2. Xác Định Các Yêu Cầu Phi Chức Năng

Internet được xây dựng tốt đến mức hầu hết mọi người coi nó như một tài nguyên thiên nhiên giống Thái Bình Dương, chứ không phải thứ do con người tạo ra. Lần cuối cùng một công nghệ với quy mô như vậy không có lỗi là khi nào?
Alan Kay, trong cuộc phỏng vấn với Dr Dobb’s Journal (2012)
Khi xây dựng một ứng dụng, bạn sẽ được dẫn dắt bởi một danh sách các yêu cầu. Đứng đầu danh sách đó thường là các chức năng mà ứng dụng phải cung cấp: những màn hình và nút bấm nào cần có, và mỗi thao tác phải làm gì để đáp ứng mục tiêu của phần mềm. Đây là các yêu cầu chức năng (functional requirements) của bạn.
Ngoài ra, bạn có thể cũng có một số yêu cầu phi chức năng (nonfunctional requirements): ví dụ, ứng dụng phải nhanh, đáng tin cậy, an toàn, tuân thủ pháp lý và dễ bảo trì. Những yêu cầu này đôi khi không được ghi rõ ràng vì chúng có vẻ hiển nhiên, nhưng chúng quan trọng không kém chức năng của ứng dụng: một ứng dụng chậm đến mức không chịu nổi hoặc liên tục gặp sự cố thì cũng như không tồn tại.
Nhiều yêu cầu phi chức năng, chẳng hạn như bảo mật, nằm ngoài phạm vi của cuốn sách này. Nhưng có một số yêu cầu phi chức năng mà chúng ta sẽ xem xét, và chương này sẽ giúp bạn diễn đạt chúng cho hệ thống của mình:
- Cách xác định và đo lường hiệu năng (performance) của một hệ thống (xem “Mô Tả Hiệu Năng”);
- Điều gì khiến một dịch vụ được gọi là đáng tin cậy (reliable), cụ thể là tiếp tục hoạt động đúng đắn ngay cả khi có sự cố (xem “Độ Tin Cậy và Khả Năng Chịu Lỗi”);
- Cho phép một hệ thống có khả năng mở rộng (scalable) bằng cách bổ sung tài nguyên tính toán một cách hiệu quả khi tải hệ thống tăng lên (xem “Khả Năng Mở Rộng”); và
- Giúp việc bảo trì hệ thống về lâu dài trở nên dễ dàng hơn (xem “Khả Năng Bảo Trì”).
Thuật ngữ được giới thiệu trong chương này cũng sẽ hữu ích trong các chương tiếp theo, khi chúng ta đi sâu vào chi tiết cách các hệ thống xử lý dữ liệu chuyên sâu được xây dựng. Tuy nhiên, các định nghĩa trừu tượng có thể khá khô khan; để làm cho các ý tưởng trở nên cụ thể hơn, chúng ta sẽ bắt đầu chương này bằng một nghiên cứu tình huống về cách một dịch vụ mạng xã hội có thể hoạt động, từ đó cung cấp các ví dụ thực tế về hiệu năng và khả năng mở rộng.
Nghiên Cứu Tình Huống: Dòng Thời Gian Trang Chủ Mạng Xã Hội
Hãy tưởng tượng bạn được giao nhiệm vụ xây dựng một mạng xã hội theo phong cách X (trước đây là Twitter), trong đó người dùng có thể đăng bài và theo dõi người dùng khác. Đây sẽ là một phiên bản đơn giản hóa rất nhiều so với cách một dịch vụ như vậy thực sự hoạt động 1 2 3, nhưng nó sẽ giúp minh họa một số vấn đề phát sinh trong các hệ thống quy mô lớn.
Giả sử người dùng đăng 500 triệu bài mỗi ngày, tức trung bình 5.700 bài mỗi giây. Đôi khi, tốc độ có thể tăng vọt lên đến 150.000 bài/giây 4. Cũng giả sử rằng người dùng trung bình theo dõi 200 người và có 200 người theo dõi (mặc dù có sự biến thiên rất lớn: hầu hết mọi người chỉ có vài người theo dõi, trong khi một số người nổi tiếng như Barack Obama có hơn 100 triệu người theo dõi).
Biểu Diễn Người Dùng, Bài Đăng và Quan Hệ Theo Dõi
Hãy tưởng tượng chúng ta lưu tất cả dữ liệu trong một cơ sở dữ liệu quan hệ như trong Hình 2-1. Chúng ta có một bảng cho người dùng, một bảng cho bài đăng và một bảng cho các quan hệ theo dõi.
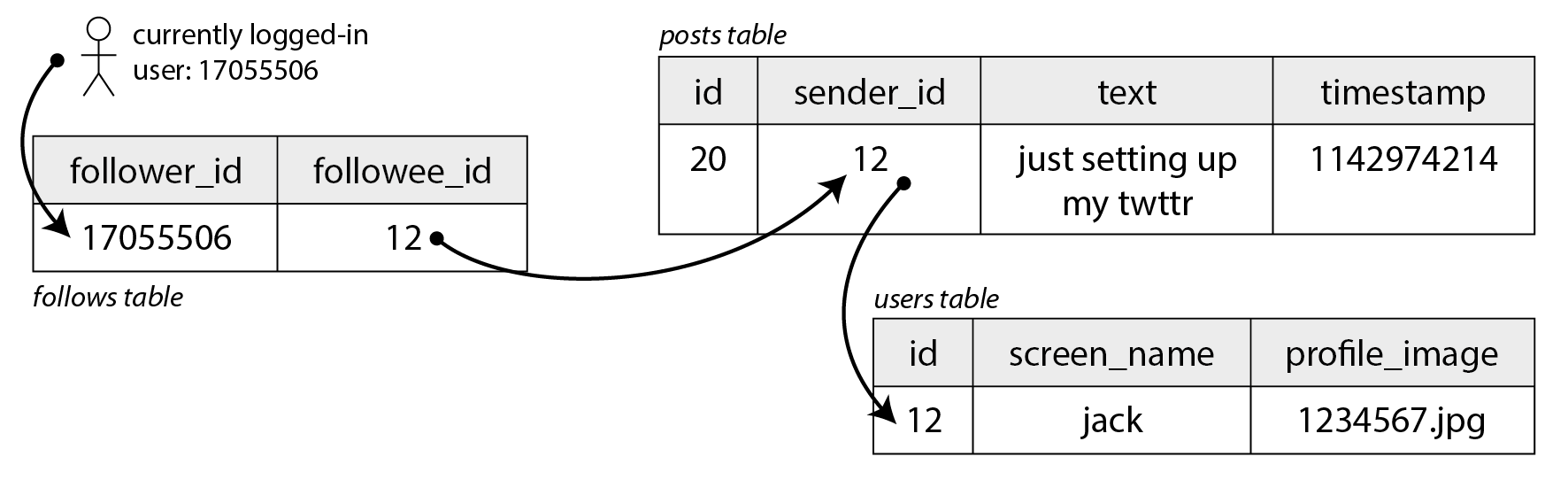
Giả sử thao tác đọc chính mà mạng xã hội của chúng ta phải hỗ trợ là dòng thời gian trang chủ (home timeline), hiển thị các bài đăng gần đây từ những người bạn đang theo dõi (để đơn giản, chúng ta sẽ bỏ qua quảng cáo, bài đề xuất từ người bạn chưa theo dõi và các phần mở rộng khác). Chúng ta có thể viết truy vấn SQL sau để lấy dòng thời gian trang chủ của một người dùng cụ thể:
SELECT posts.*, users.* FROM posts
JOIN follows ON posts.sender_id = follows.followee_id
JOIN users ON posts.sender_id = users.id
WHERE follows.follower_id = current_user
ORDER BY posts.timestamp DESC
LIMIT 1000Để thực thi truy vấn này, cơ sở dữ liệu sẽ dùng bảng follows để tìm tất cả những người mà
current_user đang theo dõi, tra cứu các bài đăng gần đây của những người đó và sắp xếp theo
timestamp để lấy 1.000 bài mới nhất từ những người được theo dõi.
Bài đăng cần được hiển thị kịp thời, vì vậy giả sử rằng sau khi ai đó đăng một bài, chúng ta muốn những người theo dõi có thể thấy bài đó trong vòng 5 giây. Một cách để làm điều đó là để client của người dùng lặp lại truy vấn trên mỗi 5 giây trong khi người dùng đang trực tuyến (cách này được gọi là polling). Nếu giả sử 10 triệu người dùng đang trực tuyến và đăng nhập cùng một lúc, điều đó có nghĩa là chạy truy vấn 2 triệu lần mỗi giây. Ngay cả khi tăng khoảng thời gian polling, con số này vẫn rất lớn.
Hơn nữa, truy vấn trên khá tốn kém: nếu bạn đang theo dõi 200 người, nó cần lấy danh sách các bài đăng gần đây của mỗi trong 200 người đó và gộp những danh sách đó lại. 2 triệu truy vấn dòng thời gian mỗi giây đồng nghĩa với việc cơ sở dữ liệu cần tra cứu các bài đăng gần đây từ một người gửi 400 triệu lần mỗi giây, một con số khổng lồ. Và đó là trường hợp trung bình. Một số người dùng theo dõi hàng chục nghìn tài khoản; với họ, truy vấn này rất tốn kém và khó tối ưu.
Vật Chất Hóa và Cập Nhật Dòng Thời Gian
Làm thế nào chúng ta có thể cải thiện? Thứ nhất, thay vì polling, sẽ tốt hơn nếu máy chủ chủ động đẩy các bài đăng mới đến những người theo dõi đang trực tuyến. Thứ hai, chúng ta nên tính trước kết quả của truy vấn trên để yêu cầu dòng thời gian trang chủ của người dùng có thể được phục vụ từ cache.
Hãy tưởng tượng rằng với mỗi người dùng, chúng ta lưu một cấu trúc dữ liệu chứa dòng thời gian trang chủ của họ, tức các bài đăng gần đây từ những người họ đang theo dõi. Mỗi khi một người dùng đăng bài, chúng ta tra cứu tất cả những người theo dõi họ và chèn bài đó vào dòng thời gian trang chủ của mỗi người theo dõi, giống như giao thư đến hộp thư. Khi người dùng đăng nhập, chúng ta chỉ cần đưa cho họ dòng thời gian trang chủ đã được tính trước. Hơn nữa, để nhận thông báo về bất kỳ bài đăng mới nào trên dòng thời gian của họ, client của người dùng chỉ cần đăng ký vào luồng bài đăng đang được thêm vào dòng thời gian trang chủ của họ.
Nhược điểm của cách tiếp cận này là chúng ta cần làm nhiều việc hơn mỗi khi người dùng đăng bài, vì các dòng thời gian trang chủ là dữ liệu dẫn xuất cần được cập nhật. Quá trình này được minh họa trong Hình 2-2. Khi một yêu cầu ban đầu dẫn đến nhiều yêu cầu tiếp theo được thực hiện, chúng ta dùng thuật ngữ fan-out để mô tả hệ số mà số lượng yêu cầu tăng lên.
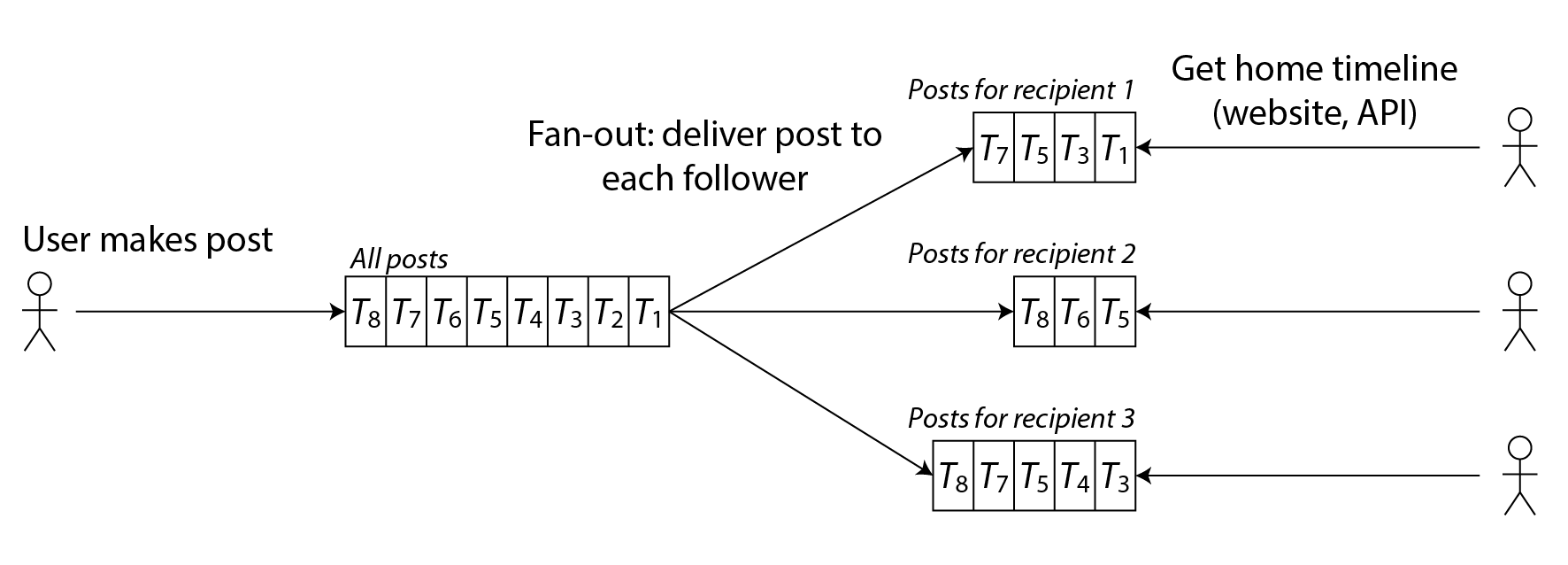
Với tốc độ 5.700 bài đăng mỗi giây, nếu một bài đăng trung bình đến 200 người theo dõi (tức hệ số fan-out là 200), chúng ta cần thực hiện hơn 1 triệu lần ghi vào dòng thời gian trang chủ mỗi giây. Con số này lớn, nhưng vẫn tiết kiệm đáng kể so với 400 triệu lần tra cứu bài đăng theo người gửi mỗi giây mà chúng ta sẽ phải thực hiện theo cách khác.
Nếu tốc độ bài đăng tăng đột biến do một sự kiện đặc biệt nào đó, chúng ta không cần phải thực hiện việc giao bài đến dòng thời gian ngay lập tức, mà có thể đưa vào hàng đợi và chấp nhận rằng sẽ mất thêm một chút thời gian để bài đăng xuất hiện trong dòng thời gian của những người theo dõi. Ngay cả trong những lúc tải tăng đột biến, dòng thời gian vẫn tải nhanh vì chúng ta chỉ đơn giản phục vụ từ cache.
Quá trình tính trước và cập nhật kết quả của một truy vấn được gọi là vật chất hóa (materialization), và cache dòng thời gian là một ví dụ về khung nhìn vật chất hóa (materialized view, một khái niệm chúng ta sẽ thảo luận thêm trong “Duy trì các khung nhìn vật chất hóa”). Khung nhìn vật chất hóa tăng tốc độ đọc, nhưng đổi lại chúng ta phải làm nhiều việc hơn khi ghi. Chi phí ghi đối với hầu hết người dùng là khiêm tốn, nhưng một mạng xã hội cũng phải xem xét một số trường hợp cực đoan:
- Nếu một người dùng đang theo dõi rất nhiều tài khoản và những tài khoản đó đăng nhiều bài, người dùng đó sẽ có tốc độ ghi cao vào dòng thời gian vật chất hóa của họ. Tuy nhiên, trong trường hợp này, khó có khả năng người dùng thực sự đọc tất cả các bài trong dòng thời gian của họ, và do đó có thể đơn giản bỏ qua một số lần ghi vào dòng thời gian và chỉ hiển thị cho người dùng một mẫu các bài từ những tài khoản họ theo dõi 5.
- Khi một tài khoản người nổi tiếng với rất nhiều người theo dõi đăng bài, chúng ta phải thực hiện một lượng công việc lớn để chèn bài đó vào dòng thời gian trang chủ của hàng triệu người theo dõi. Trong trường hợp này, không thể bỏ qua một số lần ghi đó. Một cách giải quyết vấn đề này là xử lý bài đăng của người nổi tiếng riêng biệt so với bài của mọi người khác: chúng ta có thể tiết kiệm công sức không thêm chúng vào hàng triệu dòng thời gian bằng cách lưu riêng các bài của người nổi tiếng và gộp chúng vào dòng thời gian vật chất hóa khi đọc. Dù có những tối ưu như vậy, việc xử lý người nổi tiếng trên một mạng xã hội vẫn có thể đòi hỏi rất nhiều cơ sở hạ tầng 6.
Mô Tả Hiệu Năng
Hầu hết các cuộc thảo luận về hiệu năng phần mềm xem xét hai loại chỉ số chính:
- Thời gian phản hồi (Response time)
- Thời gian trôi qua từ lúc người dùng gửi một yêu cầu cho đến khi họ nhận được câu trả lời. Đơn vị đo là giây (hoặc mili giây, hoặc micro giây).
- Thông lượng (Throughput)
- Số lượng yêu cầu mỗi giây, hoặc lượng dữ liệu mỗi giây mà hệ thống đang xử lý. Với một lượng tài nguyên phần cứng nhất định, có một thông lượng tối đa có thể xử lý. Đơn vị đo là “X cái gì đó mỗi giây”.
Trong nghiên cứu tình huống mạng xã hội, “bài đăng mỗi giây” và “lần ghi vào dòng thời gian mỗi giây” là các chỉ số thông lượng, trong khi “thời gian tải dòng thời gian trang chủ” hay “thời gian để bài đăng được giao đến người theo dõi” là các chỉ số thời gian phản hồi.
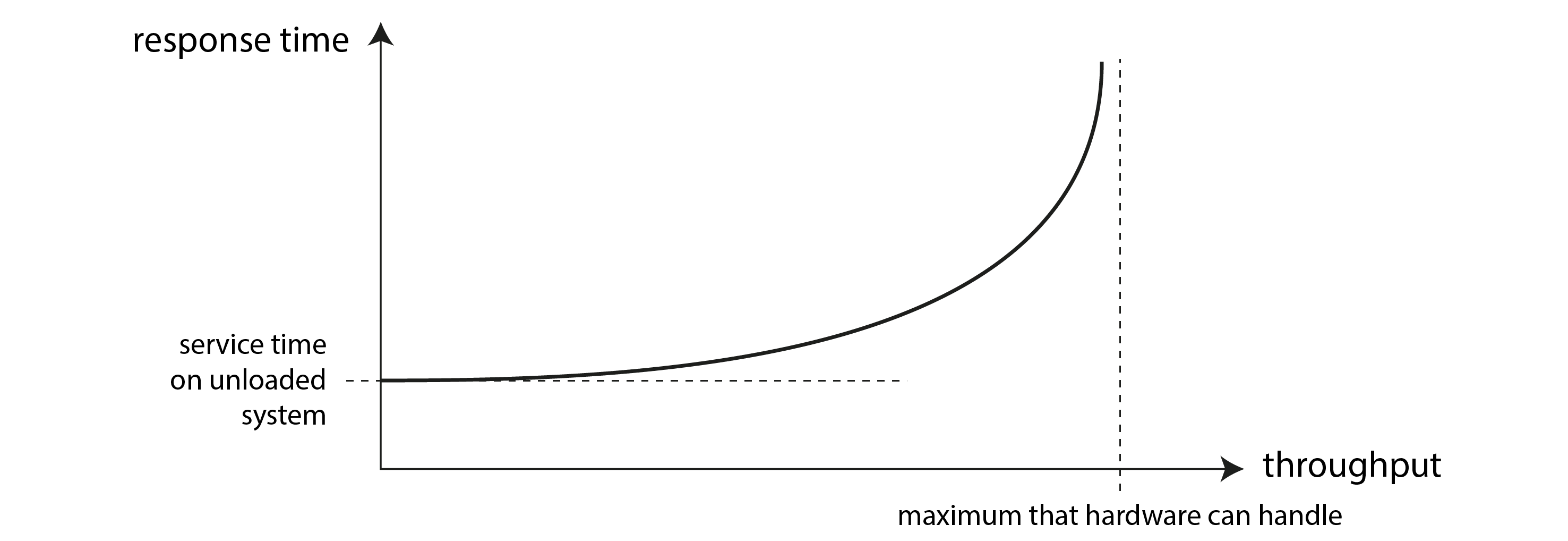
Thường có mối liên hệ giữa thông lượng và thời gian phản hồi; một ví dụ về mối quan hệ đó đối với một dịch vụ trực tuyến được phác thảo trong Hình 2-3. Dịch vụ có thời gian phản hồi thấp khi thông lượng yêu cầu thấp, nhưng thời gian phản hồi tăng khi tải tăng. Nguyên nhân là do xếp hàng (queueing): khi một yêu cầu đến một hệ thống đang chịu tải cao, CPU có thể đang xử lý một yêu cầu trước đó, và do đó yêu cầu đến cần phải chờ cho đến khi yêu cầu trước hoàn thành. Khi thông lượng tiếp cận mức tối đa mà phần cứng có thể xử lý, độ trễ xếp hàng tăng mạnh.
KHI MỘT HỆ THỐNG QUÁ TẢI KHÔNG THỂ PHỤC HỒI
Nếu một hệ thống gần đến ngưỡng quá tải, với thông lượng bị đẩy gần đến giới hạn, đôi khi nó có thể rơi vào một vòng xoáy xấu, nơi nó trở nên kém hiệu quả hơn và do đó càng quá tải hơn. Ví dụ, nếu có một hàng đợi dài các yêu cầu chờ xử lý, thời gian phản hồi có thể tăng đến mức client hết thời gian chờ và gửi lại yêu cầu. Điều này khiến tốc độ yêu cầu tăng thêm, làm vấn đề tệ hơn, được gọi là retry storm. Ngay cả khi tải giảm xuống, hệ thống như vậy có thể vẫn ở trạng thái quá tải cho đến khi khởi động lại hoặc được đặt lại bằng cách khác. Hiện tượng này được gọi là lỗi siêu ổn định (metastable failure), và nó có thể gây ra các sự cố nghiêm trọng trong môi trường sản xuất 7 8.
Để tránh các lần thử lại làm quá tải dịch vụ, bạn có thể tăng và ngẫu nhiên hóa thời gian giữa các lần thử lại liên tiếp ở phía client (exponential backoff 9 10), và tạm thời ngừng gửi yêu cầu đến một dịch vụ đã trả về lỗi hoặc hết thời gian chờ gần đây (sử dụng thuật toán circuit breaker 11 12 hoặc token bucket 13). Máy chủ cũng có thể phát hiện khi đang tiếp cận quá tải và bắt đầu chủ động từ chối yêu cầu (load shedding 14), và gửi lại phản hồi yêu cầu client chậm lại (backpressure 1 15). Lựa chọn thuật toán xếp hàng và cân bằng tải cũng có thể tạo ra sự khác biệt 16.
Về các chỉ số hiệu năng, thời gian phản hồi thường là điều người dùng quan tâm nhất, trong khi thông lượng xác định tài nguyên tính toán cần thiết (ví dụ, bạn cần bao nhiêu máy chủ), và do đó là chi phí để phục vụ một khối lượng công việc cụ thể. Nếu thông lượng có khả năng vượt quá những gì phần cứng hiện tại có thể xử lý, năng lực cần được mở rộng; một hệ thống được gọi là có khả năng mở rộng (scalable) nếu thông lượng tối đa của nó có thể tăng đáng kể bằng cách thêm tài nguyên tính toán.
Trong phần này, chúng ta sẽ tập trung chủ yếu vào thời gian phản hồi, và sẽ quay lại thông lượng và khả năng mở rộng trong “Khả Năng Mở Rộng”.
Độ Trễ và Thời Gian Phản Hồi
“Độ trễ” (latency) và “thời gian phản hồi” (response time) đôi khi được dùng thay thế cho nhau, nhưng trong cuốn sách này chúng ta sẽ dùng các thuật ngữ theo một cách cụ thể (được minh họa trong Hình 2-4):
- Thời gian phản hồi (response time) là những gì client thấy; nó bao gồm tất cả các độ trễ phát sinh ở bất kỳ đâu trong hệ thống.
- Thời gian xử lý (service time) là khoảng thời gian dịch vụ đang xử lý chủ động yêu cầu của người dùng.
- Độ trễ xếp hàng (queueing delays) có thể xảy ra ở nhiều điểm trong luồng: ví dụ, sau khi nhận yêu cầu, yêu cầu đó có thể cần chờ cho đến khi CPU sẵn sàng trước khi được xử lý; một gói phản hồi có thể cần được đệm trước khi gửi qua mạng nếu các tác vụ khác trên cùng máy đang gửi nhiều dữ liệu qua giao diện mạng đầu ra.
- Độ trễ (latency) là thuật ngữ bao quát cho thời gian một yêu cầu không được xử lý chủ động, tức là trong thời gian nó đang ở trạng thái tiềm ẩn (latent). Đặc biệt, độ trễ mạng (network latency) hay trễ mạng (network delay) chỉ thời gian yêu cầu và phản hồi truyền qua mạng.
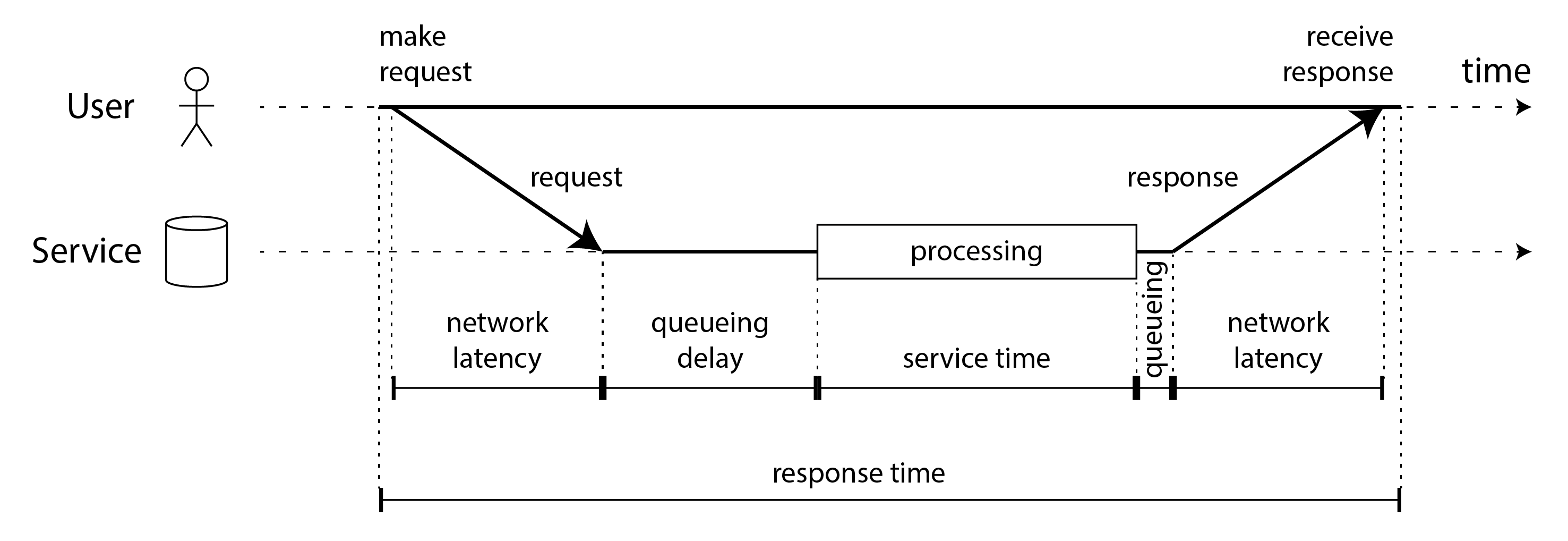
Trong Hình 2-4, thời gian chạy từ trái sang phải, mỗi nút giao tiếp được hiển thị là một đường ngang, và một thông điệp yêu cầu hoặc phản hồi được hiển thị là một mũi tên chéo đậm từ nút này sang nút khác. Bạn sẽ gặp kiểu sơ đồ này thường xuyên trong suốt cuốn sách.
Thời gian phản hồi có thể biến đổi đáng kể từ yêu cầu này sang yêu cầu khác, ngay cả khi bạn liên tục thực hiện cùng một yêu cầu. Nhiều yếu tố có thể thêm độ trễ ngẫu nhiên: ví dụ, chuyển ngữ cảnh sang một tiến trình nền, mất gói mạng và truyền lại TCP, dừng thu gom rác (garbage collection pause), lỗi trang buộc đọc từ đĩa, rung cơ học trong giá đỡ máy chủ 17, hoặc nhiều nguyên nhân khác. Chúng ta sẽ thảo luận chủ đề này chi tiết hơn trong “Thời Gian Chờ và Độ Trễ Không Giới Hạn”.
Độ trễ xếp hàng thường chiếm phần lớn sự biến thiên trong thời gian phản hồi. Vì một máy chủ chỉ có thể xử lý một số lượng nhỏ việc song song (bị giới hạn bởi số lõi CPU chẳng hạn), chỉ cần một số ít yêu cầu chậm cũng có thể cản trở việc xử lý các yêu cầu tiếp theo, hiệu ứng này được gọi là chặn đầu hàng (head-of-line blocking). Ngay cả khi các yêu cầu tiếp theo đó có thời gian xử lý nhanh, client vẫn sẽ thấy thời gian phản hồi tổng thể chậm do phải chờ yêu cầu trước hoàn thành. Độ trễ xếp hàng không phải là một phần của thời gian xử lý, và vì lý do này, điều quan trọng là phải đo thời gian phản hồi ở phía client.
Trung Bình, Trung Vị và Phân Vị
Vì thời gian phản hồi thay đổi từ yêu cầu này sang yêu cầu khác, chúng ta cần nghĩ về nó không phải là một con số duy nhất, mà là một phân phối (distribution) các giá trị có thể đo được. Trong Hình 2-5, mỗi thanh xám đại diện cho một yêu cầu đến dịch vụ, và chiều cao của nó cho thấy yêu cầu đó mất bao lâu. Hầu hết các yêu cầu đều khá nhanh, nhưng có một số giá trị ngoại lệ (outliers) mất lâu hơn nhiều. Sự biến thiên trong độ trễ mạng còn được gọi là jitter.
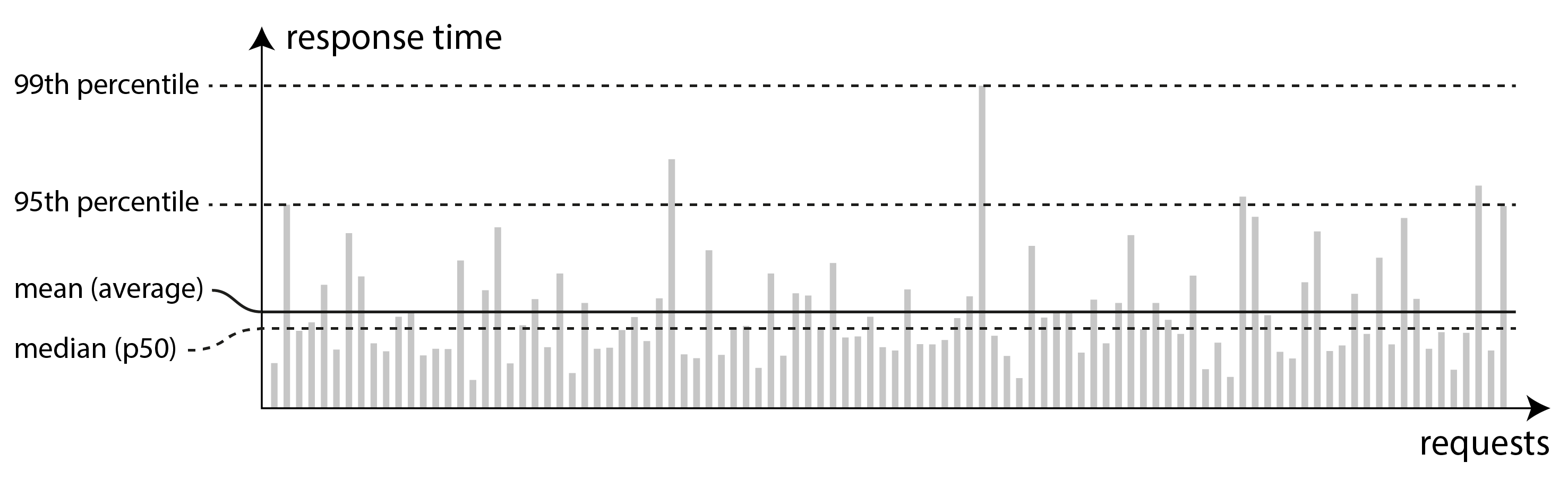
Thông thường người ta báo cáo thời gian phản hồi trung bình (average) của một dịch vụ (về mặt kỹ thuật là trung bình cộng: tức là cộng tất cả các thời gian phản hồi và chia cho số lượng yêu cầu). Thời gian phản hồi trung bình hữu ích để ước tính giới hạn thông lượng 18. Tuy nhiên, trung bình không phải là chỉ số tốt nếu bạn muốn biết thời gian phản hồi “điển hình” của mình, vì nó không cho biết có bao nhiêu người dùng thực sự trải qua độ trễ đó.
Thường thì tốt hơn khi dùng phân vị (percentiles). Nếu bạn lấy danh sách các thời gian phản hồi và sắp xếp từ nhanh đến chậm, thì trung vị (median) là điểm giữa: ví dụ, nếu thời gian phản hồi trung vị của bạn là 200 ms, điều đó có nghĩa là một nửa số yêu cầu của bạn trả về trong chưa đến 200 ms, và một nửa mất lâu hơn. Điều này khiến trung vị là một chỉ số tốt nếu bạn muốn biết người dùng thường phải chờ bao lâu. Trung vị còn được biết đến là phân vị thứ 50 (50th percentile), đôi khi viết tắt là p50.
Để tìm hiểu mức độ tệ của các giá trị ngoại lệ, bạn có thể xem các phân vị cao hơn: phân vị thứ 95, 99 và 99.9 là phổ biến (viết tắt là p95, p99 và p999). Đây là các ngưỡng thời gian phản hồi mà tại đó 95%, 99% hoặc 99.9% các yêu cầu nhanh hơn ngưỡng đó. Ví dụ, nếu thời gian phản hồi ở phân vị thứ 95 là 1.5 giây, có nghĩa là 95 trong 100 yêu cầu mất chưa đến 1.5 giây, và 5 trong 100 yêu cầu mất 1.5 giây hoặc hơn. Điều này được minh họa trong Hình 2-5.
Các phân vị cao của thời gian phản hồi, còn được gọi là độ trễ đuôi (tail latencies), rất quan trọng vì chúng ảnh hưởng trực tiếp đến trải nghiệm người dùng. Ví dụ, Amazon mô tả yêu cầu thời gian phản hồi cho các dịch vụ nội bộ theo phân vị thứ 99.9, mặc dù nó chỉ ảnh hưởng đến 1 trong 1.000 yêu cầu. Điều này là vì những khách hàng có yêu cầu chậm nhất thường là những người có nhiều dữ liệu nhất trong tài khoản vì họ đã thực hiện nhiều giao dịch mua, tức là họ là những khách hàng có giá trị nhất 19. Điều quan trọng là giữ cho những khách hàng đó hài lòng bằng cách đảm bảo trang web nhanh với họ.
Mặt khác, việc tối ưu hóa phân vị thứ 99.99 (1 trong 10.000 yêu cầu chậm nhất) được coi là quá tốn kém và không mang lại đủ lợi ích cho mục đích của Amazon. Giảm thời gian phản hồi ở các phân vị rất cao là khó vì chúng dễ bị ảnh hưởng bởi các sự kiện ngẫu nhiên ngoài tầm kiểm soát của bạn, và lợi ích ngày càng giảm dần.
TÁC ĐỘNG CỦA THỜI GIAN PHẢN HỒI ĐẾN NGƯỜI DÙNG
Có vẻ hiển nhiên rằng một dịch vụ nhanh tốt hơn cho người dùng so với một dịch vụ chậm 20. Tuy nhiên, thật đáng ngạc nhiên khi rất khó có được dữ liệu đáng tin cậy để lượng hóa tác động mà độ trễ (latency) có đến hành vi người dùng.
Một số thống kê thường được trích dẫn không đáng tin cậy. Năm 2006, Google báo cáo rằng sự chậm lại trong kết quả tìm kiếm từ 400 ms lên 900 ms có liên quan đến mức giảm 20% lưu lượng truy cập và doanh thu 21. Tuy nhiên, một nghiên cứu khác của Google năm 2009 báo cáo rằng tăng 400 ms độ trễ chỉ dẫn đến 0.6% ít tìm kiếm hơn mỗi ngày 22, và cùng năm đó Bing nhận thấy rằng tăng hai giây thời gian tải làm giảm doanh thu quảng cáo 4.3% 23. Dữ liệu mới hơn từ các công ty này dường như không được công bố rộng rãi.
Một nghiên cứu gần đây hơn của Akamai 24 cho rằng tăng 100 ms thời gian phản hồi làm giảm tỷ lệ chuyển đổi của các trang thương mại điện tử lên đến 7%; tuy nhiên, xem xét kỹ hơn, cùng một nghiên cứu cho thấy rằng các trang tải rất nhanh cũng tương quan với tỷ lệ chuyển đổi thấp hơn! Kết quả có vẻ nghịch lý này được giải thích bởi thực tế là các trang tải nhanh nhất thường là những trang không có nội dung hữu ích (ví dụ: trang lỗi 404). Tuy nhiên, vì nghiên cứu không cố gắng tách biệt tác động của nội dung trang và tác động của thời gian tải, kết quả của nó có thể không có ý nghĩa.
Một nghiên cứu của Yahoo 25 so sánh tỷ lệ nhấp vào các kết quả tìm kiếm tải nhanh và tải chậm, có kiểm soát chất lượng kết quả tìm kiếm. Nghiên cứu cho thấy nhiều hơn 20-30% lượt nhấp vào các tìm kiếm nhanh khi sự khác biệt giữa phản hồi nhanh và chậm là 1.25 giây trở lên.
Sử Dụng Chỉ Số Thời Gian Phản Hồi
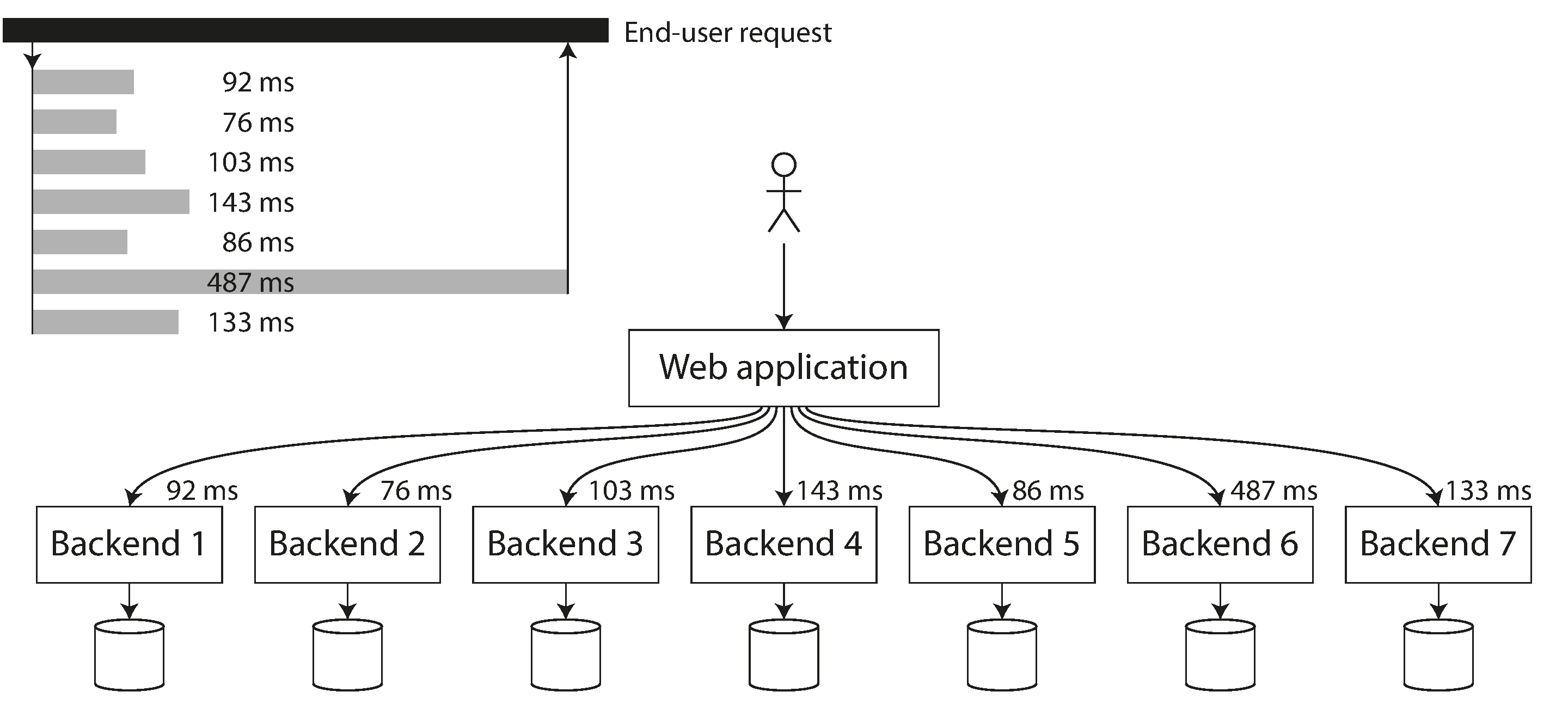
Các phân vị cao đặc biệt quan trọng trong các dịch vụ backend được gọi nhiều lần như một phần để phục vụ một yêu cầu người dùng đầu cuối. Ngay cả khi bạn thực hiện các cuộc gọi song song, yêu cầu người dùng đầu cuối vẫn phải chờ cuộc gọi chậm nhất trong số các cuộc gọi song song hoàn thành. Chỉ cần một cuộc gọi chậm là đủ để làm chậm toàn bộ yêu cầu người dùng đầu cuối, như minh họa trong Hình 2-6. Ngay cả khi chỉ một tỷ lệ nhỏ các cuộc gọi backend chậm, khả năng nhận được một cuộc gọi chậm tăng lên nếu một yêu cầu người dùng đầu cuối yêu cầu nhiều cuộc gọi backend, và do đó tỷ lệ cao hơn các yêu cầu người dùng đầu cuối bị chậm (hiệu ứng được gọi là khuếch đại độ trễ đuôi hay tail latency amplification 26).
Phân vị thường được sử dụng trong mục tiêu mức dịch vụ (service level objectives, SLO) và thỏa thuận mức dịch vụ (service level agreements, SLA) như các cách để xác định hiệu năng và tính khả dụng kỳ vọng của một dịch vụ 27. Ví dụ, một SLO có thể đặt mục tiêu cho một dịch vụ có thời gian phản hồi trung vị dưới 200 ms và phân vị thứ 99 dưới 1 giây, và mục tiêu là ít nhất 99.9% các yêu cầu hợp lệ dẫn đến phản hồi không có lỗi. SLA là một hợp đồng quy định điều gì xảy ra nếu SLO không được đáp ứng (ví dụ, khách hàng có thể được quyền hoàn tiền). Đó là ý tưởng cơ bản, ít nhất là vậy; trong thực tế, việc xác định các chỉ số khả dụng tốt cho SLO và SLA không phải là điều đơn giản 28 29.
TÍNH TOÁN PHÂN VỊ
Nếu bạn muốn thêm các phân vị thời gian phản hồi vào bảng điều khiển giám sát cho các dịch vụ của mình, bạn cần tính toán chúng một cách hiệu quả trên cơ sở liên tục. Ví dụ, bạn có thể muốn giữ một cửa sổ trượt các thời gian phản hồi của các yêu cầu trong 10 phút qua. Mỗi phút, bạn tính toán trung vị và các phân vị khác nhau trên các giá trị trong cửa sổ đó và vẽ các chỉ số đó trên biểu đồ.
Cách triển khai đơn giản nhất là giữ danh sách các thời gian phản hồi cho tất cả các yêu cầu trong cửa sổ thời gian và sắp xếp danh sách đó mỗi phút. Nếu điều đó quá kém hiệu quả, có các thuật toán có thể tính toán xấp xỉ tốt của phân vị với chi phí CPU và bộ nhớ tối thiểu. Các thư viện ước tính phân vị mã nguồn mở bao gồm HdrHistogram, t-digest 30 31, OpenHistogram 32 và DDSketch 33.
Hãy cẩn thận rằng lấy trung bình các phân vị, ví dụ để giảm độ phân giải thời gian hoặc kết hợp dữ liệu từ nhiều máy, là vô nghĩa về mặt toán học, cách đúng để tổng hợp dữ liệu thời gian phản hồi là cộng các histogram 34.
Độ Tin Cậy và Khả Năng Chịu Lỗi
Mọi người đều có trực giác về ý nghĩa của việc một thứ gì đó đáng tin cậy hoặc không đáng tin cậy. Đối với phần mềm, các kỳ vọng điển hình bao gồm:
- Ứng dụng thực hiện chức năng mà người dùng mong đợi.
- Nó có thể chịu đựng được việc người dùng mắc lỗi hoặc sử dụng phần mềm theo những cách không mong đợi.
- Hiệu năng của nó đủ tốt cho trường hợp sử dụng yêu cầu, dưới tải và khối lượng dữ liệu dự kiến.
- Hệ thống ngăn chặn mọi truy cập trái phép và lạm dụng.
Nếu tất cả những điều đó cùng nhau có nghĩa là “hoạt động đúng đắn”, thì chúng ta có thể hiểu độ tin cậy (reliability) có nghĩa là, đại khái, “tiếp tục hoạt động đúng đắn, ngay cả khi có sự cố.” Để nói chính xác hơn về những sự cố xảy ra, chúng ta sẽ phân biệt giữa lỗi (faults) và thất bại (failures) 35 36 37:
- Lỗi (Fault)
- Lỗi là khi một bộ phận cụ thể của hệ thống ngừng hoạt động đúng đắn: ví dụ, nếu một ổ cứng bị hỏng, hoặc một máy bị treo, hoặc một dịch vụ bên ngoài (mà hệ thống phụ thuộc vào) bị gián đoạn.
- Thất bại (Failure)
- Thất bại là khi hệ thống toàn bộ ngừng cung cấp dịch vụ cần thiết cho người dùng; nói cách khác, khi nó không đáp ứng mục tiêu mức dịch vụ (SLO).
Sự phân biệt giữa lỗi và thất bại có thể gây nhầm lẫn vì chúng giống nhau, chỉ khác ở mức độ. Ví dụ, nếu một ổ cứng ngừng hoạt động, chúng ta nói rằng ổ cứng đó đã thất bại: nếu hệ thống chỉ bao gồm một ổ cứng đó, nó đã ngừng cung cấp dịch vụ cần thiết. Tuy nhiên, nếu hệ thống bạn đang nói đến chứa nhiều ổ cứng, thì sự thất bại của một ổ cứng duy nhất chỉ là một lỗi từ góc độ của hệ thống lớn hơn, và hệ thống lớn hơn có thể có khả năng chịu đựng lỗi đó bằng cách có bản sao dữ liệu trên một ổ cứng khác.
Khả Năng Chịu Lỗi
Chúng ta gọi một hệ thống là có khả năng chịu lỗi (fault-tolerant) nếu nó tiếp tục cung cấp dịch vụ cần thiết cho người dùng mặc dù có một số lỗi xảy ra. Nếu một hệ thống không thể chịu đựng một bộ phận nào đó bị lỗi, chúng ta gọi bộ phận đó là điểm lỗi duy nhất (single point of failure, SPOF), vì lỗi ở bộ phận đó leo thang gây ra thất bại của toàn bộ hệ thống.
Ví dụ, trong nghiên cứu tình huống mạng xã hội, một lỗi có thể xảy ra là trong quá trình fan-out, một máy tham gia vào việc cập nhật các dòng thời gian vật chất hóa bị treo hoặc không khả dụng. Để làm cho quá trình này có khả năng chịu lỗi, chúng ta cần đảm bảo rằng một máy khác có thể tiếp quản nhiệm vụ này mà không bỏ sót bất kỳ bài đăng nào đáng lẽ phải được giao, và không trùng lặp bất kỳ bài đăng nào. (Ý tưởng này được gọi là ngữ nghĩa đúng một lần (exactly-once semantics), và chúng ta sẽ xem xét chi tiết trong “Lập Luận Đầu Cuối cho Cơ Sở Dữ Liệu”.)
Khả năng chịu lỗi luôn bị giới hạn ở một số lượng nhất định của các loại lỗi nhất định. Ví dụ, một hệ thống có thể chịu đựng tối đa hai ổ cứng bị hỏng cùng lúc, hoặc tối đa một trong ba nút bị treo. Sẽ không hợp lý khi chịu đựng bất kỳ số lượng lỗi nào: nếu tất cả các nút đều bị treo, không có gì có thể được thực hiện. Nếu toàn bộ Trái Đất (và tất cả các máy chủ trên đó) bị nuốt chửng bởi một lỗ đen, việc chịu đựng lỗi đó sẽ đòi hỏi lưu trữ web trong không gian, chúc may mắn khi xin phê duyệt ngân sách đó.
Trái với trực giác, trong các hệ thống có khả năng chịu lỗi như vậy, đôi khi có ý nghĩa khi tăng tốc độ lỗi bằng cách kích hoạt chúng một cách có chủ đích, ví dụ bằng cách ngẫu nhiên tắt các tiến trình riêng lẻ mà không cảnh báo. Điều này được gọi là tiêm lỗi (fault injection). Nhiều lỗi nghiêm trọng thực ra là do xử lý lỗi kém 38; bằng cách cố tình gây ra lỗi, bạn đảm bảo rằng cơ chế chịu lỗi được liên tục thực thi và kiểm tra, điều này có thể tăng sự tự tin của bạn rằng lỗi sẽ được xử lý đúng khi chúng xảy ra tự nhiên. Kỹ thuật hỗn loạn (chaos engineering) là một ngành nhằm cải thiện sự tự tin vào các cơ chế chịu lỗi thông qua các thí nghiệm như cố ý tiêm lỗi 39.
Mặc dù chúng ta thường thích chịu đựng lỗi hơn là ngăn chặn lỗi, có những trường hợp phòng ngừa tốt hơn chữa trị (ví dụ, vì không có cách chữa trị nào tồn tại). Điều này đúng với các vấn đề bảo mật, chẳng hạn: nếu kẻ tấn công đã xâm phạm một hệ thống và có quyền truy cập vào dữ liệu nhạy cảm, sự kiện đó không thể hoàn tác. Tuy nhiên, cuốn sách này chủ yếu xử lý các loại lỗi có thể được khắc phục, như được mô tả trong các phần sau.
Lỗi Phần Cứng và Lỗi Phần Mềm
Khi nghĩ về nguyên nhân gây ra thất bại hệ thống, lỗi phần cứng nhanh chóng xuất hiện trong đầu:
- Khoảng 2-5% ổ cứng từ tính bị hỏng mỗi năm 40 41; trong một cụm lưu trữ với 10.000 đĩa, chúng ta nên dự kiến trung bình một đĩa bị hỏng mỗi ngày. Dữ liệu gần đây cho thấy đĩa đang trở nên đáng tin cậy hơn, nhưng tỷ lệ hỏng hóc vẫn đáng kể 42.
- Khoảng 0.5-1% ổ đĩa thể rắn (SSD) bị hỏng mỗi năm 43. Một số ít lỗi bit được tự động sửa 44, nhưng các lỗi không thể sửa xảy ra khoảng một lần mỗi năm mỗi đĩa, ngay cả trong các đĩa còn khá mới (tức là đã trải qua ít hao mòn); tỷ lệ lỗi này cao hơn so với ổ cứng từ tính 45 46.
- Các thành phần phần cứng khác như nguồn điện, bộ điều khiển RAID và mô-đun bộ nhớ cũng bị hỏng, mặc dù ít thường xuyên hơn ổ cứng 47 48.
- Khoảng một trong 1.000 máy có lõi CPU đôi khi tính toán kết quả sai, có thể do lỗi sản xuất 49 50 51. Trong một số trường hợp, một phép tính sai dẫn đến treo máy, nhưng trong các trường hợp khác nó dẫn đến một chương trình đơn giản là trả về kết quả sai.
- Dữ liệu trong RAM cũng có thể bị hỏng, do các sự kiện ngẫu nhiên như tia vũ trụ, hoặc do các lỗi vật lý vĩnh viễn. Ngay cả khi bộ nhớ có mã sửa lỗi (ECC) được sử dụng, hơn 1% máy gặp lỗi không thể sửa trong một năm nhất định, thường dẫn đến treo máy và mô-đun bộ nhớ bị ảnh hưởng cần được thay thế 52. Hơn nữa, một số mẫu truy cập bộ nhớ bệnh lý nhất định có thể lật bit với xác suất cao 53.
- Toàn bộ một trung tâm dữ liệu có thể trở nên không khả dụng (ví dụ do mất điện hoặc cấu hình mạng sai) hoặc thậm chí bị phá hủy vĩnh viễn (ví dụ do hỏa hoạn, lũ lụt hoặc động đất 54). Bão mặt trời, gây ra dòng điện lớn trong các dây dẫn đường dài khi mặt trời phóng ra lượng lớn các hạt mang điện, có thể làm hỏng lưới điện và cáp mạng dưới biển 55. Mặc dù các thất bại quy mô lớn như vậy là hiếm, tác động của chúng có thể thảm khốc nếu một dịch vụ không thể chịu đựng việc mất một trung tâm dữ liệu 56.
Những sự kiện này đủ hiếm để bạn thường không cần lo lắng về chúng khi làm việc trên một hệ thống nhỏ, miễn là bạn có thể dễ dàng thay thế phần cứng bị hỏng. Tuy nhiên, trong một hệ thống quy mô lớn, lỗi phần cứng xảy ra đủ thường xuyên đến mức chúng trở thành một phần của hoạt động hệ thống bình thường.
Chịu đựng lỗi phần cứng thông qua dự phòng
Phản ứng đầu tiên của chúng ta với phần cứng không đáng tin cậy thường là thêm dự phòng vào các thành phần phần cứng riêng lẻ để giảm tỷ lệ thất bại của hệ thống. Đĩa có thể được thiết lập theo cấu hình RAID (trải dữ liệu trên nhiều đĩa trong cùng máy để đĩa bị hỏng không gây mất dữ liệu), máy chủ có thể có nguồn điện kép và CPU có thể tháo lắp nóng, và các trung tâm dữ liệu có thể có pin và máy phát điện diesel để dự phòng điện. Sự dự phòng như vậy thường có thể giữ cho máy chạy liên tục trong nhiều năm.
Dự phòng hiệu quả nhất khi các lỗi thành phần là độc lập, tức là sự xuất hiện của một lỗi không thay đổi khả năng một lỗi khác sẽ xảy ra. Tuy nhiên, kinh nghiệm đã cho thấy thường có sự tương quan đáng kể giữa các lỗi thành phần 41 57 58; việc không khả dụng của toàn bộ một giá máy chủ hoặc toàn bộ một trung tâm dữ liệu vẫn xảy ra thường xuyên hơn mong muốn.
Dự phòng phần cứng tăng thời gian hoạt động của một máy đơn lẻ; tuy nhiên, như đã thảo luận trong “Hệ Thống Phân Tán so với Hệ Thống Đơn Nút”, có những lợi thế khi sử dụng một hệ thống phân tán, chẳng hạn như khả năng chịu đựng một sự cố hoàn toàn của một trung tâm dữ liệu. Vì lý do này, các hệ thống đám mây có xu hướng ít tập trung hơn vào độ tin cậy của các máy riêng lẻ, mà thay vào đó nhằm mục tiêu làm cho các dịch vụ có tính khả dụng cao bằng cách chịu đựng các nút bị lỗi ở mức phần mềm. Các nhà cung cấp đám mây sử dụng vùng khả dụng (availability zones) để xác định tài nguyên nào được đặt cùng vị trí vật lý; tài nguyên ở cùng một nơi có nhiều khả năng thất bại cùng lúc hơn so với các tài nguyên được phân tán về mặt địa lý.
Các kỹ thuật chịu lỗi chúng ta thảo luận trong cuốn sách này được thiết kế để chịu đựng việc mất toàn bộ máy, giá máy hoặc vùng khả dụng. Chúng thường hoạt động bằng cách cho phép một máy trong một trung tâm dữ liệu tiếp quản khi một máy trong một trung tâm dữ liệu khác bị hỏng hoặc không thể tiếp cận. Chúng ta sẽ thảo luận các kỹ thuật như vậy về chịu lỗi trong Chương 6, Chương 10 và tại nhiều điểm khác trong cuốn sách này.
Các hệ thống có thể chịu đựng việc mất toàn bộ máy cũng có lợi thế vận hành: một hệ thống đơn máy chủ yêu cầu thời gian ngừng hoạt động có kế hoạch nếu bạn cần khởi động lại máy (ví dụ để áp dụng các bản vá bảo mật hệ điều hành), trong khi một hệ thống chịu lỗi đa nút có thể được vá bằng cách khởi động lại từng nút một, mà không ảnh hưởng đến dịch vụ cho người dùng. Đây được gọi là nâng cấp cuốn chiếu (rolling upgrade), và chúng ta sẽ thảo luận thêm trong Chương 5.
Lỗi phần mềm
Mặc dù lỗi phần cứng có thể có tương quan yếu, chúng vẫn chủ yếu là độc lập: ví dụ, nếu một đĩa bị hỏng, các đĩa khác trong cùng máy có khả năng sẽ ổn trong một thời gian nữa. Mặt khác, lỗi phần mềm thường có tương quan rất cao, vì nhiều nút thường chạy cùng một phần mềm và do đó có cùng các lỗi 59 60. Những lỗi như vậy khó dự đoán hơn, và chúng có xu hướng gây ra nhiều thất bại hệ thống hơn so với lỗi phần cứng không tương quan 47. Ví dụ:
- Một lỗi phần mềm khiến mọi nút bị hỏng cùng lúc trong các hoàn cảnh đặc biệt. Ví dụ, vào ngày 30 tháng 6 năm 2012, một giây nhuận đã khiến nhiều ứng dụng Java bị treo đồng thời do lỗi trong kernel Linux, làm ngừng hoạt động nhiều dịch vụ Internet 61. Do lỗi firmware, tất cả SSD của một số mẫu nhất định đột ngột bị hỏng sau chính xác 32.768 giờ hoạt động (ít hơn 4 năm), khiến dữ liệu trên chúng không thể phục hồi 62.
- Một tiến trình không kiểm soát sử dụng hết tài nguyên chung có giới hạn, chẳng hạn như thời gian CPU, bộ nhớ, không gian đĩa, băng thông mạng hoặc luồng 63. Ví dụ, một tiến trình tiêu thụ quá nhiều bộ nhớ trong khi xử lý một yêu cầu lớn có thể bị hệ điều hành tắt. Một lỗi trong thư viện client có thể gây ra lượng yêu cầu cao hơn nhiều so với dự kiến 64.
- Một dịch vụ mà hệ thống phụ thuộc vào bị chậm lại, không phản hồi hoặc bắt đầu trả về các phản hồi bị hỏng.
- Sự tương tác giữa các hệ thống khác nhau dẫn đến hành vi mới nổi không xảy ra khi mỗi hệ thống được kiểm tra riêng lẻ 65.
- Lỗi dây chuyền, nơi một vấn đề trong một thành phần khiến thành phần khác bị quá tải và chậm lại, điều này đến lượt nó lại làm ngừng thành phần khác 66 67.
Các lỗi gây ra các loại lỗi phần mềm này thường nằm im một thời gian dài cho đến khi chúng được kích hoạt bởi một tập hợp hoàn cảnh bất thường. Trong những hoàn cảnh đó, người ta nhận ra rằng phần mềm đang đưa ra một số giả định về môi trường của nó, và trong khi giả định đó thường đúng, cuối cùng nó không còn đúng nữa vì một lý do nào đó 68 69.
Không có giải pháp nhanh chóng cho vấn đề lỗi hệ thống trong phần mềm. Nhiều điều nhỏ có thể giúp ích: suy nghĩ cẩn thận về các giả định và tương tác trong hệ thống; kiểm tra kỹ lưỡng; cô lập tiến trình; cho phép các tiến trình bị treo và khởi động lại; tránh các vòng phản hồi như retry storm (xem “Khi một hệ thống quá tải không thể phục hồi”); đo lường, giám sát và phân tích hành vi hệ thống trong môi trường sản xuất.
Con Người và Độ Tin Cậy
Con người thiết kế và xây dựng các hệ thống phần mềm, và những người vận hành giữ cho hệ thống chạy cũng là con người. Không giống như máy móc, con người không chỉ tuân theo quy tắc; điểm mạnh của họ là sáng tạo và thích nghi trong việc hoàn thành công việc của mình. Tuy nhiên, đặc điểm này cũng dẫn đến sự không thể đoán trước, và đôi khi là những sai lầm có thể dẫn đến thất bại, mặc dù có ý định tốt. Ví dụ, một nghiên cứu về các dịch vụ internet lớn đã phát hiện rằng các thay đổi cấu hình bởi người vận hành là nguyên nhân hàng đầu gây ra sự cố, trong khi lỗi phần cứng (máy chủ hoặc mạng) chỉ đóng vai trò trong 10-25% các sự cố 70.
Rất dễ dán nhãn các vấn đề như vậy là “lỗi con người” và mong muốn chúng có thể được giải quyết bằng cách kiểm soát tốt hơn hành vi con người thông qua các thủ tục chặt chẽ hơn và tuân thủ các quy tắc. Tuy nhiên, đổ lỗi cho mọi người vì sai lầm là phản tác dụng. Những gì chúng ta gọi là “lỗi con người” thực sự không phải là nguyên nhân của sự cố, mà là triệu chứng của một vấn đề với hệ thống kỹ thuật xã hội trong đó mọi người đang cố gắng hết sức để làm công việc của họ 71. Thường các hệ thống phức tạp có hành vi mới nổi, trong đó các tương tác không mong đợi giữa các thành phần cũng có thể dẫn đến thất bại 72.
Nhiều biện pháp kỹ thuật có thể giúp giảm thiểu tác động của sai lầm con người, bao gồm kiểm tra kỹ lưỡng (cả kiểm tra viết tay và kiểm tra thuộc tính (property testing) trên nhiều đầu vào ngẫu nhiên) 38, cơ chế rollback để nhanh chóng hoàn tác các thay đổi cấu hình, triển khai dần dần mã mới, giám sát chi tiết và rõ ràng, công cụ quan sát (observability) để chẩn đoán các vấn đề sản xuất (xem “Vấn Đề với Hệ Thống Phân Tán”), và các giao diện được thiết kế tốt khuyến khích “điều đúng” và ngăn cản “điều sai”.
Tuy nhiên, những điều này đòi hỏi đầu tư thời gian và tiền bạc, và trong thực tế thực dụng của hoạt động kinh doanh hàng ngày, các tổ chức thường ưu tiên các hoạt động tạo ra doanh thu hơn các biện pháp tăng cường khả năng phục hồi trước sai lầm. Nếu phải chọn giữa nhiều tính năng hơn và kiểm tra nhiều hơn, nhiều tổ chức hiểu được lý do mà chọn tính năng. Với lựa chọn này, khi một sai lầm có thể phòng ngừa chắc chắn xảy ra, không có ý nghĩa gì khi đổ lỗi cho người đã mắc sai lầm, vấn đề là các ưu tiên của tổ chức.
Ngày càng nhiều tổ chức đang áp dụng văn hóa kiểm điểm không đổ lỗi (blameless postmortems): sau một sự cố, những người liên quan được khuyến khích chia sẻ đầy đủ chi tiết về những gì đã xảy ra, mà không sợ bị trừng phạt, vì điều này cho phép những người khác trong tổ chức học cách ngăn chặn các vấn đề tương tự trong tương lai 73. Quá trình này có thể phát lộ sự cần thiết phải thay đổi ưu tiên kinh doanh, sự cần thiết phải đầu tư vào các lĩnh vực đã bị bỏ quên, sự cần thiết phải thay đổi các khuyến khích cho những người liên quan, hoặc một số vấn đề hệ thống khác cần được đưa đến sự chú ý của ban quản lý.
Như một nguyên tắc chung, khi điều tra một sự cố, bạn nên hoài nghi với các câu trả lời đơn giản. “Bob đáng lẽ phải cẩn thận hơn khi triển khai thay đổi đó” là không hiệu quả, nhưng “Chúng ta phải viết lại backend bằng Haskell” cũng vậy. Thay vào đó, ban quản lý nên tận dụng cơ hội để tìm hiểu chi tiết về cách hệ thống kỹ thuật xã hội hoạt động từ góc độ của những người làm việc với nó mỗi ngày, và thực hiện các bước cải thiện nó dựa trên phản hồi này 71.
ĐỘ TIN CẬY QUAN TRỌNG NHƯ THẾ NÀO?
Độ tin cậy không chỉ dành cho các nhà máy điện hạt nhân và kiểm soát không lưu, các ứng dụng bình thường hơn cũng được kỳ vọng hoạt động đáng tin cậy. Lỗi trong các ứng dụng kinh doanh gây ra mất năng suất (và rủi ro pháp lý nếu các con số được báo cáo không chính xác), và sự cố của các trang thương mại điện tử có thể có chi phí khổng lồ về mất doanh thu và thiệt hại uy tín.
Trong nhiều ứng dụng, một sự cố tạm thời vài phút hoặc thậm chí vài giờ là có thể chấp nhận 74, nhưng mất hoặc hỏng dữ liệu vĩnh viễn sẽ là thảm họa. Hãy nghĩ đến một bậc phụ huynh lưu tất cả ảnh và video về con cái của họ trong ứng dụng ảnh của bạn 75. Họ sẽ cảm thấy thế nào nếu cơ sở dữ liệu đó đột nhiên bị hỏng? Họ có biết cách khôi phục từ bản sao lưu không?
Như một ví dụ khác về cách phần mềm không đáng tin cậy có thể gây hại cho mọi người, hãy xem xét vụ bê bối Post Office Horizon. Giữa năm 1999 và 2019, hàng trăm người quản lý các chi nhánh Bưu điện ở Anh đã bị kết tội trộm cắp hoặc gian lận vì phần mềm kế toán hiển thị thiếu hụt trong tài khoản của họ. Cuối cùng, rõ ràng là nhiều thiếu hụt này là do lỗi trong phần mềm, và nhiều bản án đã được lật ngược kể từ đó 76. Điều dẫn đến điều này, có lẽ là sự bất công tư pháp lớn nhất trong lịch sử Anh, là thực tế là luật Anh giả định rằng máy tính hoạt động đúng (và do đó, bằng chứng do máy tính tạo ra là đáng tin cậy) trừ khi có bằng chứng ngược lại 77. Các kỹ sư phần mềm có thể cười nhạo ý tưởng rằng phần mềm có thể không có lỗi, nhưng điều này không có ích gì cho những người đã bị bỏ tù oan, tuyên bố phá sản, hoặc thậm chí tự tử vì bị kết tội oan do một hệ thống máy tính không đáng tin cậy.
Có những tình huống mà chúng ta có thể chọn hy sinh độ tin cậy để giảm chi phí phát triển (ví dụ, khi phát triển sản phẩm nguyên mẫu cho một thị trường chưa được kiểm chứng), nhưng chúng ta phải rất ý thức về khi nào chúng ta đang cắt giảm và ghi nhớ các hậu quả tiềm tàng.
Khả Năng Mở Rộng
Ngay cả khi một hệ thống đang hoạt động đáng tin cậy hôm nay, điều đó không có nghĩa là nó nhất thiết sẽ hoạt động đáng tin cậy trong tương lai. Một lý do phổ biến cho sự suy giảm là tải tăng lên: có lẽ hệ thống đã tăng từ 10.000 người dùng đồng thời lên 100.000, hoặc từ 1 triệu lên 10 triệu. Có lẽ nó đang xử lý khối lượng dữ liệu lớn hơn nhiều so với trước đây.
Khả năng mở rộng (scalability) là thuật ngữ chúng ta dùng để mô tả khả năng của một hệ thống trong việc đối phó với tải tăng lên. Đôi khi, khi thảo luận về khả năng mở rộng, mọi người đưa ra nhận xét kiểu như “Bạn không phải Google hay Amazon. Đừng lo lắng về quy mô và chỉ cần dùng cơ sở dữ liệu quan hệ.” Liệu phương châm này có áp dụng cho bạn hay không phụ thuộc vào loại ứng dụng bạn đang xây dựng.
Nếu bạn đang xây dựng một sản phẩm mới hiện chỉ có ít người dùng, có lẽ ở giai đoạn startup, mục tiêu kỹ thuật chủ đạo thường là giữ hệ thống đơn giản và linh hoạt nhất có thể, để bạn có thể dễ dàng sửa đổi và thích ứng các tính năng của sản phẩm khi bạn tìm hiểu thêm về nhu cầu của khách hàng 78. Trong môi trường như vậy, lo lắng về quy mô giả thuyết có thể cần thiết trong tương lai là phản tác dụng: trong trường hợp tốt nhất, đầu tư vào khả năng mở rộng là nỗ lực lãng phí và tối ưu hóa sớm; trong trường hợp xấu nhất, chúng khóa bạn vào một thiết kế cứng nhắc và làm cho việc phát triển ứng dụng khó hơn.
Lý do là khả năng mở rộng không phải là một nhãn một chiều: vô nghĩa khi nói “X có thể mở rộng” hoặc “Y không thể mở rộng.” Thay vào đó, thảo luận về khả năng mở rộng có nghĩa là xem xét các câu hỏi như:
- “Nếu hệ thống phát triển theo một cách cụ thể, các lựa chọn của chúng ta để đối phó với sự tăng trưởng là gì?”
- “Làm thế nào chúng ta có thể thêm tài nguyên tính toán để xử lý tải bổ sung?”
- “Dựa trên các dự báo tăng trưởng hiện tại, khi nào chúng ta sẽ đạt đến giới hạn của kiến trúc hiện tại?”
Nếu bạn thành công trong việc làm cho ứng dụng của mình phổ biến, và do đó xử lý lượng tải ngày càng tăng, bạn sẽ biết được các điểm nghẽn cổ chai về hiệu năng của mình nằm ở đâu, và do đó bạn sẽ biết cần mở rộng theo những chiều nào. Đến lúc đó mới là lúc bắt đầu lo lắng về các kỹ thuật khả năng mở rộng.
Mô Tả Tải
Trước tiên, chúng ta cần mô tả ngắn gọn tải hiện tại trên hệ thống; chỉ sau đó chúng ta mới có thể thảo luận về các câu hỏi tăng trưởng (điều gì xảy ra nếu tải của chúng ta tăng gấp đôi?). Thường đây sẽ là một thước đo thông lượng: ví dụ, số lượng yêu cầu mỗi giây đến một dịch vụ, bao nhiêu gigabyte dữ liệu mới đến mỗi ngày, hoặc số lượng giỏ hàng thanh toán mỗi giờ. Đôi khi bạn quan tâm đến đỉnh của một lượng biến đổi nào đó, chẳng hạn như số người dùng trực tuyến đồng thời trong “Nghiên Cứu Tình Huống: Dòng Thời Gian Trang Chủ Mạng Xã Hội”.
Thường có các đặc điểm thống kê khác của tải cũng ảnh hưởng đến các mẫu truy cập và do đó các yêu cầu về khả năng mở rộng. Ví dụ, bạn có thể cần biết tỷ lệ đọc và ghi trong cơ sở dữ liệu, tỷ lệ trúng cache, hoặc số mục dữ liệu mỗi người dùng (ví dụ, số người theo dõi trong nghiên cứu tình huống mạng xã hội). Có lẽ trường hợp trung bình là điều quan trọng với bạn, hoặc có lẽ điểm nghẽn cổ chai của bạn bị chi phối bởi một số ít trường hợp cực đoan. Tất cả phụ thuộc vào chi tiết của ứng dụng cụ thể của bạn.
Một khi bạn đã mô tả tải trên hệ thống của mình, bạn có thể điều tra điều gì xảy ra khi tải tăng. Bạn có thể xem xét theo hai cách:
- Khi bạn tăng tải theo một cách cụ thể và giữ nguyên tài nguyên hệ thống (CPU, bộ nhớ, băng thông mạng, v.v.), hiệu năng của hệ thống của bạn bị ảnh hưởng như thế nào?
- Khi bạn tăng tải theo một cách cụ thể, bạn cần tăng tài nguyên bao nhiêu nếu bạn muốn giữ hiệu năng không thay đổi?
Thường mục tiêu của chúng ta là giữ hiệu năng của hệ thống trong các yêu cầu của SLA (xem “Sử Dụng Chỉ Số Thời Gian Phản Hồi”) trong khi cũng giảm thiểu chi phí vận hành hệ thống. Tài nguyên tính toán càng nhiều thì chi phí càng cao. Có thể một số loại phần cứng có hiệu quả chi phí hơn loại khác, và các yếu tố này có thể thay đổi theo thời gian khi có các loại phần cứng mới.
Nếu bạn có thể tăng gấp đôi tài nguyên để xử lý gấp đôi tải trong khi giữ hiệu năng như nhau, chúng ta nói rằng bạn có khả năng mở rộng tuyến tính (linear scalability), và đây được coi là điều tốt. Đôi khi có thể xử lý gấp đôi tải với ít hơn gấp đôi tài nguyên, do tính kinh tế theo quy mô hoặc phân phối tải đỉnh tốt hơn 79 80. Có nhiều khả năng hơn là chi phí tăng nhanh hơn tuyến tính, và có thể có nhiều lý do cho sự kém hiệu quả. Ví dụ, nếu bạn có nhiều dữ liệu, thì việc xử lý một yêu cầu ghi duy nhất có thể đòi hỏi nhiều công việc hơn so với khi bạn có ít dữ liệu, ngay cả khi kích thước của yêu cầu là như nhau.
Kiến Trúc Bộ Nhớ Chung, Đĩa Chung và Không Chia Sẻ Gì
Cách đơn giản nhất để tăng tài nguyên phần cứng của một dịch vụ là chuyển nó sang một máy mạnh hơn. Các lõi CPU riêng lẻ không còn nhanh hơn đáng kể nữa, nhưng bạn có thể mua một máy (hoặc thuê một phiên bản đám mây) với nhiều lõi CPU hơn, nhiều RAM hơn và nhiều không gian đĩa hơn. Cách tiếp cận này được gọi là mở rộng theo chiều dọc (vertical scaling) hay scale up.
Bạn có thể đạt được tính song song trên một máy đơn bằng cách sử dụng nhiều tiến trình hoặc luồng. Tất cả các luồng thuộc cùng một tiến trình có thể truy cập cùng một RAM, và do đó cách tiếp cận này cũng được gọi là kiến trúc bộ nhớ chung (shared-memory architecture). Vấn đề với cách tiếp cận bộ nhớ chung là chi phí tăng nhanh hơn tuyến tính: một máy cao cấp với gấp đôi tài nguyên phần cứng thường tốn hơn gấp đôi. Và do các điểm nghẽn cổ chai, một máy có kích thước gấp đôi thường chỉ xử lý được ít hơn gấp đôi tải.
Một cách tiếp cận khác là kiến trúc đĩa chung (shared-disk architecture), sử dụng nhiều máy với CPU và RAM độc lập, nhưng lưu trữ dữ liệu trên một mảng đĩa được chia sẻ giữa các máy, được kết nối qua một mạng nhanh: Network-Attached Storage (NAS) hoặc Storage Area Network (SAN). Kiến trúc này theo truyền thống được sử dụng cho khối lượng công việc kho dữ liệu tại chỗ, nhưng tranh chấp và overhead của khóa giới hạn khả năng mở rộng của cách tiếp cận đĩa chung 81.
Ngược lại, kiến trúc không chia sẻ gì (shared-nothing architecture) 82 (còn gọi là mở rộng theo chiều ngang hay scale out) đã trở nên rất phổ biến. Trong cách tiếp cận này, chúng ta sử dụng một hệ thống phân tán với nhiều nút, mỗi nút có CPU, RAM và đĩa riêng. Mọi phối hợp giữa các nút được thực hiện ở mức phần mềm, thông qua một mạng thông thường.
Lợi thế của kiến trúc không chia sẻ gì là nó có tiềm năng mở rộng tuyến tính, có thể sử dụng bất kỳ phần cứng nào cung cấp tỷ lệ giá/hiệu năng tốt nhất (đặc biệt trên đám mây), có thể dễ dàng điều chỉnh tài nguyên phần cứng khi tải tăng hoặc giảm, và có thể đạt được khả năng chịu lỗi lớn hơn bằng cách phân tán hệ thống qua nhiều trung tâm dữ liệu và vùng. Nhược điểm là nó đòi hỏi sharding rõ ràng (xem Chương 7), và nó phát sinh tất cả sự phức tạp của hệ thống phân tán (Chương 9).
Một số hệ thống cơ sở dữ liệu gốc đám mây sử dụng các dịch vụ riêng biệt cho lưu trữ và thực thi giao dịch (xem “Tách biệt lưu trữ và tính toán”), với nhiều nút tính toán chia sẻ quyền truy cập vào cùng một dịch vụ lưu trữ. Mô hình này có một số điểm tương đồng với kiến trúc đĩa chung, nhưng nó tránh các vấn đề về khả năng mở rộng của các hệ thống cũ hơn: thay vì cung cấp trừu tượng hóa filesystem (NAS) hoặc thiết bị block (SAN), dịch vụ lưu trữ cung cấp một API chuyên biệt được thiết kế cho nhu cầu cụ thể của cơ sở dữ liệu 83.
Nguyên Tắc cho Khả Năng Mở Rộng
Kiến trúc của các hệ thống hoạt động ở quy mô lớn thường rất đặc thù với ứng dụng, không có kiến trúc mở rộng chung, phù hợp với tất cả (thường được gọi không chính thức là magic scaling sauce). Ví dụ, một hệ thống được thiết kế để xử lý 100.000 yêu cầu mỗi giây, mỗi yêu cầu 1 kB, trông rất khác so với một hệ thống được thiết kế cho 3 yêu cầu mỗi phút, mỗi yêu cầu 2 GB, mặc dù hai hệ thống có cùng thông lượng dữ liệu (100 MB/giây).
Hơn nữa, một kiến trúc phù hợp cho một mức tải thường không thể đối phó với 10 lần tải đó. Nếu bạn đang làm việc trên một dịch vụ phát triển nhanh, do đó có thể bạn sẽ cần phải suy nghĩ lại kiến trúc của mình sau mỗi bậc tải lớn hơn. Vì nhu cầu của ứng dụng có khả năng phát triển, thường không đáng để lên kế hoạch cho nhu cầu mở rộng trong tương lai vượt quá một bậc độ lớn.
Một nguyên tắc chung tốt cho khả năng mở rộng là phân tách một hệ thống thành các thành phần nhỏ hơn có thể hoạt động phần lớn độc lập với nhau. Đây là nguyên tắc cơ bản đằng sau microservices (xem “Microservices và Serverless”), sharding (Chương 7), xử lý luồng (Chương 12) và kiến trúc không chia sẻ gì. Tuy nhiên, thách thức là biết ranh giới giữa những thứ nên ở cùng nhau và những thứ nên tách ra. Hướng dẫn thiết kế cho microservices có thể được tìm thấy trong các sách khác 84, và chúng ta thảo luận về sharding của hệ thống không chia sẻ gì trong Chương 7.
Một nguyên tắc tốt khác là không làm mọi thứ phức tạp hơn mức cần thiết. Nếu một cơ sở dữ liệu đơn máy sẽ hoàn thành công việc, nó có thể tốt hơn một thiết lập phân tán phức tạp. Các hệ thống tự mở rộng (tự động thêm hoặc xóa tài nguyên để đáp ứng nhu cầu) thật thú vị, nhưng nếu tải của bạn khá có thể dự đoán, một hệ thống được mở rộng thủ công có thể ít bất ngờ về mặt vận hành hơn (xem “Vận Hành: Cân Bằng Tự Động hay Thủ Công”). Một hệ thống với năm dịch vụ đơn giản hơn một hệ thống với năm mươi dịch vụ. Các kiến trúc tốt thường bao gồm sự kết hợp thực dụng của các cách tiếp cận.
Khả Năng Bảo Trì
Phần mềm không bị hao mòn hay mỏi vật liệu, vì vậy nó không bị hỏng theo cùng cách như các vật thể cơ học. Nhưng các yêu cầu cho một ứng dụng thường xuyên thay đổi, môi trường mà phần mềm chạy trong thay đổi (chẳng hạn như các phụ thuộc và nền tảng cơ bản), và nó có các lỗi cần sửa.
Người ta thừa nhận rộng rãi rằng phần lớn chi phí của phần mềm không nằm ở quá trình phát triển ban đầu, mà ở quá trình bảo trì liên tục, sửa lỗi, giữ cho hệ thống hoạt động, điều tra sự cố, thích nghi với nền tảng mới, sửa đổi cho các trường hợp sử dụng mới, trả nợ kỹ thuật và thêm tính năng mới 85 86.
Tuy nhiên, bảo trì cũng khó khăn. Nếu một hệ thống đã chạy thành công trong một thời gian dài, nó có thể sử dụng các công nghệ lỗi thời mà không nhiều kỹ sư hiểu ngày nay (chẳng hạn như máy tính lớn và mã COBOL); kiến thức tổ chức về cách và tại sao một hệ thống được thiết kế theo một cách nhất định có thể đã bị mất khi mọi người rời tổ chức; có thể cần thiết phải sửa sai lầm của người khác. Hơn nữa, hệ thống máy tính thường gắn liền với tổ chức con người mà nó hỗ trợ, có nghĩa là bảo trì các hệ thống kế thừa (legacy) như vậy là một vấn đề con người không kém phần kỹ thuật 87.
Mọi hệ thống chúng ta tạo ra ngày nay cuối cùng sẽ trở thành một hệ thống kế thừa nếu nó đủ có giá trị để tồn tại trong một thời gian dài. Để giảm thiểu khó khăn cho các thế hệ tương lai cần bảo trì phần mềm của chúng ta, chúng ta nên thiết kế nó với các mối quan tâm bảo trì trong tâm trí. Mặc dù chúng ta không thể luôn luôn dự đoán những quyết định nào có thể tạo ra đau đầu bảo trì trong tương lai, trong cuốn sách này chúng ta sẽ chú ý đến một số nguyên tắc được áp dụng rộng rãi:
- Khả năng vận hành (Operability)
- Giúp tổ chức dễ dàng giữ cho hệ thống chạy trơn tru.
- Tính đơn giản (Simplicity)
- Giúp các kỹ sư mới dễ dàng hiểu hệ thống, bằng cách triển khai nó sử dụng các mẫu và cấu trúc được hiểu rõ và nhất quán, tránh sự phức tạp không cần thiết.
- Khả năng phát triển (Evolvability)
- Giúp các kỹ sư dễ dàng thực hiện các thay đổi cho hệ thống trong tương lai, thích nghi và mở rộng nó cho các trường hợp sử dụng không được dự kiến khi các yêu cầu thay đổi.
Khả Năng Vận Hành: Làm Cuộc Sống Dễ Dàng hơn cho Vận Hành
Chúng ta đã thảo luận về vai trò của vận hành trong “Vận Hành trong Thời Đại Đám Mây”, và chúng ta thấy rằng các quy trình con người ít nhất cũng quan trọng đối với hoạt động đáng tin cậy như các công cụ phần mềm. Thực tế, người ta đã gợi ý rằng “vận hành tốt thường có thể khắc phục những hạn chế của phần mềm xấu (hoặc chưa hoàn chỉnh), nhưng phần mềm tốt không thể chạy đáng tin cậy với vận hành xấu” 60.
Trong các hệ thống quy mô lớn bao gồm hàng nghìn máy, bảo trì thủ công sẽ quá tốn kém, và tự động hóa là điều thiết yếu. Tuy nhiên, tự động hóa có thể là một con dao hai lưỡi: sẽ luôn có các trường hợp cạnh (như các kịch bản lỗi hiếm gặp) đòi hỏi sự can thiệp thủ công từ đội vận hành. Vì các trường hợp không thể xử lý tự động là các vấn đề phức tạp nhất, tự động hóa nhiều hơn đòi hỏi đội vận hành có kỹ năng cao hơn để giải quyết những vấn đề đó 88.
Hơn nữa, nếu một hệ thống tự động gặp sự cố, thường khó khắc phục hơn một hệ thống dựa vào người vận hành thực hiện một số hành động thủ công. Vì lý do đó, không phải tự động hóa nhiều hơn luôn luôn tốt hơn cho khả năng vận hành. Tuy nhiên, một mức độ tự động hóa nhất định là quan trọng, và điểm ngọt ngào sẽ phụ thuộc vào các chi tiết cụ thể của ứng dụng và tổ chức của bạn.
Khả năng vận hành tốt có nghĩa là làm cho các tác vụ thường xuyên trở nên dễ dàng, cho phép đội vận hành tập trung nỗ lực của họ vào các hoạt động có giá trị cao. Các hệ thống dữ liệu có thể làm nhiều thứ để làm cho các tác vụ thường xuyên trở nên dễ dàng, bao gồm 89:
- Cho phép các công cụ giám sát kiểm tra các chỉ số chính của hệ thống, và hỗ trợ các công cụ quan sát (xem “Vấn Đề với Hệ Thống Phân Tán”) để cung cấp thông tin chi tiết về hành vi thời gian chạy của hệ thống. Nhiều công cụ thương mại và mã nguồn mở có thể giúp ích ở đây 90.
- Tránh phụ thuộc vào các máy riêng lẻ (cho phép máy bị tắt để bảo trì trong khi hệ thống tổng thể tiếp tục chạy không bị gián đoạn)
- Cung cấp tài liệu tốt và mô hình vận hành dễ hiểu (“Nếu tôi làm X, Y sẽ xảy ra”)
- Cung cấp hành vi mặc định tốt, nhưng cũng cho phép quản trị viên tự do ghi đè các mặc định khi cần
- Tự phục hồi khi thích hợp, nhưng cũng cho phép quản trị viên kiểm soát thủ công trạng thái hệ thống khi cần
- Thể hiện hành vi có thể dự đoán, giảm thiểu bất ngờ
Tính Đơn Giản: Quản Lý Sự Phức Tạp
Các dự án phần mềm nhỏ có thể có mã đơn giản và biểu đạt một cách thú vị, nhưng khi các dự án lớn hơn, chúng thường trở nên rất phức tạp và khó hiểu. Sự phức tạp này làm chậm tất cả những ai cần làm việc trên hệ thống, tiếp tục tăng chi phí bảo trì. Một dự án phần mềm bị sa lầy trong sự phức tạp đôi khi được mô tả là đống bùn lớn (big ball of mud) 91.
Khi sự phức tạp làm cho bảo trì khó khăn, ngân sách và lịch trình thường bị vượt quá. Trong phần mềm phức tạp, cũng có nhiều rủi ro hơn trong việc đưa ra lỗi khi thực hiện thay đổi: khi hệ thống khó hiểu và lý luận hơn với nhà phát triển, các giả định ẩn, hậu quả không mong muốn và các tương tác bất ngờ dễ bị bỏ qua hơn 69. Ngược lại, giảm sự phức tạp cải thiện đáng kể khả năng bảo trì của phần mềm, và do đó sự đơn giản nên là một mục tiêu chính cho các hệ thống chúng ta xây dựng.
Các hệ thống đơn giản dễ hiểu hơn, và do đó chúng ta nên cố gắng giải quyết một vấn đề nhất định theo cách đơn giản nhất có thể. Thật không may, điều này dễ nói hơn làm. Liệu một thứ gì đó có đơn giản hay không thường là vấn đề chủ quan về sở thích, vì không có tiêu chuẩn khách quan về sự đơn giản 92. Ví dụ, một hệ thống có thể ẩn một triển khai phức tạp đằng sau một giao diện đơn giản, trong khi một hệ thống khác có thể có một triển khai đơn giản nhưng hiển thị nhiều chi tiết nội bộ hơn cho người dùng, cái nào đơn giản hơn?
Một nỗ lực lý luận về sự phức tạp là chia nó thành hai loại, phức tạp thiết yếu (essential complexity) và phức tạp tình cờ (accidental complexity) 93. Ý tưởng là phức tạp thiết yếu vốn có trong miền vấn đề của ứng dụng, trong khi phức tạp tình cờ chỉ phát sinh do giới hạn của công cụ của chúng ta. Thật không may, sự phân biệt này cũng có lỗ hổng, vì ranh giới giữa thiết yếu và tình cờ dịch chuyển khi công cụ của chúng ta phát triển 94.
Một trong những công cụ tốt nhất chúng ta có để quản lý sự phức tạp là trừu tượng hóa (abstraction). Một trừu tượng hóa tốt có thể ẩn rất nhiều chi tiết triển khai đằng sau một giao diện sạch sẽ, dễ hiểu. Một trừu tượng hóa tốt cũng có thể được sử dụng cho nhiều ứng dụng khác nhau. Không chỉ việc tái sử dụng này hiệu quả hơn so với việc triển khai lại một thứ tương tự nhiều lần, mà nó còn dẫn đến phần mềm chất lượng cao hơn, vì các cải tiến chất lượng trong thành phần được trừu tượng hóa mang lại lợi ích cho tất cả các ứng dụng sử dụng nó.
Ví dụ, các ngôn ngữ lập trình cấp cao là các trừu tượng hóa ẩn mã máy, các thanh ghi CPU và syscall. SQL là một trừu tượng hóa ẩn các cấu trúc dữ liệu phức tạp trên đĩa và trong bộ nhớ, các yêu cầu đồng thời từ các client khác và sự không nhất quán sau sự cố. Tất nhiên, khi lập trình trong một ngôn ngữ cấp cao, chúng ta vẫn đang sử dụng mã máy; chúng ta chỉ không sử dụng nó trực tiếp, vì trừu tượng hóa ngôn ngữ lập trình giúp chúng ta không phải nghĩ về điều đó.
Các trừu tượng hóa cho mã ứng dụng, nhằm giảm sự phức tạp của nó, có thể được tạo ra bằng các phương pháp luận như mẫu thiết kế (design patterns) 95 và thiết kế hướng miền (domain-driven design, DDD) 96. Cuốn sách này không phải về các trừu tượng hóa đặc thù ứng dụng như vậy, mà về các trừu tượng hóa mục đích chung mà bạn có thể xây dựng ứng dụng của mình trên đó, chẳng hạn như giao dịch cơ sở dữ liệu, chỉ mục và nhật ký sự kiện. Nếu bạn muốn sử dụng các kỹ thuật như DDD, bạn có thể triển khai chúng trên các nền tảng được mô tả trong cuốn sách này.
Khả Năng Phát Triển: Làm Cho Thay Đổi Dễ Dàng
Rất khó xảy ra rằng các yêu cầu của hệ thống của bạn sẽ không thay đổi mãi mãi. Chúng có nhiều khả năng hơn là liên tục biến đổi: bạn học được những sự kiện mới, các trường hợp sử dụng chưa được dự kiến xuất hiện, các ưu tiên kinh doanh thay đổi, người dùng yêu cầu các tính năng mới, các nền tảng mới thay thế các nền tảng cũ, các yêu cầu pháp lý hoặc quy định thay đổi, sự tăng trưởng của hệ thống buộc phải thay đổi kiến trúc, v.v.
Về các quy trình tổ chức, các mẫu làm việc Agile cung cấp một khung để thích nghi với sự thay đổi. Cộng đồng Agile cũng đã phát triển các công cụ và quy trình kỹ thuật hữu ích khi phát triển phần mềm trong môi trường thay đổi thường xuyên, chẳng hạn như phát triển hướng kiểm thử (test-driven development, TDD) và tái cấu trúc (refactoring). Trong cuốn sách này, chúng ta tìm kiếm các cách tăng tính linh hoạt ở cấp độ một hệ thống bao gồm một số ứng dụng hoặc dịch vụ khác nhau với các đặc điểm khác nhau.
Sự dễ dàng mà bạn có thể sửa đổi một hệ thống dữ liệu và thích nghi nó với các yêu cầu thay đổi gắn liền với sự đơn giản và trừu tượng hóa của nó: các hệ thống đơn giản, ghép lỏng thường dễ sửa đổi hơn các hệ thống phức tạp, ghép chặt. Vì đây là một ý tưởng quan trọng như vậy, chúng ta sẽ dùng một từ khác để chỉ tính linh hoạt ở cấp độ hệ thống dữ liệu: khả năng phát triển (evolvability) 97.
Một yếu tố lớn làm cho sự thay đổi khó khăn trong các hệ thống lớn là khi một số hành động không thể đảo ngược, và do đó hành động đó cần được thực hiện rất cẩn thận 98. Ví dụ, giả sử bạn đang di chuyển từ một cơ sở dữ liệu sang cơ sở dữ liệu khác: nếu bạn không thể quay lại hệ thống cũ trong trường hợp có vấn đề với hệ thống mới, rủi ro cao hơn nhiều so với khi bạn có thể dễ dàng quay lại. Giảm thiểu tính không thể đảo ngược cải thiện tính linh hoạt.
Tóm Tắt
Trong chương này, chúng ta đã xem xét một số ví dụ về các yêu cầu phi chức năng: hiệu năng, độ tin cậy, khả năng mở rộng và khả năng bảo trì. Qua các chủ đề này, chúng ta cũng đã gặp các nguyên tắc và thuật ngữ mà chúng ta sẽ cần trong suốt phần còn lại của cuốn sách. Chúng ta bắt đầu với một nghiên cứu tình huống về cách người ta có thể triển khai dòng thời gian trangchủ trong một mạng xã hội, minh họa một số thách thức phát sinh ở quy mô lớn.
Chúng ta đã thảo luận về cách đo lường hiệu năng (ví dụ, sử dụng phân vị thời gian phản hồi), tải trên một hệ thống (ví dụ, sử dụng các chỉ số thông lượng), và cách chúng được sử dụng trong SLA. Khả năng mở rộng là một khái niệm liên quan chặt chẽ: đó là đảm bảo hiệu năng không thay đổi khi tải tăng lên. Chúng ta đã thấy một số nguyên tắc chung cho khả năng mở rộng, chẳng hạn như phân tách một tác vụ thành các phần nhỏ hơn có thể hoạt động độc lập, và chúng ta sẽ đi sâu vào chi tiết kỹ thuật về các kỹ thuật khả năng mở rộng trong các chương tiếp theo.
Để đạt được độ tin cậy, bạn có thể sử dụng các kỹ thuật chịu lỗi, cho phép một hệ thống tiếp tục cung cấp dịch vụ ngay cả khi một số thành phần (ví dụ, một đĩa, một máy, hoặc một dịch vụ khác) bị lỗi. Chúng ta đã thấy các ví dụ về lỗi phần cứng có thể xảy ra, và phân biệt chúng với lỗi phần mềm, vốn khó xử lý hơn vì chúng thường có tương quan chặt chẽ. Một khía cạnh khác của việc đạt được độ tin cậy là xây dựng khả năng phục hồi trước sai lầm của con người, và chúng ta đã thấy kiểm điểm không đổ lỗi như một kỹ thuật để học hỏi từ các sự cố.
Cuối cùng, chúng ta đã xem xét một số khía cạnh của khả năng bảo trì, bao gồm hỗ trợ công việc của các đội vận hành, quản lý sự phức tạp và làm cho việc phát triển chức năng của ứng dụng theo thời gian trở nên dễ dàng. Không có câu trả lời dễ dàng nào về cách đạt được những điều này, nhưng một điều có thể giúp ích là xây dựng các ứng dụng sử dụng các khối xây dựng được hiểu rõ cung cấp các trừu tượng hóa hữu ích. Phần còn lại của cuốn sách này sẽ đề cập đến một số khối xây dựng đã được chứng minh là có giá trị trong thực tế.
Tài Liệu Tham Khảo
Mike Cvet. How We Learned to Stop Worrying and Love Fan-In at Twitter. At QCon San Francisco, December 2016. ↩︎ ↩︎
Raffi Krikorian. Timelines at Scale. At QCon San Francisco, November 2012. Archived at perma.cc/V9G5-KLYK ↩︎
Twitter. Twitter’s Recommendation Algorithm. blog.twitter.com, March 2023. Archived at perma.cc/L5GT-229T ↩︎
Raffi Krikorian. New Tweets per second record, and how! blog.twitter.com, August 2013. Archived at perma.cc/6JZN-XJYN ↩︎
Jaz Volpert. When Imperfect Systems are Good, Actually: Bluesky’s Lossy Timelines. jazco.dev, February 2025. Archived at perma.cc/2PVE-L2MX ↩︎
Samuel Axon. 3% of Twitter’s Servers Dedicated to Justin Bieber. mashable.com, September 2010. Archived at perma.cc/F35N-CGVX ↩︎
Nathan Bronson, Abutalib Aghayev, Aleksey Charapko, and Timothy Zhu. Metastable Failures in Distributed Systems. At Workshop on Hot Topics in Operating Systems (HotOS), May 2021. doi:10.1145/3458336.3465286 ↩︎
Marc Brooker. Metastability and Distributed Systems. brooker.co.za, May 2021. Archived at perma.cc/7FGJ-7XRK ↩︎
Marc Brooker. Exponential Backoff And Jitter. aws.amazon.com, March 2015. Archived at perma.cc/R6MS-AZKH ↩︎
Marc Brooker. What is Backoff For? brooker.co.za, August 2022. Archived at perma.cc/PW9N-55Q5 ↩︎
Michael T. Nygard. Release It!, 2nd Edition. Pragmatic Bookshelf, January 2018. ISBN: 9781680502398 ↩︎
Frank Chen. Slowing Down to Speed Up - Circuit Breakers for Slack’s CI/CD. slack.engineering, August 2022. Archived at perma.cc/5FGS-ZPH3 ↩︎
Marc Brooker. Fixing retries with token buckets and circuit breakers. brooker.co.za, February 2022. Archived at perma.cc/MD6N-GW26 ↩︎
David Yanacek. Using load shedding to avoid overload. Amazon Builders’ Library, aws.amazon.com. Archived at perma.cc/9SAW-68MP ↩︎
Matthew Sackman. Pushing Back. wellquite.org, May 2016. Archived at perma.cc/3KCZ-RUFY ↩︎
Dmitry Kopytkov and Patrick Lee. Meet Bandaid, the Dropbox service proxy. dropbox.tech, March 2018. Archived at perma.cc/KUU6-YG4S ↩︎
Haryadi S. Gunawi et al. Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems. At 16th USENIX Conference on File and Storage Technologies, February 2018. ↩︎
Marc Brooker. Is the Mean Really Useless? brooker.co.za, December 2017. Archived at perma.cc/U5AE-CVEM ↩︎
Giuseppe DeCandia et al. Dynamo: Amazon’s Highly Available Key-Value Store. At 21st ACM Symposium on Operating Systems Principles (SOSP), October 2007. doi:10.1145/1294261.1294281 ↩︎
Kathryn Whitenton. The Need for Speed, 23 Years Later. nngroup.com, May 2020. Archived at perma.cc/C4ER-LZYA ↩︎
Greg Linden. Marissa Mayer at Web 2.0. glinden.blogspot.com, November 2005. Archived at perma.cc/V7EA-3VXB ↩︎
Jake Brutlag. Speed Matters for Google Web Search. services.google.com, June 2009. Archived at perma.cc/BK7R-X7M2 ↩︎
Eric Schurman and Jake Brutlag. Performance Related Changes and their User Impact. Talk at Velocity 2009. ↩︎
Akamai Technologies, Inc. The State of Online Retail Performance. akamai.com, April 2017. Archived at perma.cc/UEK2-HYCS ↩︎
Xiao Bai et al. Understanding and Leveraging the Impact of Response Latency on User Behaviour in Web Search. ACM Transactions on Information Systems, volume 36, issue 2, article 21, April 2018. doi:10.1145/3106372 ↩︎
Jeffrey Dean and Luiz Andre Barroso. The Tail at Scale. Communications of the ACM, volume 56, issue 2, pages 74-80, February 2013. doi:10.1145/2408776.2408794 ↩︎
Alex Hidalgo. Implementing Service Level Objectives. O’Reilly Media, September 2020. ISBN: 1492076813 ↩︎
Jeffrey C. Mogul and John Wilkes. Nines are Not Enough: Meaningful Metrics for Clouds. At 17th Workshop on Hot Topics in Operating Systems (HotOS), May 2019. doi:10.1145/3317550.3321432 ↩︎
Tamás Hauer et al. Meaningful Availability. At 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI), February 2020. ↩︎
Ted Dunning. The t-digest: Efficient estimates of distributions. Software Impacts, volume 7, article 100049, February 2021. doi:10.1016/j.simpa.2020.100049 ↩︎
David Kohn. How percentile approximation works (and why it’s more useful than averages). timescale.com, September 2021. Archived at perma.cc/3PDP-NR8B ↩︎
Heinrich Hartmann and Theo Schlossnagle. Circllhist - A Log-Linear Histogram Data Structure for IT Infrastructure Monitoring. arxiv.org, January 2020. ↩︎
Charles Masson, Jee E. Rim, and Homin K. Lee. DDSketch: A Fast and Fully-Mergeable Quantile Sketch with Relative-Error Guarantees. Proceedings of the VLDB Endowment, volume 12, issue 12, pages 2195-2205, August 2019. doi:10.14778/3352063.3352135 ↩︎
Baron Schwartz. Why Percentiles Don’t Work the Way You Think. solarwinds.com, November 2016. Archived at perma.cc/469T-6UGB ↩︎
Walter L. Heimerdinger and Charles B. Weinstock. A Conceptual Framework for System Fault Tolerance. Technical Report CMU/SEI-92-TR-033, Software Engineering Institute, Carnegie Mellon University, October 1992. Archived at perma.cc/GD2V-DMJW ↩︎
Felix C. Gartner. Fundamentals of fault-tolerant distributed computing in asynchronous environments. ACM Computing Surveys, volume 31, issue 1, pages 1-26, March 1999. doi:10.1145/311531.311532 ↩︎
Algirdas Avizienis et al. Basic Concepts and Taxonomy of Dependable and Secure Computing. IEEE Transactions on Dependable and Secure Computing, volume 1, issue 1, January 2004. doi:10.1109/TDSC.2004.2 ↩︎
Ding Yuan et al. Simple Testing Can Prevent Most Critical Failures. At 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI), October 2014. ↩︎ ↩︎
Casey Rosenthal and Nora Jones. Chaos Engineering. O’Reilly Media, April 2020. ISBN: 9781492043867 ↩︎
Eduardo Pinheiro, Wolf-Dietrich Weber, and Luiz Andre Barroso. Failure Trends in a Large Disk Drive Population. At 5th USENIX Conference on File and Storage Technologies (FAST), February 2007. ↩︎
Bianca Schroeder and Garth A. Gibson. Disk failures in the real world. At 5th USENIX Conference on File and Storage Technologies (FAST), February 2007. ↩︎ ↩︎
Andy Klein. Backblaze Drive Stats for Q2 2021. backblaze.com, August 2021. Archived at perma.cc/2943-UD5E ↩︎
Iyswarya Narayanan et al. SSD Failures in Datacenters: What? When? and Why? At 9th ACM International on Systems and Storage Conference (SYSTOR), June 2016. doi:10.1145/2928275.2928278 ↩︎
Alibaba Cloud Storage Team. Storage System Design Analysis: Factors Affecting NVMe SSD Performance (1). alibabacloud.com, January 2019. ↩︎
Bianca Schroeder, Raghav Lagisetty, and Arif Merchant. Flash Reliability in Production: The Expected and the Unexpected. At 14th USENIX Conference on File and Storage Technologies (FAST), February 2016. ↩︎
Jacob Alter et al. SSD failures in the field: symptoms, causes, and prediction models. At International Conference for High Performance Computing, Networking, Storage and Analysis (SC), November 2019. doi:10.1145/3295500.3356172 ↩︎
Daniel Ford et al. Availability in Globally Distributed Storage Systems. At 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI), October 2010. ↩︎ ↩︎
Kashi Venkatesh Vishwanath and Nachiappan Nagappan. Characterizing Cloud Computing Hardware Reliability. At 1st ACM Symposium on Cloud Computing (SoCC), June 2010. doi:10.1145/1807128.1807161 ↩︎
Peter H. Hochschild et al. Cores that don’t count. At Workshop on Hot Topics in Operating Systems (HotOS), June 2021. doi:10.1145/3458336.3465297 ↩︎
Harish Dattatraya Dixit et al. Silent Data Corruptions at Scale. arXiv:2102.11245, February 2021. ↩︎
Diogo Behrens et al. Scalable Error Isolation for Distributed Systems. At 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI), May 2015. ↩︎
Bianca Schroeder, Eduardo Pinheiro, and Wolf-Dietrich Weber. DRAM Errors in the Wild: A Large-Scale Field Study. At 11th International Joint Conference on Measurement and Modeling of Computer Systems (SIGMETRICS), June 2009. doi:10.1145/1555349.1555372 ↩︎
Yoongu Kim et al. Flipping Bits in Memory Without Accessing Them. At 41st Annual International Symposium on Computer Architecture (ISCA), June 2014. doi:10.5555/2665671.2665726 ↩︎
Tim Bray. Worst Case. tbray.org, October 2021. Archived at perma.cc/4QQM-RTHN ↩︎
Sangeetha Abdu Jyothi. Solar Superstorms: Planning for an Internet Apocalypse. At ACM SIGCOMM Conference, August 2021. doi:10.1145/3452296.3472916 ↩︎
Adrian Cockcroft. Failure Modes and Continuous Resilience. adrianco.medium.com, November 2019. Archived at perma.cc/7SYS-BVJP ↩︎
Shujie Han et al. An In-Depth Study of Correlated Failures in Production SSD-Based Data Centers. At 19th USENIX Conference on File and Storage Technologies (FAST), February 2021. ↩︎
Edmund B. Nightingale, John R. Douceur, and Vince Orgovan. Cycles, Cells and Platters: An Empirical Analysis of Hardware Failures on a Million Consumer PCs. At 6th European Conference on Computer Systems (EuroSys), April 2011. doi:10.1145/1966445.1966477 ↩︎
Haryadi S. Gunawi et al. What Bugs Live in the Cloud? At 5th ACM Symposium on Cloud Computing (SoCC), November 2014. doi:10.1145/2670979.2670986 ↩︎
Jay Kreps. Getting Real About Distributed System Reliability. blog.empathybox.com, March 2012. Archived at perma.cc/9B5Q-AEBW ↩︎ ↩︎
Nelson Minar. Leap Second Crashes Half the Internet. somebits.com, July 2012. Archived at perma.cc/2WB8-D6EU ↩︎
Hewlett Packard Enterprise. Support Alerts - Customer Bulletin a00092491en_us. support.hpe.com, November 2019. Archived at perma.cc/S5F6-7ZAC ↩︎
Lorin Hochstein. awesome limits. github.com, November 2020. Archived at perma.cc/3R5M-E5Q4 ↩︎
Caitie McCaffrey. Clients Are Jerks: AKA How Halo 4 DoSed the Services at Launch. caitiem.com, June 2015. Archived at perma.cc/MXX4-W373 ↩︎
Lilia Tang et al. Fail through the Cracks: Cross-System Interaction Failures in Modern Cloud Systems. At 18th European Conference on Computer Systems (EuroSys), May 2023. doi:10.1145/3552326.3587448 ↩︎
Mike Ulrich. Addressing Cascading Failures. In Site Reliability Engineering. O’Reilly Media, 2016. ↩︎
Harri Fassbender. Cascading failures in large-scale distributed systems. blog.mi.hdm-stuttgart.de, March 2022. Archived at perma.cc/K7VY-YJRX ↩︎
Richard I. Cook. How Complex Systems Fail. Cognitive Technologies Laboratory, April 2000. Archived at perma.cc/RDS6-2YVA ↩︎
David D. Woods. STELLA: Report from the SNAFUcatchers Workshop on Coping With Complexity. snafucatchers.github.io, March 2017. ↩︎ ↩︎
David Oppenheimer, Archana Ganapathi, and David A. Patterson. Why Do Internet Services Fail, and What Can Be Done About It? At 4th USENIX Symposium on Internet Technologies and Systems (USITS), March 2003. ↩︎
Sidney Dekker. The Field Guide to Understanding ‘Human Error’, 3rd Edition. CRC Press, November 2017. ISBN: 9781472439055 ↩︎ ↩︎
Sidney Dekker. Drift into Failure. CRC Press, 2011. ISBN: 9781315257396 ↩︎
John Allspaw. Blameless PostMortems and a Just Culture. etsy.com, May 2012. Archived at perma.cc/YMJ7-NTAP ↩︎
Itzy Sabo. Uptime Guarantees - A Pragmatic Perspective. world.hey.com, March 2023. Archived at perma.cc/F7TU-78JB ↩︎
Michael Jurewitz. The Human Impact of Bugs. jury.me, March 2013. Archived at perma.cc/5KQ4-VDYL ↩︎
Mark Halper. How Software Bugs led to ‘One of the Greatest Miscarriages of Justice’ in British History. Communications of the ACM, January 2025. doi:10.1145/3703779 ↩︎
Nicholas Bohm et al. The legal rule that computers are presumed to be operating correctly. Briefing note, benthamsgaze.org, June 2022. Archived at perma.cc/WQ6X-TMW4 ↩︎
Dan McKinley. Choose Boring Technology. mcfunley.com, March 2015. Archived at perma.cc/7QW7-J4YP ↩︎
Andy Warfield. Building and operating a pretty big storage system called S3. allthingsdistributed.com, July 2023. Archived at perma.cc/7LPK-TP7V ↩︎
Marc Brooker. Surprising Scalability of Multitenancy. brooker.co.za, March 2023. Archived at perma.cc/ZZD9-VV8T ↩︎
Ben Stopford. Shared Nothing vs. Shared Disk Architectures: An Independent View. benstopford.com, November 2009. Archived at perma.cc/7BXH-EDUR ↩︎
Michael Stonebraker. The Case for Shared Nothing. IEEE Database Engineering Bulletin, volume 9, issue 1, pages 4-9, March 1986. ↩︎
Panagiotis Antonopoulos et al. Socrates: The New SQL Server in the Cloud. At ACM International Conference on Management of Data (SIGMOD), pages 1743-1756, June 2019. doi:10.1145/3299869.3314047 ↩︎
Sam Newman. Building Microservices, second edition. O’Reilly Media, 2021. ISBN: 9781492034025 ↩︎
Nathan Ensmenger. When Good Software Goes Bad. At The Maintainers Conference, April 2016. Archived at perma.cc/ZXT4-HGZB ↩︎
Robert L. Glass. Facts and Fallacies of Software Engineering. Addison-Wesley Professional, October 2002. ISBN: 9780321117427 ↩︎
Marianne Bellotti. Kill It with Fire. No Starch Press, April 2021. ISBN: 9781718501188 ↩︎
Lisanne Bainbridge. Ironies of automation. Automatica, volume 19, issue 6, pages 775-779, November 1983. doi:10.1016/0005-1098(83)90046-8 ↩︎
James Hamilton. On Designing and Deploying Internet-Scale Services. At 21st Large Installation System Administration Conference (LISA), November 2007. ↩︎
Dotan Horovits. Open Source for Better Observability. horovits.medium.com, October 2021. Archived at perma.cc/R2HD-U2ZT ↩︎
Brian Foote and Joseph Yoder. Big Ball of Mud. At 4th Conference on Pattern Languages of Programs (PLoP), September 1997. Archived at perma.cc/4GUP-2PBV ↩︎
Marc Brooker. What is a simple system? brooker.co.za, May 2022. Archived at perma.cc/U72T-BFVE ↩︎
Frederick P. Brooks. No Silver Bullet - Essence and Accident in Software Engineering. In The Mythical Man-Month, Anniversary edition, Addison-Wesley, 1995. ↩︎
Dan Luu. Against essential and accidental complexity. danluu.com, December 2020. Archived at perma.cc/H5ES-69KC ↩︎
Erich Gamma et al. Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley Professional, October 1994. ISBN: 9780201633610 ↩︎
Eric Evans. Domain-Driven Design: Tackling Complexity in the Heart of Software. Addison-Wesley Professional, August 2003. ISBN: 9780321125217 ↩︎
Hongyu Pei Breivold, Ivica Crnkovic, and Peter J. Eriksson. Analyzing Software Evolvability. at 32nd Annual IEEE International Computer Software and Applications Conference (COMPSAC), July 2008. doi:10.1109/COMPSAC.2008.50 ↩︎
Maximilian Schireson. Why I Turned Down $500 Million. maxschireson.com, September 2023. Archived at perma.cc/ZN5J-AZ6L ↩︎