11. Xử Lý Hàng Loạt
Một hệ thống không thể thành công nếu chịu ảnh hưởng quá lớn từ một cá nhân duy nhất. Một khi thiết kế ban đầu đã hoàn chỉnh và đủ vững chắc, bài kiểm tra thực sự mới bắt đầu khi những người có nhiều quan điểm khác nhau tiến hành các thí nghiệm của riêng họ.
Donald Knuth
A NOTE FOR EARLY RELEASE READERS
With Early Release ebooks, you get books in their earliest form—the author’s raw and unedited content as they write—so you can take advantage of these technologies long before the official release of these titles.
This will be the 11th chapter of the final book. The GitHub repo for this book is https://github.com/ept/ddia2-feedback.
If you’d like to be actively involved in reviewing and commenting on this draft, please reach out on GitHub.
Phần lớn cuốn sách này đến nay đã nói về yêu cầu (request) và truy vấn (query), cùng với các phản hồi (response) hoặc kết quả tương ứng. Phong cách xử lý dữ liệu này được mặc định trong nhiều hệ thống dữ liệu hiện đại: bạn hỏi một điều gì đó, hoặc gửi một lệnh, và hệ thống cố gắng đưa ra câu trả lời càng nhanh càng tốt.
Trình duyệt web yêu cầu một trang, một dịch vụ gọi API từ xa, cơ sở dữ liệu, bộ nhớ đệm, chỉ mục tìm kiếm, và nhiều hệ thống khác đều hoạt động theo cách này. Chúng ta gọi những hệ thống này là hệ thống trực tuyến (online system). Thời gian phản hồi thường là thước đo hiệu năng chính của chúng, và chúng thường đòi hỏi khả năng chịu lỗi để đảm bảo tính sẵn sàng cao.
Tuy nhiên, đôi khi bạn cần chạy một phép tính lớn hơn hoặc xử lý lượng dữ liệu nhiều hơn những gì có thể thực hiện trong một yêu cầu tương tác. Có thể bạn cần huấn luyện một mô hình AI, hoặc chuyển đổi nhiều dữ liệu từ dạng này sang dạng khác, hoặc tính toán phân tích trên một tập dữ liệu rất lớn. Chúng ta gọi các tác vụ này là công việc xử lý hàng loạt (batch processing), hay đôi khi là hệ thống ngoại tuyến (offline system).
Một công việc xử lý hàng loạt nhận một số dữ liệu đầu vào (chỉ đọc), và tạo ra một số dữ liệu đầu ra (được tạo mới hoàn toàn mỗi lần công việc chạy). Nó thường không thay đổi dữ liệu theo cách mà một giao dịch đọc/ghi thực hiện. Do đó, đầu ra được dẫn xuất (derived) từ đầu vào (như đã thảo luận trong “Hệ Thống Bản Ghi và Dữ Liệu Dẫn Xuất”): nếu bạn không hài lòng với đầu ra, bạn có thể xóa nó đi, điều chỉnh logic công việc, và chạy lại. Bằng cách coi đầu vào là bất biến và tránh các tác dụng phụ (chẳng hạn như ghi vào cơ sở dữ liệu bên ngoài), các công việc hàng loạt không chỉ đạt được hiệu năng tốt mà còn có những lợi ích khác:
Nếu bạn đưa ra một lỗi trong mã và đầu ra bị sai hoặc bị hỏng, bạn chỉ cần quay lại phiên bản trước của mã và chạy lại công việc, và đầu ra sẽ lại đúng. Hoặc, đơn giản hơn, bạn có thể giữ đầu ra cũ trong một thư mục khác và chỉ cần chuyển lại về nó. Hầu hết các kho lưu trữ đối tượng (object store) và định dạng bảng mở (open table format) (xem “Kho Dữ Liệu Đám Mây”) đều hỗ trợ tính năng này, được gọi là du hành thời gian (time travel). Hầu hết các cơ sở dữ liệu với giao dịch đọc-ghi không có thuộc tính này: nếu bạn triển khai mã có lỗi ghi dữ liệu xấu vào cơ sở dữ liệu, thì việc quay lại mã sẽ không sửa được dữ liệu trong cơ sở dữ liệu. Ý tưởng có thể phục hồi từ mã lỗi được gọi là khả năng chịu lỗi của con người (human fault tolerance) 1.
Hệ quả của sự dễ dàng quay lui này là việc phát triển tính năng có thể tiến triển nhanh hơn so với môi trường mà lỗi lầm có thể gây ra thiệt hại không thể đảo ngược. Nguyên tắc giảm thiểu tính không thể đảo ngược (minimizing irreversibility) này có lợi cho phát triển phần mềm Agile 2.
Cùng một tập hợp tệp có thể được sử dụng làm đầu vào cho nhiều công việc khác nhau, bao gồm các công việc giám sát tính toán các chỉ số và đánh giá xem đầu ra của một công việc có các đặc điểm mong đợi hay không (ví dụ: bằng cách so sánh với đầu ra của lần chạy trước và đo lường sự khác biệt).
Các khung xử lý hàng loạt (batch processing framework) sử dụng hiệu quả tài nguyên tính toán. Mặc dù có thể xử lý dữ liệu hàng loạt bằng cách sử dụng các hệ thống dữ liệu trực tuyến như cơ sở dữ liệu OLTP và máy chủ ứng dụng, nhưng làm vậy có thể tốn kém hơn nhiều về tài nguyên cần thiết.
Xử lý dữ liệu hàng loạt cũng đặt ra những thách thức. Với hầu hết các khung, đầu ra chỉ có thể được xử lý bởi các công việc khác sau khi toàn bộ công việc kết thúc. Xử lý hàng loạt cũng có thể kém hiệu quả: bất kỳ thay đổi nào đối với dữ liệu đầu vào, dù chỉ một byte, đều có nghĩa là công việc hàng loạt phải xử lý lại toàn bộ tập dữ liệu đầu vào. Bất chấp những hạn chế này, xử lý hàng loạt đã chứng tỏ hữu ích trong nhiều trường hợp sử dụng, mà chúng ta sẽ xem lại trong “Các Trường Hợp Sử Dụng Hàng Loạt”.
Một công việc hàng loạt có thể mất nhiều thời gian để chạy: vài phút, vài giờ, hoặc thậm chí vài ngày. Các công việc có thể được lên lịch để chạy định kỳ (ví dụ: một lần mỗi ngày). Thước đo hiệu năng chính thường là thông lượng (throughput): lượng dữ liệu mà công việc có thể xử lý trong một đơn vị thời gian. Một số hệ thống hàng loạt xử lý lỗi bằng cách đơn giản là hủy bỏ và khởi động lại toàn bộ công việc, trong khi những hệ thống khác có khả năng chịu lỗi để công việc có thể hoàn thành thành công dù một số node bị lỗi.
Note
Một giải pháp thay thế cho xử lý hàng loạt là xử lý luồng (stream processing), trong đó công việc không kết thúc chạy khi đã xử lý xong đầu vào, mà thay vào đó tiếp tục theo dõi đầu vào và xử lý các thay đổi trong đầu vào ngay sau khi chúng xảy ra. Chúng ta sẽ chuyển sang xử lý luồng trong Chương 12.
Ranh giới giữa các hệ thống trực tuyến và hàng loạt không phải lúc nào cũng rõ ràng: một truy vấn cơ sở dữ liệu chạy lâu trông khá giống một quy trình hàng loạt. Nhưng xử lý hàng loạt cũng có một số đặc điểm cụ thể khiến nó trở thành một khối xây dựng hữu ích để xây dựng các ứng dụng đáng tin cậy, có khả năng mở rộng và dễ bảo trì. Ví dụ, nó thường đóng vai trò trong tích hợp dữ liệu (data integration), tức là kết hợp nhiều hệ thống dữ liệu để đạt được những điều mà một hệ thống đơn lẻ không thể làm. ETL, như đã thảo luận trong “Kho Dữ Liệu”, là một ví dụ về điều này.
Xử lý hàng loạt hiện đại bị ảnh hưởng nhiều bởi MapReduce, một thuật toán xử lý hàng loạt được Google công bố năm 2004 3, và sau đó được triển khai trong nhiều hệ thống dữ liệu mã nguồn mở, bao gồm Hadoop, CouchDB và MongoDB. MapReduce là một mô hình lập trình khá cấp thấp, và kém tinh vi hơn các engine thực thi truy vấn song song tìm thấy, ví dụ, trong các kho dữ liệu 4, 5. Khi mới xuất hiện, MapReduce là một bước tiến về quy mô xử lý có thể đạt được trên phần cứng thông thường, nhưng hiện tại nó phần lớn đã lỗi thời và không còn được sử dụng tại Google 6, 7.
Xử lý hàng loạt ngày nay thường được thực hiện bằng các khung như Spark hoặc Flink, hoặc các engine truy vấn kho dữ liệu. Giống như MapReduce, chúng phụ thuộc nhiều vào phân mảnh (sharding) (xem Chương 7) và thực thi song song, nhưng chúng có các chiến lược bộ nhớ đệm và thực thi tinh vi hơn nhiều. Khi các hệ thống này trưởng thành, các vấn đề vận hành phần lớn đã được giải quyết, vì vậy sự tập trung đã chuyển sang khả năng sử dụng. Các mô hình xử lý mới như API luồng dữ liệu (dataflow API), ngôn ngữ truy vấn, và API DataFrame hiện được hỗ trợ rộng rãi. Điều phối công việc và quy trình làm việc (workflow orchestration) cũng đã trưởng thành. Các bộ lên lịch quy trình làm việc tập trung vào Hadoop như Oozie và Azkaban đã được thay thế bằng các giải pháp tổng quát hơn như Airflow, Dagster và Prefect, hỗ trợ nhiều khung xử lý hàng loạt và kho dữ liệu đám mây.
Điện toán đám mây đã trở nên phổ biến. Các tầng lưu trữ hàng loạt đang chuyển từ các hệ thống tệp phân tán (Distributed File System, DFS) như HDFS, GlusterFS và CephFS sang các hệ thống lưu trữ đối tượng (object storage) như S3. Các kho dữ liệu đám mây có thể mở rộng như BigQuery và Snowflake đang làm mờ ranh giới giữa kho dữ liệu và xử lý hàng loạt.
Để xây dựng trực giác về xử lý hàng loạt là gì, chúng ta sẽ bắt đầu chương này bằng một ví dụ sử dụng các công cụ Unix tiêu chuẩn trên một máy đơn. Sau đó, chúng ta sẽ tìm hiểu cách có thể mở rộng xử lý dữ liệu ra nhiều máy trong một hệ thống phân tán. Chúng ta sẽ thấy rằng, giống như một hệ điều hành, các khung xử lý hàng loạt phân tán có một bộ lên lịch và một hệ thống tệp. Chúng ta sẽ khám phá các mô hình xử lý khác nhau mà chúng ta dùng để viết công việc hàng loạt. Cuối cùng, chúng ta thảo luận về các trường hợp sử dụng hàng loạt phổ biến.
Xử Lý Hàng Loạt với Công Cụ Unix
Giả sử bạn có một máy chủ web ghi thêm một dòng vào tệp nhật ký (log file) mỗi khi nó phục vụ một yêu cầu. Ví dụ, sử dụng định dạng nhật ký truy cập mặc định của nginx, một dòng nhật ký có thể trông như thế này:
216.58.210.78 - - [27/Jun/2025:17:55:11 +0000] "GET /css/typography.css HTTP/1.1"
200 3377 "https://martin.kleppmann.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36"
(Đó thực ra là một dòng; nó chỉ được ngắt thành nhiều dòng ở đây để dễ đọc hơn.) Có rất nhiều thông tin trong dòng đó. Để giải thích nó, bạn cần xem định nghĩa của định dạng nhật ký, như sau:
$remote_addr - $remote_user [$time_local] "$request"
$status $body_bytes_sent "$http_referer" "$http_user_agent"
Vì vậy, dòng nhật ký này cho biết rằng vào ngày 27 tháng 6 năm 2025, lúc 17:55:11 UTC, máy chủ đã
nhận được yêu cầu cho tệp /css/typography.css từ địa chỉ IP client 216.58.210.78. Người dùng
không được xác thực, vì vậy $remote_user được đặt thành dấu gạch ngang (-). Trạng thái phản
hồi là 200 (tức là yêu cầu thành công), và phản hồi có kích thước 3.377 byte. Trình duyệt web là
Chrome 137, và nó tải tệp vì tệp được tham chiếu trong trang tại URL
https://martin.kleppmann.com/.
Mặc dù việc phân tích nhật ký có vẻ giả tạo, nhưng thực ra đây là một phần quan trọng của nhiều công ty công nghệ hiện đại, và được sử dụng cho mọi thứ từ các pipeline quảng cáo đến xử lý thanh toán. Thực vậy, đây là động lực thúc đẩy sự áp dụng nhanh chóng của MapReduce và phong trào “dữ liệu lớn” (big data).
Phân Tích Nhật Ký Đơn Giản
Nhiều công cụ có thể lấy các tệp nhật ký này và tạo ra các báo cáo khá đẹp về lưu lượng truy cập trang web của bạn, nhưng để thực hành, hãy tự xây dựng một công cụ, sử dụng các công cụ Unix cơ bản. Ví dụ, giả sử bạn muốn tìm năm trang phổ biến nhất trên trang web của bạn. Bạn có thể làm điều này trong Unix shell như sau:
cat /var/log/nginx/access.log | #1
awk '{print $7}' | #2
sort | #3
uniq -c | #4
sort -r -n | #5
head -n 5 #6Đọc tệp nhật ký. (Nói nghiêm túc,
catkhông cần thiết ở đây, vì tệp đầu vào có thể được cung cấp trực tiếp như một đối số choawk. Tuy nhiên, pipeline tuyến tính trở nên rõ ràng hơn khi viết như thế này.)Tách mỗi dòng thành các trường theo khoảng trắng, và chỉ xuất trường thứ bảy từ mỗi dòng, đó chính là URL được yêu cầu. Trong dòng ví dụ của chúng ta, URL yêu cầu này là /css/typography.css.
Sắp xếp theo thứ tự bảng chữ cái (
sort) danh sách các URL được yêu cầu. Nếu một URL nào đó được yêu cầu n lần, thì sau khi sắp xếp, tệp chứa cùng một URL được lặp lại n lần liên tiếp.Lệnh
uniqlọc các dòng lặp lại trong đầu vào bằng cách kiểm tra xem hai dòng liền kề có giống nhau không. Tùy chọn-cyêu cầu nó cũng xuất ra một bộ đếm: với mỗi URL riêng biệt, nó báo cáo URL đó xuất hiện bao nhiêu lần trong đầu vào.Lệnh
sortthứ hai sắp xếp theo số (-n) ở đầu mỗi dòng, đó là số lần URL được yêu cầu. Sau đó nó trả về kết quả theo thứ tự ngược lại (-r), tức là với số lớn nhất trước.Cuối cùng,
headchỉ xuất ra năm dòng đầu tiên (-n 5) của đầu vào, và bỏ qua phần còn lại.
Đầu ra của chuỗi lệnh đó trông giống như thế này:
4189 /favicon.ico
3631 /2016/02/08/how-to-do-distributed-locking.html
2124 /2020/11/18/distributed-systems-and-elliptic-curves.html
1369 /
915 /css/typography.css
Mặc dù dòng lệnh trên có thể trông hơi khó hiểu nếu bạn chưa quen với công cụ Unix, nhưng nó cực
kỳ mạnh mẽ. Nó sẽ xử lý hàng gigabyte tệp nhật ký chỉ trong vài giây, và bạn có thể dễ dàng sửa
đổi phân tích để phù hợp với nhu cầu của mình. Ví dụ, nếu bạn muốn bỏ qua các tệp CSS khỏi báo
cáo, hãy thay đổi đối số awk thành '$7 !~ /\.css$/ {print $7}'. Nếu bạn muốn đếm các địa chỉ
IP client hàng đầu thay vì các trang hàng đầu, hãy thay đổi đối số awk thành '{print $1}'. Và
cứ thế tiếp tục.
Chúng ta không có đủ chỗ trong cuốn sách này để khám phá chi tiết các công cụ Unix, nhưng chúng
rất đáng để học. Đáng ngạc nhiên là nhiều phân tích dữ liệu có thể được thực hiện trong vài phút
bằng cách sử dụng một số kết hợp của awk, sed, grep, sort, uniq, và xargs, và chúng
hoạt động đáng ngạc nhiên tốt 8.
Chuỗi Lệnh So Với Chương Trình Tùy Chỉnh
Thay vì chuỗi lệnh Unix, bạn có thể viết một chương trình đơn giản để làm điều tương tự. Ví dụ, trong Python, nó có thể trông như thế này:
from collections import defaultdict
counts = defaultdict(int) #1
with open('/var/log/nginx/access.log', 'r') as file:
for line in file:
url = line.split()[6] #2
counts[url] += 1 #3
top5 = sorted(((count, url) for url, count in counts.items()), reverse=True)[:5] #4
for count, url in top5: #5
print(f"{count} {url}")countslà một bảng băm (hash table) giữ bộ đếm cho số lần chúng ta đã thấy mỗi URL. Bộ đếm mặc định là không.Từ mỗi dòng nhật ký, chúng ta lấy URL là trường thứ bảy được phân tách bằng khoảng trắng (chỉ số mảng là 6 vì mảng của Python được đánh chỉ số từ 0).
Tăng bộ đếm cho URL trong dòng nhật ký hiện tại.
Sắp xếp nội dung bảng băm theo giá trị bộ đếm (giảm dần), và lấy năm mục hàng đầu.
In ra năm mục hàng đầu đó.
Chương trình này không ngắn gọn như chuỗi pipe Unix, nhưng nó khá dễ đọc, và lựa chọn nào bạn thích một phần là vấn đề sở thích. Tuy nhiên, ngoài các khác biệt cú pháp bề ngoài giữa hai cách, có một sự khác biệt lớn trong luồng thực thi, điều này trở nên rõ ràng nếu bạn chạy phân tích này trên một tệp lớn.
Sắp Xếp So Với Tổng Hợp Trong Bộ Nhớ
Script Python giữ một bảng băm trong bộ nhớ (in-memory hash table) của các URL, trong đó mỗi URL được ánh xạ tới số lần nó được nhìn thấy. Ví dụ pipeline Unix không có bảng băm như vậy, mà thay vào đó dựa vào việc sắp xếp một danh sách các URL, trong đó nhiều lần xuất hiện của cùng một URL đơn giản là được lặp lại.
Cách tiếp cận nào tốt hơn? Điều đó phụ thuộc vào số lượng URL khác nhau bạn có. Đối với hầu hết các trang web vừa và nhỏ, bạn có thể đặt tất cả các URL riêng biệt, và một bộ đếm cho mỗi URL, vào (khoảng) 1 GB bộ nhớ. Trong ví dụ này, tập làm việc (working set) của công việc (lượng bộ nhớ mà công việc cần truy cập ngẫu nhiên) chỉ phụ thuộc vào số lượng URL riêng biệt: nếu có một triệu mục nhật ký cho một URL duy nhất, không gian cần thiết trong bảng băm vẫn chỉ là một URL cộng với kích thước của bộ đếm. Nếu tập làm việc này đủ nhỏ, một bảng băm trong bộ nhớ hoạt động tốt, ngay cả trên máy tính xách tay.
Mặt khác, nếu tập làm việc của công việc lớn hơn bộ nhớ khả dụng, cách tiếp cận sắp xếp có lợi thế là có thể sử dụng đĩa hiệu quả. Đó là cùng nguyên tắc chúng ta đã thảo luận trong “Lưu Trữ Có Cấu Trúc Nhật Ký”: các khối dữ liệu có thể được sắp xếp trong bộ nhớ và ghi ra đĩa dưới dạng các tệp phân đoạn (segment file), và sau đó nhiều phân đoạn đã sắp xếp có thể được hợp nhất thành một tệp đã sắp xếp lớn hơn. Mergesort có các mẫu truy cập tuần tự hoạt động tốt trên đĩa (xem “Ghi Tuần Tự So Với Ghi Ngẫu Nhiên trên SSD”).
Tiện ích sort trong GNU Coreutils (Linux) tự động xử lý các tập dữ liệu lớn hơn bộ nhớ bằng cách
tràn ra đĩa, và tự động song song hóa việc sắp xếp trên nhiều lõi CPU 9. Điều này có nghĩa là
chuỗi lệnh Unix đơn giản mà chúng ta thấy trước đó dễ dàng mở rộng sang các tập dữ liệu lớn, mà
không hết bộ nhớ. Điểm nghẽn có thể là tốc độ mà tệp đầu vào có thể được đọc từ đĩa.
Một hạn chế của công cụ Unix là chúng chỉ chạy trên một máy duy nhất. Các tập dữ liệu quá lớn để vừa trong bộ nhớ hoặc đĩa cục bộ đặt ra một vấn đề, và đó là nơi các khung xử lý hàng loạt phân tán (distributed batch processing framework) xuất hiện.
Xử Lý Hàng Loạt trong Hệ Thống Phân Tán
Máy chạy ví dụ công cụ Unix của chúng ta có một số thành phần cùng làm việc để xử lý dữ liệu nhật ký:
Các thiết bị lưu trữ được truy cập thông qua giao diện hệ thống tệp của hệ điều hành.
Một bộ lên lịch (scheduler) xác định khi nào các tiến trình được chạy, và cách phân bổ tài nguyên CPU cho chúng.
Một chuỗi các chương trình Unix có
stdinvàstdoutđược kết nối với nhau qua các pipe.
Những thành phần tương tự này tồn tại trong các khung xử lý dữ liệu phân tán. Thực ra, bạn có thể nghĩ một khung xử lý phân tán như một hệ điều hành phân tán; chúng có hệ thống tệp, bộ lên lịch công việc, và các chương trình gửi dữ liệu cho nhau qua hệ thống tệp hoặc các kênh giao tiếp khác.
Hệ Thống Tệp Phân Tán
Hệ thống tệp do hệ điều hành cung cấp được tạo thành từ một số tầng:
Ở cấp độ thấp nhất, trình điều khiển thiết bị khối (block device driver) giao tiếp trực tiếp với đĩa, và cho phép các tầng bên trên đọc và ghi các khối thô.
Phía trên tầng khối là một bộ nhớ đệm trang (page cache) giữ các khối được truy cập gần đây trong bộ nhớ để truy cập nhanh hơn.
API khối được bọc trong một tầng hệ thống tệp chia các tệp lớn thành các khối, và theo dõi siêu dữ liệu tệp như inode, thư mục và tệp. ext4 và XFS là hai triển khai phổ biến trên Linux, ví dụ.
Cuối cùng, hệ điều hành hiển thị các hệ thống tệp khác nhau cho các ứng dụng thông qua một API chung được gọi là hệ thống tệp ảo (virtual file system, VFS). VFS là thứ cho phép các ứng dụng đọc và ghi theo cách chuẩn bất kể hệ thống tệp bên dưới là gì.
Các hệ thống tệp phân tán hoạt động theo cách tương tự. Các tệp được chia thành các khối, được phân phối trên nhiều máy. Các khối DFS thường lớn hơn nhiều so với các khối cục bộ: HDFS (Hadoop Distributed File System) mặc định là 128MB, trong khi JuiceFS và nhiều kho lưu trữ đối tượng sử dụng các khối 4MB, lớn hơn nhiều so với 4096 byte của ext4. Các khối lớn hơn có nghĩa là ít siêu dữ liệu cần theo dõi hơn, điều này tạo ra sự khác biệt lớn trên các tập dữ liệu có kích thước petabyte. Các khối lớn hơn cũng giảm chi phí tìm kiếm đến một khối so với việc đọc nó.
Hầu hết các thiết bị lưu trữ vật lý không thể ghi các khối một phần, vì vậy hệ điều hành yêu cầu ghi phải sử dụng toàn bộ khối ngay cả khi dữ liệu không chiếm hết toàn bộ khối. Vì các hệ thống tệp phân tán có các khối lớn hơn và thường được triển khai trên hệ thống tệp của hệ điều hành, chúng không có yêu cầu này. Ví dụ, một tệp 900MB được lưu trữ với các khối 128MB sẽ có 7 khối sử dụng 128MB và 1 khối sử dụng 4MB.
Các khối DFS được đọc bằng cách thực hiện các yêu cầu mạng đến một máy trong cụm lưu trữ khối đó. Mỗi máy chạy một daemon, tiếp xúc với một API cho phép các tiến trình từ xa đọc và ghi các khối dưới dạng tệp trên hệ thống tệp cục bộ của nó. HDFS gọi các daemon này là DataNode, trong khi GlusterFS gọi chúng là tiến trình glusterfsd. Chúng ta sẽ gọi chúng là node dữ liệu (data node) trong cuốn sách này.
Các hệ thống tệp phân tán cũng triển khai tương đương phân tán của bộ nhớ đệm trang. Vì các khối DFS được lưu trữ dưới dạng tệp trên các node dữ liệu, việc đọc và ghi đi qua hệ điều hành của mỗi node dữ liệu, bao gồm một bộ nhớ đệm trang trong bộ nhớ. Điều này giữ các khối dữ liệu được đọc thường xuyên trong bộ nhớ trên các node dữ liệu. Một số hệ thống tệp phân tán cũng triển khai thêm các tầng bộ nhớ đệm như bộ nhớ đệm phía client và đĩa cục bộ được tìm thấy trong JuiceFS.
Các hệ thống tệp như ext4 và XFS theo dõi siêu dữ liệu lưu trữ bao gồm không gian trống, vị trí khối tệp, cấu trúc thư mục, cài đặt quyền, và nhiều hơn nữa. Các hệ thống tệp phân tán cũng cần một cách để theo dõi vị trí tệp trải rộng trên các máy, cài đặt quyền, và vân vân. Hadoop có một dịch vụ được gọi là NameNode, duy trì siêu dữ liệu cho cụm. 3FS của DeepSeek có một dịch vụ siêu dữ liệu duy trì dữ liệu của nó trong một kho khóa-giá trị như FoundationDB.
Phía trên hệ thống tệp là VFS. Một tương đương gần trong xử lý hàng loạt là giao thức của hệ thống tệp phân tán. Các hệ thống tệp phân tán phải tiếp xúc với một giao thức hoặc giao diện để các hệ thống xử lý hàng loạt có thể đọc và ghi tệp. Giao thức này hoạt động như một giao diện có thể thay thế: bất kỳ DFS nào cũng có thể được sử dụng miễn là nó triển khai giao thức. Ví dụ, API của Amazon S3 đã được nhiều hệ thống lưu trữ khác như MinIO, R2 của Cloudflare, Tigris, B2 của Backblaze, và nhiều hệ thống khác áp dụng rộng rãi. Các hệ thống xử lý hàng loạt có hỗ trợ S3 có thể sử dụng bất kỳ hệ thống lưu trữ nào trong số này.
Một số DFS triển khai hệ thống tệp tuân thủ POSIX xuất hiện với VFS của hệ điều hành như bất kỳ hệ thống tệp nào khác. Filesystem in Userspace (FUSE) hoặc giao thức Network File System (NFS) thường được sử dụng để tích hợp vào VFS. NFS có lẽ là giao thức hệ thống tệp phân tán được biết đến nhiều nhất. Giao thức này ban đầu được phát triển để cho phép nhiều client đọc và ghi dữ liệu trên một máy chủ duy nhất. Gần đây hơn, các hệ thống tệp như Elastic File System (EFS) của AWS và Archil cung cấp các triển khai hệ thống tệp phân tán tương thích NFS có khả năng mở rộng cao hơn nhiều. Các client NFS vẫn kết nối đến một điểm cuối, nhưng bên dưới, các hệ thống này giao tiếp với các dịch vụ siêu dữ liệu phân tán và các node dữ liệu để đọc và ghi dữ liệu.
DISTRIBUTED FILESYSTEMS AND NETWORK STORAGE
Distributed filesystems are based on the shared-nothing principle (see “Shared-Memory, Shared-Disk, and Shared-Nothing Architecture”), in contrast to the shared-disk approach of Network Attached Storage (NAS) and Storage Area Network (SAN) architectures. Shared-disk storage is implemented by a centralized storage appliance, often using custom hardware and special network infrastructure such as Fibre Channel. On the other hand, the shared-nothing approach requires no special hardware, only computers connected by a conventional datacenter network.
Nhiều hệ thống tệp phân tán được xây dựng trên phần cứng thông thường, vốn rẻ hơn nhưng có tỷ lệ lỗi cao hơn phần cứng cấp doanh nghiệp. Để chịu đựng lỗi máy và đĩa, các khối tệp được sao chép trên nhiều máy. Điều này cũng cho phép các bộ lên lịch phân phối khối lượng công việc đồng đều hơn vì họ có thể thực thi một tác vụ trên bất kỳ node nào chứa một bản sao của dữ liệu đầu vào của tác vụ. Sao chép có thể có nghĩa là đơn giản là nhiều bản sao của cùng một dữ liệu trên nhiều máy, như trong Chương 6, hoặc một lược đồ mã hóa xóa (erasure coding) như mã Reed-Solomon, cho phép khôi phục dữ liệu bị mất với chi phí lưu trữ thấp hơn sao chép đầy đủ 10, 11, 12. Các kỹ thuật này tương tự RAID, cung cấp dự phòng trên nhiều đĩa gắn vào cùng một máy; sự khác biệt là trong một hệ thống tệp phân tán, truy cập tệp và sao chép được thực hiện qua mạng trung tâm dữ liệu thông thường mà không cần phần cứng đặc biệt.
Kho Lưu Trữ Đối Tượng
Các dịch vụ lưu trữ đối tượng (object storage) như Amazon S3, Google Cloud Storage, Azure Blob Storage, và OpenStack Swift đã trở thành một giải pháp thay thế phổ biến cho các hệ thống tệp phân tán đối với các công việc xử lý hàng loạt. Thực ra, ranh giới giữa hai loại này có phần mờ nhạt. Như chúng ta đã thấy trong phần trước và “Cơ Sở Dữ Liệu Được Hỗ Trợ Bởi Lưu Trữ Đối Tượng”, các trình điều khiển Filesystem in Userspace (FUSE) cho phép người dùng xử lý các kho lưu trữ đối tượng như S3 như một hệ thống tệp. Một số triển khai DFS như JuiceFS và Ceph cung cấp cả API lưu trữ đối tượng và hệ thống tệp. Tuy nhiên, API, hiệu năng và đảm bảo tính nhất quán của chúng rất khác nhau. Phải cẩn thận khi áp dụng các hệ thống đó để đảm bảo chúng hoạt động như mong đợi, ngay cả khi chúng có vẻ triển khai các API cần thiết.
Mỗi đối tượng trong kho lưu trữ đối tượng có một URL như
s3://my-photo-bucket/2025/04/01/birthday.png. Phần host của URL (my-photo-bucket) mô tả bucket
nơi các đối tượng được lưu trữ, và phần tiếp theo là khóa (key) của đối tượng
(/2025/04/01/birthday.png trong ví dụ của chúng ta). Một bucket có tên duy nhất toàn cầu, và
khóa của mỗi đối tượng phải là duy nhất trong bucket của nó.
Các đối tượng được đọc bằng lệnh get và được ghi bằng lệnh put. Không giống như các tệp trên
hệ thống tệp, các đối tượng là bất biến sau khi được ghi. Để cập nhật một đối tượng, nó phải được
ghi lại hoàn toàn bằng lệnh put, tương tự như một kho khóa-giá trị (key-value store). Azure Blob
Storage và S3 Express One Zone hỗ trợ gắn thêm (append), nhưng hầu hết các kho khác thì không. Không
có API file handle với các hàm như fopen và fseek.
Các đối tượng có thể trông như thể chúng được tổ chức thành các thư mục, điều này có phần gây nhầm lẫn, vì Object store không có khái niệm thư mục. Cấu trúc đường dẫn chỉ là một quy ước, và các dấu gạch chéo là một phần trong khóa (key) của object. Quy ước này cho phép bạn thực hiện điều gì đó tương tự như liệt kê thư mục bằng cách yêu cầu danh sách các object có một tiền tố cụ thể. Tuy nhiên, việc liệt kê object theo tiền tố khác với liệt kê thư mục hệ thống tệp ở hai điểm:
Thao tác
listtheo tiền tố hoạt động giống như lệnhls -Rđệ quy trên hệ thống Unix: nó trả về tất cả các object bắt đầu bằng tiền tố đó, bao gồm cả object trong các đường dẫn con.Thư mục rỗng là không thể: nếu bạn xóa tất cả các object bên trong
s3://my-photo-bucket/2025/04/01, thì01sẽ không còn xuất hiện khi chúng ta gọilisttrêns3://my-photo-bucket/2025/04. Một thực hành phổ biến là tạo một object có kích thước bằng không để biểu diễn một thư mục rỗng (ví dụ: tạo một tệp rỗngs3://my-photo-bucket/2025/04/01để giữ nó tồn tại khi tất cả các object con bị xóa).
Các DFS (Distributed File System, hệ thống tệp phân tán) thường hỗ trợ nhiều thao tác hệ thống tệp phổ biến như hard link (liên kết cứng), symbolic link (liên kết tượng trưng), file locking (khóa tệp), và atomic rename (đổi tên nguyên tử). Những tính năng này không có trong object store. Link và lock thường không được hỗ trợ, còn việc đổi tên là không nguyên tử: nó được thực hiện bằng cách sao chép object sang khóa mới, rồi xóa object cũ. Nếu bạn muốn đổi tên một thư mục, bạn phải đổi tên từng object bên trong nó một cách riêng lẻ, vì tên thư mục là một phần của khóa.
Các key-value store mà chúng ta đã thảo luận trong Chương 4 được tối ưu cho các giá trị nhỏ (thường là kilobyte) và các lần đọc/ghi thường xuyên, độ trễ thấp. Ngược lại, hệ thống tệp phân tán và object store thường được tối ưu cho các object lớn (megabyte đến gigabyte) và các lần đọc ít thường xuyên hơn với kích thước lớn hơn. Tuy nhiên, gần đây, object store đã bắt đầu bổ sung hỗ trợ cho các lần đọc/ghi thường xuyên và kích thước nhỏ hơn. Ví dụ, S3 Express One Zone hiện cung cấp độ trễ mili giây đơn lẻ và mô hình giá tương tự hơn với key-value store.
Một điểm khác biệt khác giữa hệ thống tệp phân tán và object store là các DFS như HDFS cho phép các tác vụ tính toán chạy trên máy lưu trữ một bản sao của tệp cụ thể. Điều này cho phép tác vụ đọc tệp đó mà không cần gửi qua mạng, tiết kiệm băng thông nếu mã thực thi của tác vụ nhỏ hơn tệp cần đọc. Mặt khác, object store thường tách biệt lưu trữ và tính toán. Làm như vậy có thể dùng nhiều băng thông hơn, nhưng mạng datacenter hiện đại rất nhanh, nên điều này thường được chấp nhận. Kiến trúc này cũng cho phép tài nguyên máy chủ như CPU và bộ nhớ được mở rộng độc lập với lưu trữ vì hai thứ được tách rời nhau.
Phối hợp tác vụ phân tán (Distributed Job Orchestration)
Phép tương tự hệ điều hành của chúng ta cũng áp dụng cho việc phối hợp tác vụ. Khi bạn thực thi
một batch job trên Unix, cần có thứ gì đó thực sự chạy các tiến trình awk, sort, uniq, và
head. Dữ liệu cần được chuyển từ đầu ra của một tiến trình sang đầu vào của tiến trình khác, bộ
nhớ phải được cấp phát cho mỗi tiến trình, các lệnh từ mỗi tiến trình phải được lên lịch công bằng
và thực thi trên CPU, giới hạn bộ nhớ và I/O phải được thực thi, v.v. Trên một máy đơn, kernel của
hệ điều hành chịu trách nhiệm cho công việc đó. Trong môi trường phân tán, đây là vai trò của một
job orchestrator (bộ phối hợp tác vụ).
Các framework xử lý batch gửi yêu cầu đến scheduler (bộ lên lịch) của orchestrator để chạy một job. Các yêu cầu khởi động job chứa metadata như:
số lượng tác vụ cần thực thi,
lượng bộ nhớ, CPU, và đĩa cần cho mỗi tác vụ,
mã định danh job,
thông tin xác thực truy cập,
các tham số job như dữ liệu đầu vào và đầu ra,
các yêu cầu phần cứng cụ thể như GPU hoặc loại đĩa, và
vị trí mã thực thi của job.
Các orchestrator như Kubernetes và Hadoop YARN (Yet Another Resource Negotiator) 13 kết hợp thông tin này với metadata của cluster để thực thi job bằng các thành phần sau:
- Task executor (bộ thực thi tác vụ)
Một executor daemon như NodeManager của YARN hoặc kubelet của Kubernetes chạy trên mỗi node trong cluster. Executor chịu trách nhiệm chạy các tác vụ của job, gửi heartbeat (nhịp tim) để báo hiệu trạng thái hoạt động, và theo dõi trạng thái tác vụ cùng việc cấp phát tài nguyên trên node. Khi một yêu cầu khởi động tác vụ được gửi đến executor, nó tải mã thực thi của job và chạy lệnh để khởi động tác vụ. Sau đó executor giám sát tiến trình cho đến khi nó hoàn tất hoặc thất bại, lúc đó nó cập nhật metadata trạng thái tác vụ tương ứng.
Nhiều executor cũng hoạt động cùng hệ điều hành để cung cấp cả cô lập bảo mật lẫn hiệu năng. YARN và Kubernetes đều sử dụng Linux cgroups, ví dụ như vậy. Điều này ngăn các tác vụ truy cập dữ liệu không được phép, hoặc ảnh hưởng tiêu cực đến hiệu năng của các tác vụ khác trên node bằng cách sử dụng quá nhiều tài nguyên.
- Resource Manager (bộ quản lý tài nguyên)
Resource manager của orchestrator lưu trữ metadata về mỗi node, bao gồm phần cứng khả dụng (CPU, GPU, bộ nhớ, đĩa, v.v.), trạng thái tác vụ, vị trí mạng, trạng thái node, và các thông tin liên quan khác. Vì vậy, manager cung cấp cái nhìn toàn cục về trạng thái hiện tại của cluster. Tính chất tập trung của resource manager có thể dẫn đến các nút thắt về khả năng mở rộng và tính sẵn sàng. YARN sử dụng ZooKeeper và Kubernetes sử dụng etcd để lưu trạng thái cluster (xem “Dịch vụ phối hợp”).
- Scheduler (bộ lên lịch)
Orchestrator thường có một hệ thống con scheduler tập trung, nhận yêu cầu khởi động, dừng, hoặc kiểm tra trạng thái của một job. Ví dụ, một scheduler có thể nhận yêu cầu khởi động một job với 10 tác vụ sử dụng một Docker image cụ thể trên các node có loại GPU cụ thể. Scheduler sử dụng thông tin từ yêu cầu và trạng thái của resource manager để xác định tác vụ nào chạy trên node nào. Các task executor sau đó được thông báo về công việc được giao và bắt đầu thực thi.
Mặc dù mỗi orchestrator sử dụng thuật ngữ khác nhau, bạn sẽ tìm thấy những thành phần này trong hầu hết mọi hệ thống orchestration.
Note
Các quyết định lên lịch đôi khi yêu cầu các scheduler dành riêng cho ứng dụng, có thể tính đến các yêu cầu đặc thù, chẳng hạn như tự động mở rộng read replica khi đạt đến ngưỡng truy vấn nhất định. Scheduler tập trung và scheduler dành riêng cho ứng dụng làm việc cùng nhau để xác định cách thực thi tác vụ tốt nhất. YARN gọi các sub-scheduler của mình là ApplicationMaster, trong khi Kubernetes gọi chúng là operator.
Cấp phát tài nguyên (Resource Allocation)
Scheduler có vai trò đặc biệt thách thức trong việc phối hợp tác vụ: chúng phải tìm ra cách phân bổ tài nguyên hạn chế của cluster tốt nhất giữa các job có nhu cầu cạnh tranh nhau. Về cơ bản, các quyết định của nó phải cân bằng giữa sự công bằng và hiệu quả.
Hãy tưởng tượng một cluster nhỏ với năm node có tổng cộng 160 lõi CPU. Scheduler của cluster nhận hai yêu cầu job, mỗi yêu cầu cần 100 lõi để hoàn thành công việc. Cách tốt nhất để lên lịch khối lượng công việc là gì?
Scheduler có thể quyết định chạy 80 tác vụ cho mỗi job, khởi động 20 tác vụ còn lại cho mỗi job khi các tác vụ trước hoàn thành.
Scheduler có thể chạy tất cả các tác vụ của một job, và chỉ bắt đầu chạy các tác vụ của job thứ hai khi có 100 lõi sẵn sàng, một chiến lược gọi là gang scheduling (lên lịch theo nhóm).
Một yêu cầu job đến trước yêu cầu kia. Scheduler phải quyết định có nên cấp tất cả 100 lõi cho job đó, hay giữ lại một số để chờ các job trong tương lai.
Đây là một ví dụ rất đơn giản, nhưng chúng ta đã thấy nhiều đánh đổi khó khăn. Trong tình huống gang scheduling, ví dụ, nếu scheduler giữ lại các lõi CPU cho đến khi tất cả 100 lõi cùng sẵn sàng, các node sẽ ngồi không. Mức sử dụng tài nguyên của cluster sẽ giảm và deadlock (bế tắc) có thể xảy ra nếu các job khác cũng cố gắng giữ lại các lõi CPU.
Mặt khác, nếu scheduler chỉ đơn giản chờ 100 lõi trở nên sẵn sàng, các job khác có thể chiếm các lõi đó trong thời gian chờ. Cluster có thể không có 100 lõi sẵn sàng trong một thời gian rất dài, dẫn đến starvation (chết đói tài nguyên). Scheduler có thể quyết định preempt (ưu tiên chiếm quyền) một số tác vụ của job đầu tiên, giết chúng để nhường chỗ cho job thứ hai. Preemption cũng làm giảm hiệu quả cluster vì các tác vụ bị giết sẽ cần được khởi động lại và chạy lại.
Bây giờ hãy tưởng tượng một scheduler phải đưa ra quyết định cấp phát cho hàng trăm hoặc thậm chí hàng triệu yêu cầu job như vậy. Tìm ra một giải pháp tối ưu có vẻ không khả thi. Thực ra, bài toán này là NP-hard (NP-khó), nghĩa là việc tính toán giải pháp tối ưu quá chậm đối với tất cả trừ những ví dụ nhỏ nhất 14, 15.
Trong thực tế, các scheduler do đó sử dụng heuristic (phương pháp ước lượng) để đưa ra các quyết định không tối ưu nhưng hợp lý. Một số thuật toán thường được sử dụng, bao gồm first-in first-out (FIFO, vào trước ra trước), dominant resource fairness (DRF, công bằng tài nguyên chủ đạo), hàng đợi ưu tiên, lên lịch dựa trên capacity hay quota, và các thuật toán bin-packing khác nhau. Chi tiết của các thuật toán này nằm ngoài phạm vi cuốn sách này, nhưng chúng là một lĩnh vực nghiên cứu thú vị.
Lên lịch workflow (Scheduling Workflows)
Ví dụ về các công cụ Unix ở đầu chương này liên quan đến một chuỗi nhiều lệnh, được kết nối bằng Unix pipe. Cùng một mẫu xuất hiện trong các tiến trình batch phân tán: thường đầu ra của một job cần trở thành đầu vào cho một hoặc nhiều job khác, và mỗi job có thể có nhiều đầu vào được tạo ra bởi các job khác. Đây được gọi là workflow hoặc đồ thị có hướng không chu trình (directed acyclic graph, DAG) của các job.
Note
Trong “Durable Execution và Workflow” chúng ta đã thấy các workflow engine cung cấp thực thi bền vững của một chuỗi các bước, thường thực hiện RPC. Trong bối cảnh xử lý batch, “workflow” có nghĩa khác: đó là một chuỗi các tiến trình batch, mỗi tiến trình nhận dữ liệu đầu vào và tạo ra dữ liệu đầu ra, nhưng thường không thực hiện RPC đến các dịch vụ bên ngoài. Các engine thực thi bền vững thường xử lý ít dữ liệu hơn trên mỗi yêu cầu so với các đối tác xử lý batch của chúng, mặc dù ranh giới có phần mờ nhạt.
Có một số lý do tại sao một workflow gồm nhiều job có thể cần thiết:
Nếu đầu ra của một job cần trở thành đầu vào cho nhiều job khác, được duy trì bởi các nhóm khác nhau, tốt nhất là job đầu tiên nên ghi đầu ra của nó vào một vị trí mà tất cả các job khác có thể đọc. Các job tiêu thụ đó sau đó có thể được lên lịch chạy mỗi khi dữ liệu đó được cập nhật, hoặc theo một lịch nào khác.
Bạn có thể muốn chuyển dữ liệu từ một công cụ xử lý này sang công cụ khác. Ví dụ, một Spark job có thể xuất dữ liệu ra HDFS, sau đó một Python script có thể kích hoạt một truy vấn Trino SQL (xem “Cloud Data Warehouse”) thực hiện xử lý thêm trên các tệp HDFS và xuất ra S3.
Một số pipeline dữ liệu yêu cầu nhiều giai đoạn xử lý bên trong. Ví dụ, nếu một giai đoạn cần phân mảnh dữ liệu theo một khóa, và giai đoạn tiếp theo cần phân mảnh theo một khóa khác, giai đoạn đầu tiên có thể xuất dữ liệu được phân mảnh theo cách mà giai đoạn thứ hai yêu cầu.
Trong ví dụ về công cụ Unix, pipe kết nối đầu ra của một lệnh với đầu vào của lệnh khác chỉ sử dụng một bộ đệm nhỏ trong bộ nhớ, và không ghi dữ liệu vào tệp. Nếu bộ đệm đó đầy, tiến trình tạo ra dữ liệu cần phải chờ cho đến khi tiến trình tiêu thụ đọc một số dữ liệu từ bộ đệm trước khi có thể xuất thêm, đây là một dạng backpressure (áp suất ngược). Spark, Flink, và các engine thực thi batch khác hỗ trợ một mô hình tương tự, trong đó đầu ra của một tác vụ được chuyển trực tiếp đến tác vụ khác (qua mạng nếu các tác vụ chạy trên các máy khác nhau).
Tuy nhiên, trong một workflow, thường thấy hơn là một job ghi đầu ra của nó vào hệ thống tệp phân tán hoặc object store, và job tiếp theo đọc từ đó. Điều này tách rời các job khỏi nhau, cho phép chúng chạy vào các thời điểm khác nhau. Nếu một job có nhiều đầu vào, một workflow scheduler thường chờ cho đến khi tất cả các job tạo ra đầu vào của nó hoàn thành thành công trước khi chạy job tiêu thụ những đầu vào đó.
Các scheduler trong các framework orchestration như ResourceManager của YARN hoặc scheduler tích hợp của Spark không quản lý toàn bộ workflow; chúng thực hiện lên lịch trên cơ sở từng job. Để xử lý các phụ thuộc giữa các lần thực thi job, nhiều workflow scheduler đã được phát triển, bao gồm Airflow, Dagster, và Prefect. Workflow scheduler có các tính năng quản lý hữu ích khi duy trì một tập hợp lớn các batch job. Các workflow bao gồm 50 đến 100 job là phổ biến trong nhiều pipeline dữ liệu, và trong một tổ chức lớn, nhiều nhóm khác nhau có thể đang chạy các job hoặc workflow khác nhau, đọc đầu ra của nhau trên nhiều hệ thống khác nhau. Hỗ trợ công cụ là quan trọng để quản lý các luồng dữ liệu phức tạp như vậy.
Xử lý lỗi (Handling Faults)
Batch job thường chạy trong thời gian dài. Các job chạy dài với nhiều tác vụ song song có khả năng gặp ít nhất một lần thất bại tác vụ trên đường. Như đã thảo luận trong “Lỗi phần cứng và phần mềm” và “Mạng không đáng tin cậy”, có nhiều lý do tại sao điều này có thể xảy ra, bao gồm lỗi phần cứng (đặc biệt trên phần cứng thông thường), hoặc gián đoạn mạng.
Một lý do khác tại sao một tác vụ có thể không hoàn thành là scheduler có thể cố ý preempt (giết) nó. Preemption đặc biệt hữu ích nếu bạn có nhiều mức ưu tiên: các tác vụ ưu tiên thấp rẻ hơn để chạy, và các tác vụ ưu tiên cao tốn kém hơn. Các tác vụ ưu tiên thấp có thể chạy bất cứ khi nào có năng lực tính toán dư thừa, nhưng chúng có nguy cơ bị preempt bất kỳ lúc nào nếu một tác vụ ưu tiên cao hơn xuất hiện. Các máy ảo rẻ hơn, ưu tiên thấp như vậy được gọi là spot instance trên Amazon EC2, spot virtual machine trên Azure, và preemptible instance trên Google Cloud 16.
Vì xử lý batch thường được sử dụng cho các job không nhạy cảm với thời gian, nó phù hợp để sử dụng các tác vụ ưu tiên thấp và spot instance để giảm chi phí chạy job. Về bản chất, những job đó có thể sử dụng các tài nguyên tính toán dư thừa mà nếu không sẽ nhàn rỗi, và từ đó tăng mức sử dụng của cluster. Tuy nhiên, điều này cũng có nghĩa là những tác vụ đó có nhiều khả năng bị giết bởi scheduler hơn: preemption xảy ra thường xuyên hơn lỗi phần cứng 17.
Vì batch job tái tạo đầu ra của chúng từ đầu mỗi lần chạy, các lỗi tác vụ dễ xử lý hơn so với trong các hệ thống trực tuyến: hệ thống có thể xóa đầu ra một phần từ lần thực thi thất bại và lên lịch chạy lại trên một máy khác. Sẽ lãng phí khi chạy lại toàn bộ job chỉ do một lỗi tác vụ đơn lẻ. MapReduce và các hệ thống kế thừa do đó giữ cho việc thực thi các tác vụ song song độc lập với nhau, để chúng có thể thử lại công việc ở mức độ chi tiết của một tác vụ riêng lẻ 3.
Khả năng chịu lỗi phức tạp hơn khi đầu ra của một tác vụ trở thành đầu vào cho tác vụ khác như một phần của workflow. MapReduce giải quyết điều này bằng cách luôn ghi dữ liệu trung gian như vậy trở lại hệ thống tệp phân tán, và chờ tác vụ ghi hoàn thành thành công trước khi cho phép các tác vụ khác đọc dữ liệu. Điều này hoạt động, ngay cả trong môi trường mà preemption phổ biến, nhưng có nghĩa là nhiều lần ghi vào DFS, có thể không hiệu quả.
Spark giữ dữ liệu trung gian trong bộ nhớ hoặc “tràn” ra đĩa cục bộ, và chỉ ghi kết quả cuối cùng vào DFS. Nó cũng theo dõi cách dữ liệu trung gian được tính toán, cho phép Spark tính toán lại trong trường hợp mất dữ liệu 18. Flink sử dụng một cách tiếp cận khác dựa trên việc định kỳ checkpointing (tạo điểm kiểm tra) một snapshot (ảnh chụp nhanh) của các tác vụ 19. Chúng ta sẽ quay lại chủ đề này trong “Dataflow Engine”.
Các mô hình xử lý batch (Batch Processing Models)
Chúng ta đã thấy cách các batch job được lên lịch trong môi trường phân tán. Bây giờ hãy chú ý đến cách các framework xử lý batch thực sự xử lý dữ liệu. Hai mô hình phổ biến nhất là MapReduce và dataflow engine. Mặc dù dataflow engine phần lớn đã thay thế MapReduce trong thực tế, nhưng việc hiểu cách MapReduce hoạt động là hữu ích, vì nó đã ảnh hưởng đến nhiều framework xử lý batch hiện đại.
MapReduce và dataflow engine đã phát triển để hỗ trợ nhiều mô hình lập trình, bao gồm API lập trình cấp thấp, ngôn ngữ truy vấn quan hệ, và DataFrame API. Nhiều tùy chọn khác nhau cho phép kỹ sư ứng dụng, kỹ sư phân tích, nhà phân tích kinh doanh, và thậm chí nhân viên không kỹ thuật xử lý dữ liệu công ty cho các trường hợp sử dụng khác nhau, mà chúng ta sẽ thảo luận trong “Các trường hợp sử dụng Batch”.
MapReduce
Mẫu xử lý dữ liệu trong MapReduce rất giống với ví dụ phân tích log web server trong “Phân tích log đơn giản”:
Đọc một tập hợp các tệp đầu vào, và chia nhỏ thành các record (bản ghi). Trong ví dụ log web server, mỗi record là một dòng trong log (tức là
\nlà dấu phân cách record). Trong MapReduce của Hadoop, tệp đầu vào được lưu trong hệ thống tệp phân tán như HDFS hoặc object store như S3. Nhiều định dạng tệp được sử dụng, chẳng hạn như Apache Parquet (định dạng cột, xem “Column-Oriented Storage”) hoặc Apache Avro (định dạng theo hàng, xem “Avro”).Gọi hàm mapper để trích xuất một khóa và giá trị từ mỗi record đầu vào. Trong ví dụ công cụ Unix, hàm mapper là
awk '{print $7}': nó trích xuất URL ($7) làm khóa, và để giá trị trống.Sắp xếp tất cả các cặp khóa-giá trị theo khóa. Trong ví dụ log, điều này được thực hiện bởi lệnh
sortđầu tiên.Gọi hàm reducer để lặp qua các cặp khóa-giá trị đã được sắp xếp. Nếu có nhiều lần xuất hiện của cùng một khóa, việc sắp xếp đã đặt chúng liền kề nhau trong danh sách, nên dễ dàng kết hợp các giá trị đó mà không cần giữ nhiều trạng thái trong bộ nhớ. Trong ví dụ công cụ Unix, reducer được triển khai bởi lệnh
uniq -c, đếm số lượng record liền kề có cùng khóa.
Bốn bước đó có thể được thực hiện bởi một MapReduce job. Bước 2 (map) và 4 (reduce) là nơi bạn
viết mã xử lý dữ liệu tùy chỉnh của mình. Bước 1 (chia tệp thành record) được xử lý bởi bộ phân
tích cú pháp định dạng đầu vào. Bước 3, bước sort, là ẩn trong MapReduce: bạn không cần phải
viết nó, vì đầu ra từ mapper luôn được sắp xếp trước khi đưa cho reducer. Bước sắp xếp này là một
thuật toán xử lý batch cơ bản, mà chúng ta sẽ xem lại trong “Shuffling Data”.
Để tạo một MapReduce job, bạn cần triển khai hai hàm callback: mapper và reducer, hoạt động như sau:
- Mapper
Mapper được gọi một lần cho mỗi record đầu vào, và nhiệm vụ của nó là trích xuất khóa và giá trị từ record đầu vào. Với mỗi đầu vào, nó có thể tạo ra bất kỳ số lượng cặp khóa-giá trị nào (kể cả không có cặp nào). Nó không giữ bất kỳ trạng thái nào từ record đầu vào này sang record tiếp theo, vì vậy mỗi record được xử lý độc lập.
- Reducer
Framework MapReduce lấy các cặp khóa-giá trị được tạo ra bởi các mapper, thu thập tất cả các giá trị thuộc cùng một khóa, và gọi reducer với một iterator (bộ lặp) trên tập hợp giá trị đó. Reducer có thể tạo ra các record đầu ra (chẳng hạn như số lần xuất hiện của cùng một URL).
Trong ví dụ log web server, chúng ta có lệnh sort thứ hai ở bước 5, xếp hạng URL theo số lượng
yêu cầu. Trong MapReduce, nếu bạn cần một giai đoạn sắp xếp thứ hai, bạn có thể triển khai nó
bằng cách viết một MapReduce job thứ hai và sử dụng đầu ra của job đầu tiên làm đầu vào cho job
thứ hai. Nhìn như thế này, vai trò của mapper là chuẩn bị dữ liệu bằng cách đưa nó vào dạng phù
hợp để sắp xếp, và vai trò của reducer là xử lý dữ liệu đã được sắp xếp.
MAPREDUCE VÀ LẬP TRÌNH HÀM (FUNCTIONAL PROGRAMMING)
Mặc dù MapReduce được dùng để xử lý batch, mô hình lập trình xuất phát từ lập trình hàm. Lisp đã giới thiệu map và reduce (hay fold) như các hàm bậc cao trên danh sách, và chúng đã được đưa vào các ngôn ngữ phổ biến như Python, Rust, và Java. Nhiều thao tác xử lý dữ liệu phổ biến, bao gồm những thao tác được cung cấp bởi SQL, có thể được triển khai trên MapReduce. Cả hai hàm, và lập trình hàm nói chung, có những thuộc tính quan trọng mà MapReduce được hưởng lợi. Map và reduce có thể kết hợp (composable), phù hợp với xử lý dữ liệu (như chúng ta đã thấy trong ví dụ Unix). Map cũng song song hóa một cách dễ dàng (mỗi đầu vào được xử lý độc lập), giúp đơn giản hóa việc thực thi song song của MapReduce. Đối với reduce, các khóa khác nhau có thể được xử lý song song.
Triển khai một job xử lý phức tạp bằng API MapReduce thô thực sự khá khó và tốn công, ví dụ, bất kỳ thuật toán join nào được job sử dụng sẽ cần phải triển khai từ đầu 20. MapReduce cũng khá chậm so với các bộ xử lý batch hiện đại hơn. Một lý do là I/O dựa trên tệp của nó ngăn việc pipeline hóa job, tức là xử lý dữ liệu đầu ra trong một job downstream trước khi job upstream hoàn thành.
Dataflow Engine
Để khắc phục một số vấn đề của MapReduce, một số engine thực thi mới cho các tính toán batch phân tán đã được phát triển, nổi tiếng nhất trong số đó là Spark 18, 21 và Flink 19. Có nhiều sự khác biệt trong cách chúng được thiết kế, nhưng chúng có một điểm chung: chúng xử lý toàn bộ workflow như một job duy nhất, thay vì chia nó thành các subjob độc lập.
Vì chúng mô hình hóa rõ ràng luồng dữ liệu qua nhiều giai đoạn xử lý, các hệ thống này được gọi là dataflow engine (engine luồng dữ liệu). Giống như MapReduce, chúng hỗ trợ một API cấp thấp gọi hàm do người dùng định nghĩa để xử lý một record tại một thời điểm, nhưng chúng cũng cung cấp các toán tử cấp cao hơn như join và group by. Chúng song song hóa công việc bằng cách phân mảnh đầu vào, và sao chép đầu ra của một tác vụ qua mạng để trở thành đầu vào cho tác vụ khác. Không giống như trong MapReduce, các toán tử không cần phải đảm nhận các vai trò nghiêm ngặt xen kẽ giữa map và reduce, mà thay vào đó có thể được lắp ráp theo những cách linh hoạt hơn.
Các dataflow API này thường sử dụng các khối xây dựng theo phong cách quan hệ để biểu diễn một phép tính: join (kết hợp) các dataset theo giá trị của một số trường; group by (nhóm) các tuple theo khóa; filter (lọc) theo một điều kiện nào đó; và aggregate (tổng hợp) các tuple bằng cách đếm, tính tổng, hoặc các hàm khác. Về mặt nội bộ, các thao tác này được triển khai bằng các thuật toán shuffle mà chúng ta thảo luận trong phần tiếp theo.
Phong cách engine xử lý này dựa trên các hệ thống nghiên cứu như Dryad 22 và Nephele 23, và nó cung cấp một số ưu điểm so với mô hình MapReduce:
Công việc tốn kém như sắp xếp chỉ cần được thực hiện ở những nơi thực sự cần thiết, thay vì luôn xảy ra theo mặc định giữa mỗi giai đoạn map và reduce.
Khi có nhiều toán tử liên tiếp không thay đổi việc phân mảnh của dataset (chẳng hạn như map hoặc filter), chúng có thể được kết hợp thành một tác vụ duy nhất, giảm chi phí sao chép dữ liệu.
Vì tất cả các join và phụ thuộc dữ liệu trong một workflow được khai báo rõ ràng, scheduler có cái nhìn tổng quan về dữ liệu nào được yêu cầu ở đâu, vì vậy nó có thể thực hiện các tối ưu hóa về tính cục bộ. Ví dụ, nó có thể cố gắng đặt tác vụ tiêu thụ một số dữ liệu trên cùng máy với tác vụ tạo ra nó, để dữ liệu có thể được trao đổi qua bộ đệm bộ nhớ dùng chung thay vì phải sao chép qua mạng.
Thường đủ để giữ trạng thái trung gian giữa các toán tử trong bộ nhớ hoặc ghi vào đĩa cục bộ, yêu cầu ít I/O hơn so với ghi vào hệ thống tệp phân tán hoặc object store (nơi nó phải được sao chép sang nhiều máy và ghi vào đĩa trên mỗi replica). MapReduce đã sử dụng tối ưu hóa này cho đầu ra mapper, nhưng dataflow engine tổng quát hóa ý tưởng cho tất cả trạng thái trung gian.
Các toán tử có thể bắt đầu thực thi ngay khi đầu vào của chúng sẵn sàng; không cần chờ toàn bộ giai đoạn trước đó hoàn thành trước khi giai đoạn tiếp theo bắt đầu.
Các tiến trình hiện có có thể được tái sử dụng để chạy các toán tử mới, giảm chi phí khởi động so với MapReduce (khởi động một JVM mới cho mỗi tác vụ).
Bạn có thể sử dụng dataflow engine để triển khai các tính toán tương tự như workflow MapReduce, và chúng thường thực thi nhanh hơn đáng kể nhờ các tối ưu hóa được mô tả ở đây.
Shuffling dữ liệu (Shuffling Data)
Chúng ta đã thấy rằng cả ví dụ công cụ Unix ở đầu chương và MapReduce đều dựa trên sắp xếp. Các bộ xử lý batch cần có khả năng sắp xếp các dataset có kích thước petabyte, quá lớn để vừa trên một máy đơn. Do đó chúng yêu cầu một thuật toán sắp xếp phân tán trong đó cả đầu vào và đầu ra đều được phân mảnh. Thuật toán như vậy được gọi là shuffle (xáo trộn).
SHUFFLE KHÔNG PHẢI LÀ NGẪU NHIÊN
Thuật ngữ shuffle gây nhầm lẫn. Khi bạn xáo trộn một bộ bài, bạn kết thúc với thứ tự ngẫu nhiên. Ngược lại, shuffle mà chúng ta đang nói đến ở đây tạo ra một thứ tự được sắp xếp, không có tính ngẫu nhiên.
Shuffling là một thuật toán cơ bản cho các bộ xử lý batch, được sử dụng cho các join và tổng hợp. MapReduce, Spark, Flink, Daft, Dataflow, và BigQuery 24 đều triển khai các thuật toán shuffle có khả năng mở rộng và hiệu suất cao để xử lý các dataset lớn. Chúng ta sẽ sử dụng shuffle trong Hadoop MapReduce 25 để minh họa, nhưng các khái niệm trong phần này cũng áp dụng cho các hệ thống khác.
Hình 11-1 cho thấy luồng dữ liệu trong một MapReduce job. Chúng ta
giả định rằng đầu vào của job được phân mảnh, và các mảnh được đánh nhãn m 1, m 2, và m 3.
Ví dụ, mỗi mảnh có thể là một tệp riêng biệt trên HDFS hoặc một object riêng biệt trong object
store, và tất cả các mảnh thuộc cùng một dataset được nhóm vào cùng một thư mục HDFS hoặc có cùng
khóa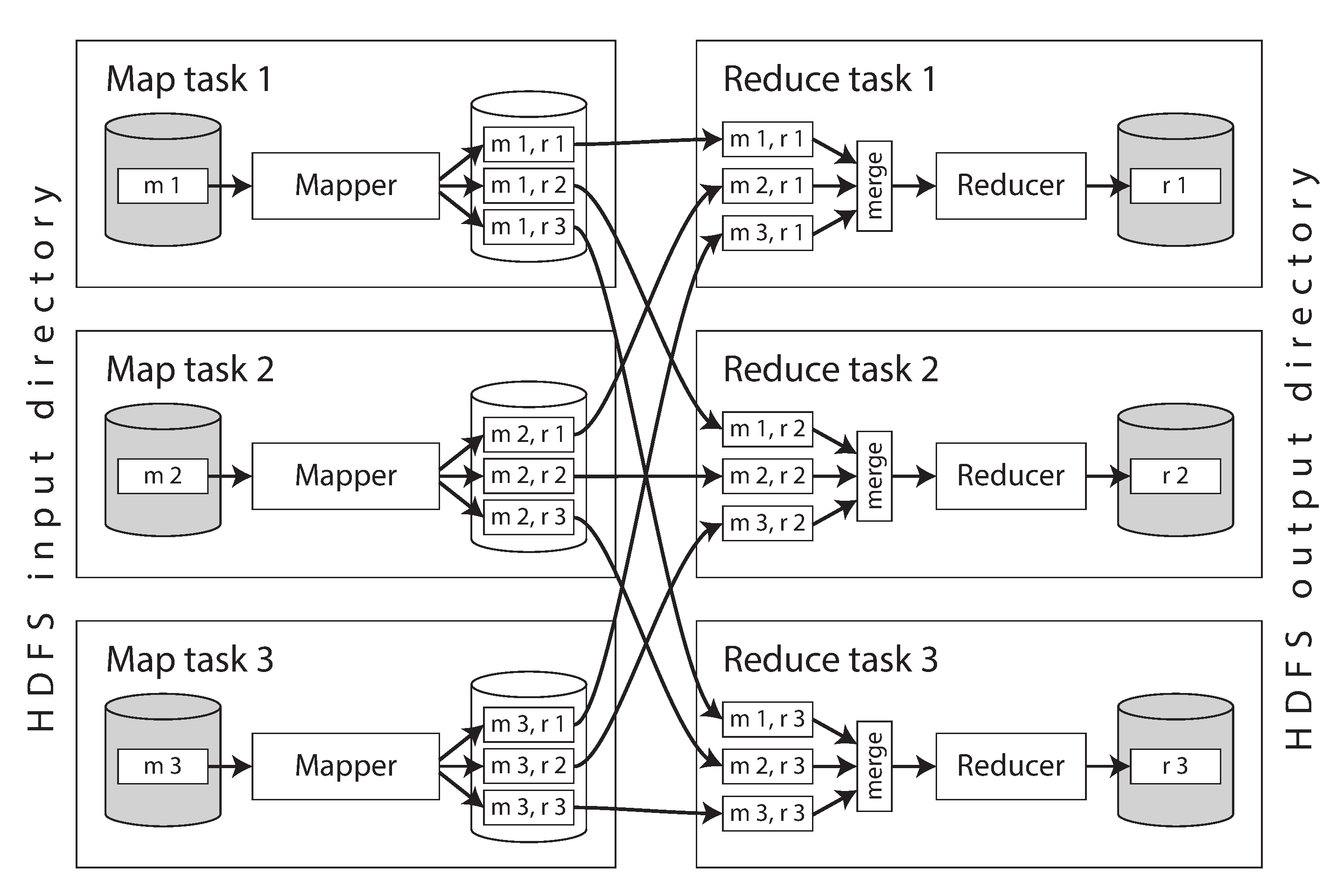
Framework khởi động một map task (tác vụ ánh xạ) riêng biệt cho mỗi shard đầu vào. Một task đọc tệp được giao cho nó, truyền từng bản ghi một tới hàm callback của mapper. Phía reduce của tính toán cũng được phân shard. Trong khi số lượng map task được xác định bởi số lượng shard đầu vào, số lượng reduce task do tác giả tác vụ cấu hình (có thể khác với số lượng map task).
Đầu ra của mapper gồm các cặp key-value, và framework cần đảm bảo rằng nếu hai mapper khác nhau cho ra cùng một key, các cặp key-value đó sẽ được xử lý bởi cùng một reducer task. Để đạt điều này, mỗi mapper tạo một tệp đầu ra riêng biệt trên đĩa cục bộ của nó cho mỗi reducer (ví dụ, tệp m 1, r 2 trong Hình 11-1 là tệp do mapper 1 tạo ra chứa dữ liệu dành cho reducer 2). Khi mapper cho ra một cặp key-value, hash của key thường xác định tệp reducer nào nó được ghi vào (tương tự “Sharding by Hash of Key”).
Trong khi mapper đang ghi các tệp này, nó cũng sắp xếp các cặp key-value trong mỗi tệp. Điều này có thể thực hiện bằng các kỹ thuật chúng ta đã thấy trong “Log-Structured Storage”: các lô cặp key-value trước tiên được thu thập trong một cấu trúc dữ liệu được sắp xếp trong bộ nhớ, sau đó được ghi ra dưới dạng các tệp segment đã sắp xếp, và các tệp segment nhỏ hơn dần dần được hợp nhất thành các tệp lớn hơn.
Sau khi mỗi mapper hoàn thành, các reducer kết nối tới nó và sao chép tệp cặp key-value đã sắp xếp phù hợp về đĩa cục bộ của chúng. Khi reduce task đã có phần đầu ra từ tất cả các mapper, nó hợp nhất các tệp này lại với nhau, giữ nguyên thứ tự sắp xếp, theo kiểu mergesort. Các cặp key-value có cùng key lúc này nằm liên tiếp nhau, dù chúng đến từ các mapper khác nhau. Hàm reducer sau đó được gọi một lần cho mỗi key, mỗi lần với một iterator trả về tất cả các giá trị cho key đó.
Bất kỳ bản ghi nào do hàm reducer cho ra đều được ghi tuần tự vào một tệp, với một tệp cho mỗi reduce task. Các tệp này (r 1, r 2, r 3 trong Hình 11-1) trở thành các shard của dataset đầu ra của tác vụ, và chúng được ghi trở lại vào distributed filesystem hoặc object store.
Mặc dù MapReduce thực thi bước shuffle giữa các bước map và reduce, các engine dataflow hiện đại và data warehouse trên cloud tinh vi hơn. Các hệ thống như BigQuery đã tối ưu thuật toán shuffle để giữ dữ liệu trong bộ nhớ và ghi dữ liệu ra các dịch vụ sắp xếp ngoài 24. Các dịch vụ như vậy tăng tốc quá trình shuffle và nhân bản dữ liệu đã shuffle để đảm bảo khả năng chịu lỗi.
JOIN và GROUP BY
Hãy xem dữ liệu đã được sắp xếp đơn giản hóa các phép join và tổng hợp phân tán như thế nào. Chúng ta sẽ tiếp tục dùng MapReduce để minh họa, mặc dù các khái niệm này áp dụng cho hầu hết các hệ thống xử lý batch.
Một ví dụ điển hình về phép join trong một tác vụ batch được minh họa trong Hình 11-2. Bên trái là nhật ký các sự kiện mô tả những gì người dùng đã đăng nhập thực hiện trên một website (được gọi là activity events hay clickstream data), và bên phải là cơ sở dữ liệu người dùng. Bạn có thể hình dung ví dụ này là một phần của star schema (xem “Stars and Snowflakes: Schemas for Analytics”): nhật ký sự kiện là bảng fact, và cơ sở dữ liệu người dùng là một trong các chiều (dimension).
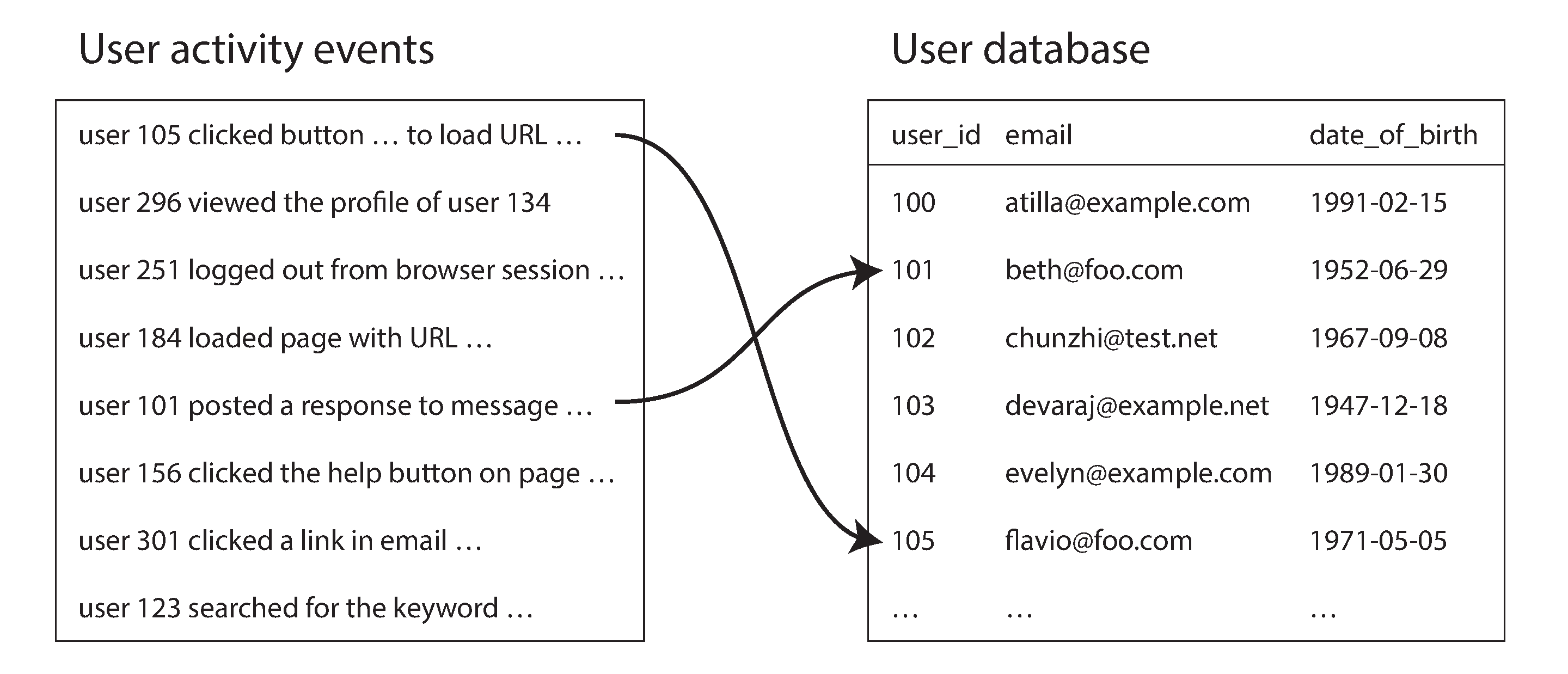
Nếu bạn muốn phân tích các sự kiện hoạt động có tính đến thông tin từ cơ sở dữ liệu người dùng (ví dụ, tìm hiểu xem các trang nào phổ biến hơn với người dùng trẻ hay lớn tuổi, dùng trường ngày sinh trong hồ sơ người dùng), bạn cần tính toán phép join giữa hai bảng này. Bạn sẽ tính phép join đó như thế nào, giả sử cả hai bảng đều lớn đến mức phải được phân shard?
Bạn có thể tận dụng đặc điểm trong MapReduce: bước shuffle tập hợp tất cả các cặp key-value có cùng key về cùng một reducer, bất kể chúng nằm ở shard nào ban đầu. Ở đây, user ID có thể dùng làm key. Vì vậy, bạn có thể viết một mapper duyệt qua các sự kiện hoạt động của người dùng và phát ra các URL trang xem được đánh key theo user ID, như minh họa trong Hình 11-3. Một mapper khác duyệt qua từng hàng của cơ sở dữ liệu người dùng, trích xuất user ID làm key và ngày sinh của người dùng làm value.
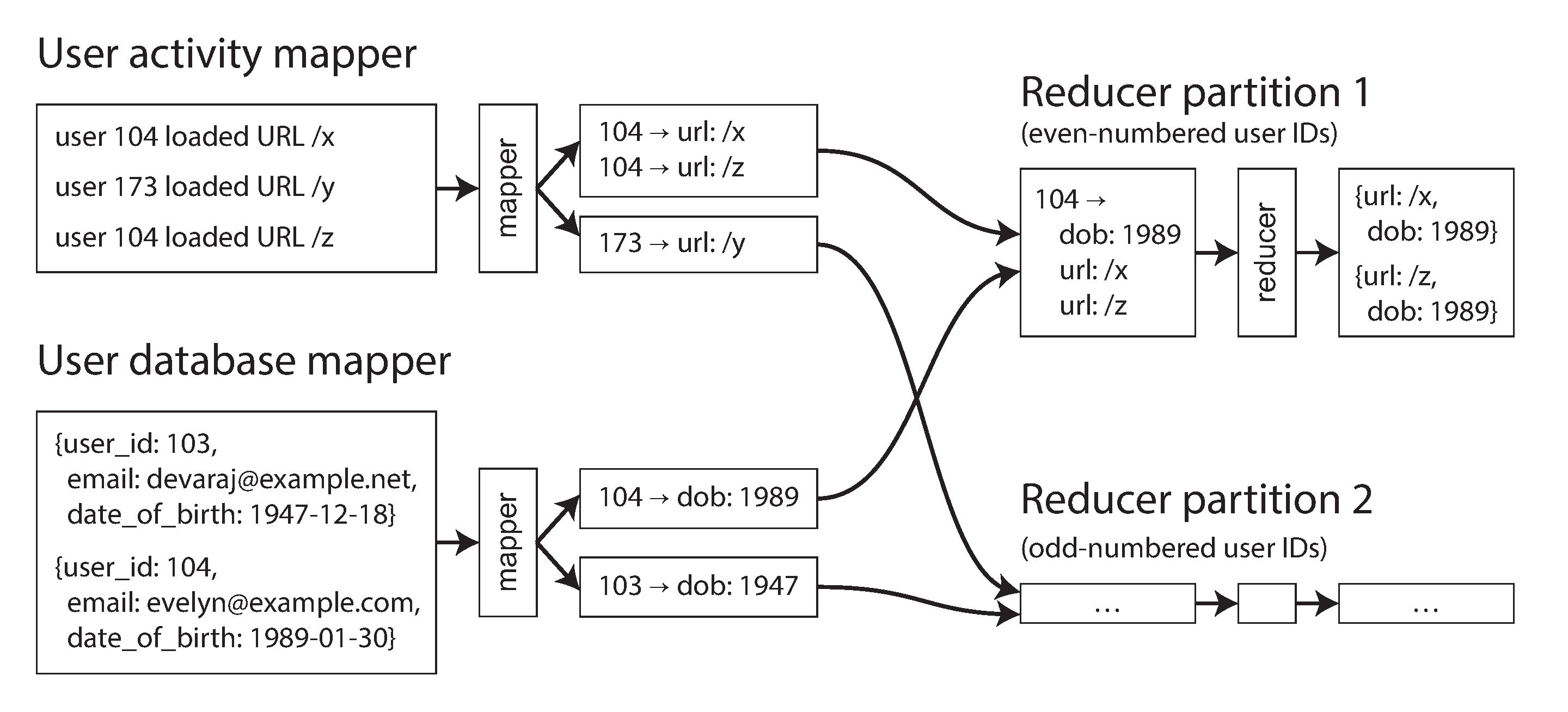
Bước shuffle sau đó đảm bảo rằng một hàm reducer có thể truy cập ngày sinh của một người dùng cụ thể và tất cả các sự kiện xem trang của người dùng đó cùng một lúc. Tác vụ MapReduce thậm chí có thể sắp xếp các bản ghi sao cho reducer luôn nhận bản ghi từ cơ sở dữ liệu người dùng trước, tiếp theo là các sự kiện hoạt động theo thứ tự timestamp. Kỹ thuật này được gọi là secondary sort 25.
Reducer sau đó có thể thực hiện logic join thực sự một cách dễ dàng. Giá trị đầu tiên được kỳ vọng là ngày sinh, mà reducer lưu vào một biến cục bộ. Sau đó nó lặp qua các sự kiện hoạt động với cùng user ID, cho ra mỗi URL đã xem cùng với ngày sinh của người xem. Vì reducer xử lý tất cả các bản ghi cho một user ID cụ thể trong một lần, nó chỉ cần giữ một bản ghi người dùng trong bộ nhớ tại bất kỳ thời điểm nào, và không bao giờ cần thực hiện bất kỳ yêu cầu nào qua mạng. Thuật toán này được gọi là sort-merge join, vì đầu ra của mapper được sắp xếp theo key, và các reducer sau đó hợp nhất các danh sách bản ghi đã sắp xếp từ cả hai phía của phép join.
Tác vụ MapReduce tiếp theo trong workflow có thể tính toán phân phối tuổi của người xem cho mỗi URL. Để làm vậy, tác vụ trước tiên sẽ shuffle dữ liệu dùng URL làm key. Sau khi sắp xếp, các reducer sẽ lặp qua tất cả lượt xem trang (với ngày sinh của người xem) cho một URL duy nhất, giữ bộ đếm số lần xem theo từng nhóm tuổi, và tăng bộ đếm phù hợp cho mỗi lượt xem trang. Theo cách này bạn có thể triển khai thao tác group by và tổng hợp.
Ngôn ngữ truy vấn
Theo năm tháng, các engine thực thi cho xử lý batch phân tán đã trưởng thành. Đến nay, hạ tầng đã đủ mạnh để lưu trữ và xử lý hàng chục petabyte dữ liệu trên các cụm máy hơn 10.000 máy. Khi vấn đề vận hành vật lý các tiến trình batch ở quy mô như vậy được coi là đã giải quyết ít nhiều, sự chú ý đã chuyển sang cải thiện mô hình lập trình.
MapReduce, các engine dataflow, và các cloud data warehouse đều đã chấp nhận SQL như ngôn ngữ chung (lingua franca) cho xử lý batch. Đây là sự phù hợp tự nhiên: các data warehouse truyền thống đã dùng SQL, các công cụ phân tích dữ liệu và ETL đã hỗ trợ SQL, và tất cả các nhà phát triển và chuyên viên phân tích đều biết nó.
Ngoài lợi thế rõ ràng là yêu cầu ít code hơn so với các tác vụ MapReduce viết tay, các giao diện ngôn ngữ truy vấn này cũng cho phép sử dụng tương tác, trong đó bạn viết các truy vấn phân tích và chạy chúng từ terminal hoặc GUI. Kiểu truy vấn tương tác này là cách hiệu quả và tự nhiên cho phân tích kinh doanh, quản lý sản phẩm, đội ngũ bán hàng và tài chính, cũng như những người khác để khám phá dữ liệu trong môi trường xử lý batch. Mặc dù không phải dạng xử lý batch cổ điển, hỗ trợ SQL đã làm cho các truy vấn khám phá phù hợp với các hệ thống xử lý batch phân tán.
Các ngôn ngữ truy vấn cấp cao không chỉ làm cho con người sử dụng hệ thống hiệu quả hơn, mà còn cải thiện hiệu suất thực thi tác vụ ở cấp độ máy. Như chúng ta đã thấy trong “Cloud Data Warehouses”, các query engine chịu trách nhiệm chuyển đổi các truy vấn SQL thành các tác vụ batch để thực thi trong cụm. Bước chuyển đổi từ truy vấn sang cây cú pháp rồi tới các toán tử vật lý cho phép engine tối ưu hóa truy vấn. Các query engine như Hive, Trino, Spark, và Flink có các bộ tối ưu hóa truy vấn dựa trên chi phí (cost-based query optimizer) có thể phân tích thuộc tính của các đầu vào join và tự động quyết định thuật toán nào phù hợp nhất cho nhiệm vụ hiện tại. Các bộ tối ưu hóa thậm chí có thể thay đổi thứ tự join để giảm thiểu lượng trạng thái trung gian 19, 26, 27, 28.
Trong khi SQL là ngôn ngữ truy vấn xử lý batch đa năng phổ biến nhất, các ngôn ngữ khác vẫn được dùng cho các trường hợp đặc thù. Apache Pig là ngôn ngữ dựa trên các toán tử quan hệ cho phép xác định các pipeline dữ liệu theo từng bước, thay vì một truy vấn SQL lớn duy nhất. DataFrame (xem phần tiếp theo) có các đặc điểm tương tự, và Morel là ngôn ngữ hiện đại hơn chịu ảnh hưởng bởi Pig. Một số người dùng khác đã áp dụng các ngôn ngữ truy vấn JSON như jq, JMESPath, hoặc JsonPath.
Trong “Graph-Like Data Models” chúng ta đã thảo luận về sử dụng đồ thị để mô hình hóa dữ liệu, và sử dụng các ngôn ngữ truy vấn đồ thị để duyệt qua các cạnh và đỉnh trong đồ thị. Nhiều framework xử lý đồ thị cũng hỗ trợ tính toán batch thông qua các ngôn ngữ truy vấn như Gremlin của Apache TinkerPop. Chúng ta sẽ xem xét các trường hợp sử dụng xử lý đồ thị chi tiết hơn trong “Batch Use Cases”.
XỬ LÝ BATCH VÀ CLOUD DATA WAREHOUSE HỘI TỤ
Về mặt lịch sử, các data warehouse chạy trên phần cứng chuyên dụng, cung cấp các truy vấn phân tích SQL trên dữ liệu quan hệ. Ngược lại, các framework xử lý batch như MapReduce nhằm mục tiêu cung cấp khả năng mở rộng lớn hơn và tính linh hoạt cao hơn bằng cách hỗ trợ logic xử lý viết bằng ngôn ngữ lập trình đa năng, cho phép đọc và ghi các định dạng dữ liệu tùy ý.
Theo thời gian, hai hướng này đã trở nên giống nhau hơn nhiều. Các framework xử lý batch hiện đại nay hỗ trợ SQL như ngôn ngữ để viết các tác vụ batch, và đạt hiệu suất tốt trên các truy vấn quan hệ bằng cách sử dụng các định dạng lưu trữ theo cột như Parquet và các engine thực thi truy vấn được tối ưu hóa (xem “Query Execution: Compilation and Vectorization”). Trong khi đó, các data warehouse đã trở nên có khả năng mở rộng hơn bằng cách chuyển lên cloud (xem “Cloud Data Warehouses”), và triển khai nhiều kỹ thuật lập lịch, chịu lỗi và shuffle tương tự như các framework batch phân tán. Nhiều hệ thống cũng sử dụng distributed filesystem.
Cũng như các hệ thống xử lý batch đã áp dụng SQL như mô hình xử lý, các cloud warehouse cũng đã áp dụng các mô hình xử lý thay thế như DataFrame (được thảo luận trong phần tiếp theo). Ví dụ, Google Cloud BigQuery cung cấp thư viện BigQuery DataFrames và Snowpark của Snowflake tích hợp với Pandas. Các bộ điều phối workflow xử lý batch như Airflow, Prefect, và Dagster cũng tích hợp với các cloud warehouse.
Không phải tất cả các tác vụ batch đều dễ biểu đạt bằng SQL. Các thuật toán đồ thị lặp như PageRank, machine learning phức tạp, và nhiều tác vụ khác khó biểu đạt bằng SQL. Xử lý dữ liệu AI, bao gồm dữ liệu phi quan hệ và đa phương thức như hình ảnh, video, và âm thanh, cũng có thể khó thực hiện bằng SQL.
Hơn nữa, các cloud data warehouse gặp khó khăn với một số workload nhất định. Tính toán từng hàng kém hiệu quả hơn khi sử dụng các định dạng lưu trữ theo cột. API warehouse thay thế hoặc hệ thống xử lý batch được ưu tiên hơn trong những trường hợp như vậy. Các cloud data warehouse cũng thường đắt hơn các hệ thống xử lý batch khác. Việc chạy các tác vụ lớn trong các hệ thống xử lý batch như Spark hay Flink có thể tiết kiệm chi phí hơn.
Cuối cùng, quyết định giữa xử lý dữ liệu trong các hệ thống batch hay data warehouse phụ thuộc vào các yếu tố như chi phí, sự tiện lợi, tính dễ triển khai, tính khả dụng, v.v. Hầu hết các doanh nghiệp lớn có nhiều hệ thống xử lý dữ liệu, cho họ sự linh hoạt trong quyết định này. Các công ty nhỏ hơn thường chỉ cần một hệ thống.
DataFrame
Khi các nhà khoa học dữ liệu và thống kê học bắt đầu sử dụng các framework xử lý batch phân tán cho các trường hợp sử dụng machine learning, họ thấy các mô hình xử lý hiện có rườm rà, vì họ quen làm việc với mô hình dữ liệu DataFrame có trong R và Pandas (xem “DataFrames, Matrices, and Arrays”). DataFrame tương tự như một bảng trong cơ sở dữ liệu quan hệ: là tập hợp các hàng, và tất cả các giá trị trong cùng một cột có cùng kiểu. Thay vì viết một truy vấn SQL lớn, người dùng gọi các hàm tương ứng với các toán tử quan hệ để thực hiện lọc, join, sắp xếp, group by, và các thao tác khác.
Ban đầu, thao tác DataFrame thường xảy ra cục bộ, trong bộ nhớ. Do đó, DataFrame bị giới hạn với các dataset vừa với một máy đơn. Các nhà khoa học dữ liệu muốn tương tác với các dataset lớn trong môi trường xử lý batch bằng các API DataFrame mà họ quen dùng. Các framework xử lý dữ liệu phân tán như Spark, Flink, và Daft đã áp dụng các API DataFrame để đáp ứng nhu cầu này. Mặt khác, DataFrame cục bộ thường được đánh chỉ mục và có thứ tự trong khi DataFrame phân tán thường không 29. Điều này có thể dẫn đến bất ngờ về hiệu suất khi di chuyển sang các framework batch.
Các API DataFrame trông giống với API dataflow, nhưng cách triển khai khác nhau. Trong khi Pandas thực thi các thao tác ngay lập tức khi các phương thức DataFrame được gọi, Apache Spark trước tiên dịch tất cả các lời gọi API DataFrame thành một query plan và chạy tối ưu hóa truy vấn trước khi thực thi workflow trên engine dataflow phân tán của nó. Điều này cho phép cải thiện hiệu suất.
Các framework như Daft thậm chí hỗ trợ cả tính toán phía client và phía server. Các thao tác nhỏ hơn, trong bộ nhớ được thực thi trên client trong khi các dataset lớn hơn và tính toán được thực thi trên server. Các định dạng lưu trữ theo cột như Apache Arrow cung cấp mô hình dữ liệu thống nhất mà cả engine thực thi phía client và phía server đều có thể chia sẻ.
Các Trường Hợp Sử Dụng Batch
Bây giờ chúng ta đã hiểu cách xử lý batch hoạt động, hãy xem nó được áp dụng cho một loạt các ứng dụng khác nhau như thế nào. Các tác vụ batch rất phù hợp để xử lý các dataset lớn theo khối, nhưng không tốt cho các trường hợp sử dụng có độ trễ thấp. Do đó, bạn sẽ thấy các tác vụ batch ở bất cứ đâu có nhiều dữ liệu và độ mới của dữ liệu không quan trọng. Điều này nghe có vẻ hạn chế, nhưng hóa ra một lượng đáng kể xử lý dữ liệu phù hợp với mô hình này:
Đối chiếu kế toán và tồn kho (accounting and inventory reconciliation), nơi các công ty xác minh rằng các giao dịch khớp với tài khoản ngân hàng và tồn kho của họ, thường được thực hiện theo batch 30.
Trong sản xuất, dự báo nhu cầu được tính toán trong các tác vụ batch định kỳ 31.
Các công ty thương mại điện tử, truyền thông, và mạng xã hội huấn luyện các mô hình đề xuất của họ bằng các tác vụ batch 32, 33.
Nhiều hệ thống tài chính cũng dựa trên batch. Ví dụ, mạng ngân hàng của Hoa Kỳ chạy gần như hoàn toàn trên các tác vụ batch 34.
Trong các phần tiếp theo, chúng ta sẽ thảo luận một số trường hợp sử dụng xử lý batch mà bạn sẽ tìm thấy trong hầu hết mọi ngành công nghiệp.
Extract–Transform–Load (ETL)
“Data Warehousing” đã giới thiệu ý tưởng về ETL và ELT, nơi một pipeline xử lý dữ liệu trích xuất dữ liệu từ cơ sở dữ liệu sản xuất, chuyển đổi nó, và tải kết quả vào một hệ thống downstream (chúng ta sẽ dùng “ETL” trong phần này để đại diện cho cả workload ETL và ELT). Các tác vụ batch thường được dùng cho các workload như vậy, đặc biệt khi hệ thống downstream là một data warehouse.
Bản chất song song của các tác vụ batch làm cho chúng rất phù hợp cho chuyển đổi dữ liệu. Phần lớn chuyển đổi dữ liệu liên quan đến các workload “embarrassingly parallel” (song song hoàn toàn). Lọc dữ liệu, chiếu các trường, và nhiều chuyển đổi data warehouse phổ biến khác đều có thể được thực hiện song song.
Các môi trường xử lý batch cũng đi kèm với các bộ lập lịch workflow mạnh mẽ, giúp dễ dàng lập lịch, điều phối và gỡ lỗi các tác vụ pipeline dữ liệu ETL. Khi xảy ra lỗi, các bộ lập lịch thường thử lại các tác vụ để giảm thiểu các vấn đề tạm thời có thể xảy ra. Một tác vụ liên tục thất bại sẽ được đánh dấu là thất bại, giúp các nhà phát triển dễ dàng thấy tác vụ nào trong pipeline dữ liệu của họ ngừng hoạt động. Các bộ lập lịch như Airflow thậm chí đi kèm với các toán tử source, sink, và query tích hợp sẵn cho MySQL, PostgreSQL, Snowflake, Spark, Flink, và hàng chục hệ thống phổ biến khác. Sự tích hợp chặt chẽ giữa bộ lập lịch và các hệ thống xử lý dữ liệu đơn giản hóa việc tích hợp dữ liệu.
Chúng ta cũng đã thấy rằng các tác vụ batch dễ khắc phục sự cố và sửa chữa khi có sự cố. Tính năng này vô giá khi gỡ lỗi các pipeline dữ liệu. Các tệp thất bại có thể được kiểm tra dễ dàng để xem điều gì đã xảy ra, và các tác vụ batch ETL có thể được sửa và chạy lại. Ví dụ, một tệp đầu vào có thể không còn chứa một trường mà tác vụ batch chuyển đổi dự định sử dụng. Các kỹ sư dữ liệu sẽ thấy rằng trường đó bị thiếu, và cập nhật logic chuyển đổi hoặc tác vụ tạo ra đầu vào.
Các pipeline dữ liệu trước đây được quản lý bởi một nhóm kỹ thuật dữ liệu duy nhất, vì người ta coi là không công bằng khi yêu cầu các nhóm khác đang làm tính năng sản phẩm phải viết và quản lý các pipeline dữ liệu batch phức tạp. Gần đây, các cải tiến trong các mô hình xử lý batch và quản lý metadata đã làm cho các kỹ sư trong toàn tổ chức dễ dàng đóng góp và quản lý các pipeline dữ liệu của riêng họ hơn nhiều. Các thực hành Data mesh 35, 36, data contract 37, và data fabric 38 cung cấp các tiêu chuẩn và công cụ để giúp các nhóm xuất bản dữ liệu của họ một cách an toàn để bất kỳ ai trong tổ chức có thể sử dụng.
Các pipeline dữ liệu và các truy vấn phân tích đã bắt đầu chia sẻ không chỉ các mô hình xử lý, mà còn cả các engine thực thi. Nhiều tác vụ ETL batch hiện chạy trên cùng các hệ thống như các truy vấn phân tích đọc đầu ra của chúng. Không phải hiếm khi thấy cả chuyển đổi pipeline dữ liệu và truy vấn phân tích đều chạy dưới dạng các truy vấn SparkSQL, Trino, hoặc DuckDB. Kiến trúc như vậy càng làm mờ ranh giới giữa kỹ thuật ứng dụng, kỹ thuật dữ liệu, kỹ thuật phân tích, và phân tích kinh doanh.
Phân Tích Dữ Liệu
Trong “Operational Versus Analytical Systems”, chúng ta đã thấy rằng các truy vấn phân tích (OLAP) thường quét qua một số lượng lớn bản ghi, thực hiện nhóm và tổng hợp. Có thể chạy các workload như vậy trong một hệ thống xử lý batch, cùng với các workload xử lý batch khác. Các nhà phân tích viết các truy vấn SQL thực thi trên một query engine, đọc và ghi từ distributed file system hoặc object store. Metadata bảng như ánh xạ bảng tới tệp, tên và kiểu được quản lý với các định dạng bảng như Apache Iceberg và các catalog như Unity (xem “Cloud Data Warehouses”). Kiến trúc này được gọi là data lakehouse 39.
Cũng như với ETL, các cải tiến trong giao diện truy vấn SQL có nghĩa là nhiều tổ chức hiện sử dụng các framework batch như Spark cho phân tích. Các mẫu truy vấn như vậy có hai kiểu:
Truy vấn pre-aggregation (tổng hợp trước), nơi dữ liệu được tổng hợp thành các OLAP cube hoặc data mart để tăng tốc truy vấn (xem “Materialized Views and Data Cubes”). Dữ liệu được tổng hợp trước được truy vấn trong warehouse hoặc đẩy tới các hệ thống OLAP realtime chuyên dụng như Apache Druid hoặc Apache Pinot. Việc tổng hợp trước thường diễn ra theo khoảng thời gian định kỳ. Các bộ điều phối workflow được thảo luận trong “Scheduling Workflows” được dùng để quản lý các workload này.
Truy vấn ad hoc mà người dùng chạy để trả lời các câu hỏi kinh doanh cụ thể, điều tra hành vi người dùng, gỡ lỗi các vấn đề vận hành, và nhiều hơn nữa. Thời gian phản hồi quan trọng với trường hợp sử dụng này. Các nhà phân tích chạy truy vấn lặp đi lặp lại khi nhận được phản hồi và tìm hiểu thêm về dữ liệu họ đang điều tra. Các framework xử lý batch với thực thi truy vấn nhanh giúp giảm thời gian chờ đợi cho các nhà phân tích.
Hỗ trợ SQL cho phép các framework xử lý batch tích hợp với bảng tính và các công cụ trực quan hóa dữ liệu như Tableau, Power BI, Looker, và Apache Superset. Ví dụ, Tableau cung cấp các kết nối SparkSQL và Presto, trong khi Apache Superset hỗ trợ Trino, Hive, Spark SQL, Presto, và nhiều hệ thống khác cuối cùng thực thi các tác vụ batch để truy vấn dữ liệu.
Machine Learning
Machine learning (ML) thường xuyên sử dụng xử lý batch. Các nhà khoa học dữ liệu, kỹ sư ML, và kỹ sư AI sử dụng các framework xử lý batch để điều tra các mẫu dữ liệu, chuyển đổi dữ liệu, và huấn luyện các mô hình machine learning. Các ứng dụng phổ biến bao gồm:
Feature engineering (kỹ thuật tính năng): Dữ liệu thô được lọc và chuyển đổi thành dữ liệu mà các mô hình có thể được huấn luyện trên đó. Các mô hình dự đoán thường cần dữ liệu số, vì vậy các kỹ sư phải chuyển đổi các dạng dữ liệu khác (như văn bản hoặc giá trị rời rạc) sang định dạng yêu cầu.
Model training (huấn luyện mô hình): Dữ liệu huấn luyện là đầu vào cho tiến trình batch, và các trọng số của mô hình được huấn luyện là đầu ra.
Batch inference (suy luận batch): Một mô hình đã huấn luyện sau đó có thể được dùng để thực hiện các dự đoán theo khối nếu dataset lớn và kết quả realtime không cần thiết. Điều này bao gồm đánh giá các dự đoán của mô hình trên một dataset kiểm tra.
Các framework xử lý batch cung cấp các công cụ rõ ràng cho các trường hợp sử dụng này. Ví dụ, MLlib của Apache Spark và FlinkML của Apache Flink đi kèm với nhiều công cụ feature engineering, hàm thống kê, và các bộ phân loại.
Các ứng dụng machine learning như hệ thống đề xuất và hệ thống xếp hạng cũng sử dụng nhiều xử lý đồ thị (xem “Graph-Like Data Models”). Nhiều thuật toán đồ thị được biểu đạt bằng cách duyệt từng cạnh một, join một đỉnh với một đỉnh liền kề để truyền một số thông tin, và lặp lại cho đến khi một điều kiện nào đó được đáp ứng, ví dụ cho đến khi không còn cạnh nào để đi theo, hoặc cho đến khi một số liệu nào đó hội tụ.
Mô hình tính toán bulk synchronous parallel (BSP) 40 đã trở nên phổ biến để xử lý đồ thị theo batch. Ngoài những ứng dụng khác, nó được triển khai bởi Apache Giraph 20, API GraphX của Spark, và API Gelly của Flink 41. Nó cũng được gọi là mô hình Pregel, vì bài báo Pregel của Google đã phổ biến cách tiếp cận này để xử lý đồ thị 42.
Xử lý batch cũng là một phần không thể thiếu trong việc chuẩn bị dữ liệu và huấn luyện large language model (LLM). Dữ liệu đầu vào văn bản thô như các website thường nằm trong DFS hoặc object store. Dữ liệu này phải được tiền xử lý để phù hợp với việc huấn luyện. Các bước tiền xử lý phù hợp với các framework xử lý batch bao gồm:
Văn bản thuần phải được trích xuất từ HTML và văn bản không đúng định dạng phải được sửa chữa.
Các tài liệu chất lượng thấp, không liên quan và trùng lặp phải được phát hiện và loại bỏ.
Văn bản phải được tokenize (tách thành các từ) và chuyển đổi thành các embedding, là các biểu diễn số của mỗi từ.
Các framework xử lý batch như Kubeflow, Flyte, và Ray được xây dựng có mục đích cho các workload như vậy. Ví dụ, OpenAI sử dụng Ray như một phần trong quy trình huấn luyện ChatGPT 43. Các framework này có tích hợp sẵn cho các thư viện LLM và AI như PyTorch, Tensorflow, XGBoost, và nhiều thư viện khác. Chúng cũng cung cấp hỗ trợ tích hợp sẵn cho feature engineering, huấn luyện mô hình, batch inference, và fine tuning (điều chỉnh một mô hình nền tảng cho các trường hợp sử dụng cụ thể).
Cuối cùng, các nhà khoa học dữ liệu thường thí nghiệm với dữ liệu trong các notebook tương tác như Jupyter hoặc Hex. Notebook được tạo thành từ các cell (ô), là các đoạn nhỏ markdown, Python, hoặc SQL. Các cell được thực thi tuần tự để tạo ra bảng tính, đồ thị, hoặc dữ liệu. Nhiều notebook sử dụng xử lý batch thông qua các API DataFrame hoặc truy vấn các hệ thống như vậy bằng SQL.
Phục Vụ Dữ Liệu Dẫn Xuất
Các tác vụ batch thường được dùng để xây dựng các dataset được tính toán trước hoặc dẫn xuất như đề xuất sản phẩm, báo cáo cho người dùng cuối, và các tính năng cho các mô hình machine learning. Các dataset này thường được phục vụ từ cơ sở dữ liệu sản xuất, key-value store, hoặc search engine. Bất kể hệ thống nào được sử dụng, dữ liệu được tính toán trước cần đi từ distributed filesystem hoặc object store của bộ xử lý batch vào cơ sở dữ liệu đang phục vụ lưu lượng truy cập trực tiếp.
Lựa chọn rõ ràng nhất có thể là dùng thư viện client cho cơ sở dữ liệu yêu thích của bạn trực tiếp trong một tác vụ batch, và ghi trực tiếp vào server cơ sở dữ liệu, từng bản ghi một. Điều này sẽ hoạt động (giả sử các quy tắc firewall của bạn cho phép truy cập trực tiếp từ môi trường xử lý batch của bạn đến các cơ sở dữ liệu sản xuất của bạn), nhưng đây là ý tưởng tồi vì một số lý do:
Thực hiện một yêu cầu mạng cho mỗi bản ghi đơn lẻ chậm hơn nhiều bậc so với thông lượng thông thường của một tác vụ batch. Ngay cả khi thư viện client hỗ trợ batching, hiệu suất có thể kém.
Các framework xử lý batch thường chạy nhiều tác vụ song song. Nếu tất cả các tác vụ cùng lúc ghi vào cùng một cơ sở dữ liệu đầu ra, với tốc độ được kỳ vọng của một tiến trình batch, cơ sở dữ liệu đó có thể dễ dàng bị quá tải, và hiệu suất của nó đối với các truy vấn có thể bị ảnh hưởng. Điều này đến lượt có thể gây ra các vấn đề vận hành ở các phần khác của hệ thống 44.
Thông thường, các tác vụ batch cung cấp đảm bảo all-or-nothing (tất cả hoặc không gì cả) rõ ràng cho đầu ra tác vụ: nếu một tác vụ thành công, kết quả là đầu ra của việc chạy mọi task đúng một lần, ngay cả khi một số task thất bại và phải được thử lại dọc đường; nếu toàn bộ tác vụ thất bại, không có đầu ra nào được tạo ra. Tuy nhiên, ghi vào một hệ thống bên ngoài từ bên trong một tác vụ tạo ra các tác dụng phụ có thể nhìn thấy từ bên ngoài mà không thể che giấu theo cách này. Do đó, bạn phải lo lắng về kết quả từ các tác vụ hoàn thành một phần có thể nhìn thấy với các hệ thống khác. Nếu một task thất bại và được khởi động lại, nó có thể trùng lặp đầu ra từ lần thực thi thất bại.
Giải pháp tốt hơn là để các tác vụ batch đẩy các dataset được tính toán trước vào các stream như các Kafka topic, mà chúng ta thảo luận thêm trong Chương 12. Các search engine như Elasticsearch, các hệ thống OLAP realtime như Apache Pinot và Apache Druid, các datastore dẫn xuất như Venice [^45], và các cloud data warehouse như ClickHouse đều có khả năng tích hợp sẵn để nhận dữ liệu từ Kafka vào hệ thống của họ. Đẩy dữ liệu qua các hệ thống streaming giải quyết một số vấn đề chúng ta đã thảo luận ở trên:
Các hệ thống streaming được tối ưu hóa cho việc ghi tuần tự, giúp chúng phù hợp hơn với workload ghi theo khối của một tác vụ batch.
Các hệ thống streaming cũng có thể hoạt động như một bộ đệm giữa tác vụ batch và các cơ sở dữ liệu sản xuất. Các hệ thống downstream có thể điều tiết tốc độ đọc của chúng để đảm bảo chúng có thể tiếp tục phục vụ lưu lượng sản xuất một cách thoải mái.
Đầu ra của một tác vụ batch đơn lẻ có thể được tiêu thụ bởi nhiều hệ thống downstream.
Các hệ thống streaming có thể đóng vai trò là ranh giới bảo mật giữa môi trường xử lý batch và mạng sản xuất: chúng có thể được triển khai trong một mạng DMZ (vùng phi quân sự) nằm giữa mạng xử lý batch và mạng sản xuất.
Đẩy dữ liệu qua các stream không vốn dĩ giải quyết vấn đề đảm bảo all-or-nothing mà chúng ta đã thảo luận ở trên. Để thực hiện điều này, các tác vụ batch phải gửi thông báo đến các hệ thống downstream rằng tác vụ của chúng đã hoàn thành và dữ liệu hiện có thể được phục vụ. Người tiêu dùng stream cần có khả năng giữ dữ liệu họ nhận được ẩn với các truy vấn, như một giao dịch chưa được commit với cô lập read committed (xem “Read Committed”), cho đến khi họ được thông báo rằng nó đã hoàn tất.
Một mẫu phổ biến hơn khi bootstrapping (khởi tạo) cơ sở dữ liệu là xây dựng một cơ sở dữ liệu hoàn toàn mới bên trong tác vụ batch và tải hàng loạt các tệp đó trực tiếp vào cơ sở dữ liệu từ distributed filesystem, object store, hoặc local filesystem. Nhiều hệ thống dữ liệu cung cấp các công cụ nhập hàng loạt như API để nhập hàng loạt các SST từ các batch job.
Xây dựng cơ sở dữ liệu theo batch và nhập dữ liệu hàng loạt rất nhanh, đồng thời giúp các hệ thống dễ dàng chuyển đổi nguyên tử (atomic switch) giữa các phiên bản dataset. Mặt khác, việc cập nhật gia tăng (incrementally update) các dataset từ các batch job tạo cơ sở dữ liệu hoàn toàn mới có thể là thách thức. Cách tiếp cận kết hợp (hybrid approach) thường được dùng trong các tình huống cần cả khởi tạo ban đầu (bootstrapping) lẫn tải gia tăng (incremental loads). Venice, ví dụ, hỗ trợ các hybrid store cho phép cập nhật từng dòng theo batch và hoán đổi toàn bộ dataset.
Tóm tắt
Trong chương này, chúng ta đã khám phá thiết kế và triển khai các hệ thống xử lý batch. Chúng ta bắt đầu với chuỗi công cụ Unix cổ điển (awk, sort, uniq, v.v.), để minh họa các nguyên lý cơ bản của xử lý batch như sắp xếp và đếm.
Chúng ta sau đó mở rộng lên các hệ thống xử lý batch phân tán. Chúng ta thấy rằng I/O kiểu batch xử lý các dataset đầu vào bất biến (immutable), có giới hạn (bounded) để tạo ra dữ liệu đầu ra, cho phép chạy lại và gỡ lỗi mà không có tác dụng phụ. Để xử lý các file, chúng ta thấy rằng các framework batch có ba thành phần chính: một lớp điều phối (orchestration layer) xác định nơi và thời điểm các job chạy, một lớp lưu trữ (storage layer) để lưu trữ dữ liệu, và một lớp tính toán (computation layer) xử lý dữ liệu thực tế.
Chúng ta đã xem xét cách các hệ thống file phân tán và object store quản lý các file lớn thông qua sao chép theo khối (block-based replication), bộ nhớ đệm (caching) và dịch vụ metadata, cũng như cách các framework batch hiện đại tương tác với các hệ thống này thông qua các API có thể thay thế được (pluggable APIs). Chúng ta cũng đã thảo luận về cách các orchestrator lên lịch tác vụ, phân bổ tài nguyên và xử lý lỗi trong các cluster lớn. Chúng ta cũng so sánh các job orchestrator lên lịch các job với các workflow orchestrator quản lý vòng đời của một tập hợp các job chạy theo đồ thị phụ thuộc (dependency graph).
Chúng ta đã khảo sát các mô hình xử lý batch, bắt đầu với MapReduce và các hàm map và reduce chuẩn của nó. Tiếp theo, chúng ta chuyển sang các dataflow engine như Spark và Flink, cung cấp các API dataflow dễ sử dụng hơn và hiệu năng tốt hơn. Để hiểu cách các batch job mở rộng quy mô, chúng ta đã đề cập đến thuật toán shuffle, một thao tác nền tảng cho phép nhóm, join và tổng hợp dữ liệu.
Khi các hệ thống batch trưởng thành, trọng tâm chuyển sang tính khả dụng. Bạn đã tìm hiểu về các ngôn ngữ truy vấn cấp cao như SQL và DataFrame API, giúp các batch job dễ tiếp cận và dễ tối ưu hóa hơn. Các query optimizer dịch các truy vấn khai báo (declarative queries) thành các kế hoạch thực thi hiệu quả.
Chúng ta kết thúc chương với các trường hợp sử dụng xử lý batch phổ biến:
Pipeline ETL (Extract, Transform, Load: trích xuất, biến đổi và tải dữ liệu), trích xuất, biến đổi và tải dữ liệu giữa các hệ thống khác nhau bằng các workflow theo lịch;
Phân tích (Analytics), nơi các batch job hỗ trợ cả dashboard đã được tổng hợp trước và các truy vấn ad hoc;
Học máy (Machine learning), nơi các batch job chuẩn bị và xử lý các tập dữ liệu huấn luyện lớn;
Điền dữ liệu vào các hệ thống phục vụ sản xuất (production-facing systems) từ đầu ra batch, thường thông qua stream hoặc các công cụ tải hàng loạt (bulk loading tools), nhằm phục vụ dữ liệu dẫn xuất cho người dùng.
Trong chương tiếp theo, chúng ta sẽ chuyển sang xử lý stream (stream processing), trong đó đầu vào là không giới hạn (unbounded), tức là bạn vẫn có một job, nhưng đầu vào của nó là các luồng dữ liệu không bao giờ kết thúc. Trong trường hợp này, một job không bao giờ hoàn thành, vì bất kỳ lúc nào cũng có thể có thêm công việc đến. Chúng ta sẽ thấy rằng xử lý stream và xử lý batch có điểm tương đồng ở một số khía cạnh, nhưng giả định về các stream không giới hạn cũng thay đổi nhiều điều về cách chúng ta xây dựng hệ thống.
Chú thích
Tài liệu tham khảo
Nathan Marz. How to Beat the CAP Theorem. nathanmarz.com, October 2011. Archived at perma.cc/4BS9-R9A4 ↩︎
Molly Bartlett Dishman and Martin Fowler. Agile Architecture. At O’Reilly Software Architecture Conference, March 2015. ↩︎
Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. At 6th USENIX Symposium on Operating System Design and Implementation (OSDI), December 2004. ↩︎ ↩︎
Shivnath Babu and Herodotos Herodotou. Massively Parallel Databases and MapReduce Systems. Foundations and Trends in Databases, volume 5, issue 1, pages 1–104, November 2013. doi:10.1561/1900000036 ↩︎
David J. DeWitt and Michael Stonebraker. MapReduce: A Major Step Backwards. Originally published at databasecolumn.vertica.com, January 2008. Archived at perma.cc/U8PA-K48V ↩︎
Henry Robinson. The Elephant Was a Trojan Horse: On the Death of Map-Reduce at Google. the-paper-trail.org, June 2014. Archived at perma.cc/9FEM-X787 ↩︎
Urs Hölzle. R.I.P. MapReduce. After having served us well since 2003, today we removed the remaining internal codebase for good. twitter.com, September 2019. Archived at perma.cc/B34T-LLY7 ↩︎
Adam Drake. Command-Line Tools Can Be 235x Faster than Your Hadoop Cluster. aadrake.com, January 2014. Archived at perma.cc/87SP-ZMCY ↩︎
sort: Sort text files. GNU Coreutils 9.7 Documentation, Free Software Foundation, Inc., 2025. ↩︎Michael Ovsiannikov, Silvius Rus, Damian Reeves, Paul Sutter, Sriram Rao, and Jim Kelly. The Quantcast File System. Proceedings of the VLDB Endowment, volume 6, issue 11, pages 1092–1101, August 2013. doi:10.14778/2536222.2536234 ↩︎
Andrew Wang, Zhe Zhang, Kai Zheng, Uma Maheswara G., and Vinayakumar B. Introduction to HDFS Erasure Coding in Apache Hadoop. blog.cloudera.com, September 2015. Archived at archive.org ↩︎
Andy Warfield. Building and operating a pretty big storage system called S3. allthingsdistributed.com, July 2023. Archived at perma.cc/7LPK-TP7V ↩︎
Vinod Kumar Vavilapalli, Arun C. Murthy, Chris Douglas, Sharad Agarwal, Mahadev Konar, Robert Evans, Thomas Graves, Jason Lowe, Hitesh Shah, Siddharth Seth, Bikas Saha, Carlo Curino, Owen O’Malley, Sanjay Radia, Benjamin Reed, and Eric Baldeschwieler. Apache Hadoop YARN: Yet Another Resource Negotiator. At 4th Annual Symposium on Cloud Computing (SoCC), October 2013. doi:10.1145/2523616.2523633 ↩︎
Richard M. Karp. Reducibility Among Combinatorial Problems. Complexity of Computer Computations. The IBM Research Symposia Series. Springer, 1972. doi:10.1007/978-1-4684-2001-2_9 ↩︎
J. D. Ullman. NP-Complete Scheduling Problems. Journal of Computer and System Sciences, volume 10, issue 3, June 1975. doi:10.1016/S0022-0000(75)80008-0 ↩︎
Gilad David Maayan. The complete guide to spot instances on AWS, Azure and GCP. datacenterdynamics.com, March 2021. Archived at archive.org ↩︎
Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, and John Wilkes. Large-Scale Cluster Management at Google with Borg. At 10th European Conference on Computer Systems (EuroSys), April 2015. doi:10.1145/2741948.2741964 ↩︎
Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, and Ion Stoica. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. At 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), April 2012. ↩︎ ↩︎
Paris Carbone, Stephan Ewen, Seif Haridi, Asterios Katsifodimos, Volker Markl, and Kostas Tzoumas. Apache Flink™: Stream and Batch Processing in a Single Engine. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, volume 38, issue 4, December 2015. Archived at perma.cc/G3N3-BKX5 ↩︎ ↩︎ ↩︎
Mark Grover, Ted Malaska, Jonathan Seidman, and Gwen Shapira. Hadoop Application Architectures. O’Reilly Media, 2015. ISBN: 978-1-491-90004-8 ↩︎ ↩︎
Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee. Learning Spark, 2nd Edition. O’Reilly Media, 2020. ISBN: 978-1492050049 ↩︎
Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly. Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks. At 2nd European Conference on Computer Systems (EuroSys), March 2007. doi:10.1145/1272996.1273005 ↩︎
Daniel Warneke and Odej Kao. Nephele: Efficient Parallel Data Processing in the Cloud. At 2nd Workshop on Many-Task Computing on Grids and Supercomputers (MTAGS), November 2009. doi:10.1145/1646468.1646476 ↩︎
Hossein Ahmadi. In-memory query execution in Google BigQuery. cloud.google.com, August 2016. Archived at perma.cc/DGG2-FL9W ↩︎ ↩︎
Tom White. Hadoop: The Definitive Guide, 4th edition. O’Reilly Media, 2015. ISBN: 978-1-491-90163-2 ↩︎ ↩︎
Fabian Hüske. Peeking into Apache Flink’s Engine Room. flink.apache.org, March 2015. Archived at perma.cc/44BW-ALJX ↩︎
Mostafa Mokhtar. Hive 0.14 Cost Based Optimizer (CBO) Technical Overview. hortonworks.com, March 2015. Archived on archive.org ↩︎
Michael Armbrust, Reynold S. Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan, Michael J. Franklin, Ali Ghodsi, and Matei Zaharia. Spark SQL: Relational Data Processing in Spark. At ACM International Conference on Management of Data (SIGMOD), June 2015. doi:10.1145/2723372.2742797 ↩︎
Kaya Kupferschmidt. Spark vs Pandas, part 2 – Spark. towardsdatascience.com, October 2020. Archived at perma.cc/5BRK-G4N5 ↩︎
Ammar Chalifah. Tracking payments at scale. bolt.eu.com, June 2025. Archived at perma.cc/Q4KX-8K3J ↩︎
Nafi Ahmet Turgut, Hamza Akyıldız, Hasan Burak Yel, Mehmet İkbal Özmen, Mutlu Polatcan, Pinar Baki, and Esra Kayabali. Demand forecasting at Getir built with Amazon Forecast. aws.amazon.com.com, May 2023. Archived at perma.cc/H3H6-GNL7 ↩︎
Jason (Siyu) Zhu. Enhancing homepage feed relevance by harnessing the power of large corpus sparse ID embeddings. linkedin.com, August 2023. Archived at archive.org ↩︎
Avery Ching, Sital Kedia, and Shuojie Wang. Apache Spark @Scale: A 60 TB+ production use case. engineering.fb.com, August 2016. Archived at perma.cc/F7R5-YFAV ↩︎
Edward Kim. How ACH works: A developer perspective — Part 1. engineering.gusto.com, April 2014. Archived at perma.cc/F67P-VBLK ↩︎
Zhamak Dehghani. How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh. martinfowler.com, May 2019. Archived at perma.cc/LN2L-L4VC ↩︎
Chris Riccomini. What the Heck is a Data Mesh?! cnr.sh, June 2021. Archived at perma.cc/NEJ2-BAX3 ↩︎
Chad Sanderson, Mark Freeman, B. E. Schmidt. Data Contracts. O’Reilly Media, 2025. ISBN: 9781098157623 ↩︎
Daniel Abadi. Data Fabric vs. Data Mesh: What’s the Difference? starburst.io, November 2021. Archived at perma.cc/RSK3-HXDK ↩︎
Michael Armbrust, Ali Ghodsi, Reynold Xin, and Matei Zaharia. Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. At 11th Annual Conference on Innovative Data Systems Research (CIDR), January 2021. ↩︎
Leslie G. Valiant. A Bridging Model for Parallel Computation. Communications of the ACM, volume 33, issue 8, pages 103–111, August 1990. doi:10.1145/79173.79181 ↩︎
Stephan Ewen, Kostas Tzoumas, Moritz Kaufmann, and Volker Markl. Spinning Fast Iterative Data Flows. Proceedings of the VLDB Endowment, volume 5, issue 11, pages 1268-1279, July 2012. doi:10.14778/2350229.2350245 ↩︎
Grzegorz Malewicz, Matthew H. Austern, Aart J. C. Bik, James C. Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Czajkowski. Pregel: A System for Large-Scale Graph Processing. At ACM International Conference on Management of Data (SIGMOD), June 2010. doi:10.1145/1807167.1807184 ↩︎
Richard MacManus. OpenAI Chats about Scaling LLMs at Anyscale’s Ray Summit. thenewstack.io, September 2023. Archived at perma.cc/YJD6-KUXU ↩︎
Jay Kreps. Why Local State is a Fundamental Primitive in Stream Processing. oreilly.com, July 2014. Archived at perma.cc/P8HU-R5LA ↩︎