1. Đánh đổi trong Kiến trúc Hệ thống Dữ liệu
Không có giải pháp nào là hoàn hảo, chỉ có những sự đánh đổi. […] Nhưng bạn cố gắng đạt được sự đánh đổi tốt nhất có thể, và đó là tất cả những gì bạn có thể hy vọng.
Thomas Sowell, Phỏng vấn với Fred Barnes (2005)
Dữ liệu đóng vai trò trung tâm trong phần lớn quá trình phát triển ứng dụng ngày nay. Với các ứng dụng web và di động, phần mềm dưới dạng dịch vụ (SaaS - Software as a Service), và các dịch vụ đám mây, việc lưu trữ dữ liệu từ nhiều người dùng khác nhau trong một hạ tầng dữ liệu dùng chung trên máy chủ đã trở nên bình thường. Dữ liệu từ hoạt động người dùng, giao dịch kinh doanh, thiết bị và cảm biến cần được lưu trữ và cung cấp cho việc phân tích. Khi người dùng tương tác với một ứng dụng, họ vừa đọc dữ liệu đang được lưu trữ, vừa tạo ra thêm dữ liệu mới.
Lượng dữ liệu nhỏ, có thể được lưu trữ và xử lý trên một máy duy nhất, thường khá dễ xử lý. Tuy nhiên, khi khối lượng dữ liệu hoặc tốc độ truy vấn tăng lên, dữ liệu cần được phân tán trên nhiều máy, điều này dẫn đến nhiều thách thức. Khi nhu cầu của ứng dụng trở nên phức tạp hơn, việc lưu trữ tất cả trong một hệ thống duy nhất không còn đủ nữa, mà có thể cần phải kết hợp nhiều hệ thống lưu trữ hoặc xử lý khác nhau cung cấp các khả năng khác nhau.
Chúng ta gọi một ứng dụng là data-intensive (thâm dụng dữ liệu) nếu quản lý dữ liệu là một trong những thách thức chính trong quá trình phát triển ứng dụng đó 1. Trong khi các hệ thống compute-intensive (thâm dụng tính toán) đối mặt với thách thức song song hóa những tính toán rất lớn, thì trong các ứng dụng thâm dụng dữ liệu, chúng ta thường lo lắng hơn về những vấn đề như lưu trữ và xử lý khối lượng dữ liệu lớn, quản lý thay đổi dữ liệu, đảm bảo tính nhất quán khi đối mặt với lỗi và truy cập đồng thời, và đảm bảo các dịch vụ có tính sẵn sàng cao.
Các ứng dụng như vậy thường được xây dựng từ những thành phần chuẩn cung cấp các chức năng thường dùng. Ví dụ, nhiều ứng dụng cần:
- Lưu trữ dữ liệu để chúng, hoặc ứng dụng khác, có thể tìm lại sau (databases - cơ sở dữ liệu)
- Ghi nhớ kết quả của một thao tác tốn kém, để tăng tốc độ đọc (caches - bộ nhớ đệm)
- Cho phép người dùng tìm kiếm dữ liệu theo từ khóa hoặc lọc theo nhiều cách khác nhau (search indexes - chỉ mục tìm kiếm)
- Xử lý sự kiện và thay đổi dữ liệu ngay khi chúng xảy ra (stream processing - xử lý luồng)
- Định kỳ xử lý một lượng lớn dữ liệu tích lũy (batch processing - xử lý theo lô)
Khi xây dựng một ứng dụng, chúng ta thường lấy một vài hệ thống hoặc dịch vụ phần mềm, chẳng hạn như cơ sở dữ liệu hoặc API, và kết nối chúng lại với nhau bằng một số mã ứng dụng. Nếu bạn đang làm chính xác những gì các hệ thống dữ liệu được thiết kế để làm, thì quá trình này có thể khá dễ dàng.
Tuy nhiên, khi ứng dụng của bạn trở nên tham vọng hơn, các thách thức sẽ nảy sinh. Có rất nhiều hệ thống cơ sở dữ liệu với các đặc điểm khác nhau, phù hợp với các mục đích khác nhau - làm thế nào bạn chọn cái nào để sử dụng? Có nhiều cách tiếp cận để caching, nhiều cách xây dựng chỉ mục tìm kiếm, v.v. - làm thế nào bạn lý luận về sự đánh đổi của chúng? Bạn cần tìm ra công cụ nào và cách tiếp cận nào phù hợp nhất với nhiệm vụ trong tầm tay, và có thể khó khăn khi kết hợp các công cụ khi bạn cần làm điều mà một công cụ đơn lẻ không thể làm một mình.
Cuốn sách này là hướng dẫn giúp bạn đưa ra quyết định về công nghệ nào nên sử dụng và cách kết hợp chúng. Như bạn sẽ thấy, không có một cách tiếp cận nào về cơ bản tốt hơn cách khác; mọi thứ đều có ưu và nhược điểm. Với cuốn sách này, bạn sẽ học cách đặt ra các câu hỏi đúng để đánh giá và so sánh các hệ thống dữ liệu, để bạn có thể tìm ra cách tiếp cận nào sẽ phục vụ tốt nhất cho nhu cầu của ứng dụng cụ thể của bạn.
Chúng ta sẽ bắt đầu hành trình bằng cách xem xét một số cách dữ liệu thường được sử dụng trong các tổ chức ngày nay. Nhiều ý tưởng ở đây có nguồn gốc từ enterprise software (phần mềm doanh nghiệp), tức là nhu cầu phần mềm và thực hành kỹ thuật của các tổ chức lớn, như các tập đoàn và chính phủ lớn, vì trong lịch sử, chỉ có các tổ chức lớn mới có khối lượng dữ liệu lớn đòi hỏi các giải pháp kỹ thuật phức tạp. Nếu khối lượng dữ liệu của bạn đủ nhỏ, bạn có thể chỉ cần giữ nó trong một bảng tính! Tuy nhiên, gần đây cũng đã trở nên phổ biến hơn khi các công ty nhỏ hơn và các công ty khởi nghiệp quản lý khối lượng dữ liệu lớn và xây dựng các hệ thống thâm dụng dữ liệu.
Một trong những thách thức chính với các hệ thống dữ liệu là những người khác nhau cần làm những việc rất khác nhau với dữ liệu. Nếu bạn đang làm việc tại một công ty, bạn và nhóm của bạn sẽ có một tập ưu tiên, trong khi một nhóm khác có thể có mục tiêu hoàn toàn khác, dù bạn có thể đang làm việc với cùng một bộ dữ liệu! Hơn nữa, những mục tiêu đó có thể không được trình bày rõ ràng, điều này có thể dẫn đến hiểu lầm và bất đồng về cách tiếp cận đúng đắn.
Để giúp bạn hiểu những lựa chọn nào bạn có thể thực hiện, chương này so sánh một số khái niệm trái chiều nhau và khám phá sự đánh đổi của chúng:
- sự khác biệt giữa hệ thống vận hành và hệ thống phân tích (“Hệ thống Phân tích so với Hệ thống Vận hành”);
- ưu và nhược điểm của dịch vụ đám mây và hệ thống tự vận hành (“Đám mây so với Tự vận hành”);
- khi nào nên chuyển từ hệ thống đơn nút sang hệ thống phân tán (“Hệ thống Phân tán so với Hệ thống Đơn nút”); và
- cân bằng nhu cầu của doanh nghiệp và quyền của người dùng (“Hệ thống Dữ liệu, Pháp luật và Xã hội”).
Hơn nữa, chương này sẽ cung cấp cho bạn các thuật ngữ mà chúng ta sẽ cần cho phần còn lại của cuốn sách.
THUẬT NGỮ: FRONTEND VÀ BACKEND
Phần lớn những gì chúng ta sẽ thảo luận trong cuốn sách này liên quan đến backend development (phát triển phía máy chủ). Để giải thích thuật ngữ đó: đối với các ứng dụng web, mã phía client (chạy trong trình duyệt web) được gọi là frontend (giao diện phía người dùng), và mã phía máy chủ xử lý các yêu cầu của người dùng được gọi là backend (logic phía máy chủ). Các ứng dụng di động tương tự như frontend ở chỗ chúng cung cấp giao diện người dùng, thường giao tiếp qua Internet với backend phía máy chủ. Frontend đôi khi quản lý dữ liệu cục bộ trên thiết bị của người dùng 2, nhưng những thách thức hạ tầng dữ liệu lớn nhất thường nằm ở backend: một frontend chỉ cần xử lý dữ liệu của một người dùng, trong khi backend quản lý dữ liệu thay mặt cho tất cả người dùng.
Một dịch vụ backend thường có thể truy cập qua HTTP (đôi khi là WebSocket); nó thường bao gồm một số mã ứng dụng đọc và ghi dữ liệu trong một hoặc nhiều cơ sở dữ liệu, và đôi khi giao tiếp với các hệ thống dữ liệu bổ sung như cache hoặc hàng đợi thông điệp (mà chúng ta có thể gọi chung là data infrastructure - hạ tầng dữ liệu). Mã ứng dụng thường là stateless (không trạng thái), tức là khi nó hoàn thành xử lý một yêu cầu HTTP, nó quên tất cả mọi thứ về yêu cầu đó, và bất kỳ thông tin nào cần được duy trì từ yêu cầu này sang yêu cầu khác cần được lưu trữ trên client hoặc trong hạ tầng dữ liệu phía máy chủ.
Hệ thống Phân tích so với Hệ thống Vận hành
Nếu bạn đang làm việc với các hệ thống dữ liệu trong doanh nghiệp, bạn có thể sẽ gặp một số kiểu người khác nhau làm việc với dữ liệu. Kiểu đầu tiên là backend engineers (kỹ sư backend) - những người xây dựng các dịch vụ xử lý các yêu cầu đọc và cập nhật dữ liệu; các dịch vụ này thường phục vụ người dùng bên ngoài, trực tiếp hoặc gián tiếp qua các dịch vụ khác (xem “Microservices và Serverless”). Đôi khi các dịch vụ dành cho sử dụng nội bộ bởi các bộ phận khác của tổ chức.
Ngoài các nhóm quản lý dịch vụ backend, hai nhóm người khác thường cần truy cập vào dữ liệu của tổ chức: business analysts (nhà phân tích kinh doanh), những người tạo báo cáo về các hoạt động của tổ chức để giúp ban quản lý đưa ra quyết định tốt hơn (business intelligence hay BI), và data scientists (nhà khoa học dữ liệu), những người tìm kiếm những hiểu biết mới trong dữ liệu hoặc tạo ra các tính năng sản phẩm hướng đến người dùng được hỗ trợ bởi phân tích dữ liệu và học máy/AI (ví dụ, gợi ý “người mua X cũng mua Y” trên trang web thương mại điện tử, phân tích dự đoán như tính điểm rủi ro hoặc lọc thư rác, và xếp hạng kết quả tìm kiếm).
Mặc dù các nhà phân tích kinh doanh và nhà khoa học dữ liệu có xu hướng sử dụng các công cụ khác nhau và hoạt động theo những cách khác nhau, họ có một số điểm chung: cả hai đều thực hiện analytics (phân tích), có nghĩa là họ xem xét dữ liệu mà người dùng và các dịch vụ backend đã tạo ra, nhưng họ thường không sửa đổi dữ liệu này (ngoại trừ có thể để sửa lỗi). Họ có thể tạo ra các bộ dữ liệu dẫn xuất trong đó dữ liệu gốc đã được xử lý theo một cách nào đó. Điều này dẫn đến sự phân chia giữa hai loại hệ thống - một sự phân biệt mà chúng ta sẽ sử dụng xuyên suốt cuốn sách này:
- Operational systems (hệ thống vận hành) bao gồm các dịch vụ backend và hạ tầng dữ liệu nơi dữ liệu được tạo ra, ví dụ bằng cách phục vụ người dùng bên ngoài. Ở đây, mã ứng dụng vừa đọc vừa sửa đổi dữ liệu trong cơ sở dữ liệu của nó, dựa trên các hành động được thực hiện bởi người dùng.
- Analytical systems (hệ thống phân tích) phục vụ nhu cầu của các nhà phân tích kinh doanh và nhà khoa học dữ liệu. Chúng chứa một bản sao chỉ đọc của dữ liệu từ các hệ thống vận hành, và được tối ưu hóa cho các loại xử lý dữ liệu cần thiết cho phân tích.
Như chúng ta sẽ thấy trong phần tiếp theo, các hệ thống vận hành và phân tích thường được tách biệt, vì những lý do chính đáng. Khi các hệ thống này trưởng thành, hai vai trò chuyên biệt mới đã xuất hiện: data engineers (kỹ sư dữ liệu) và analytics engineers (kỹ sư phân tích). Kỹ sư dữ liệu là những người biết cách tích hợp các hệ thống vận hành và phân tích, và chịu trách nhiệm về hạ tầng dữ liệu của tổ chức rộng hơn 3. Kỹ sư phân tích mô hình hóa và biến đổi dữ liệu để làm cho nó hữu ích hơn cho các nhà phân tích kinh doanh và nhà khoa học dữ liệu trong một tổ chức 4.
Nhiều kỹ sư chuyên về phía vận hành hoặc phía phân tích. Tuy nhiên, cuốn sách này bao quát cả hai hệ thống dữ liệu vận hành và phân tích, vì cả hai đều đóng vai trò quan trọng trong vòng đời của dữ liệu trong một tổ chức. Chúng ta sẽ khám phá chuyên sâu hạ tầng dữ liệu được sử dụng để cung cấp dịch vụ cho cả người dùng nội bộ và bên ngoài, để bạn có thể làm việc tốt hơn với đồng nghiệp ở phía kia của sự phân chia này.
Đặc trưng của Xử lý Giao dịch và Phân tích
Trong những ngày đầu của xử lý dữ liệu kinh doanh, một thao tác ghi vào cơ sở dữ liệu thường tương ứng với một giao dịch thương mại đang diễn ra: thực hiện một giao dịch bán hàng, đặt hàng từ nhà cung cấp, trả lương nhân viên, v.v. Khi cơ sở dữ liệu mở rộng sang các lĩnh vực không liên quan đến chuyển đổi tiền tệ, thuật ngữ transaction (giao dịch) vẫn giữ nguyên, đề cập đến một nhóm các thao tác đọc và ghi tạo thành một đơn vị logic.
Note
Chương 8 khám phá chi tiết ý nghĩa của chúng ta với một giao dịch. Chương này sử dụng thuật ngữ theo nghĩa rộng để đề cập đến các thao tác đọc và ghi có độ trễ thấp.
Mặc dù cơ sở dữ liệu bắt đầu được sử dụng cho nhiều loại dữ liệu khác nhau - bài đăng trên mạng xã hội, nước đi trong trò chơi, danh bạ địa chỉ, và nhiều loại khác - mẫu truy cập cơ bản vẫn tương tự như xử lý các giao dịch kinh doanh. Một hệ thống vận hành thường tra cứu một số lượng nhỏ bản ghi theo một số khóa (đây được gọi là point query - truy vấn điểm). Các bản ghi được chèn, cập nhật hoặc xóa dựa trên đầu vào của người dùng. Vì các ứng dụng này có tính tương tác, mẫu truy cập này được gọi là online transaction processing (OLTP - xử lý giao dịch trực tuyến).
Tuy nhiên, cơ sở dữ liệu cũng ngày càng được sử dụng nhiều hơn cho phân tích, với các mẫu truy cập rất khác so với OLTP. Thông thường một truy vấn phân tích quét qua một số lượng lớn bản ghi và tính toán số liệu thống kê tổng hợp (như đếm, tổng hoặc trung bình) thay vì trả về các bản ghi riêng lẻ cho người dùng. Ví dụ, một nhà phân tích kinh doanh tại một chuỗi siêu thị có thể muốn trả lời các truy vấn phân tích như:
- Tổng doanh thu của mỗi cửa hàng trong tháng Giêng là bao nhiêu?
- Trong đợt khuyến mãi mới nhất, chúng ta bán thêm bao nhiêu chuối so với thông thường?
- Nhãn hiệu thức ăn trẻ em nào thường được mua cùng với tã Pampers nhãn hiệu X nhất?
Các báo cáo từ các loại truy vấn này rất quan trọng cho business intelligence (thông minh kinh doanh), giúp ban quản lý quyết định phải làm gì tiếp theo. Để phân biệt mẫu sử dụng cơ sở dữ liệu này với xử lý giao dịch, nó được gọi là online analytic processing (OLAP - xử lý phân tích trực tuyến) 5. Sự khác biệt giữa OLTP và phân tích không phải lúc nào cũng rõ ràng, nhưng một số đặc điểm điển hình được liệt kê trong Bảng 1-1.
Bảng 1-1. So sánh đặc điểm của hệ thống vận hành và hệ thống phân tích
| Thuộc tính | Hệ thống vận hành (OLTP) | Hệ thống phân tích (OLAP) |
|---|---|---|
| Mẫu đọc chính | Truy vấn điểm (lấy bản ghi riêng lẻ theo khóa) | Tổng hợp trên số lượng lớn bản ghi |
| Mẫu ghi chính | Tạo, cập nhật và xóa các bản ghi riêng lẻ | Nhập hàng loạt (ETL) hoặc luồng sự kiện |
| Ví dụ người dùng người | Người dùng cuối của ứng dụng web/di động | Nhà phân tích nội bộ, phục vụ hỗ trợ quyết định |
| Ví dụ sử dụng máy | Kiểm tra xem một hành động có được ủy quyền không | Phát hiện các mẫu gian lận/lạm dụng |
| Loại truy vấn | Tập truy vấn cố định, được xác định trước bởi ứng dụng | Nhà phân tích có thể thực hiện các truy vấn tùy ý |
| Dữ liệu biểu diễn | Trạng thái mới nhất của dữ liệu (thời điểm hiện tại) | Lịch sử các sự kiện đã xảy ra theo thời gian |
| Kích thước bộ dữ liệu | Gigabyte đến terabyte | Terabyte đến petabyte |
Note
Ý nghĩa của online trong OLAP không rõ ràng; nó có lẽ đề cập đến thực tế rằng các truy vấn không chỉ dành cho các báo cáo được xác định trước, mà các nhà phân tích sử dụng hệ thống OLAP một cách tương tác cho các truy vấn khám phá.
Với các hệ thống vận hành, người dùng thường không được phép xây dựng các truy vấn SQL tùy chỉnh và chạy chúng trên cơ sở dữ liệu, vì điều đó có thể cho phép họ đọc hoặc sửa đổi dữ liệu mà họ không có quyền truy cập. Hơn nữa, họ có thể viết các truy vấn tốn kém để thực thi, và do đó ảnh hưởng đến hiệu suất cơ sở dữ liệu cho những người dùng khác. Vì những lý do này, các hệ thống OLTP chủ yếu chạy một tập truy vấn cố định được nhúng vào mã ứng dụng, và chỉ sử dụng các truy vấn tùy chỉnh một lần cho việc bảo trì hoặc khắc phục sự cố. Mặt khác, các cơ sở dữ liệu phân tích thường cho người dùng tự do viết các truy vấn SQL tùy ý bằng tay, hoặc tạo truy vấn tự động bằng cách sử dụng công cụ trực quan hóa dữ liệu hoặc dashboard như Tableau, Looker, hoặc Microsoft Power BI.
Cũng có một loại hệ thống được thiết kế cho khối lượng công việc phân tích (các truy vấn tổng hợp trên nhiều bản ghi) nhưng được nhúng vào các sản phẩm hướng đến người dùng. Danh mục này được gọi là product analytics (phân tích sản phẩm) hoặc real-time analytics (phân tích thời gian thực), và các hệ thống được thiết kế cho loại sử dụng này bao gồm Pinot, Druid và ClickHouse 6.
Kho Dữ liệu
Ban đầu, cùng một cơ sở dữ liệu được sử dụng cho cả xử lý giao dịch và truy vấn phân tích. SQL hóa ra khá linh hoạt trong vấn đề này: nó hoạt động tốt cho cả hai loại truy vấn. Tuy nhiên, vào cuối những năm 1980 và đầu những năm 1990, có xu hướng các công ty ngừng sử dụng hệ thống OLTP của họ cho mục đích phân tích, và thay vào đó chạy phân tích trên một hệ thống cơ sở dữ liệu riêng biệt. Cơ sở dữ liệu riêng biệt này được gọi là data warehouse (kho dữ liệu).
Một doanh nghiệp lớn có thể có hàng chục, thậm chí hàng trăm hệ thống xử lý giao dịch trực tuyến: các hệ thống hỗ trợ trang web khách hàng, kiểm soát hệ thống điểm bán hàng (thanh toán) tại các cửa hàng thực, theo dõi hàng tồn kho trong kho, lập kế hoạch tuyến đường cho xe cộ, quản lý nhà cung cấp, quản lý nhân viên, và thực hiện nhiều nhiệm vụ khác. Mỗi hệ thống này phức tạp và cần một nhóm người để duy trì, vì vậy các hệ thống này cuối cùng hoạt động chủ yếu độc lập với nhau.
Thường thì không mong muốn cho các nhà phân tích kinh doanh và nhà khoa học dữ liệu trực tiếp truy vấn các hệ thống OLTP này, vì một số lý do:
- dữ liệu quan tâm có thể trải rộng trên nhiều hệ thống vận hành, khiến việc kết hợp các bộ dữ liệu đó trong một truy vấn duy nhất trở nên khó khăn (một vấn đề được gọi là data silos - silos dữ liệu);
- các loại schema và bố cục dữ liệu phù hợp cho OLTP ít phù hợp hơn cho phân tích (xem “Ngôi sao và Bông tuyết: Schema cho Phân tích”);
- các truy vấn phân tích có thể khá tốn kém, và chạy chúng trên cơ sở dữ liệu OLTP sẽ ảnh hưởng đến hiệu suất cho những người dùng khác; và
- các hệ thống OLTP có thể nằm trong một mạng riêng mà người dùng không được phép truy cập trực tiếp vì lý do bảo mật hoặc tuân thủ quy định.
Ngược lại, một data warehouse (kho dữ liệu) là một cơ sở dữ liệu riêng biệt mà các nhà phân tích có thể truy vấn thoải mái, mà không ảnh hưởng đến các hoạt động OLTP 7. Như chúng ta sẽ thấy trong Chương 4, kho dữ liệu thường lưu trữ dữ liệu theo cách rất khác so với cơ sở dữ liệu OLTP, để tối ưu hóa cho các loại truy vấn phổ biến trong phân tích.
Kho dữ liệu chứa một bản sao chỉ đọc của dữ liệu trong tất cả các hệ thống OLTP khác nhau trong công ty. Dữ liệu được trích xuất từ cơ sở dữ liệu OLTP (sử dụng xuất dữ liệu định kỳ hoặc luồng cập nhật liên tục), được biến đổi thành schema thân thiện với phân tích, được làm sạch, và sau đó được tải vào kho dữ liệu. Quá trình đưa dữ liệu vào kho dữ liệu này được gọi là Extract-Transform-Load (ETL) và được minh họa trong Hình 1-1. Đôi khi thứ tự của các bước transform và load bị hoán đổi (tức là việc biến đổi được thực hiện trong kho dữ liệu, sau khi tải), dẫn đến ELT.
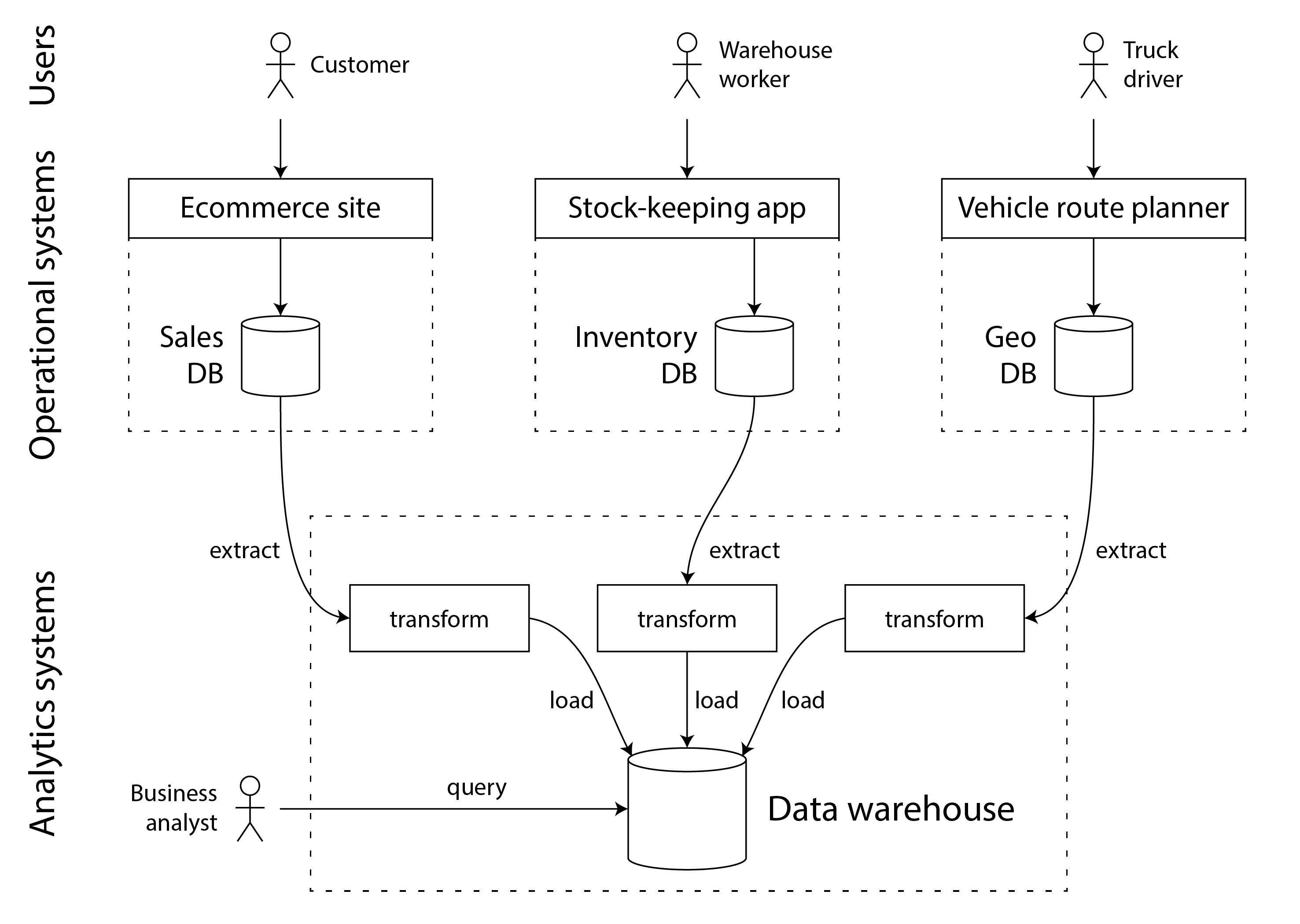
Trong một số trường hợp, các nguồn dữ liệu của quy trình ETL là các sản phẩm SaaS bên ngoài như hệ thống quản lý quan hệ khách hàng (CRM), tiếp thị qua email, hoặc hệ thống xử lý thẻ tín dụng. Trong những trường hợp đó, bạn không có quyền truy cập trực tiếp vào cơ sở dữ liệu gốc, vì nó chỉ có thể truy cập qua API của nhà cung cấp phần mềm. Đưa dữ liệu từ các hệ thống bên ngoài này vào kho dữ liệu của riêng bạn có thể cho phép các phân tích không thể thực hiện được qua API SaaS. ETL cho các API SaaS thường được triển khai bởi các dịch vụ kết nối dữ liệu chuyên biệt như Fivetran, Singer, hoặc AirByte.
Một số hệ thống cơ sở dữ liệu cung cấp hybrid transactional/analytic processing (HTAP - xử lý giao dịch/phân tích kết hợp), nhằm mục đích cho phép OLTP và phân tích trong một hệ thống duy nhất mà không cần ETL từ hệ thống này sang hệ thống khác 8 9. Tuy nhiên, nhiều hệ thống HTAP bên trong bao gồm một hệ thống OLTP kết hợp với một hệ thống phân tích riêng biệt, ẩn đằng sau một giao diện chung - vì vậy sự phân biệt giữa hai loại vẫn quan trọng để hiểu cách các hệ thống này hoạt động.
Hơn nữa, mặc dù HTAP tồn tại, việc có sự tách biệt giữa các hệ thống giao dịch và phân tích là phổ biến do các mục tiêu và yêu cầu khác nhau của chúng. Đặc biệt, được coi là thực hành tốt khi mỗi hệ thống vận hành có cơ sở dữ liệu riêng (xem “Microservices và Serverless”), dẫn đến hàng trăm cơ sở dữ liệu vận hành riêng biệt; mặt khác, một doanh nghiệp thường có một kho dữ liệu duy nhất, để các nhà phân tích kinh doanh có thể kết hợp dữ liệu từ nhiều hệ thống vận hành trong một truy vấn duy nhất.
Do đó, HTAP không thay thế kho dữ liệu. Thay vào đó, nó hữu ích trong các tình huống mà cùng một ứng dụng cần vừa thực hiện các truy vấn phân tích quét một số lượng lớn hàng, vừa đọc và cập nhật các bản ghi riêng lẻ với độ trễ thấp. Phát hiện gian lận có thể liên quan đến các khối lượng công việc như vậy, chẳng hạn 10.
Sự tách biệt giữa hệ thống vận hành và phân tích là một phần của xu hướng rộng hơn: khi khối lượng công việc trở nên khó khăn hơn, các hệ thống trở nên chuyên biệt hơn và được tối ưu hóa cho các khối lượng công việc cụ thể. Các hệ thống đa mục đích có thể xử lý khối lượng dữ liệu nhỏ một cách thoải mái, nhưng quy mô càng lớn, các hệ thống càng có xu hướng chuyên biệt hơn 11.
Từ kho dữ liệu đến hồ dữ liệu
Một kho dữ liệu thường sử dụng mô hình dữ liệu relational (quan hệ) được truy vấn qua SQL (xem Chương 3), có thể sử dụng phần mềm business intelligence chuyên biệt. Mô hình này hoạt động tốt cho các loại truy vấn mà các nhà phân tích kinh doanh cần thực hiện, nhưng ít phù hợp hơn với nhu cầu của các nhà khoa học dữ liệu, những người có thể cần thực hiện các nhiệm vụ như:
- Biến đổi dữ liệu thành dạng phù hợp để huấn luyện mô hình học máy; thường điều này đòi hỏi phải chuyển các hàng và cột của bảng cơ sở dữ liệu thành một vector hoặc ma trận các giá trị số được gọi là features (đặc trưng). Quá trình thực hiện phép biến đổi này theo cách tối đa hóa hiệu suất của mô hình đã huấn luyện được gọi là feature engineering (kỹ thuật đặc trưng), và thường đòi hỏi mã tùy chỉnh khó diễn đạt bằng SQL.
- Lấy dữ liệu văn bản (ví dụ, đánh giá về một sản phẩm) và sử dụng các kỹ thuật xử lý ngôn ngữ tự nhiên để cố gắng trích xuất thông tin có cấu trúc từ nó (ví dụ, cảm xúc của tác giả, hoặc chủ đề nào họ đề cập đến). Tương tự, họ có thể cần trích xuất thông tin có cấu trúc từ ảnh bằng cách sử dụng các kỹ thuật thị giác máy tính.
Mặc dù đã có những nỗ lực để thêm các toán tử học máy vào mô hình dữ liệu SQL 12 và xây dựng các hệ thống học máy hiệu quả trên nền tảng quan hệ 13, nhiều nhà khoa học dữ liệu không thích làm việc trong cơ sở dữ liệu quan hệ như kho dữ liệu. Thay vào đó, nhiều người thích sử dụng các thư viện phân tích dữ liệu Python như pandas và scikit-learn, các ngôn ngữ phân tích thống kê như R, và các framework phân tích phân tán như Spark 14. Chúng ta thảo luận thêm về những điều này trong “Dataframes, Ma trận và Mảng”.
Do đó, các tổ chức phải đối mặt với nhu cầu cung cấp dữ liệu ở dạng phù hợp để sử dụng bởi các nhà khoa học dữ liệu. Câu trả lời là data lake (hồ dữ liệu): một kho lưu trữ dữ liệu tập trung chứa bản sao của bất kỳ dữ liệu nào có thể hữu ích cho phân tích, thu được từ các hệ thống vận hành qua các quy trình ETL. Sự khác biệt so với kho dữ liệu là hồ dữ liệu chỉ đơn giản là chứa các tệp, mà không áp đặt bất kỳ định dạng tệp hoặc mô hình dữ liệu cụ thể nào. Các tệp trong hồ dữ liệu có thể là các tập hợp bản ghi cơ sở dữ liệu, được mã hóa bằng định dạng tệp như Avro hoặc Parquet (xem Chương 5), nhưng chúng cũng có thể chứa văn bản, hình ảnh, video, dữ liệu cảm biến, ma trận thưa, vector đặc trưng, trình tự bộ gen, hoặc bất kỳ loại dữ liệu nào khác 15. Ngoài việc linh hoạt hơn, điều này thường cũng rẻ hơn so với lưu trữ dữ liệu quan hệ, vì hồ dữ liệu có thể sử dụng lưu trữ tệp được hàng hóa hóa như các object store (xem “Kiến trúc Hệ thống Cloud-Native”).
Các quy trình ETL đã được tổng quát hóa thành data pipelines (đường ống dữ liệu), và trong một số trường hợp hồ dữ liệu đã trở thành một trạm dừng trung gian trên con đường từ các hệ thống vận hành đến kho dữ liệu. Hồ dữ liệu chứa dữ liệu ở dạng “thô” do các hệ thống vận hành tạo ra, mà không có sự biến đổi thành schema kho dữ liệu quan hệ. Cách tiếp cận này có ưu điểm là mỗi người dùng dữ liệu có thể biến đổi dữ liệu thô thành dạng phù hợp nhất với nhu cầu của họ. Cách này được gọi là sushi principle (nguyên tắc sushi): “raw data is better” (dữ liệu thô tốt hơn) 16.
Ngoài việc tải dữ liệu từ hồ dữ liệu vào một kho dữ liệu riêng biệt, cũng có thể chạy các khối lượng công việc kho dữ liệu điển hình (truy vấn SQL và phân tích kinh doanh) trực tiếp trên các tệp trong hồ dữ liệu, cùng với các khối lượng công việc khoa học dữ liệu/học máy. Kiến trúc này được gọi là data lakehouse (nhà kho hồ dữ liệu), và nó đòi hỏi một engine thực thi truy vấn và một lớp metadata (ví dụ, quản lý schema) mở rộng lưu trữ tệp của hồ dữ liệu 17.
Apache Hive, Spark SQL, Presto, và Trino là các ví dụ của cách tiếp cận này.
Ngoài hồ dữ liệu
Khi các thực hành phân tích đã trưởng thành, các tổ chức ngày càng chú ý hơn đến việc quản lý và vận hành các hệ thống phân tích và đường ống dữ liệu, như được thể hiện chẳng hạn trong bản tuyên ngôn DataOps 18. Một phần của điều này là các vấn đề về quản trị, quyền riêng tư và tuân thủ quy định như GDPR và CCPA, mà chúng ta thảo luận trong “Hệ thống Dữ liệu, Pháp luật và Xã hội” và “Pháp luật và Tự điều tiết”.
Hơn nữa, dữ liệu phân tích ngày càng được cung cấp không chỉ dưới dạng tệp và bảng quan hệ, mà còn dưới dạng các luồng sự kiện (xem Chương 12). Với phân tích dữ liệu dựa trên tệp, bạn có thể chạy lại phân tích định kỳ (ví dụ, hàng ngày) để phản ứng với các thay đổi trong dữ liệu, nhưng xử lý luồng cho phép các hệ thống phân tích phản ứng với các sự kiện nhanh hơn nhiều, trong vòng vài giây. Tùy thuộc vào ứng dụng và mức độ nhạy cảm với thời gian của nó, cách tiếp cận xử lý luồng có thể có giá trị, ví dụ để xác định và chặn hoạt động gian lận hoặc lạm dụng tiềm ẩn.
Trong một số trường hợp, kết quả đầu ra của các hệ thống phân tích được cung cấp cho các hệ thống vận hành (một quá trình đôi khi được gọi là reverse ETL 19). Ví dụ, một mô hình học máy được huấn luyện trên dữ liệu trong hệ thống phân tích có thể được triển khai vào production, để nó có thể tạo ra các gợi ý cho người dùng cuối, như “người mua X cũng mua Y”. Các kết quả đầu ra như vậy của hệ thống phân tích cũng được gọi là data products (sản phẩm dữ liệu) 20. Các mô hình học máy có thể được triển khai vào các hệ thống vận hành bằng cách sử dụng các công cụ chuyên biệt như TFX, Kubeflow, hoặc MLflow.
Hệ thống Gốc và Dữ liệu Dẫn xuất
Liên quan đến sự phân biệt giữa hệ thống vận hành và phân tích, cuốn sách này cũng phân biệt giữa systems of record (hệ thống gốc) và derived data systems (hệ thống dữ liệu dẫn xuất). Các thuật ngữ này hữu ích vì chúng có thể giúp bạn làm rõ luồng dữ liệu qua một hệ thống:
- Hệ thống gốc (Systems of record)
- Một hệ thống gốc, còn được gọi là source of truth (nguồn sự thật), giữ phiên bản có thẩm quyền hoặc canonical (chuẩn) của một số dữ liệu. Khi dữ liệu mới đến, ví dụ như đầu vào của người dùng, nó được ghi đầu tiên vào đây. Mỗi sự thật được biểu diễn chính xác một lần (biểu diễn thường là normalized - chuẩn hóa; xem “Chuẩn hóa, Phi chuẩn hóa và Join”). Nếu có bất kỳ sự khác biệt nào giữa hệ thống khác và hệ thống gốc, thì giá trị trong hệ thống gốc là (theo định nghĩa) giá trị đúng.
- Hệ thống dữ liệu dẫn xuất (Derived data systems)
- Dữ liệu trong hệ thống dẫn xuất là kết quả của việc lấy một số dữ liệu hiện có từ hệ thống khác và biến đổi hoặc xử lý nó theo một cách nào đó. Nếu bạn mất dữ liệu dẫn xuất, bạn có thể tạo lại nó từ nguồn gốc. Một ví dụ điển hình là cache: dữ liệu có thể được phục vụ từ cache nếu có, nhưng nếu cache không chứa những gì bạn cần, bạn có thể quay lại cơ sở dữ liệu cơ bản. Các giá trị phi chuẩn hóa, chỉ mục, materialized view, biểu diễn dữ liệu đã biến đổi, và các mô hình được huấn luyện trên bộ dữ liệu cũng thuộc danh mục này.
Về mặt kỹ thuật, dữ liệu dẫn xuất là redundant (dư thừa), theo nghĩa là nó sao chép thông tin hiện có. Tuy nhiên, nó thường thiết yếu để đạt được hiệu suất tốt trên các truy vấn đọc. Bạn có thể dẫn xuất nhiều bộ dữ liệu khác nhau từ một nguồn duy nhất, cho phép bạn nhìn dữ liệu từ các “góc nhìn” khác nhau.
Các hệ thống phân tích thường là hệ thống dữ liệu dẫn xuất, vì chúng là người tiêu thụ dữ liệu được tạo ra ở nơi khác. Các dịch vụ vận hành có thể chứa hỗn hợp các hệ thống gốc và hệ thống dữ liệu dẫn xuất. Các hệ thống gốc là cơ sở dữ liệu chính mà dữ liệu được ghi đầu tiên, trong khi các hệ thống dữ liệu dẫn xuất là các chỉ mục và cache tăng tốc các thao tác đọc phổ biến, đặc biệt cho các truy vấn mà hệ thống gốc không thể trả lời hiệu quả.
Hầu hết các cơ sở dữ liệu, engine lưu trữ và ngôn ngữ truy vấn về bản chất không phải là hệ thống gốc hay hệ thống dẫn xuất. Cơ sở dữ liệu chỉ là một công cụ: cách bạn sử dụng nó tùy thuộc vào bạn. Sự phân biệt giữa hệ thống gốc và hệ thống dữ liệu dẫn xuất không phụ thuộc vào công cụ, mà phụ thuộc vào cách bạn sử dụng nó trong ứng dụng của mình. Bằng cách làm rõ dữ liệu nào được dẫn xuất từ dữ liệu nào khác, bạn có thể mang lại sự rõ ràng cho một kiến trúc hệ thống vốn gây nhầm lẫn.
Khi dữ liệu trong một hệ thống được dẫn xuất từ dữ liệu trong hệ thống khác, bạn cần một quy trình để cập nhật dữ liệu dẫn xuất khi dữ liệu gốc trong hệ thống gốc thay đổi. Thật không may, nhiều cơ sở dữ liệu được thiết kế dựa trên giả định rằng ứng dụng của bạn chỉ cần sử dụng một cơ sở dữ liệu đó, và chúng không làm cho việc tích hợp nhiều hệ thống để truyền bá các cập nhật như vậy trở nên dễ dàng. Trong “Tích hợp Dữ liệu”, chúng ta sẽ thảo luận các cách tiếp cận để data integration (tích hợp dữ liệu), cho phép chúng ta kết hợp nhiều hệ thống dữ liệu để đạt được những điều mà một hệ thống đơn lẻ không thể làm một mình.
Điều đó đưa chúng ta đến cuối so sánh giữa phân tích và xử lý giao dịch. Trong phần tiếp theo, chúng ta sẽ xem xét một sự đánh đổi khác mà bạn có thể đã thấy được tranh luận nhiều lần.
Đám mây so với Tự vận hành
Với bất kỳ điều gì mà một tổ chức cần thực hiện, một trong những câu hỏi đầu tiên là: nên thực hiện nội bộ, hay nên thuê ngoài? Nên xây dựng hay nên mua?
Cuối cùng, đây là câu hỏi về ưu tiên kinh doanh. Triết lý quản lý thông thường là những thứ là năng lực cốt lõi hoặc lợi thế cạnh tranh của tổ chức bạn nên được thực hiện nội bộ, trong khi những thứ không phải cốt lõi, thông thường hoặc phổ biến nên được giao cho nhà cung cấp 21. Để đưa ra một ví dụ cực đoan, hầu hết các công ty không tự sản xuất điện (trừ khi họ là công ty năng lượng, và bỏ qua nguồn điện dự phòng khẩn cấp), vì mua điện từ lưới điện rẻ hơn.
Với phần mềm, hai quyết định quan trọng cần được thực hiện là ai xây dựng phần mềm và ai triển khai nó. Có một phổ các khả năng thuê ngoài mỗi quyết định ở các mức độ khác nhau, như được minh họa trong Hình 1-2. Ở một đầu cực đoan là phần mềm tùy chỉnh mà bạn viết và chạy nội bộ; ở đầu cực đoan kia là các dịch vụ đám mây được sử dụng rộng rãi hoặc các sản phẩm Software as a Service (SaaS) được triển khai và vận hành bởi nhà cung cấp bên ngoài, và chỉ có thể truy cập qua giao diện web hoặc API.

Điểm trung gian là phần mềm có sẵn (mã nguồn mở hoặc thương mại) mà bạn tự vận hành, tức là tự triển khai - ví dụ, nếu bạn tải xuống MySQL và cài đặt nó trên máy chủ bạn kiểm soát. Điều này có thể trên phần cứng của riêng bạn (thường được gọi là on-premises - tại chỗ, ngay cả khi máy chủ thực sự ở trong một rack datacenter thuê và không thực sự ở cơ sở của bạn), hoặc trên một máy ảo trong đám mây (Infrastructure as a Service hay IaaS). Vẫn còn nhiều điểm hơn dọc theo phổ này, ví dụ, lấy phần mềm mã nguồn mở và chạy phiên bản sửa đổi của nó.
Tách biệt với phổ này còn có câu hỏi về cách bạn triển khai dịch vụ, dù trên đám mây hay tại chỗ - ví dụ, liệu bạn có sử dụng framework điều phối như Kubernetes hay không. Tuy nhiên, lựa chọn công cụ triển khai nằm ngoài phạm vi của cuốn sách này, vì các yếu tố khác có ảnh hưởng lớn hơn đến kiến trúc của các hệ thống dữ liệu.
Ưu và Nhược điểm của Dịch vụ Đám mây
Sử dụng dịch vụ đám mây, thay vì tự chạy phần mềm tương tự, về cơ bản là thuê ngoài việc vận hành phần mềm đó cho nhà cung cấp đám mây. Có những lập luận tốt cả ủng hộ và phản đối dịch vụ đám mây. Các nhà cung cấp đám mây tuyên bố rằng sử dụng dịch vụ của họ giúp bạn tiết kiệm thời gian và tiền bạc, và cho phép bạn di chuyển nhanh hơn so với việc thiết lập cơ sở hạ tầng của riêng bạn.
Liệu một dịch vụ đám mây có thực sự rẻ hơn và dễ hơn so với tự vận hành hay không phụ thuộc rất nhiều vào kỹ năng của bạn và khối lượng công việc trên hệ thống của bạn. Nếu bạn đã có kinh nghiệm thiết lập và vận hành các hệ thống bạn cần, và nếu tải của bạn khá có thể dự đoán (tức là số lượng máy bạn cần không biến động nhiều), thì việc mua máy của riêng bạn và tự chạy phần mềm thường rẻ hơn 22 23.
Mặt khác, nếu bạn cần một hệ thống mà bạn chưa biết cách triển khai và vận hành, thì việc áp dụng dịch vụ đám mây thường dễ dàng và nhanh hơn so với việc học cách tự quản lý hệ thống. Nếu bạn phải tuyển dụng và đào tạo nhân viên đặc biệt để duy trì và vận hành hệ thống, điều đó có thể rất tốn kém. Bạn vẫn cần một nhóm vận hành khi sử dụng đám mây (xem “Vận hành trong Kỷ nguyên Đám mây”), nhưng việc thuê ngoài quản trị hệ thống cơ bản có thể giải phóng nhóm của bạn để tập trung vào các vấn đề cấp cao hơn.
Khi bạn thuê ngoài việc vận hành một hệ thống cho công ty chuyên cung cấp dịch vụ đó, điều đó có thể dẫn đến dịch vụ tốt hơn, vì nhà cung cấp tích lũy chuyên môn vận hành từ việc cung cấp dịch vụ cho nhiều khách hàng. Mặt khác, nếu bạn tự chạy dịch vụ, bạn có thể cấu hình và tinh chỉnh nó để hoạt động tốt trên khối lượng công việc cụ thể của bạn; khó có khả năng một dịch vụ đám mây sẽ sẵn sàng thực hiện các tùy chỉnh như vậy thay mặt cho bạn.
Các dịch vụ đám mây đặc biệt có giá trị nếu tải trên hệ thống của bạn biến đổi nhiều theo thời gian. Nếu bạn cấp phát máy để có thể xử lý tải đỉnh, nhưng các tài nguyên máy tính đó nhàn rỗi hầu hết thời gian, hệ thống trở nên kém hiệu quả về chi phí. Trong tình huống này, các dịch vụ đám mây có lợi thế là chúng có thể giúp dễ dàng mở rộng hoặc thu hẹp tài nguyên máy tính của bạn để đáp ứng các thay đổi trong nhu cầu.
Ví dụ, các hệ thống phân tích thường có tải biến đổi cực kỳ cao: chạy một truy vấn phân tích lớn nhanh chóng đòi hỏi nhiều tài nguyên máy tính song song, nhưng một khi truy vấn hoàn thành, các tài nguyên đó ngồi không cho đến khi người dùng thực hiện truy vấn tiếp theo. Các truy vấn được xác định trước (ví dụ, cho các báo cáo hàng ngày) có thể được xếp hàng đợi và lên lịch để làm phẳng tải, nhưng đối với các truy vấn tương tác, bạn muốn chúng hoàn thành càng nhanh thì khối lượng công việc càng biến đổi. Nếu bộ dữ liệu của bạn lớn đến mức truy vấn nhanh đòi hỏi tài nguyên máy tính đáng kể, sử dụng đám mây có thể tiết kiệm tiền, vì bạn có thể trả lại các tài nguyên không sử dụng cho nhà cung cấp thay vì để chúng nhàn rỗi. Đối với các bộ dữ liệu nhỏ hơn, sự khác biệt này ít quan trọng hơn.
Nhược điểm lớn nhất của dịch vụ đám mây là bạn không có quyền kiểm soát nó:
- Nếu nó thiếu một tính năng bạn cần, tất cả những gì bạn có thể làm là lịch sự yêu cầu nhà cung cấp xem họ có thêm nó không; thông thường bạn không thể tự triển khai nó.
- Nếu dịch vụ ngừng hoạt động, tất cả những gì bạn có thể làm là chờ đợi nó phục hồi.
- Nếu bạn đang sử dụng dịch vụ theo cách kích hoạt lỗi hoặc gây ra vấn đề hiệu suất, sẽ khó khăn cho bạn để chẩn đoán vấn đề. Với phần mềm bạn tự chạy, bạn có thể nhận số liệu hiệu suất và thông tin gỡ lỗi từ hệ điều hành để giúp bạn hiểu hành vi của nó, và bạn có thể xem nhật ký máy chủ, nhưng với dịch vụ được vận hành bởi nhà cung cấp, bạn thường không có quyền truy cập vào các nội bộ này.
- Hơn nữa, nếu dịch vụ đóng cửa hoặc trở nên quá đắt không thể chấp nhận, hoặc nếu nhà cung cấp quyết định thay đổi sản phẩm của họ theo cách bạn không thích, bạn ở thế họ muốn gì thì làm - tiếp tục chạy phiên bản cũ của phần mềm thường không phải là một lựa chọn, vì vậy bạn sẽ bị buộc phải di chuyển sang dịch vụ thay thế 24. Rủi ro này được giảm nhẹ nếu có các dịch vụ thay thế cung cấp API tương thích, nhưng đối với nhiều dịch vụ đám mây không có API tiêu chuẩn, điều này làm tăng chi phí chuyển đổi, khiến vendor lock-in (khóa nhà cung cấp) trở thành một vấn đề.
- Nhà cung cấp đám mây cần được tin tưởng để giữ dữ liệu an toàn, điều này có thể làm phức tạp quá trình tuân thủ các quy định về quyền riêng tư và bảo mật.
Mặc dù tất cả những rủi ro này, ngày càng phổ biến hơn khi các tổ chức xây dựng ứng dụng mới trên các dịch vụ đám mây, hoặc áp dụng cách tiếp cận kết hợp trong đó các dịch vụ đám mây được sử dụng cho một số khía cạnh của hệ thống. Tuy nhiên, các dịch vụ đám mây sẽ không thay thế tất cả các hệ thống dữ liệu nội bộ: nhiều hệ thống cũ hơn xuất hiện trước đám mây, và đối với bất kỳ dịch vụ nào có yêu cầu chuyên biệt mà các dịch vụ đám mây hiện tại không đáp ứng được, các hệ thống nội bộ vẫn cần thiết. Ví dụ, các ứng dụng rất nhạy cảm với độ trễ như giao dịch tần số cao đòi hỏi toàn quyền kiểm soát phần cứng.
Kiến trúc Hệ thống Cloud-Native
Ngoài việc có mô hình kinh tế khác nhau (đăng ký dịch vụ thay vì mua phần cứng và cấp phép phần mềm để chạy trên đó), sự nổi lên của đám mây cũng có tác động sâu sắc đến cách các hệ thống dữ liệu được triển khai ở cấp độ kỹ thuật. Thuật ngữ cloud-native được sử dụng để mô tả kiến trúc được thiết kế để tận dụng các dịch vụ đám mây.
Về nguyên tắc, hầu hết mọi phần mềm bạn có thể tự vận hành cũng có thể được cung cấp như một dịch vụ đám mây, và thực sự các dịch vụ quản lý như vậy hiện có sẵn cho nhiều hệ thống dữ liệu phổ biến. Tuy nhiên, các hệ thống được thiết kế từ đầu để trở thành cloud-native đã được chứng minh có một số lợi thế: hiệu suất tốt hơn trên cùng phần cứng, phục hồi nhanh hơn sau lỗi, có thể nhanh chóng mở rộng tài nguyên máy tính để phù hợp với tải, và hỗ trợ các bộ dữ liệu lớn hơn 25 26 27. Bảng 1-2 liệt kê một số ví dụ về cả hai loại hệ thống.
Bảng 1-2. Ví dụ về hệ thống cơ sở dữ liệu tự vận hành và cloud-native
| Danh mục | Hệ thống tự vận hành | Hệ thống cloud-native |
|---|---|---|
| Vận hành/OLTP | MySQL, PostgreSQL, MongoDB | AWS Aurora 25, Azure SQL DB Hyperscale 26, Google Cloud Spanner |
| Phân tích/OLAP | Teradata, ClickHouse, Spark | Snowflake 27, Google BigQuery, Azure Synapse Analytics |
Phân lớp dịch vụ đám mây
Nhiều hệ thống dữ liệu tự vận hành có yêu cầu hệ thống rất đơn giản: chúng chạy trên hệ điều hành thông thường như Linux hoặc Windows, lưu trữ dữ liệu dưới dạng tệp trên filesystem, và giao tiếp qua các giao thức mạng tiêu chuẩn như TCP/IP. Một vài hệ thống phụ thuộc vào phần cứng đặc biệt như GPU (cho học máy) hoặc giao diện mạng RDMA, nhưng nhìn chung, phần mềm tự vận hành có xu hướng sử dụng các tài nguyên máy tính rất chung: CPU, RAM, filesystem và mạng IP.
Trong đám mây, loại phần mềm này có thể chạy trên môi trường Infrastructure-as-a-Service, sử dụng một hoặc nhiều máy ảo (hoặc instance) với lượng CPU, bộ nhớ, đĩa và băng thông mạng nhất định. So với các máy vật lý, các instance đám mây có thể được cấp phát nhanh hơn và chúng có nhiều kích thước hơn, nhưng nếu không, chúng tương tự như máy tính truyền thống: bạn có thể chạy bất kỳ phần mềm nào bạn thích trên đó, nhưng bạn có trách nhiệm tự quản trị nó.
Ngược lại, ý tưởng chính của các dịch vụ cloud-native là không chỉ sử dụng các tài nguyên máy tính được quản lý bởi hệ điều hành của bạn, mà còn xây dựng trên các dịch vụ đám mây cấp thấp hơn để tạo ra các dịch vụ cấp cao hơn. Ví dụ:
- Các dịch vụ object storage (lưu trữ đối tượng) như Amazon S3, Azure Blob Storage và Cloudflare R2 lưu trữ các tệp lớn. Chúng cung cấp các API hạn chế hơn so với filesystem thông thường (đọc và ghi tệp cơ bản), nhưng chúng có lợi thế là ẩn các máy vật lý bên dưới: dịch vụ tự động phân phối dữ liệu trên nhiều máy, để bạn không phải lo lắng về việc hết dung lượng đĩa trên bất kỳ máy nào. Ngay cả khi một số máy hoặc đĩa của chúng hoàn toàn bị hỏng, không có dữ liệu nào bị mất.
- Nhiều dịch vụ khác được xây dựng trên object storage và các dịch vụ đám mây khác: ví dụ, Snowflake là cơ sở dữ liệu phân tích dựa trên đám mây (kho dữ liệu) dựa trên S3 để lưu trữ dữ liệu 27, và một số dịch vụ khác lại xây dựng trên Snowflake.
Như mọi khi với các trừu tượng trong máy tính, không có một câu trả lời đúng nào về những gì bạn nên sử dụng. Theo nguyên tắc chung, các trừu tượng cấp cao hơn có xu hướng hướng nhiều hơn về các trường hợp sử dụng cụ thể. Nếu nhu cầu của bạn phù hợp với các tình huống mà hệ thống cấp cao hơn được thiết kế, thì việc sử dụng hệ thống cấp cao hơn hiện có sẽ có thể cung cấp những gì bạn cần với ít phức tạp hơn nhiều so với việc tự xây dựng từ các hệ thống cấp thấp hơn. Mặt khác, nếu không có hệ thống cấp cao nào đáp ứng nhu cầu của bạn, thì việc tự xây dựng từ các thành phần cấp thấp hơn là lựa chọn duy nhất.
Tách biệt lưu trữ và tính toán
Trong máy tính truyền thống, lưu trữ đĩa được coi là bền (chúng ta giả định rằng một khi thứ gì đó được ghi vào đĩa, nó sẽ không bị mất). Để chịu đựng lỗi của một ổ cứng riêng lẻ, RAID (Redundant Array of Independent Disks - Mảng đĩa dự phòng độc lập) thường được sử dụng để duy trì các bản sao của dữ liệu trên một số đĩa gắn vào cùng một máy. RAID có thể được thực hiện bằng phần cứng hoặc phần mềm bởi hệ điều hành, và nó minh bạch với các ứng dụng truy cập filesystem.
Trong đám mây, các instance máy tính (máy ảo) cũng có thể có đĩa cục bộ gắn vào, nhưng các hệ thống cloud-native thường coi các đĩa này giống như một cache tạm thời hơn, và ít giống như lưu trữ lâu dài hơn. Điều này là vì đĩa cục bộ trở nên không thể truy cập nếu instance liên quan bị lỗi, hoặc nếu instance được thay thế bằng instance lớn hơn hoặc nhỏ hơn (trên một máy vật lý khác) để thích nghi với các thay đổi trong tải.
Thay thế cho đĩa cục bộ, các dịch vụ đám mây cũng cung cấp lưu trữ đĩa ảo có thể được tháo khỏi một instance và gắn vào một instance khác (Amazon EBS, Azure managed disks và persistent disks trong Google Cloud). Đĩa ảo như vậy thực sự không phải là đĩa vật lý, mà là một dịch vụ đám mây được cung cấp bởi một tập hợp máy riêng biệt, mô phỏng hành vi của một đĩa (một block device - thiết bị khối, trong đó mỗi khối thường có kích thước 4 KiB). Công nghệ này giúp có thể chạy phần mềm dựa trên đĩa truyền thống trong đám mây, nhưng việc mô phỏng thiết bị khối giới thiệu các chi phí bổ sung có thể được tránh trong các hệ thống được thiết kế từ đầu cho đám mây 25. Nó cũng làm cho ứng dụng rất nhạy cảm với các sự cố mạng, vì mỗi I/O trên thiết bị khối ảo thực sự là một cuộc gọi mạng 28.
Để giải quyết vấn đề này, các dịch vụ cloud-native thường tránh sử dụng đĩa ảo, và thay vào đó xây dựng trên các dịch vụ lưu trữ chuyên dụng được tối ưu hóa cho các khối lượng công việc cụ thể. Các dịch vụ object storage như S3 được thiết kế để lưu trữ lâu dài các tệp khá lớn, từ hàng trăm kilobyte đến vài gigabyte. Các hàng hoặc giá trị riêng lẻ được lưu trữ trong cơ sở dữ liệu thường nhỏ hơn nhiều so với điều này; do đó các cơ sở dữ liệu đám mây thường quản lý các giá trị nhỏ hơn trong một dịch vụ riêng biệt, và lưu trữ các khối dữ liệu lớn hơn (chứa nhiều giá trị riêng lẻ) trong object store 26 29. Chúng ta sẽ thấy các cách thực hiện điều này trong Chương 4.
Trong kiến trúc hệ thống truyền thống, cùng một máy tính có trách nhiệm cả lưu trữ (đĩa) và tính toán (CPU và RAM), nhưng trong các hệ thống cloud-native, hai trách nhiệm này đã trở nên phần nào tách biệt hay disaggregated (phân rã) 9 27 30 31: ví dụ, S3 chỉ lưu trữ tệp, và nếu bạn muốn phân tích dữ liệu đó, bạn sẽ phải chạy mã phân tích ở đâu đó bên ngoài S3. Điều này ngụ ý việc truyền dữ liệu qua mạng, mà chúng ta sẽ thảo luận thêm trong “Hệ thống Phân tán so với Hệ thống Đơn nút”.
Hơn nữa, các hệ thống cloud-native thường là multitenant (đa thuê), có nghĩa là thay vì có một máy riêng biệt cho mỗi khách hàng, dữ liệu và tính toán từ nhiều khách hàng khác nhau được xử lý trên cùng một phần cứng dùng chung bởi cùng một dịch vụ 32.
Multitenancy có thể cho phép sử dụng phần cứng tốt hơn, khả năng mở rộng dễ dàng hơn và quản lý dễ dàng hơn bởi nhà cung cấp đám mây, nhưng nó cũng đòi hỏi kỹ thuật cẩn thận để đảm bảo rằng hoạt động của một khách hàng không ảnh hưởng đến hiệu suất hoặc bảo mật của hệ thống cho các khách hàng khác 33.
Vận hành trong Kỷ nguyên Đám mây
Theo truyền thống, những người quản lý hạ tầng dữ liệu phía máy chủ của tổ chức được gọi là database administrators (DBA - quản trị viên cơ sở dữ liệu) hoặc system administrators (sysadmin - quản trị viên hệ thống). Gần đây hơn, nhiều tổ chức đã cố gắng tích hợp vai trò phát triển phần mềm và vận hành vào các nhóm có trách nhiệm chung về cả dịch vụ backend và hạ tầng dữ liệu; triết lý DevOps đã hướng dẫn xu hướng này. Site Reliability Engineers (SRE - Kỹ sư độ tin cậy trang web) là cách triển khai ý tưởng này của Google 34.
Vai trò của vận hành là đảm bảo các dịch vụ được cung cấp đáng tin cậy cho người dùng (bao gồm cấu hình cơ sở hạ tầng và triển khai ứng dụng), và đảm bảo môi trường production ổn định (bao gồm giám sát và chẩn đoán bất kỳ vấn đề nào có thể ảnh hưởng đến độ tin cậy). Đối với các hệ thống tự vận hành, vận hành truyền thống liên quan đến một lượng công việc đáng kể ở cấp độ các máy riêng lẻ, như lập kế hoạch dung lượng (ví dụ, giám sát dung lượng đĩa có sẵn và thêm đĩa trước khi hết dung lượng), cấp phát máy mới, di chuyển dịch vụ từ máy này sang máy khác, và cài đặt các bản vá hệ điều hành.
Nhiều dịch vụ đám mây cung cấp API ẩn các máy riêng lẻ thực sự triển khai dịch vụ. Ví dụ, lưu trữ đám mây thay thế các đĩa có kích thước cố định bằng metered billing (thanh toán theo mức dùng), nơi bạn có thể lưu trữ dữ liệu mà không cần lập kế hoạch nhu cầu dung lượng trước, và sau đó bạn bị tính phí dựa trên không gian thực sự sử dụng. Hơn nữa, nhiều dịch vụ đám mây vẫn có tính sẵn sàng cao, ngay cả khi các máy riêng lẻ bị lỗi (xem “Độ tin cậy và Chịu lỗi”).
Sự thay đổi trọng tâm này từ các máy riêng lẻ sang dịch vụ đi kèm với sự thay đổi trong vai trò vận hành. Mục tiêu cấp cao là cung cấp dịch vụ đáng tin cậy vẫn giữ nguyên, nhưng các quy trình và công cụ đã phát triển. Triết lý DevOps/SRE nhấn mạnh hơn vào:
- tự động hóa - ưu tiên các quy trình có thể lặp lại thay vì các công việc thủ công một lần,
- ưu tiên các máy ảo và dịch vụ tạm thời thay vì các máy chủ chạy lâu dài,
- cho phép các bản cập nhật ứng dụng thường xuyên,
- học hỏi từ các sự cố, và
- bảo tồn kiến thức của tổ chức về hệ thống, ngay cả khi các cá nhân đến và đi 35.
Với sự nổi lên của các dịch vụ đám mây, đã có sự phân hóa vai trò: các nhóm vận hành tại các công ty cơ sở hạ tầng chuyên về chi tiết cung cấp dịch vụ đáng tin cậy cho nhiều khách hàng, trong khi khách hàng của dịch vụ dành ít thời gian và công sức nhất có thể cho cơ sở hạ tầng 36.
Khách hàng của các dịch vụ đám mây vẫn cần vận hành, nhưng họ tập trung vào các khía cạnh khác, như chọn dịch vụ phù hợp nhất cho một nhiệm vụ nhất định, tích hợp các dịch vụ khác nhau với nhau, và di chuyển từ dịch vụ này sang dịch vụ khác. Mặc dù thanh toán theo mức dùng loại bỏ nhu cầu lập kế hoạch dung lượng theo nghĩa truyền thống, vẫn quan trọng là biết bạn đang sử dụng tài nguyên gì cho mục đích gì, để bạn không lãng phí tiền vào các tài nguyên đám mây không cần thiết: lập kế hoạch dung lượng trở thành lập kế hoạch tài chính, và tối ưu hóa hiệu suất trở thành tối ưu hóa chi phí 37.
Hơn nữa, các dịch vụ đám mây có giới hạn tài nguyên hoặc quotas (hạn mức) (như số lượng tối đa các quy trình bạn có thể chạy đồng thời), mà bạn cần biết và lập kế hoạch trước khi bạn gặp phải chúng 38.
Áp dụng dịch vụ đám mây có thể dễ dàng và nhanh hơn so với tự chạy cơ sở hạ tầng của bạn, mặc dù ngay cả ở đây cũng có chi phí học cách sử dụng nó, và có thể làm việc xung quanh các giới hạn của nó. Tích hợp giữa các dịch vụ khác nhau trở thành một thách thức đặc biệt khi ngày càng nhiều nhà cung cấp cung cấp một phạm vi ngày càng rộng hơn các dịch vụ đám mây nhắm vào các trường hợp sử dụng khác nhau 39 40.
ETL (xem “Kho Dữ liệu”) chỉ là một phần của câu chuyện; các dịch vụ đám mây vận hành cũng cần được tích hợp với nhau. Hiện tại, thiếu các tiêu chuẩn sẽ tạo điều kiện cho loại tích hợp này, vì vậy nó thường đòi hỏi nỗ lực thủ công đáng kể.
Các khía cạnh vận hành khác không thể hoàn toàn thuê ngoài cho các dịch vụ đám mây bao gồm duy trì bảo mật của ứng dụng và các thư viện nó sử dụng, quản lý các tương tác giữa các dịch vụ của riêng bạn, giám sát tải trên các dịch vụ của bạn, và truy tìm nguyên nhân của các vấn đề như giảm hiệu suất hoặc sự cố ngừng hoạt động. Trong khi đám mây đang thay đổi vai trò vận hành, nhu cầu vận hành vẫn lớn như cũ.
Hệ thống Phân tán so với Hệ thống Đơn nút
Một hệ thống liên quan đến nhiều máy giao tiếp qua mạng được gọi là distributed system (hệ thống phân tán). Mỗi quy trình tham gia vào hệ thống phân tán được gọi là node (nút). Có nhiều lý do khiến bạn muốn một hệ thống được phân tán:
- Hệ thống vốn đã phân tán (Inherently distributed systems)
- Nếu một ứng dụng liên quan đến hai hoặc nhiều người dùng tương tác, mỗi người dùng thiết bị của riêng họ, thì hệ thống không thể tránh khỏi là phân tán: giao tiếp giữa các thiết bị sẽ phải đi qua mạng.
- Yêu cầu giữa các dịch vụ đám mây (Requests between cloud services)
- Nếu dữ liệu được lưu trữ trong một dịch vụ nhưng được xử lý trong dịch vụ khác, nó phải được truyền qua mạng từ dịch vụ này sang dịch vụ kia.
- Chịu lỗi/tính sẵn sàng cao (Fault tolerance/high availability)
- Nếu ứng dụng của bạn cần tiếp tục hoạt động ngay cả khi một máy (hoặc nhiều máy, hoặc mạng, hoặc toàn bộ datacenter) ngừng hoạt động, bạn có thể sử dụng nhiều máy để cung cấp cho bạn sự dự phòng. Khi một máy bị lỗi, một máy khác có thể thay thế. Xem “Độ tin cậy và Chịu lỗi” và Chương 6 về replication (sao chép).
- Khả năng mở rộng (Scalability)
- Nếu khối lượng dữ liệu hoặc yêu cầu tính toán của bạn tăng lên lớn hơn một máy có thể xử lý, bạn có thể phân phối tải trên nhiều máy. Xem “Khả năng mở rộng”.
- Độ trễ (Latency)
- Nếu bạn có người dùng trên khắp thế giới, bạn có thể muốn có máy chủ ở các vùng khác nhau trên thế giới để mỗi người dùng có thể được phục vụ từ máy chủ gần họ về mặt địa lý. Điều đó tránh việc người dùng phải chờ các gói mạng đi nửa vòng trái đất để trả lời yêu cầu của họ. Xem “Mô tả Hiệu suất”.
- Tính đàn hồi (Elasticity)
- Nếu ứng dụng của bạn bận rộn vào một số thời điểm và nhàn rỗi vào các thời điểm khác, một triển khai đám mây có thể mở rộng hoặc thu hẹp để đáp ứng nhu cầu, để bạn chỉ trả tiền cho các tài nguyên bạn đang tích cực sử dụng. Điều này khó hơn trên một máy đơn, cần được cấp phát để xử lý tải tối đa, ngay cả những lúc nó hầu như không được sử dụng.
- Sử dụng phần cứng chuyên biệt (Using specialized hardware)
- Các phần khác nhau của hệ thống có thể tận dụng các loại phần cứng khác nhau để phù hợp với khối lượng công việc của chúng. Ví dụ, một object store có thể sử dụng các máy có nhiều đĩa nhưng ít CPU, trong khi hệ thống phân tích dữ liệu có thể sử dụng các máy với nhiều CPU và bộ nhớ nhưng không có đĩa, và hệ thống học máy có thể sử dụng các máy có GPU (hiệu quả hơn nhiều so với CPU để huấn luyện mạng nơ-ron sâu và các tác vụ học máy khác).
- Tuân thủ pháp lý (Legal compliance)
- Một số quốc gia có luật lưu trú dữ liệu yêu cầu dữ liệu về người trong phạm vi quyền tài phán của họ phải được lưu trữ và xử lý về mặt địa lý trong quốc gia đó 41. Phạm vi của các quy tắc này khác nhau - ví dụ, trong một số trường hợp nó chỉ áp dụng cho dữ liệu y tế hoặc tài chính, trong khi các trường hợp khác rộng hơn. Một dịch vụ có người dùng ở nhiều khu vực tài phán như vậy sẽ phải phân phối dữ liệu của họ trên các máy chủ ở nhiều địa điểm.
- Tính bền vững (Sustainability)
- Nếu bạn có sự linh hoạt về nơi và thời điểm chạy công việc của mình, bạn có thể chạy chúng ở nơi và thời điểm có nhiều điện tái tạo, và tránh chạy chúng khi lưới điện đang bị căng thẳng. Điều này có thể giảm lượng khí thải carbon của bạn và cho phép bạn tận dụng điện giá rẻ khi có sẵn 42 43.
Những lý do này áp dụng cho cả các dịch vụ bạn tự viết (mã ứng dụng) và các dịch vụ bao gồm phần mềm có sẵn (như cơ sở dữ liệu).
Các Vấn đề với Hệ thống Phân tán
Các hệ thống phân tán cũng có những nhược điểm. Mỗi yêu cầu và cuộc gọi API đi qua mạng cần xử lý khả năng thất bại: mạng có thể bị gián đoạn, hoặc dịch vụ có thể bị quá tải hoặc sập, và do đó bất kỳ yêu cầu nào cũng có thể hết thời gian mà không nhận được phản hồi. Trong trường hợp này, chúng ta không biết dịch vụ có nhận được yêu cầu hay không, và việc thử lại đơn giản có thể không an toàn. Chúng ta sẽ thảo luận chi tiết về những vấn đề này trong Chương 9.
Mặc dù các mạng datacenter nhanh, việc thực hiện một cuộc gọi đến dịch vụ khác vẫn chậm hơn rất nhiều so với gọi một hàm trong cùng một quy trình 44.
Khi vận hành trên khối lượng dữ liệu lớn, thay vì chuyển dữ liệu từ lưu trữ sang một máy riêng biệt xử lý nó, có thể nhanh hơn khi đưa tính toán đến máy đã có dữ liệu 45.
Nhiều nút hơn không phải lúc nào cũng nhanh hơn: trong một số trường hợp, một chương trình đơn luồng đơn giản trên một máy tính có thể hoạt động tốt hơn đáng kể so với một cụm với hơn 100 lõi CPU 46.
Khắc phục sự cố hệ thống phân tán thường khó khăn: nếu hệ thống phản hồi chậm, làm thế nào bạn tìm ra vấn đề nằm ở đâu? Các kỹ thuật chẩn đoán vấn đề trong hệ thống phân tán được phát triển dưới tiêu đề observability (quan sát được) 47 48, bao gồm thu thập dữ liệu về việc thực thi của hệ thống, và cho phép nó được truy vấn theo cách cho phép cả số liệu cấp cao và các sự kiện riêng lẻ được phân tích. Các công cụ Tracing (theo dõi) như OpenTelemetry, Zipkin và Jaeger cho phép bạn theo dõi client nào đã gọi server nào cho hoạt động nào, và mỗi cuộc gọi mất bao lâu 49.
Cơ sở dữ liệu cung cấp các cơ chế khác nhau để đảm bảo tính nhất quán dữ liệu, như chúng ta sẽ thấy trong Chương 6 và Chương 8. Tuy nhiên, khi mỗi dịch vụ có cơ sở dữ liệu riêng, việc duy trì tính nhất quán của dữ liệu trên các dịch vụ khác nhau đó trở thành vấn đề của ứng dụng. Distributed transactions (giao dịch phân tán), mà chúng ta khám phá trong Chương 8, là một kỹ thuật có thể để đảm bảo tính nhất quán, nhưng chúng hiếm khi được sử dụng trong ngữ cảnh microservices vì chúng đi ngược lại mục tiêu làm cho các dịch vụ độc lập với nhau, và nhiều cơ sở dữ liệu không hỗ trợ chúng 50.
Vì tất cả những lý do này, nếu bạn có thể làm gì đó trên một máy đơn, điều này thường đơn giản hơn và rẻ hơn nhiều so với thiết lập hệ thống phân tán 23 46 51. CPU, bộ nhớ và đĩa đã ngày càng lớn hơn, nhanh hơn và đáng tin cậy hơn. Khi kết hợp với các cơ sở dữ liệu đơn nút như DuckDB, SQLite và KùzuDB, nhiều khối lượng công việc hiện có thể chạy trên một nút đơn. Chúng ta sẽ khám phá thêm về chủ đề này trong Chương 4.
Microservices và Serverless
Cách phổ biến nhất để phân phối một hệ thống trên nhiều máy là chia chúng thành client và server, và để client thực hiện yêu cầu đến server. Thông thường HTTP được sử dụng cho giao tiếp này, như chúng ta sẽ thảo luận trong “Luồng dữ liệu qua Dịch vụ: REST và RPC”. Cùng một quy trình có thể vừa là server (xử lý các yêu cầu đến) vừa là client (thực hiện các yêu cầu ra đến các dịch vụ khác).
Cách xây dựng ứng dụng này theo truyền thống được gọi là service-oriented architecture (SOA - kiến trúc hướng dịch vụ); gần đây hơn ý tưởng này đã được tinh chỉnh thành kiến trúc microservices 52 53. Trong kiến trúc này, một dịch vụ có một mục đích được xác định rõ ràng (ví dụ, trong trường hợp của S3, đây sẽ là lưu trữ tệp); mỗi dịch vụ cung cấp một API có thể được gọi bởi các client qua mạng, và mỗi dịch vụ có một nhóm chịu trách nhiệm bảo trì của nó. Một ứng dụng phức tạp có thể được phân rã thành nhiều dịch vụ tương tác, mỗi dịch vụ được quản lý bởi một nhóm riêng biệt.
Có một số lợi thế khi chia nhỏ một phần mềm phức tạp thành nhiều dịch vụ: mỗi dịch vụ có thể được cập nhật độc lập, giảm nỗ lực phối hợp giữa các nhóm; mỗi dịch vụ có thể được phân bổ tài nguyên phần cứng nó cần; và bằng cách ẩn các chi tiết triển khai phía sau API, chủ sở hữu dịch vụ được tự do thay đổi triển khai mà không ảnh hưởng đến client. Về mặt lưu trữ dữ liệu, việc mỗi dịch vụ có cơ sở dữ liệu riêng và không chia sẻ cơ sở dữ liệu giữa các dịch vụ là phổ biến: chia sẻ cơ sở dữ liệu sẽ thực sự làm cho toàn bộ cấu trúc cơ sở dữ liệu trở thành một phần của API dịch vụ, và sau đó cấu trúc đó sẽ khó thay đổi. Cơ sở dữ liệu dùng chung cũng có thể khiến các truy vấn của một dịch vụ ảnh hưởng tiêu cực đến hiệu suất của các dịch vụ khác.
Mặt khác, có nhiều dịch vụ có thể tự tạo ra sự phức tạp: mỗi dịch vụ đòi hỏi cơ sở hạ tầng để triển khai các bản phát hành mới, điều chỉnh tài nguyên phần cứng được phân bổ để phù hợp với tải, thu thập nhật ký, giám sát tình trạng dịch vụ và cảnh báo kỹ sư trực khi có sự cố. Các framework Orchestration (điều phối) như Kubernetes đã trở thành cách phổ biến để triển khai dịch vụ, vì chúng cung cấp nền tảng cho cơ sở hạ tầng này. Kiểm tra dịch vụ trong quá trình phát triển có thể phức tạp, vì bạn cũng cần chạy tất cả các dịch vụ khác mà nó phụ thuộc vào.
Các API microservice có thể khó phát triển. Các client gọi API mong đợi API có các trường nhất định. Các nhà phát triển có thể muốn thêm hoặc xóa các trường khỏi API khi nhu cầu kinh doanh thay đổi, nhưng làm như vậy có thể khiến client thất bại. Tệ hơn nữa, các thất bại như vậy thường không được phát hiện cho đến muộn trong chu kỳ phát triển khi API dịch vụ được cập nhật được triển khai vào môi trường staging hoặc production. Các tiêu chuẩn mô tả API như OpenAPI và gRPC giúp quản lý mối quan hệ giữa API client và server; chúng ta thảo luận thêm về những điều này trong Chương 5.
Microservices chủ yếu là giải pháp kỹ thuật cho một vấn đề con người: cho phép các nhóm khác nhau tiến bộ độc lập mà không cần phối hợp với nhau. Điều này có giá trị trong một công ty lớn, nhưng trong một công ty nhỏ nơi không có nhiều nhóm, việc sử dụng microservices có thể là chi phí bổ sung không cần thiết, và nên ưu tiên triển khai ứng dụng theo cách đơn giản nhất có thể 52.
Serverless, hay function-as-a-service (FaaS), là một cách tiếp cận khác để triển khai dịch vụ, trong đó việc quản lý cơ sở hạ tầng được thuê ngoài cho nhà cung cấp đám mây 33. Khi sử dụng máy ảo, bạn phải chọn rõ ràng khi nào để khởi động hoặc tắt một instance; ngược lại, với mô hình serverless, nhà cung cấp đám mây tự động phân bổ và giải phóng tài nguyên phần cứng khi cần, dựa trên các yêu cầu đến dịch vụ của bạn 54. Triển khai serverless chuyển nhiều gánh nặng vận hành hơn cho các nhà cung cấp đám mây và cho phép thanh toán linh hoạt theo mức sử dụng thay vì các instance máy. Để cung cấp những lợi ích như vậy, nhiều nhà cung cấp cơ sở hạ tầng serverless áp đặt giới hạn thời gian cho việc thực thi hàm, hạn chế môi trường runtime, và có thể gặp phải thời gian khởi động chậm khi một hàm được gọi lần đầu tiên. Thuật ngữ “serverless” cũng có thể gây hiểu lầm: mỗi lần thực thi hàm serverless vẫn chạy trên một máy chủ, nhưng các lần thực thi tiếp theo có thể chạy trên một máy chủ khác. Hơn nữa, cơ sở hạ tầng như BigQuery và các sản phẩm Kafka khác nhau đã áp dụng thuật ngữ “serverless” để báo hiệu rằng dịch vụ của họ tự mở rộng và thanh toán theo mức sử dụng thay vì các instance máy.
Giống như lưu trữ đám mây đã thay thế lập kế hoạch dung lượng (quyết định trước số lượng đĩa cần mua) bằng mô hình thanh toán theo mức dùng, cách tiếp cận serverless đang đưa thanh toán theo mức dùng vào thực thi mã: bạn chỉ trả tiền cho thời gian mã ứng dụng của bạn thực sự chạy, thay vì phải cấp phát tài nguyên trước.
Điện toán Đám mây so với Siêu máy tính
Điện toán đám mây không phải là cách duy nhất để xây dựng các hệ thống tính toán quy mô lớn; một giải pháp thay thế là high-performance computing (HPC - tính toán hiệu năng cao), còn được gọi là supercomputing (siêu máy tính). Mặc dù có sự chồng chéo, HPC thường có các ưu tiên khác nhau và sử dụng các kỹ thuật khác nhau so với điện toán đám mây và các hệ thống datacenter doanh nghiệp. Một số khác biệt đó là:
- Siêu máy tính thường được sử dụng cho các tác vụ tính toán khoa học cường độ cao, như dự báo thời tiết, mô hình hóa khí hậu, động lực học phân tử (mô phỏng chuyển động của nguyên tử và phân tử), các vấn đề tối ưu hóa phức tạp, và giải các phương trình vi phân một phần. Mặt khác, điện toán đám mây có xu hướng được sử dụng cho các dịch vụ trực tuyến, hệ thống dữ liệu kinh doanh và các hệ thống tương tự cần phục vụ yêu cầu người dùng với tính sẵn sàng cao.
- Một siêu máy tính thường chạy các công việc theo lô lớn có checkpoint trạng thái tính toán của chúng vào đĩa theo thời gian. Nếu một nút bị lỗi, giải pháp phổ biến là chỉ đơn giản dừng toàn bộ khối lượng công việc cụm, sửa chữa nút bị lỗi, và sau đó khởi động lại tính toán từ checkpoint cuối cùng 55 56. Với các dịch vụ đám mây, thường không mong muốn dừng toàn bộ cụm, vì các dịch vụ cần liên tục phục vụ người dùng với ít gián đoạn nhất.
- Các nút siêu máy tính thường giao tiếp qua bộ nhớ dùng chung và remote direct memory access (RDMA), hỗ trợ băng thông cao và độ trễ thấp, nhưng giả định mức độ tin cậy cao giữa người dùng của hệ thống 57. Trong điện toán đám mây, mạng và máy thường được chia sẻ bởi các tổ chức không tin tưởng lẫn nhau, đòi hỏi các cơ chế bảo mật mạnh hơn như cách ly tài nguyên (ví dụ, máy ảo), mã hóa và xác thực.
- Các mạng datacenter đám mây thường dựa trên IP và Ethernet, được sắp xếp trong các cấu trúc liên kết Clos để cung cấp băng thông bisection cao - một thước đo thường được sử dụng về hiệu suất tổng thể của mạng 55 58. Siêu máy tính thường sử dụng các cấu trúc liên kết mạng chuyên biệt, như lưới và torus đa chiều 59, tạo ra hiệu suất tốt hơn cho các khối lượng công việc HPC với các mẫu giao tiếp đã biết.
- Điện toán đám mây cho phép các nút được phân phối trên nhiều vùng địa lý, trong khi siêu máy tính thường giả định rằng tất cả các nút của chúng ở gần nhau.
Các hệ thống phân tích quy mô lớn đôi khi chia sẻ một số đặc điểm với siêu máy tính, đó là lý do tại sao việc biết về các kỹ thuật này có thể có giá trị nếu bạn đang làm việc trong lĩnh vực này. Tuy nhiên, cuốn sách này chủ yếu liên quan đến các dịch vụ cần liên tục sẵn sàng, như đã thảo luận trong “Độ tin cậy và Chịu lỗi”.
Hệ thống Dữ liệu, Pháp luật và Xã hội
Cho đến nay trong chương này bạn đã thấy rằng kiến trúc của các hệ thống dữ liệu không chỉ bị ảnh hưởng bởi các mục tiêu và yêu cầu kỹ thuật, mà còn bởi nhu cầu của con người trong các tổ chức mà chúng hỗ trợ. Ngày càng nhiều, các kỹ sư hệ thống dữ liệu nhận ra rằng phục vụ nhu cầu của doanh nghiệp của họ là chưa đủ: chúng ta cũng có trách nhiệm đối với xã hội nói chung.
Một mối quan tâm đặc biệt là các hệ thống lưu trữ dữ liệu về con người và hành vi của họ. Kể từ năm 2018, General Data Protection Regulation (GDPR - Quy định Bảo vệ Dữ liệu Chung) đã mang lại cho người dân ở nhiều quốc gia châu Âu quyền kiểm soát và quyền pháp lý lớn hơn đối với dữ liệu cá nhân của họ, và các quy định quyền riêng tư tương tự đã được áp dụng ở nhiều quốc gia và tiểu bang khác trên thế giới, bao gồm ví dụ California Consumer Privacy Act (CCPA). Các quy định về AI, như EU AI Act, đặt ra các hạn chế bổ sung về cách dữ liệu cá nhân có thể được sử dụng.
Hơn nữa, ngay cả trong các lĩnh vực không trực tiếp chịu sự điều tiết, có sự thừa nhận ngày càng tăng về các tác động mà các hệ thống máy tính có đối với con người và xã hội. Mạng xã hội đã thay đổi cách các cá nhân tiêu thụ tin tức, điều này ảnh hưởng đến ý kiến chính trị của họ và do đó có thể ảnh hưởng đến kết quả bầu cử. Các hệ thống tự động ngày càng đưa ra các quyết định có hậu quả sâu sắc đối với các cá nhân, như quyết định ai được vay tiền hoặc bảo hiểm, ai được mời phỏng vấn việc làm, hoặc ai nên bị nghi ngờ phạm tội 60.
Tất cả những người làm việc trên các hệ thống như vậy đều có trách nhiệm xem xét tác động đạo đức và đảm bảo rằng chúng tuân thủ luật pháp liên quan. Không nhất thiết mọi người đều phải trở thành chuyên gia về pháp luật và đạo đức, nhưng nhận thức cơ bản về các nguyên tắc pháp lý và đạo đức cũng quan trọng như, chẳng hạn, một số kiến thức nền tảng về hệ thống phân tán.
Các cân nhắc pháp lý đang ảnh hưởng đến nền tảng cơ bản của cách các hệ thống dữ liệu đang được thiết kế 61. Ví dụ, GDPR trao cho các cá nhân quyền xóa dữ liệu của họ theo yêu cầu (đôi khi được gọi là right to be forgotten - quyền được lãng quên). Tuy nhiên, như chúng ta sẽ thấy trong cuốn sách này, nhiều hệ thống dữ liệu dựa vào các cấu trúc bất biến như log chỉ thêm như một phần của thiết kế của chúng; làm thế nào chúng ta có thể đảm bảo xóa một số dữ liệu ở giữa tệp được cho là bất biến? Làm thế nào chúng ta xử lý việc xóa dữ liệu đã được kết hợp vào các bộ dữ liệu dẫn xuất (xem “Hệ thống Gốc và Dữ liệu Dẫn xuất”), như dữ liệu huấn luyện cho các mô hình học máy? Trả lời những câu hỏi này tạo ra những thách thức kỹ thuật mới.
Hiện tại chúng ta không có hướng dẫn rõ ràng về những công nghệ hoặc kiến trúc hệ thống cụ thể nào nên được coi là “tuân thủ GDPR” hay không. Quy định cố tình không bắt buộc các công nghệ cụ thể, vì chúng có thể thay đổi nhanh chóng khi công nghệ tiến bộ. Thay vào đó, các văn bản pháp lý đặt ra các nguyên tắc cấp cao phải được diễn giải. Điều này có nghĩa là không có câu trả lời đơn giản cho câu hỏi làm thế nào để tuân thủ quy định quyền riêng tư, nhưng chúng ta sẽ xem xét một số công nghệ trong cuốn sách này qua lăng kính này.
Nói chung, chúng ta lưu trữ dữ liệu vì chúng ta nghĩ rằng giá trị của nó lớn hơn chi phí lưu trữ. Tuy nhiên, điều đáng nhớ là chi phí lưu trữ không chỉ là hóa đơn bạn trả cho Amazon S3 hoặc dịch vụ khác: tính toán chi phí-lợi ích cũng nên tính đến rủi ro trách nhiệm pháp lý và thiệt hại uy tín nếu dữ liệu bị rò rỉ hoặc bị xâm phạm bởi đối thủ, và nguy cơ chi phí pháp lý và tiền phạt nếu việc lưu trữ và xử lý dữ liệu không tuân thủ pháp luật 51.
Chính phủ hoặc cảnh sát cũng có thể buộc các công ty giao nộp dữ liệu. Khi có rủi ro rằng dữ liệu có thể tiết lộ các hành vi bị hình sự hóa (ví dụ, đồng tính luyến ái ở một số quốc gia Trung Đông và châu Phi, hoặc tìm kiếm phá thai ở một số tiểu bang Mỹ), việc lưu trữ dữ liệu đó tạo ra rủi ro an toàn thực sự cho người dùng. Ví dụ, việc đến phòng khám phá thai có thể dễ dàng bị tiết lộ qua dữ liệu vị trí, thậm chí có thể bằng nhật ký địa chỉ IP của người dùng theo thời gian (cho biết vị trí gần đúng).
Khi tất cả các rủi ro được tính đến, có thể hợp lý khi quyết định rằng một số dữ liệu đơn giản là không đáng lưu trữ, và do đó nên được xóa. Nguyên tắc data minimization (tối thiểu hóa dữ liệu) (đôi khi được biết đến bằng thuật ngữ tiếng Đức Datensparsamkeit) đi ngược lại triết lý “big data” về việc lưu trữ nhiều dữ liệu một cách suy đoán phòng khi nó có ích trong tương lai 62. Nhưng nó phù hợp với GDPR, yêu cầu dữ liệu cá nhân chỉ có thể được thu thập cho một mục đích cụ thể, rõ ràng, rằng dữ liệu này không được sử dụng sau đó cho bất kỳ mục đích nào khác, và rằng dữ liệu không được giữ lâu hơn cần thiết cho các mục đích mà nó được thu thập 63.
Các doanh nghiệp cũng đã chú ý đến các mối lo ngại về quyền riêng tư và an toàn. Các công ty thẻ tín dụng yêu cầu các doanh nghiệp xử lý thanh toán tuân thủ các tiêu chuẩn ngành thẻ thanh toán (PCI) nghiêm ngặt. Các bộ xử lý trải qua các đánh giá thường xuyên từ các kiểm toán viên độc lập để xác minh sự tuân thủ liên tục. Các nhà cung cấp phần mềm cũng được xem xét kỹ hơn. Nhiều người mua hiện yêu cầu nhà cung cấp của họ tuân thủ các tiêu chuẩn Service Organization Control (SOC) Type 2. Như với tuân thủ PCI, các nhà cung cấp trải qua các cuộc kiểm toán của bên thứ ba để xác minh sự tuân thủ.
Nói chung, điều quan trọng là cân bằng nhu cầu của doanh nghiệp với nhu cầu của những người có dữ liệu mà bạn đang thu thập và xử lý. Còn nhiều hơn nữa về chủ đề này; trong Chương 14 chúng ta sẽ đi sâu hơn vào các chủ đề đạo đức và tuân thủ pháp lý, bao gồm các vấn đề về thiên kiến và phân biệt đối xử.
Tóm tắt
Chủ đề của chương này là hiểu sự đánh đổi: tức là nhận ra rằng với nhiều câu hỏi, không có một câu trả lời đúng, mà có một số cách tiếp cận khác nhau mỗi cách có nhiều ưu và nhược điểm. Chúng ta đã khám phá một số lựa chọn quan trọng nhất ảnh hưởng đến kiến trúc của các hệ thống dữ liệu, và giới thiệu thuật ngữ sẽ cần thiết trong suốt phần còn lại của cuốn sách.
Chúng ta bắt đầu bằng cách phân biệt giữa các hệ thống vận hành (xử lý giao dịch, OLTP) và phân tích (OLAP), và thấy các đặc điểm khác nhau của chúng: không chỉ quản lý các loại dữ liệu khác nhau với các mẫu truy cập khác nhau, mà còn phục vụ các đối tượng khác nhau. Chúng ta đã gặp khái niệm kho dữ liệu và hồ dữ liệu, nhận dữ liệu từ các hệ thống vận hành qua ETL. Trong Chương 4, chúng ta sẽ thấy rằng các hệ thống vận hành và phân tích thường sử dụng các bố cục dữ liệu nội bộ rất khác nhau vì các loại truy vấn khác nhau mà chúng cần phục vụ.
Sau đó chúng ta so sánh các dịch vụ đám mây, một sự phát triển tương đối gần đây, với mô hình truyền thống của phần mềm tự vận hành đã từng thống trị kiến trúc hệ thống dữ liệu. Cách tiếp cận nào tiết kiệm chi phí hơn phụ thuộc rất nhiều vào tình huống cụ thể của bạn, nhưng không thể phủ nhận rằng các cách tiếp cận cloud-native đang mang lại những thay đổi lớn cho cách các hệ thống dữ liệu được kiến trúc, ví dụ trong cách chúng tách biệt lưu trữ và tính toán.
Các hệ thống đám mây về bản chất là phân tán, và chúng ta đã xem xét ngắn gọn một số sự đánh đổi của hệ thống phân tán so với sử dụng một máy đơn. Có những tình huống mà bạn không thể tránh khỏi việc phân tán, nhưng không nên vội vàng biến một hệ thống thành phân tán nếu có thể giữ nó trên một máy đơn. Trong Chương 9, chúng ta sẽ đề cập chi tiết hơn đến các thách thức với hệ thống phân tán.
Cuối cùng, chúng ta đã thấy rằng kiến trúc hệ thống dữ liệu không chỉ được xác định bởi nhu cầu của doanh nghiệp triển khai hệ thống, mà còn bởi quy định quyền riêng tư bảo vệ quyền của những người có dữ liệu đang được xử lý - một khía cạnh mà nhiều kỹ sư có xu hướng bỏ qua. Cách chúng ta dịch các yêu cầu pháp lý thành các triển khai kỹ thuật chưa được hiểu rõ, nhưng điều quan trọng là giữ câu hỏi này trong tâm trí khi chúng ta tiến qua phần còn lại của cuốn sách.
Tài liệu tham khảo
Richard T. Kouzes, Gordon A. Anderson, Stephen T. Elbert, Ian Gorton, and Deborah K. Gracio. The Changing Paradigm of Data-Intensive Computing. IEEE Computer, volume 42, issue 1, January 2009. doi:10.1109/MC.2009.26 ↩︎
Martin Kleppmann, Adam Wiggins, Peter van Hardenberg, and Mark McGranaghan. Local-first software: you own your data, in spite of the cloud. At 2019 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward!), October 2019. doi:10.1145/3359591.3359737 ↩︎
Joe Reis and Matt Housley. Fundamentals of Data Engineering. O’Reilly Media, 2022. ISBN: 9781098108304 ↩︎
Rui Pedro Machado and Helder Russa. Analytics Engineering with SQL and dbt. O’Reilly Media, 2023. ISBN: 9781098142384 ↩︎
Edgar F. Codd, S. B. Codd, and C. T. Salley. Providing OLAP to User-Analysts: An IT Mandate. E. F. Codd Associates, 1993. Archived at perma.cc/RKX8-2GEE ↩︎
Chinmay Soman and Neha Pawar. Comparing Three Real-Time OLAP Databases: Apache Pinot, Apache Druid, and ClickHouse. startree.ai, April 2023. Archived at perma.cc/8BZP-VWPA ↩︎
Surajit Chaudhuri and Umeshwar Dayal. An Overview of Data Warehousing and OLAP Technology. ACM SIGMOD Record, volume 26, issue 1, pages 65-74, March 1997. doi:10.1145/248603.248616 ↩︎
Fatma Özcan, Yuanyuan Tian, and Pinar Tözün. Hybrid Transactional/Analytical Processing: A Survey. At ACM International Conference on Management of Data (SIGMOD), May 2017. doi:10.1145/3035918.3054784 ↩︎
Adam Prout, Szu-Po Wang, Joseph Victor, Zhou Sun, Yongzhu Li, Jack Chen, Evan Bergeron, Eric Hanson, Robert Walzer, Rodrigo Gomes, and Nikita Shamgunov. Cloud-Native Transactions and Analytics in SingleStore. At International Conference on Management of Data (SIGMOD), June 2022. doi:10.1145/3514221.3526055 ↩︎ ↩︎
Chao Zhang, Guoliang Li, Jintao Zhang, Xinning Zhang, and Jianhua Feng. HTAP Databases: A Survey. IEEE Transactions on Knowledge and Data Engineering, April 2024. doi:10.1109/TKDE.2024.3389693 ↩︎
Michael Stonebraker and Ugur Cetintemel. ‘One Size Fits All’: An Idea Whose Time Has Come and Gone. At 21st International Conference on Data Engineering (ICDE), April 2005. doi:10.1109/ICDE.2005.1 ↩︎
Jeffrey Cohen, Brian Dolan, Mark Dunlap, Joseph M. Hellerstein, and Caleb Welton. MAD Skills: New Analysis Practices for Big Data. Proceedings of the VLDB Endowment, volume 2, issue 2, pages 1481-1492, August 2009. doi:10.14778/1687553.1687576 ↩︎
Dan Olteanu. The Relational Data Borg is Learning. Proceedings of the VLDB Endowment, volume 13, issue 12, August 2020. doi:10.14778/3415478.3415572 ↩︎
Matt Bornstein, Martin Casado, and Jennifer Li. Emerging Architectures for Modern Data Infrastructure: 2020. future.a16z.com, October 2020. Archived at perma.cc/LF8W-KDCC ↩︎
Martin Fowler. DataLake. martinfowler.com, February 2015. Archived at perma.cc/4WKN-CZUK ↩︎
Bobby Johnson and Joseph Adler. The Sushi Principle: Raw Data Is Better. At Strata+Hadoop World, February 2015. ↩︎
Michael Armbrust, Ali Ghodsi, Reynold Xin, and Matei Zaharia. Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. At 11th Annual Conference on Innovative Data Systems Research (CIDR), January 2021. ↩︎
DataKitchen, Inc. The DataOps Manifesto. dataopsmanifesto.org, 2017. Archived at perma.cc/3F5N-FUQ4 ↩︎
Tejas Manohar. What is Reverse ETL: A Definition & Why It’s Taking Off. hightouch.io, November 2021. Archived at perma.cc/A7TN-GLYJ ↩︎
Simon O’Regan. Designing Data Products. towardsdatascience.com, August 2018. Archived at perma.cc/HU67-3RV8 ↩︎
Camille Fournier. Why is it so hard to decide to buy? skamille.medium.com, July 2021. Archived at perma.cc/6VSG-HQ5X ↩︎
David Heinemeier Hansson. Why we’re leaving the cloud. world.hey.com, October 2022. Archived at perma.cc/82E6-UJ65 ↩︎
Nima Badizadegan. Use One Big Server. specbranch.com, August 2022. Archived at perma.cc/M8NB-95UK ↩︎ ↩︎
Steve Yegge. Dear Google Cloud: Your Deprecation Policy is Killing You. steve-yegge.medium.com, August 2020. Archived at perma.cc/KQP9-SPGU ↩︎
Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. At ACM International Conference on Management of Data (SIGMOD), pages 1041-1052, May 2017. doi:10.1145/3035918.3056101 ↩︎ ↩︎ ↩︎
Panagiotis Antonopoulos, Alex Budovski, Cristian Diaconu, Alejandro Hernandez Saenz, Jack Hu, Hanuma Kodavalla, Donald Kossmann, Sandeep Lingam, Umar Farooq Minhas, Naveen Prakash, Vijendra Purohit, Hugh Qu, Chaitanya Sreenivas Ravella, Krystyna Reisteter, Sheetal Shrotri, Dixin Tang, and Vikram Wakade. Socrates: The New SQL Server in the Cloud. At ACM International Conference on Management of Data (SIGMOD), pages 1743-1756, June 2019. doi:10.1145/3299869.3314047 ↩︎ ↩︎ ↩︎
Midhul Vuppalapati, Justin Miron, Rachit Agarwal, Dan Truong, Ashish Motivala, and Thierry Cruanes. Building An Elastic Query Engine on Disaggregated Storage. At 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI), February 2020. ↩︎ ↩︎ ↩︎ ↩︎
Nick Van Wiggeren. The Real Failure Rate of EBS. planetscale.com, March 2025. Archived at perma.cc/43CR-SAH5 ↩︎
Colin Breck. Predicting the Future of Distributed Systems. blog.colinbreck.com, August 2024. Archived at perma.cc/K5FC-4XX2 ↩︎
Gwen Shapira. Compute-Storage Separation Explained. thenile.dev, January 2023. Archived at perma.cc/QCV3-XJNZ ↩︎
Ravi Murthy and Gurmeet Goindi. AlloyDB for PostgreSQL under the hood: Intelligent, database-aware storage. cloud.google.com, May 2022. Archived at archive.org ↩︎
Jack Vanlightly. The Architecture of Serverless Data Systems. jack-vanlightly.com, November 2023. Archived at perma.cc/UDV4-TNJ5 ↩︎
Eric Jonas, Johann Schleier-Smith, Vikram Sreekanti, Chia-Che Tsai, Anurag Khandelwal, Qifan Pu, Vaishaal Shankar, Joao Carreira, Karl Krauth, Neeraja Yadwadkar, Joseph E. Gonzalez, Raluca Ada Popa, Ion Stoica, David A. Patterson. Cloud Programming Simplified: A Berkeley View on Serverless Computing. arxiv.org, February 2019. ↩︎ ↩︎
Betsy Beyer, Jennifer Petoff, Chris Jones, and Niall Richard Murphy. Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media, 2016. ISBN: 9781491929124 ↩︎
Thomas Limoncelli. The Time I Stole $10,000 from Bell Labs. ACM Queue, volume 18, issue 5, November 2020. doi:10.1145/3434571.3434773 ↩︎
Charity Majors. The Future of Ops Jobs. acloudguru.com, August 2020. Archived at perma.cc/GRU2-CZG3 ↩︎
Boris Cherkasky. (Over)Pay As You Go for Your Datastore. medium.com, September 2021. Archived at perma.cc/Q8TV-2AM2 ↩︎
Shlomi Kushchi. Serverless Doesn’t Mean DevOpsLess or NoOps. thenewstack.io, February 2023. Archived at perma.cc/3NJR-AYYU ↩︎
Erik Bernhardsson. Storm in the stratosphere: how the cloud will be reshuffled. erikbern.com, November 2021. Archived at perma.cc/SYB2-99P3 ↩︎
Benn Stancil. The data OS. benn.substack.com, September 2021. Archived at perma.cc/WQ43-FHS6 ↩︎
Maria Korolov. Data residency laws pushing companies toward residency as a service. csoonline.com, January 2022. Archived at perma.cc/CHE4-XZZ2 ↩︎
Severin Borenstein. Can Data Centers Flex Their Power Demand? energyathaas.wordpress.com, April 2025. Archived at perma.cc/MUD3-A6FF ↩︎
Bilge Acun, Benjamin Lee, Fiodar Kazhamiaka, Aditya Sundarrajan, Kiwan Maeng, Manoj Chakkaravarthy, David Brooks, and Carole-Jean Wu. Carbon Dependencies in Datacenter Design and Management. ACM SIGENERGY Energy Informatics Review, volume 3, issue 3, pages 21-26. doi:10.1145/3630614.3630619 ↩︎
Kousik Nath. These are the numbers every computer engineer should know. freecodecamp.org, September 2019. Archived at perma.cc/RW73-36RL ↩︎
Joseph M. Hellerstein, Jose Faleiro, Joseph E. Gonzalez, Johann Schleier-Smith, Vikram Sreekanti, Alexey Tumanov, and Chenggang Wu. Serverless Computing: One Step Forward, Two Steps Back. At Conference on Innovative Data Systems Research (CIDR), January 2019. ↩︎
Frank McSherry, Michael Isard, and Derek G. Murray. Scalability! But at What COST? At 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015. ↩︎ ↩︎
Cindy Sridharan. Distributed Systems Observability: A Guide to Building Robust Systems. Report, O’Reilly Media, May 2018. Archived at perma.cc/M6JL-XKCM ↩︎
Charity Majors. Observability - A 3-Year Retrospective. thenewstack.io, August 2019. Archived at perma.cc/CG62-TJWL ↩︎
Benjamin H. Sigelman, Luiz Andre Barroso, Mike Burrows, Pat Stephenson, Manoj Plakal, Donald Beaver, Saul Jaspan, and Chandan Shanbhag. Dapper, a Large-Scale Distributed Systems Tracing Infrastructure. Google Technical Report dapper-2010-1, April 2010. Archived at perma.cc/K7KU-2TMH ↩︎
Rodrigo Laigner, Yongluan Zhou, Marcos Antonio Vaz Salles, Yijian Liu, and Marcos Kalinowski. Data management in microservices: State of the practice, challenges, and research directions. Proceedings of the VLDB Endowment, volume 14, issue 13, pages 3348-3361, September 2021. doi:10.14778/3484224.3484232 ↩︎
Jordan Tigani. Big Data is Dead. motherduck.com, February 2023. Archived at perma.cc/HT4Q-K77U ↩︎ ↩︎
Sam Newman. Building Microservices, second edition. O’Reilly Media, 2021. ISBN: 9781492034025 ↩︎ ↩︎
Chris Richardson. Microservices: Decomposing Applications for Deployability and Scalability. infoq.com, May 2014. Archived at perma.cc/CKN4-YEQ2 ↩︎
Mohammad Shahrad, Rodrigo Fonseca, Inigo Goiri, Gohar Chaudhry, Paul Batum, Jason Cooke, Eduardo Laureano, Colby Tresness, Mark Russinovich, Ricardo Bianchini. Serverless in the Wild: Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider. At USENIX Annual Technical Conference (ATC), July 2020. ↩︎
Luiz Andre Barroso, Urs Holzle, and Parthasarathy Ranganathan. The Datacenter as a Computer: Designing Warehouse-Scale Machines, third edition. Morgan & Claypool Synthesis Lectures on Computer Architecture, October 2018. doi:10.2200/S00874ED3V01Y201809CAC046 ↩︎ ↩︎
David Fiala, Frank Mueller, Christian Engelmann, Rolf Riesen, Kurt Ferreira, and Ron Brightwell. Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing. At International Conference for High Performance Computing, Networking, Storage and Analysis (SC), November 2012. doi:10.1109/SC.2012.49 ↩︎
Anna Kornfeld Simpson, Adriana Szekeres, Jacob Nelson, and Irene Zhang. Securing RDMA for High-Performance Datacenter Storage Systems. At 12th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud), July 2020. ↩︎
Arjun Singh, Joon Ong, Amit Agarwal, Glen Anderson, Ashby Armistead, Roy Bannon, Seb Boving, Gaurav Desai, Bob Felderman, Paulie Germano, Anand Kanagala, Jeff Provost, Jason Simmons, Eiichi Tanda, Jim Wanderer, Urs Holzle, Stephen Stuart, and Amin Vahdat. Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network. At Annual Conference of the ACM Special Interest Group on Data Communication (SIGCOMM), August 2015. doi:10.1145/2785956.2787508 ↩︎
Glenn K. Lockwood. Hadoop’s Uncomfortable Fit in HPC. glennklockwood.blogspot.co.uk, May 2014. Archived at perma.cc/S8XX-Y67B ↩︎
Cathy O’Neil: Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Crown Publishing, 2016. ISBN: 9780553418811 ↩︎
Supreeth Shastri, Vinay Banakar, Melissa Wasserman, Arun Kumar, and Vijay Chidambaram. Understanding and Benchmarking the Impact of GDPR on Database Systems. Proceedings of the VLDB Endowment, volume 13, issue 7, pages 1064-1077, March 2020. doi:10.14778/3384345.3384354 ↩︎
Martin Fowler. Datensparsamkeit. martinfowler.com, December 2013. Archived at perma.cc/R9QX-CME6 ↩︎
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 (General Data Protection Regulation). Official Journal of the European Union L 119/1, May 2016. ↩︎