi sử dụng ban đầu: ngay cả khi bạn không quan tâm đến Semantic Web, triple vẫn có thể là một mô hình dữ liệu nội bộ tốt cho các ứng dụng.
Mô hình dữ liệu RDF
Ngôn ngữ Turtle chúng ta dùng trong Ví dụ 3-8 thực ra là một cách mã hóa dữ liệu trong Resource Description Framework (RDF) 55, một mô hình dữ liệu được thiết kế cho Semantic Web. Dữ liệu RDF cũng có thể được mã hóa theo các cách khác, ví dụ (dài dòng hơn) trong XML, như được trình bày trong Ví dụ 3-9. Các công cụ như Apache Jena có thể tự động chuyển đổi giữa các định dạng mã hóa RDF khác nhau.
Ví dụ 3-9. Dữ liệu của [Ví dụ 3-8](/vi/ch3#fig_graph_n3_shorthand), biểu diễn bằng cú pháp RDF/XML
<rdf:RDF xmlns="urn:example:"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Location rdf:nodeID="idaho">
<name>Idaho</name>
<type>state</type>
<within>
<Location rdf:nodeID="usa">
<name>United States</name>
<type>country</type>
<within>
<Location rdf:nodeID="namerica">
<name>North America</name>
<type>continent</type>
</Location>
</within>
</Location>
</within>
</Location>
<Person rdf:nodeID="lucy">
<name>Lucy</name>
<bornIn rdf:nodeID="idaho"/>
</Person>
</rdf:RDF>RDF có một vài điểm đặc thù do được thiết kế cho việc trao đổi dữ liệu trên toàn internet. Chủ thể,
vị từ và đối tượng của một triple thường là các URI. Ví dụ, một vị từ có thể là một URI
như <http://my-company.com/namespace#within> hoặc <http://my-company.com/namespace#lives_in>,
thay vì chỉ là WITHIN hay LIVES_IN. Lý do đằng sau thiết kế này là bạn phải có khả năng
kết hợp dữ liệu của mình với dữ liệu của người khác, và nếu họ gán nghĩa khác cho từ
within hoặc lives_in, bạn sẽ không bị xung đột vì vị từ của họ thực ra là
<http://other.org/foo#within> và <http://other.org/foo#lives_in>.
URL <http://my-company.com/namespace> không nhất thiết phải trỏ đến bất kỳ thứ gì,
từ góc độ của RDF, nó chỉ đơn giản là một namespace (không gian tên). Để tránh gây nhầm lẫn tiềm tàng với các URL dạng http://, các
ví dụ trong phần này sử dụng các URI không phân giải được như urn:example:within. May mắn thay, bạn có thể
chỉ cần khai báo tiền tố này một lần ở đầu tệp và sau đó không cần lo đến nó nữa.
Ngôn ngữ truy vấn SPARQL
SPARQL là ngôn ngữ truy vấn cho triple-store sử dụng mô hình dữ liệu RDF 56. (Đây là từ viết tắt của SPARQL Protocol and RDF Query Language, đọc là “sparkle”.) SPARQL ra đời trước Cypher, và vì pattern matching (so khớp mẫu) của Cypher được mượn từ SPARQL, chúng trông khá tương tự nhau.
Câu truy vấn tương tự như trước, tìm những người đã di chuyển từ Mỹ sang châu Âu, cũng ngắn gọn trong SPARQL như trong Cypher (xem Ví dụ 3-10).
Ví dụ 3-10. Câu truy vấn tương tự như [Ví dụ 3-5](/vi/ch3#fig_cypher_query), được biểu diễn trong SPARQL
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}Cấu trúc rất tương đồng. Hai biểu thức sau đây là tương đương (biến bắt đầu bằng dấu hỏi trong SPARQL):
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (location) # Cypher
?person :bornIn / :within* ?location. # SPARQLVì RDF không phân biệt giữa thuộc tính và cạnh mà chỉ dùng vị từ cho cả hai, bạn
có thể dùng cùng cú pháp để so khớp thuộc tính. Trong biểu thức sau, biến usa được
gán với bất kỳ đỉnh nào có thuộc tính name có giá trị là chuỗi "United States":
(usa {name:'United States'}) # Cypher
?usa :name "United States". # SPARQLSPARQL được hỗ trợ bởi Amazon Neptune, AllegroGraph, Blazegraph, OpenLink Virtuoso, Apache Jena và nhiều triple-store khác 36.
Datalog: Truy vấn quan hệ đệ quy
Datalog là một ngôn ngữ cũ hơn nhiều so với SPARQL hay Cypher: nó xuất hiện từ nghiên cứu học thuật vào những năm 1980 57 58 59. Ngôn ngữ này ít được biết đến trong giới kỹ sư phần mềm và không được hỗ trợ rộng rãi trong các cơ sở dữ liệu phổ thông, nhưng đáng lẽ nó phải được biết đến nhiều hơn vì đây là một ngôn ngữ rất biểu đạt và đặc biệt mạnh cho các truy vấn phức tạp. Một số cơ sở dữ liệu ngách, bao gồm Datomic, LogicBlox, CozoDB và LinkedIn’s LIquid 60 sử dụng Datalog làm ngôn ngữ truy vấn.
Datalog thực sự dựa trên mô hình dữ liệu quan hệ, không phải đồ thị, nhưng nó xuất hiện trong phần cơ sở dữ liệu đồ thị của cuốn sách này vì các truy vấn đệ quy trên đồ thị là điểm mạnh đặc biệt của Datalog.
Nội dung của một cơ sở dữ liệu Datalog bao gồm các fact (sự kiện), và mỗi fact tương ứng với một hàng trong bảng
quan hệ. Ví dụ, giả sử chúng ta có một bảng location chứa các địa điểm và có ba
cột: ID, name và type. Sự kiện rằng Mỹ là một quốc gia có thể được viết là
location(2, "United States", "country"), trong đó 2 là ID của Mỹ. Nói chung, câu lệnh
table(val1, val2, …) có nghĩa là table chứa một hàng mà cột đầu tiên chứa val1,
cột thứ hai chứa val2, và cứ thế tiếp tục.
Ví dụ 3-11 cho thấy cách viết dữ liệu từ phía bên trái của
Hình 3-6 trong Datalog. Các cạnh của đồ thị (within, born_in và lives_in)
được biểu diễn dưới dạng bảng join hai cột. Ví dụ, Lucy có ID 100 và Idaho có ID 3,
nên mối quan hệ “Lucy được sinh ra ở Idaho” được biểu diễn là born_in(100, 3).
Ví dụ 3-11. Một tập con của dữ liệu trong [Hình 3-6](/vi/ch3#fig_datamodels_graph), được biểu diễn dưới dạng Datalog fact
location(1, "North America", "continent").
location(2, "United States", "country").
location(3, "Idaho", "state").
within(2, 1). /* US is in North America */
within(3, 2). /* Idaho is in the US */
person(100, "Lucy").
born_in(100, 3). /* Lucy was born in Idaho */Bây giờ khi đã định nghĩa dữ liệu, chúng ta có thể viết câu truy vấn tương tự như trước, như được trình bày trong Ví dụ 3-12. Trông có vẻ khác đôi chút so với Cypher hay SPARQL, nhưng đừng để điều đó làm bạn nản lòng. Datalog là một tập con của Prolog, một ngôn ngữ lập trình mà bạn có thể đã gặp nếu từng học khoa học máy tính.
Ví dụ 3-12. Câu truy vấn tương tự như [Ví dụ 3-5](/vi/ch3#fig_cypher_query), được biểu diễn trong Datalog
within_recursive(LocID, PlaceName) :- location(LocID, PlaceName, _). /* Rule 1 */
within_recursive(LocID, PlaceName) :- within(LocID, ViaID), /* Rule 2 */
within_recursive(ViaID, PlaceName).
migrated(PName, BornIn, LivingIn) :- person(PersonID, PName), /* Rule 3 */
born_in(PersonID, BornID),
within_recursive(BornID, BornIn),
lives_in(PersonID, LivingID),
within_recursive(LivingID, LivingIn).
us_to_europe(Person) :- migrated(Person, "United States", "Europe"). /* Rule 4 */
/* us_to_europe contains the row "Lucy". */Cypher và SPARQL bắt đầu ngay với SELECT, nhưng Datalog tiến từng bước nhỏ một. Chúng ta
định nghĩa các rule (quy tắc) để dẫn xuất các bảng ảo mới từ các fact nền tảng. Các bảng dẫn xuất này
giống như các SQL view (ảo): chúng không được lưu trong cơ sở dữ liệu, nhưng bạn có thể truy vấn chúng theo cách
tương tự như một bảng chứa các fact được lưu trữ.
Trong Ví dụ 3-12 chúng ta định nghĩa ba bảng dẫn xuất: within_recursive, migrated và
us_to_europe. Tên và các cột của các bảng ảo được định nghĩa bởi những gì xuất hiện trước ký hiệu
:- của mỗi quy tắc. Ví dụ, migrated(PName, BornIn, LivingIn) là một bảng ảo có
ba cột: tên của một người, tên nơi họ được sinh ra, và tên nơi họ đang sinh sống.
Nội dung của một bảng ảo được định nghĩa bởi phần của quy tắc sau ký hiệu :-, nơi chúng ta
cố gắng tìm các hàng khớp với một mẫu nhất định trong các bảng. Ví dụ, person(PersonID, PName)
khớp với hàng person(100, "Lucy"), với biến PersonID gán với giá trị 100 và biến
PName gán với giá trị "Lucy". Một quy tắc được áp dụng nếu hệ thống có thể tìm thấy sự khớp cho
tất cả các mẫu ở phía bên phải của toán tử :-. Khi quy tắc được áp dụng, sẽ xảy ra như thể
phía bên trái của :- được thêm vào cơ sở dữ liệu (với các biến được thay thế bằng các giá trị mà chúng đã khớp).
Một cách có thể áp dụng các quy tắc là như sau (và như được minh họa trong Hình 3-7):
location(1, "North America", "continent")tồn tại trong cơ sở dữ liệu, vì vậy quy tắc 1 được áp dụng. Nó sinh rawithin_recursive(1, "North America").within(2, 1)tồn tại trong cơ sở dữ liệu và bước trước đã sinh rawithin_recursive(1, "North America"), nên quy tắc 2 được áp dụng. Nó sinh rawithin_recursive(2, "North America").within(3, 2)tồn tại trong cơ sở dữ liệu và bước trước đã sinh rawithin_recursive(2, "North America"), nên quy tắc 2 được áp dụng. Nó sinh rawithin_recursive(3, "North America").
Bằng cách áp dụng lặp đi lặp lại quy tắc 1 và 2, bảng ảo within_recursive có thể cho chúng ta biết tất cả
các địa điểm ở Bắc Mỹ (hoặc bất kỳ địa điểm nào khác) có trong cơ sở dữ liệu của chúng ta.
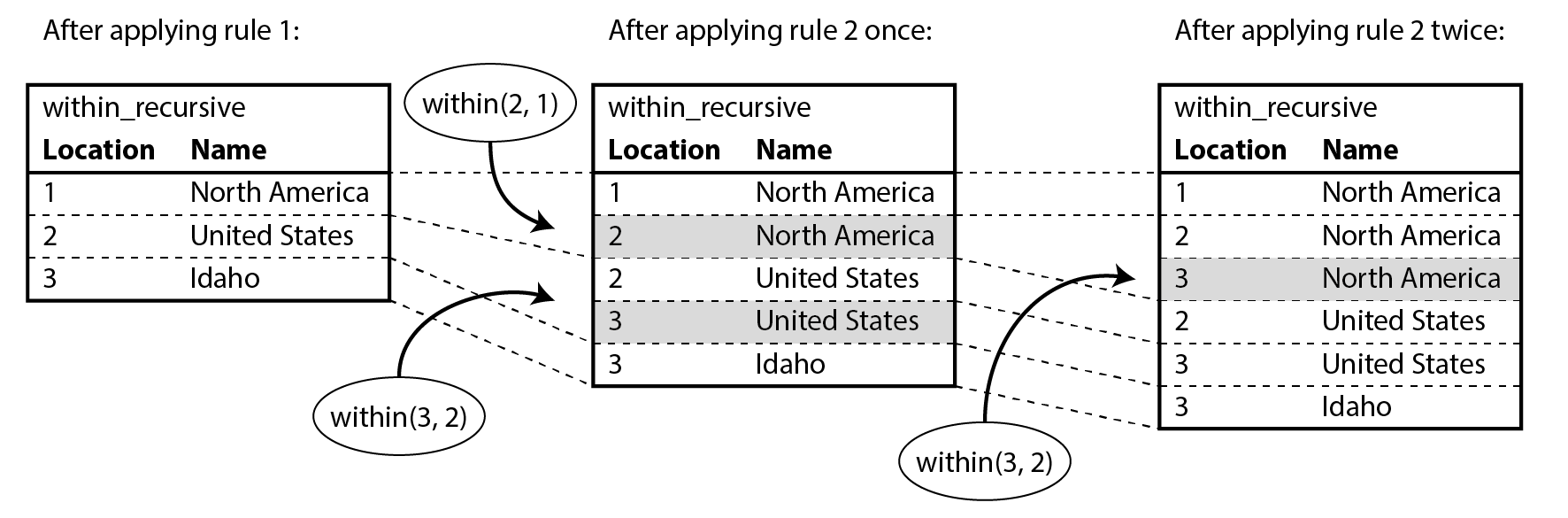
Hình 3-7. Xác định rằng Idaho nằm ở Bắc Mỹ, sử dụng các quy tắc Datalog từ Ví dụ 3-12.
Hình 3-7. Xác định rằng Idaho nằm ở Bắc Mỹ, sử dụng các quy tắc Datalog từ Ví dụ 3-12.
Bây giờ quy tắc 3 có thể tìm những người được sinh ra ở một địa điểm nào đó BornIn và đang sống ở một địa điểm nào đó
LivingIn. Quy tắc 4 gọi quy tắc 3 với BornIn = 'United States' và
LivingIn = 'Europe', và chỉ trả về tên của những người khớp với
điều kiện tìm kiếm. Bằng cách truy vấn nội dung của bảng ảo us_to_europe, hệ thống Datalog cuối cùng
nhận được câu trả lời giống như trong các truy vấn Cypher và SPARQL trước đó.
Cách tiếp cận của Datalog đòi hỏi một kiểu tư duy khác so với các ngôn ngữ truy vấn khác được thảo luận trong chương này. Nó cho phép xây dựng các truy vấn phức tạp từng quy tắc một, với quy tắc này tham chiếu đến quy tắc khác, tương tự như cách bạn chia nhỏ code thành các hàm gọi lẫn nhau. Cũng giống như các hàm có thể đệ quy, các quy tắc Datalog cũng có thể tự gọi chính mình, như quy tắc 2 trong Ví dụ 3-12, điều này cho phép duyệt đồ thị trong các truy vấn Datalog.
GraphQL
GraphQL là một ngôn ngữ truy vấn mà theo thiết kế, bị hạn chế hơn nhiều so với các ngôn ngữ truy vấn khác chúng ta đã thấy trong chương này. Mục đích của GraphQL là cho phép phần mềm client chạy trên thiết bị của người dùng (chẳng hạn như ứng dụng di động hoặc frontend ứng dụng web JavaScript) yêu cầu một tài liệu JSON với một cấu trúc cụ thể, chứa các trường cần thiết để hiển thị giao diện người dùng. Các interface GraphQL cho phép các nhà phát triển thay đổi nhanh chóng các truy vấn trong code client mà không cần thay đổi các API phía server.
Tính linh hoạt của GraphQL đi kèm với chi phí nhất định. Các tổ chức áp dụng GraphQL thường cần các công cụ để chuyển đổi truy vấn GraphQL thành các yêu cầu đến các service nội bộ, thường sử dụng REST hoặc gRPC (xem Chương 5). Phân quyền, giới hạn tốc độ và các thách thức hiệu năng là những mối lo ngại bổ sung 61. Ngôn ngữ truy vấn của GraphQL cũng bị hạn chế vì GraphQL đến từ một nguồn không đáng tin cậy. Ngôn ngữ này không cho phép bất cứ điều gì có thể tốn kém để thực thi, vì nếu không thì người dùng có thể thực hiện các cuộc tấn công từ chối dịch vụ (denial-of-service) lên server bằng cách chạy nhiều truy vấn tốn kém. Đặc biệt, GraphQL không cho phép các truy vấn đệ quy (không giống Cypher, SPARQL, SQL hay Datalog), và không cho phép các điều kiện tìm kiếm tùy ý như “tìm những người được sinh ra ở Mỹ và hiện đang sống ở châu Âu” (trừ khi chủ sở hữu service cụ thể chọn cung cấp chức năng tìm kiếm đó).
Tuy nhiên, GraphQL vẫn hữu ích. Ví dụ 3-13 cho thấy cách bạn có thể triển khai một ứng dụng chat nhóm như Discord hay Slack sử dụng GraphQL. Truy vấn yêu cầu tất cả các channel mà người dùng có quyền truy cập, bao gồm tên channel và 50 tin nhắn gần nhất trong mỗi channel. Với mỗi tin nhắn, nó yêu cầu timestamp (dấu thời gian), nội dung tin nhắn, tên và URL ảnh đại diện của người gửi. Hơn nữa, nếu một tin nhắn là trả lời cho tin nhắn khác, truy vấn cũng yêu cầu tên người gửi và nội dung của tin nhắn được trả lời (có thể được hiển thị với font chữ nhỏ hơn phía trên câu trả lời, để cung cấp thêm ngữ cảnh).
Ví dụ 3-13. Ví dụ truy vấn GraphQL cho ứng dụng chat nhóm
query ChatApp {
channels {
name
recentMessages(latest: 50) {
timestamp
content
sender {
fullName
imageUrl
}
replyTo {
content
sender {
fullName
}
}
}
}
}Ví dụ 3-14 cho thấy một phản hồi cho truy vấn trong Ví dụ 3-13 có thể
trông như thế nào. Phản hồi là một tài liệu JSON phản chiếu cấu trúc của truy vấn: nó chứa chính xác
những thuộc tính được yêu cầu, không hơn không kém. Cách tiếp cận này có ưu điểm là server
không cần biết các thuộc tính nào client cần để hiển thị giao diện người dùng; thay vào đó, client có thể đơn giản yêu cầu những gì nó cần. Ví dụ, truy vấn này không
yêu cầu URL ảnh đại diện của người gửi tin nhắn replyTo, nhưng nếu giao diện người dùng
được thay đổi để thêm ảnh đại diện đó, client chỉ cần thêm thuộc tính imageUrl cần thiết
vào truy vấn mà không cần thay đổi server.
Ví dụ 3-14. Một phản hồi có thể có cho truy vấn trong [Ví dụ 3-13](/vi/ch3#fig_graphql_query)
{
"data": {
"channels": [
{
"name": "#general",
"recentMessages": [
{
"timestamp": 1693143014,
"content": "Hey! How are y'all doing?",
"sender": {"fullName": "Aaliyah", "imageUrl": "https://..."},
"replyTo": null
},
{
"timestamp": 1693143024,
"content": "Great! And you?",
"sender": {"fullName": "Caleb", "imageUrl": "https://..."},
"replyTo": {
"content": "Hey! How are y'all doing?",
"sender": {"fullName": "Aaliyah"}
}
},
...Trong Ví dụ 3-14, tên và URL ảnh đại diện của người gửi tin nhắn được nhúng trực tiếp vào đối tượng tin nhắn. Nếu cùng một người dùng gửi nhiều tin nhắn, thông tin này sẽ lặp lại ở mỗi tin nhắn. Về nguyên tắc, có thể giảm bớt sự trùng lặp này, nhưng GraphQL đưa ra lựa chọn thiết kế là chấp nhận kích thước phản hồi lớn hơn để việc hiển thị giao diện người dùng dựa trên dữ liệu trở nên đơn giản hơn.
Trường replyTo cũng tương tự: trong Ví dụ 3-14, tin nhắn thứ hai là phản hồi cho
tin nhắn đầu tiên, và nội dung (“Hey!…”) cũng như người gửi Aaliyah được nhân bản dưới replyTo. Có thể
thay vào đó trả về ID của tin nhắn đang được trả lời, nhưng khi đó client sẽ phải
thực hiện thêm một yêu cầu đến server nếu ID đó không nằm trong 50 tin nhắn gần nhất
được trả về. Nhân bản nội dung giúp làm việc với dữ liệu đơn giản hơn nhiều.
Cơ sở dữ liệu phía server có thể lưu trữ dữ liệu ở dạng chuẩn hóa hơn, và thực hiện các join cần thiết để xử lý một truy vấn. Ví dụ, server có thể lưu một tin nhắn cùng với user ID của người gửi và ID của tin nhắn mà nó đang trả lời; khi nhận được một truy vấn như trên, server sẽ phân giải các ID đó để tìm bản ghi tương ứng. Tuy nhiên, client chỉ có thể yêu cầu server thực hiện các join được cung cấp rõ ràng trong GraphQL schema.
Mặc dù phản hồi của một truy vấn GraphQL trông giống phản hồi từ cơ sở dữ liệu tài liệu, và mặc dù tên có chứa chữ “graph”, GraphQL có thể được triển khai trên bất kỳ loại cơ sở dữ liệu nào: quan hệ, tài liệu, hoặc đồ thị.
Event Sourcing và CQRS
Trong tất cả các mô hình dữ liệu chúng ta đã thảo luận, dữ liệu được truy vấn theo cùng dạng mà nó được ghi, dù là tài liệu JSON, các hàng trong bảng, hay các đỉnh và cạnh trong đồ thị. Tuy nhiên, trong các ứng dụng phức tạp, đôi khi khó tìm ra một biểu diễn dữ liệu duy nhất có thể đáp ứng tất cả các cách mà dữ liệu cần được truy vấn và trình bày. Trong những tình huống như vậy, sẽ có lợi khi ghi dữ liệu ở một dạng, rồi từ đó suy ra nhiều biểu diễn được tối ưu hóa cho các loại đọc khác nhau.
Chúng ta đã thấy ý tưởng này trong “Systems of Record and Derived Data”, và ETL (xem “Data Warehousing”) là một ví dụ về quá trình suy dẫn như vậy. Bây giờ chúng ta sẽ đẩy ý tưởng này xa hơn. Nếu chúng ta sẽ suy dẫn một biểu diễn dữ liệu từ một biểu diễn khác, ta có thể chọn các biểu diễn khác nhau được tối ưu hóa cho việc ghi và đọc tương ứng. Bạn sẽ mô hình hóa dữ liệu như thế nào nếu chỉ muốn tối ưu hóa cho việc ghi, và không cần quan tâm đến hiệu quả truy vấn?
Có lẽ cách đơn giản nhất, nhanh nhất và biểu đạt nhất để ghi dữ liệu là một event log (nhật ký sự kiện): mỗi lần bạn muốn ghi dữ liệu, bạn mã hóa nó thành một chuỗi tự chứa (có thể là JSON), bao gồm timestamp, rồi nối nó vào một chuỗi sự kiện. Các sự kiện trong nhật ký này là immutable (bất biến): bạn không bao giờ thay đổi hoặc xóa chúng, bạn chỉ nối thêm nhiều sự kiện hơn vào nhật ký (những sự kiện này có thể thay thế các sự kiện trước đó). Một sự kiện có thể chứa các thuộc tính tùy ý.
Hình 3-8 cho thấy một ví dụ có thể lấy từ một hệ thống quản lý hội nghị. Một hội nghị có thể là một lĩnh vực kinh doanh phức tạp: không chỉ từng người tham dự có thể đăng ký và thanh toán bằng thẻ, mà các công ty cũng có thể đặt chỗ theo lô, thanh toán bằng hóa đơn, và sau đó phân bổ chỗ cho từng người. Một số chỗ ngồi có thể được dành cho diễn giả, nhà tài trợ, tình nguyện viên hỗ trợ, và các đối tượng khác. Đặt chỗ cũng có thể bị hủy, trong khi đó, ban tổ chức hội nghị có thể thay đổi sức chứa của sự kiện bằng cách chuyển sang phòng khác. Với tất cả những điều này xảy ra cùng lúc, việc chỉ đơn giản tính số chỗ còn trống đã trở thành một truy vấn đầy thách thức.
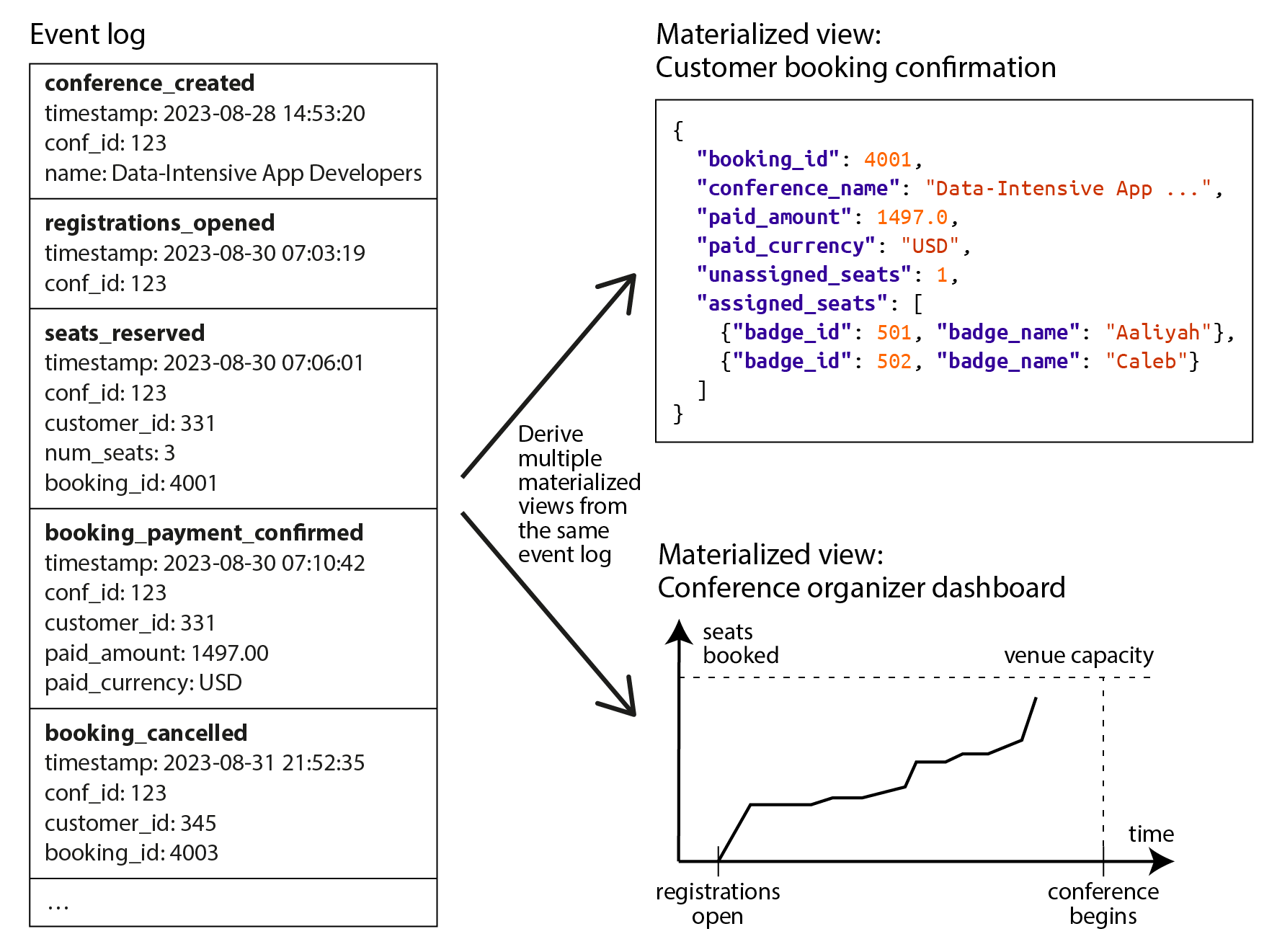
Hình 3-8. Sử dụng nhật ký các sự kiện bất biến làm nguồn sự thật, và suy dẫn các materialized view từ đó.
Trong Hình 3-8, mỗi thay đổi đối với trạng thái của hội nghị (chẳng hạn như ban tổ chức mở đăng ký, hoặc người tham dự thực hiện và hủy đăng ký) trước tiên được lưu dưới dạng sự kiện. Mỗi khi một sự kiện được nối vào nhật ký, một số materialized view (khung nhìn vật chất, còn được gọi là projection hay read model) cũng được cập nhật để phản ánh tác động của sự kiện đó. Trong ví dụ hội nghị, có thể có một materialized view thu thập tất cả thông tin liên quan đến trạng thái của từng đặt chỗ, một view khác tính toán biểu đồ cho dashboard của ban tổ chức hội nghị, và một view thứ ba tạo ra các tệp cho máy in sản xuất thẻ đeo cho người tham dự.
Ý tưởng sử dụng các sự kiện làm nguồn sự thật, và biểu diễn mỗi thay đổi trạng thái dưới dạng sự kiện, được gọi là event sourcing 62 63. Nguyên tắc duy trì các biểu diễn được tối ưu hóa cho đọc riêng biệt và suy dẫn chúng từ biểu diễn được tối ưu hóa cho ghi được gọi là command query responsibility segregation (CQRS) (phân tách trách nhiệm lệnh truy vấn) 64. Các thuật ngữ này bắt nguồn từ cộng đồng domain-driven design (DDD), mặc dù các ý tưởng tương tự đã tồn tại lâu nay, ví dụ như trong state machine replication (xem “Using shared logs”).
Khi một yêu cầu từ người dùng đến, nó được gọi là một command (lệnh), và trước tiên cần được xác thực. Chỉ khi lệnh đã được thực thi và được xác định là hợp lệ (ví dụ: có đủ chỗ trống cho một đặt chỗ được yêu cầu), nó mới trở thành một thực tế, và sự kiện tương ứng được thêm vào nhật ký. Do đó, nhật ký sự kiện chỉ nên chứa các sự kiện hợp lệ, và một consumer của nhật ký sự kiện xây dựng materialized view không được phép từ chối một sự kiện.
Khi mô hình hóa dữ liệu theo phong cách event sourcing, bạn nên đặt tên sự kiện ở thì quá khứ (ví dụ: “the seats were booked”, tức là “các chỗ đã được đặt”), vì một sự kiện là bản ghi về thực tế rằng điều gì đó đã xảy ra trong quá khứ. Dù người dùng sau này quyết định thay đổi hoặc hủy, thực tế vẫn đúng là họ đã từng có một đặt chỗ, và việc thay đổi hoặc hủy là một sự kiện riêng biệt được thêm vào sau.
Một điểm tương đồng giữa event sourcing và bảng fact trong star schema, như đã thảo luận trong “Stars and Snowflakes: Schemas for Analytics”, là cả hai đều là các tập hợp sự kiện đã xảy ra trong quá khứ. Tuy nhiên, các hàng trong một bảng fact đều có cùng một tập hợp cột, trong khi trong event sourcing có thể có nhiều loại sự kiện khác nhau, mỗi loại với các thuộc tính khác nhau. Hơn nữa, bảng fact là một tập hợp không có thứ tự, trong khi trong event sourcing thứ tự của các sự kiện là quan trọng: nếu một đặt chỗ được tạo trước rồi hủy sau, xử lý những sự kiện đó theo thứ tự sai sẽ không có ý nghĩa.
Event sourcing và CQRS có một số ưu điểm:
- Đối với những người phát triển hệ thống, các sự kiện truyền đạt rõ hơn ý định về lý do tại sao điều gì đó
xảy ra. Ví dụ, dễ hiểu hơn khi đọc sự kiện “the booking was cancelled” (đặt chỗ đã bị hủy) hơn là “cột
activetrên hàng 4001 của bảngbookingsđược đặt thànhfalse, ba hàng liên quan đến đặt chỗ đó bị xóa khỏi bảngseat_assignments, và một hàng đại diện cho khoản hoàn tiền đã được chèn vào bảngpayments”. Các thay đổi hàng đó vẫn có thể xảy ra khi một materialized view xử lý sự kiện hủy, nhưng khi chúng được thúc đẩy bởi một sự kiện, lý do của những cập nhật trở nên rõ ràng hơn nhiều. - Một nguyên tắc chủ đạo của event sourcing là các materialized view được suy dẫn từ nhật ký sự kiện theo cách có thể tái tạo: bạn phải luôn có thể xóa các materialized view và tính lại chúng bằng cách xử lý cùng các sự kiện theo cùng thứ tự, sử dụng cùng code. Nếu có lỗi trong code duy trì view, bạn chỉ cần xóa view và tính lại với code mới. Cũng dễ tìm lỗi hơn vì bạn có thể chạy lại code duy trì view bao nhiêu lần tùy thích và kiểm tra hành vi của nó.
- Bạn có thể có nhiều materialized view được tối ưu hóa cho các truy vấn cụ thể mà ứng dụng của bạn yêu cầu. Chúng có thể được lưu trữ trong cùng cơ sở dữ liệu với các sự kiện hoặc trong cơ sở dữ liệu khác, tùy thuộc vào nhu cầu. Chúng có thể sử dụng bất kỳ mô hình dữ liệu nào, và có thể được phi chuẩn hóa để đọc nhanh. Bạn thậm chí có thể chỉ giữ một view trong bộ nhớ và tránh lưu trữ nó, miễn là không sao nếu phải tính lại view từ nhật ký sự kiện mỗi khi service khởi động lại.
- Nếu bạn quyết định muốn trình bày thông tin hiện có theo một cách mới, thật dễ dàng để xây dựng một materialized view mới từ nhật ký sự kiện hiện có. Bạn cũng có thể phát triển hệ thống để hỗ trợ các tính năng mới bằng cách thêm các loại sự kiện mới, hoặc các thuộc tính mới vào các loại sự kiện hiện có (các sự kiện cũ vẫn không thay đổi). Bạn cũng có thể liên kết các hành vi mới với các sự kiện hiện có (ví dụ, khi một người tham dự hội nghị hủy, chỗ của họ có thể được cung cấp cho người tiếp theo trong danh sách chờ).
- Nếu một sự kiện được ghi nhầm, bạn có thể xóa nó đi, và sau đó bạn có thể tái tạo các view mà không có sự kiện bị xóa. Mặt khác, trong một cơ sở dữ liệu nơi bạn cập nhật và xóa dữ liệu trực tiếp, một giao dịch đã commit thường khó đảo ngược. Do đó, event sourcing có thể giảm số lượng các hành động không thể đảo ngược trong hệ thống, giúp dễ thay đổi hơn (xem “Evolvability: Making Change Easy”).
- Nhật ký sự kiện cũng có thể đóng vai trò là nhật ký kiểm toán (audit log) của mọi thứ đã xảy ra trong hệ thống, điều này có giá trị trong các ngành được quản lý chặt chẽ yêu cầu khả năng kiểm toán như vậy.
Tuy nhiên, event sourcing và CQRS cũng có nhược điểm:
- Bạn cần cẩn thận nếu có thông tin bên ngoài liên quan. Ví dụ, giả sử một sự kiện chứa một giá được tính bằng một loại tiền, và đối với một trong các view, nó cần được chuyển đổi sang một loại tiền khác. Vì tỷ giá hối đoái có thể biến động, sẽ rất có vấn đề nếu lấy tỷ giá hối đoái từ một nguồn bên ngoài khi xử lý sự kiện, vì bạn sẽ nhận được kết quả khác nếu bạn tính lại materialized view vào một ngày khác. Để làm cho logic xử lý sự kiện xác định, bạn cần bao gồm tỷ giá hối đoái trong bản thân sự kiện, hoặc có cách truy vấn tỷ giá hối đoái lịch sử tại timestamp được chỉ ra trong sự kiện, đảm bảo rằng truy vấn này luôn trả về cùng kết quả cho cùng timestamp.
- Yêu cầu rằng các sự kiện là bất biến tạo ra vấn đề nếu các sự kiện chứa dữ liệu cá nhân của người dùng, vì người dùng có thể thực hiện quyền (ví dụ: theo GDPR) yêu cầu xóa dữ liệu của họ. Nếu nhật ký sự kiện theo từng người dùng, bạn có thể chỉ cần xóa toàn bộ nhật ký cho người dùng đó, nhưng điều đó không hoạt động nếu nhật ký sự kiện của bạn chứa các sự kiện liên quan đến nhiều người dùng. Bạn có thể thử lưu trữ dữ liệu cá nhân bên ngoài sự kiện thực tế, hoặc mã hóa nó bằng khóa mà bạn có thể sau này chọn xóa, nhưng điều đó cũng làm cho việc tính lại trạng thái được suy dẫn khi cần trở nên khó khăn hơn.
- Việc xử lý lại các sự kiện đòi hỏi sự cẩn thận nếu có các tác dụng phụ hiển thị bên ngoài, ví dụ, bạn có thể không muốn gửi lại email xác nhận mỗi lần bạn tái tạo một materialized view.
Bạn có thể triển khai event sourcing trên bất kỳ cơ sở dữ liệu nào, nhưng cũng có một số hệ thống được thiết kế riêng để hỗ trợ mô hình này, chẳng hạn như EventStoreDB, MartenDB (dựa trên PostgreSQL), và Axon Framework. Bạn cũng có thể sử dụng message broker như Apache Kafka để lưu trữ nhật ký sự kiện, và các stream processor có thể giữ cho các materialized view luôn được cập nhật; chúng ta sẽ trở lại các chủ đề này trong “Change data capture versus event sourcing”.
Yêu cầu quan trọng duy nhất là hệ thống lưu trữ sự kiện phải đảm bảo rằng tất cả các materialized view xử lý các sự kiện theo đúng thứ tự chúng xuất hiện trong nhật ký; như chúng ta sẽ thấy trong Chương 10, điều này không phải lúc nào cũng dễ đạt được trong một hệ thống phân tán.
Dataframe, Ma Trận và Mảng
Các mô hình dữ liệu chúng ta đã thấy cho đến nay trong chương này thường được sử dụng cho cả xử lý giao dịch và mục đích phân tích (xem “Analytical versus Operational Systems”). Cũng có một số mô hình dữ liệu mà bạn có thể gặp trong bối cảnh phân tích hoặc khoa học, nhưng hiếm khi xuất hiện trong các hệ thống OLTP: dataframe và các mảng số đa chiều như ma trận.
Dataframe là một mô hình dữ liệu được hỗ trợ bởi ngôn ngữ R, thư viện Pandas cho Python, Apache Spark, ArcticDB, Dask, và các hệ thống khác. Chúng là công cụ phổ biến cho các nhà khoa học dữ liệu chuẩn bị dữ liệu để huấn luyện các mô hình machine learning, nhưng cũng được sử dụng rộng rãi cho khám phá dữ liệu, phân tích dữ liệu thống kê, trực quan hóa dữ liệu, và các mục đích tương tự.
Thoạt nhìn, một dataframe tương tự như một bảng trong cơ sở dữ liệu quan hệ hoặc một bảng tính. Nó hỗ trợ các toán tử giống quan hệ thực hiện các phép toán hàng loạt trên nội dung của dataframe: ví dụ, áp dụng một hàm cho tất cả các hàng, lọc các hàng dựa trên một điều kiện nào đó, nhóm các hàng theo một số cột và tổng hợp các cột khác, và join các hàng trong một dataframe với một dataframe khác dựa trên một khóa nào đó (điều mà cơ sở dữ liệu quan hệ gọi là join thường được gọi là merge trên dataframe).
Thay vì một truy vấn khai báo như SQL, một dataframe thường được thao tác thông qua một loạt các lệnh thay đổi cấu trúc và nội dung của nó. Điều này phù hợp với quy trình làm việc điển hình của các nhà khoa học dữ liệu, những người dần dần “wrangling” (xử lý thô) dữ liệu thành dạng cho phép họ tìm câu trả lời cho các câu hỏi đang đặt ra. Những thao tác này thường diễn ra trên bản sao dữ liệu riêng của nhà khoa học dữ liệu, thường trên máy tính cá nhân của họ, mặc dù kết quả cuối cùng có thể được chia sẻ với những người dùng khác.
Các API dataframe cũng cung cấp nhiều phép toán vượt xa những gì cơ sở dữ liệu quan hệ cung cấp, và mô hình dữ liệu thường được sử dụng theo những cách rất khác so với mô hình hóa dữ liệu quan hệ điển hình 65. Ví dụ, một cách sử dụng phổ biến của dataframe là chuyển đổi dữ liệu từ biểu diễn giống quan hệ thành biểu diễn ma trận hoặc mảng đa chiều, đây là dạng mà nhiều thuật toán machine learning mong đợi từ dữ liệu đầu vào.
Một ví dụ đơn giản về sự chuyển đổi như vậy được hiển thị trong Hình 3-9. Bên trái chúng ta có một bảng quan hệ về cách các người dùng khác nhau đánh giá các bộ phim khác nhau (theo thang điểm từ 1 đến 5), và bên phải dữ liệu đã được chuyển đổi thành một ma trận trong đó mỗi cột là một bộ phim và mỗi hàng là một người dùng (tương tự như pivot table trong bảng tính). Ma trận là sparse (thưa), có nghĩa là không có dữ liệu cho nhiều tổ hợp người dùng-bộ phim, nhưng điều này không sao cả. Ma trận này có thể có hàng nghìn cột và do đó sẽ không phù hợp lắm trong cơ sở dữ liệu quan hệ, nhưng dataframe và các thư viện cung cấp mảng thưa (chẳng hạn như NumPy cho Python) có thể xử lý dữ liệu như vậy một cách dễ dàng.
Hình 3-9. Chuyển đổi cơ sở dữ liệu quan hệ về đánh giá phim thành biểu diễn ma trận.
Một ma trận chỉ có thể chứa các số, và nhiều kỹ thuật được sử dụng để chuyển đổi dữ liệu không phải số thành các số trong ma trận. Ví dụ:
- Các ngày (bị bỏ qua trong ma trận ví dụ trong Hình 3-9) có thể được thu phóng thành các số dấu phẩy động trong một khoảng phù hợp.
- Đối với các cột chỉ có thể nhận một trong một tập hợp giá trị nhỏ, cố định (ví dụ, thể loại của một bộ phim trong cơ sở dữ liệu phim), one-hot encoding thường được sử dụng: chúng ta tạo một cột cho mỗi giá trị có thể (một cho “comedy”, một cho “drama”, một cho “horror”, v.v.), và cho mỗi hàng đại diện cho một bộ phim, chúng ta đặt 1 vào cột tương ứng với thể loại của bộ phim đó, và 0 vào tất cả các cột khác. Biểu diễn này cũng dễ dàng tổng quát hóa cho các bộ phim thuộc nhiều thể loại.
Khi dữ liệu ở dạng ma trận số, nó phù hợp cho các phép toán đại số tuyến tính, tạo thành cơ sở của nhiều thuật toán machine learning. Ví dụ, dữ liệu trong Hình 3-9 có thể là một phần của hệ thống đề xuất phim mà người dùng có thể thích. Dataframe đủ linh hoạt để cho phép dữ liệu dần dần phát triển từ dạng quan hệ thành biểu diễn ma trận, đồng thời cho nhà khoa học dữ liệu kiểm soát biểu diễn phù hợp nhất để đạt được các mục tiêu của quá trình phân tích dữ liệu hoặc huấn luyện mô hình.
Cũng có các cơ sở dữ liệu như TileDB 66 chuyên lưu trữ các mảng số đa chiều lớn; chúng được gọi là array database (cơ sở dữ liệu mảng) và thường được sử dụng nhất cho các tập dữ liệu khoa học như các phép đo địa không gian (dữ liệu raster trên lưới cách đều), hình ảnh y tế, hoặc các quan sát từ kính thiên văn thiên văn học 67. Dataframe cũng được sử dụng trong ngành tài chính để biểu diễn time series data (dữ liệu chuỗi thời gian), chẳng hạn như giá của các tài sản và giao dịch theo thời gian 68.
Tóm Tắt
Mô hình dữ liệu là một chủ đề rộng lớn, và trong chương này chúng ta đã xem qua nhanh một loạt các mô hình khác nhau. Chúng ta không có chỗ để đi vào tất cả các chi tiết của mỗi mô hình, nhưng hy vọng tổng quan đã đủ để kích thích bạn tìm hiểu thêm về mô hình phù hợp nhất với yêu cầu của ứng dụng.
Mô hình quan hệ (relational model), dù đã hơn nửa thế kỷ tuổi, vẫn là một mô hình dữ liệu quan trọng cho nhiều ứng dụng, đặc biệt trong kho dữ liệu và phân tích kinh doanh, nơi star schema hay snowflake schema quan hệ và các truy vấn SQL rất phổ biến. Tuy nhiên, một số phương án thay thế cho dữ liệu quan hệ cũng đã trở nên phổ biến trong các lĩnh vực khác:
- Mô hình tài liệu (document model) nhắm vào các trường hợp sử dụng nơi dữ liệu đến dưới dạng các tài liệu JSON tự chứa, và nơi các mối quan hệ giữa một tài liệu và tài liệu khác là hiếm.
- Mô hình dữ liệu đồ thị (graph data models) đi theo hướng ngược lại, nhắm vào các trường hợp sử dụng nơi bất cứ thứ gì cũng có thể liên quan đến mọi thứ, và nơi các truy vấn có thể cần duyệt qua nhiều bước nhảy để tìm dữ liệu quan tâm (có thể biểu diễn bằng các truy vấn đệ quy trong Cypher, SPARQL, hoặc Datalog).
- Dataframe tổng quát hóa dữ liệu quan hệ cho số lượng cột lớn, và do đó cung cấp cầu nối giữa cơ sở dữ liệu và các mảng đa chiều là cơ sở của nhiều machine learning, phân tích dữ liệu thống kê, và tính toán khoa học.
Ở một mức độ nào đó, một mô hình có thể được mô phỏng bằng mô hình khác, ví dụ, dữ liệu đồ thị có thể được biểu diễn trong cơ sở dữ liệu quan hệ, nhưng kết quả có thể lủng củng, như chúng ta đã thấy với sự hỗ trợ cho các truy vấn đệ quy trong SQL.
Do đó, nhiều cơ sở dữ liệu chuyên biệt đã được phát triển cho mỗi mô hình dữ liệu, cung cấp các ngôn ngữ truy vấn và engine lưu trữ được tối ưu hóa cho một mô hình cụ thể. Tuy nhiên, cũng có xu hướng các cơ sở dữ liệu mở rộng sang các lĩnh vực lân cận bằng cách thêm hỗ trợ cho các mô hình dữ liệu khác: ví dụ, cơ sở dữ liệu quan hệ đã thêm hỗ trợ cho dữ liệu tài liệu dưới dạng cột JSON, cơ sở dữ liệu tài liệu đã thêm các join giống quan hệ, và hỗ trợ cho dữ liệu đồ thị trong SQL đang dần được cải thiện.
Một mô hình khác chúng ta đã thảo luận là event sourcing, biểu diễn dữ liệu dưới dạng nhật ký chỉ thêm của các sự kiện bất biến, và có thể có lợi cho việc mô hình hóa các hoạt động trong các lĩnh vực kinh doanh phức tạp. Nhật ký chỉ thêm tốt cho việc ghi dữ liệu (như chúng ta sẽ thấy trong Chương 4); để hỗ trợ các truy vấn hiệu quả, nhật ký sự kiện được dịch thành các materialized view được tối ưu hóa cho đọc thông qua CQRS.
Một điều mà các mô hình dữ liệu phi quan hệ có chung là chúng thường không áp đặt một schema cho dữ liệu mà chúng lưu trữ, điều này có thể giúp dễ dàng thích ứng ứng dụng với các yêu cầu thay đổi. Tuy nhiên, ứng dụng của bạn rất có thể vẫn giả định rằng dữ liệu có một cấu trúc nhất định; chỉ là vấn đề liệu schema là tường minh (bắt buộc khi ghi) hay ngầm định (giả định khi đọc).
Mặc dù chúng ta đã đề cập đến nhiều nội dung, vẫn còn các mô hình dữ liệu chưa được nhắc đến. Để đưa ra một vài ví dụ ngắn:
- Các nhà nghiên cứu làm việc với dữ liệu genome thường cần thực hiện sequence-similarity search (tìm kiếm tương đồng trình tự), có nghĩa là lấy một chuỗi rất dài (đại diện cho phân tử DNA) và so khớp nó với một cơ sở dữ liệu lớn các chuỗi tương tự, nhưng không giống hệt. Không có cơ sở dữ liệu nào được mô tả ở đây có thể xử lý loại sử dụng này, đó là lý do tại sao các nhà nghiên cứu đã viết phần mềm cơ sở dữ liệu genome chuyên biệt như GenBank [^69].
- Nhiều hệ thống tài chính sử dụng sổ cái (ledger) với kế toán kép làm mô hình dữ liệu. Loại dữ liệu này có thể được biểu diễn trong cơ sở dữ liệu quan hệ, nhưng cũng có các cơ sở dữ liệu như TigerBeetle chuyên về mô hình dữ liệu này. Các tiền điện tử và blockchain thường dựa trên sổ cái phân tán, cũng có chức năng chuyển giá trị được tích hợp trong mô hình dữ liệu của chúng.
- Full-text search (tìm kiếm toàn văn) có thể được coi là một loại mô hình dữ liệu thường được sử dụng cùng với cơ sở dữ liệu. Truy xuất thông tin là một chủ đề chuyên biệt rộng lớn mà chúng ta sẽ không đề cập chi tiết trong cuốn sách này, nhưng chúng ta sẽ đề cập đến các search index và vector search trong “Full-Text Search”.
Chúng ta phải dừng ở đây. Trong chương tiếp theo, chúng ta sẽ thảo luận về một số sự đánh đổi được đặt ra khi triển khai các mô hình dữ liệu được mô tả trong chương này.
Tham Khảo
Jamie Brandon. Unexplanations: query optimization works because sql is declarative. scattered-thoughts.net, February 2024. Archived at perma.cc/P6W2-WMFZ ↩︎
Joseph M. Hellerstein. The Declarative Imperative: Experiences and Conjectures in Distributed Logic. Tech report UCB/EECS-2010-90, Electrical Engineering and Computer Sciences, University of California at Berkeley, June 2010. Archived at perma.cc/K56R-VVQM ↩︎
Edgar F. Codd. A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, volume 13, issue 6, pages 377–387, June 1970. doi:10.1145/362384.362685 ↩︎ ↩︎
Michael Stonebraker and Joseph M. Hellerstein. What Goes Around Comes Around. In Readings in Database Systems, 4th edition, MIT Press, pages 2–41, 2005. ISBN: 9780262693141 ↩︎
Markus Winand. Modern SQL: Beyond Relational. modern-sql.com, 2015. Archived at perma.cc/D63V-WAPN ↩︎
Martin Fowler. OrmHate. martinfowler.com, May 2012. Archived at perma.cc/VCM8-PKNG ↩︎
Vlad Mihalcea. N+1 query problem with JPA and Hibernate. vladmihalcea.com, January 2023. Archived at perma.cc/79EV-TZKB ↩︎
Jens Schauder. This is the Beginning of the End of the N+1 Problem: Introducing Single Query Loading. spring.io, August 2023. Archived at perma.cc/6V96-R333 ↩︎
William Zola. 6 Rules of Thumb for MongoDB Schema Design. mongodb.com, June 2014. Archived at perma.cc/T2BZ-PPJB ↩︎ ↩︎
Sidney Andrews and Christopher McClister. Data modeling in Azure Cosmos DB. learn.microsoft.com, February 2023. Archived at archive.org ↩︎
Raffi Krikorian. Timelines at Scale. At QCon San Francisco, November 2012. Archived at perma.cc/V9G5-KLYK ↩︎ ↩︎
Ralph Kimball and Margy Ross. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling, 3rd edition. John Wiley & Sons, July 2013. ISBN: 9781118530801 ↩︎ ↩︎
Michael Kaminsky. Data warehouse modeling: Star schema vs. OBT. fivetran.com, August 2022. Archived at perma.cc/2PZK-BFFP ↩︎
Joe Nelson. User-defined Order in SQL. begriffs.com, March 2018. Archived at perma.cc/GS3W-F7AD ↩︎
Evan Wallace. Realtime Editing of Ordered Sequences. figma.com, March 2017. Archived at perma.cc/K6ER-CQZW ↩︎
David Greenspan. Implementing Fractional Indexing. observablehq.com, October 2020. Archived at perma.cc/5N4R-MREN ↩︎
Martin Fowler. Schemaless Data Structures. martinfowler.com, January 2013. ↩︎
Amr Awadallah. Schema-on-Read vs. Schema-on-Write. At Berkeley EECS RAD Lab Retreat, Santa Cruz, CA, May 2009. Archived at perma.cc/DTB2-JCFR ↩︎
Martin Odersky. The Trouble with Types. At Strange Loop, September 2013. Archived at perma.cc/85QE-PVEP ↩︎
Conrad Irwin. MongoDB—Confessions of a PostgreSQL Lover. At HTML5DevConf, October 2013. Archived at perma.cc/C2J6-3AL5 ↩︎
Percona Toolkit Documentation: pt-online-schema-change. docs.percona.com, 2023. Archived at perma.cc/9K8R-E5UH ↩︎
Shlomi Noach. gh-ost: GitHub’s Online Schema Migration Tool for MySQL. github.blog, August 2016. Archived at perma.cc/7XAG-XB72 ↩︎
Shayon Mukherjee. pg-osc: Zero downtime schema changes in PostgreSQL. shayon.dev, February 2022. Archived at perma.cc/35WN-7WMY ↩︎
Carlos Pérez-Aradros Herce. Introducing pgroll: zero-downtime, reversible, schema migrations for Postgres. xata.io, October 2023. Archived at archive.org ↩︎
James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Dale Woodford, Yasushi Saito, Christopher Taylor, Michal Szymaniak, and Ruth Wang. Spanner: Google’s Globally-Distributed Database. At 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012. ↩︎
Donald K. Burleson. Reduce I/O with Oracle Cluster Tables. dba-oracle.com. Archived at perma.cc/7LBJ-9X2C ↩︎
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber. Bigtable: A Distributed Storage System for Structured Data. At 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006. ↩︎
Priscilla Walmsley. XQuery, 2nd Edition. O’Reilly Media, December 2015. ISBN: 9781491915080 ↩︎
Paul C. Bryan, Kris Zyp, and Mark Nottingham. JavaScript Object Notation (JSON) Pointer. RFC 6901, IETF, April 2013. ↩︎
Stefan Gössner, Glyn Normington, and Carsten Bormann. JSONPath: Query Expressions for JSON. RFC 9535, IETF, February 2024. ↩︎
Michael Stonebraker and Andrew Pavlo. What Goes Around Comes Around… And Around…. ACM SIGMOD Record, volume 53, issue 2, pages 21–37. doi:10.1145/3685980.3685984 ↩︎
Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The PageRank Citation Ranking: Bringing Order to the Web. Technical Report 1999-66, Stanford University InfoLab, November 1999. Archived at perma.cc/UML9-UZHW ↩︎
Nathan Bronson, Zach Amsden, George Cabrera, Prasad Chakka, Peter Dimov, Hui Ding, Jack Ferris, Anthony Giardullo, Sachin Kulkarni, Harry Li, Mark Marchukov, Dmitri Petrov, Lovro Puzar, Yee Jiun Song, and Venkat Venkataramani. TAO: Facebook’s Distributed Data Store for the Social Graph. At USENIX Annual Technical Conference (ATC), June 2013. ↩︎
Natasha Noy, Yuqing Gao, Anshu Jain, Anant Narayanan, Alan Patterson, and Jamie Taylor. Industry-Scale Knowledge Graphs: Lessons and Challenges. Communications of the ACM, volume 62, issue 8, pages 36–43, August 2019. doi:10.1145/3331166 ↩︎
Xiyang Feng, Guodong Jin, Ziyi Chen, Chang Liu, and Semih Salihoğlu. KÙZU Graph Database Management System. At 3th Annual Conference on Innovative Data Systems Research (CIDR 2023), January 2023. ↩︎ ↩︎
Maciej Besta, Emanuel Peter, Robert Gerstenberger, Marc Fischer, Michał Podstawski, Claude Barthels, Gustavo Alonso, Torsten Hoefler. Demystifying Graph Databases: Analysis and Taxonomy of Data Organization, System Designs, and Graph Queries. arxiv.org, October 2019. ↩︎ ↩︎
Apache TinkerPop 3.6.3 Documentation. tinkerpop.apache.org, May 2023. Archived at perma.cc/KM7W-7PAT ↩︎
Nadime Francis, Alastair Green, Paolo Guagliardo, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Stefan Plantikow, Mats Rydberg, Petra Selmer, and Andrés Taylor. Cypher: An Evolving Query Language for Property Graphs. At International Conference on Management of Data (SIGMOD), pages 1433–1445, May 2018. doi:10.1145/3183713.3190657 ↩︎
Emil Eifrem. Twitter correspondence, January 2014. Archived at perma.cc/WM4S-BW64 ↩︎
Francesco Tisiot. Explore the new SEARCH and CYCLE features in PostgreSQL® 14. aiven.io, December 2021. Archived at perma.cc/J6BT-83UZ ↩︎
Gaurav Goel. Understanding Hierarchies in Oracle. towardsdatascience.com, May 2020. Archived at perma.cc/5ZLR-Q7EW ↩︎
Alin Deutsch, Nadime Francis, Alastair Green, Keith Hare, Bei Li, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Wim Martens, Jan Michels, Filip Murlak, Stefan Plantikow, Petra Selmer, Oskar van Rest, Hannes Voigt, Domagoj Vrgoč, Mingxi Wu, and Fred Zemke. Graph Pattern Matching in GQL and SQL/PGQ. At International Conference on Management of Data (SIGMOD), pages 2246–2258, June 2022. doi:10.1145/3514221.3526057 ↩︎
Alastair Green. SQL… and now GQL. opencypher.org, September 2019. Archived at perma.cc/AFB2-3SY7 ↩︎
Alin Deutsch, Yu Xu, and Mingxi Wu. Seamless Syntactic and Semantic Integration of Query Primitives over Relational and Graph Data in GSQL. tigergraph.com, November 2018. Archived at perma.cc/JG7J-Y35X ↩︎
Oskar van Rest, Sungpack Hong, Jinha Kim, Xuming Meng, and Hassan Chafi. PGQL: a property graph query language. At 4th International Workshop on Graph Data Management Experiences and Systems (GRADES), June 2016. doi:10.1145/2960414.2960421 ↩︎
Amazon Web Services. Neptune Graph Data Model. Amazon Neptune User Guide, docs.aws.amazon.com. Archived at perma.cc/CX3T-EZU9 ↩︎ ↩︎
Cognitect. Datomic Data Model. Datomic Cloud Documentation, docs.datomic.com. Archived at perma.cc/LGM9-LEUT ↩︎
David Beckett and Tim Berners-Lee. Turtle – Terse RDF Triple Language. W3C Team Submission, March 2011. ↩︎
Sinclair Target. Whatever Happened to the Semantic Web? twobithistory.org, May 2018. Archived at perma.cc/M8GL-9KHS ↩︎
Gavin Mendel-Gleason. The Semantic Web is Dead – Long Live the Semantic Web! terminusdb.com, August 2022. Archived at perma.cc/G2MZ-DSS3 ↩︎
Manu Sporny. JSON-LD and Why I Hate the Semantic Web. manu.sporny.org, January 2014. Archived at perma.cc/7PT4-PJKF ↩︎
University of Michigan Library. Biomedical Ontologies and Controlled Vocabularies, guides.lib.umich.edu/ontology. Archived at perma.cc/Q5GA-F2N8 ↩︎
Facebook. The Open Graph protocol, ogp.me. Archived at perma.cc/C49A-GUSY ↩︎
Matt Haughey. Everything you ever wanted to know about unfurling but were afraid to ask /or/ How to make your site previews look amazing in Slack. medium.com, November 2015. Archived at perma.cc/C7S8-4PZN ↩︎
W3C RDF Working Group. Resource Description Framework (RDF). w3.org, February 2004. ↩︎
Steve Harris, Andy Seaborne, and Eric Prud’hommeaux. SPARQL 1.1 Query Language. W3C Recommendation, March 2013. ↩︎
Todd J. Green, Shan Shan Huang, Boon Thau Loo, and Wenchao Zhou. Datalog and Recursive Query Processing. Foundations and Trends in Databases, volume 5, issue 2, pages 105–195, November 2013. doi:10.1561/1900000017 ↩︎
Stefano Ceri, Georg Gottlob, and Letizia Tanca. What You Always Wanted to Know About Datalog (And Never Dared to Ask). IEEE Transactions on Knowledge and Data Engineering, volume 1, issue 1, pages 146–166, March 1989. doi:10.1109/69.43410 ↩︎
Serge Abiteboul, Richard Hull, and Victor Vianu. Foundations of Databases. Addison-Wesley, 1995. ISBN: 9780201537710, available online at webdam.inria.fr/Alice ↩︎
Scott Meyer, Andrew Carter, and Andrew Rodriguez. LIquid: The soul of a new graph database, Part 2. engineering.linkedin.com, September 2020. Archived at perma.cc/K9M4-PD6Q ↩︎
Matt Bessey. Why, after 6 years, I’m over GraphQL. bessey.dev, May 2024. Archived at perma.cc/2PAU-JYRA ↩︎
Dominic Betts, Julián Domínguez, Grigori Melnik, Fernando Simonazzi, and Mani Subramanian. Exploring CQRS and Event Sourcing. Microsoft Patterns & Practices, July 2012. ISBN: 1621140164, archived at perma.cc/7A39-3NM8 ↩︎
Greg Young. CQRS and Event Sourcing. At Code on the Beach, August 2014. ↩︎
Greg Young. CQRS Documents. cqrs.wordpress.com, November 2010. Archived at perma.cc/X5R6-R47F ↩︎
Devin Petersohn, Stephen Macke, Doris Xin, William Ma, Doris Lee, Xiangxi Mo, Joseph E. Gonzalez, Joseph M. Hellerstein, Anthony D. Joseph, and Aditya Parameswaran. Towards Scalable Dataframe Systems. Proceedings of the VLDB Endowment, volume 13, issue 11, pages 2033–2046. doi:10.14778/3407790.3407807 ↩︎
Stavros Papadopoulos, Kushal Datta, Samuel Madden, and Timothy Mattson. The TileDB Array Data Storage Manager. Proceedings of the VLDB Endowment, volume 10, issue 4, pages 349–360, November 2016. doi:10.14778/3025111.3025117 ↩︎
Florin Rusu. Multidimensional Array Data Management. Foundations and Trends in Databases, volume 12, numbers 2–3, pages 69–220, February 2023. doi:10.1561/1900000069 ↩︎
Ed Targett. Bloomberg, Man Group team up to develop open source “ArcticDB” database. thestack.technology, March 2023. Archived at perma.cc/M5YD-QQYV ↩︎